Język programowania Rust
autorzy: Steve Klabnik, Carol Nichols i Chris Krycho, Maciej Ostrowski (przekład pl gemini-2.5-pro sty 26 r.), przy kontrybucjach Społeczności Rusta
Ta wersja tekstu zakłada, że używasz Rusta w wersji 1.90.0 (wydanie 2025-09-18)
lub nowszej z edition = "2024" w pliku Cargo.toml wszystkich projektów, aby
skonfigurować je do używania idiomów wydania Rust 2024. Zobacz sekcję „Instalacja”
w Rozdziale 1, aby uzyskać instrukcje dotyczące instalacji lub
aktualizacji Rusta, oraz Dodatek E, aby uzyskać informacje
o wydaniach.
Format HTML jest dostępny online pod adresem
https://doc.rust-lang.org/stable/book/
oraz offline z instalacjami Rusta wykonanymi za pomocą rustup; uruchom rustup doc --book, aby otworzyć.
Dostępne są również liczne [tłumaczenia] społeczności.
Ten tekst jest dostępny w formacie papierowym i ebooku od No Starch Press.
🚨 Chcesz bardziej interaktywnego doświadczenia edukacyjnego? Wypróbuj inną wersję Książki o Ruście, zawierającą: quizy, wyróżnienia, wizualizacje i wiele więcej: https://rust-book.cs.brown.edu
Przedmowa
Język programowania Rust przeszedł długą drogę w ciągu kilku krótkich lat, od jego stworzenia i inkubacji przez małą i rodzącą się społeczność entuzjastów, aż po stanie się jednym z najbardziej lubianych i poszukiwanych języków programowania na świecie. Z perspektywy czasu było nieuniknione, że moc i obietnica Rusta przyciągną uwagę i zakorzenią się w programowaniu systemowym. To, co nie było nieuniknione, to globalny wzrost zainteresowania i innowacji, który przeniknął przez społeczności open source i katalizował szeroko zakrojoną adopcję w różnych branżach.
W tym momencie łatwo jest wskazać wspaniałe cechy, które Rust ma do zaoferowania, aby wyjaśnić ten wybuch zainteresowania i adopcji. Kto nie chce bezpieczeństwa pamięci i szybkiej wydajności, i przyjaznego kompilatora, i wspaniałych narzędzi, pośród wielu innych wspaniałych funkcji? Język Rust, który widzisz dzisiaj, łączy lata badań w programowaniu systemowym z praktyczną mądrością tętniącej życiem i pełnej pasji społeczności. Ten język został zaprojektowany z myślą o celu i starannie wykonany, oferując deweloperom narzędzie, które ułatwia pisanie bezpiecznego, szybkiego i niezawodnego kodu.
Ale to, co czyni Rusta naprawdę wyjątkowym, to jego korzenie w umożliwianiu tobie, użytkownikowi, osiągania twoich celów. Jest to język, który chce, abyś odniósł sukces, a zasada wzmacniania pozycji przeplata się przez rdzeń społeczności, która buduje, utrzymuje i promuje ten język. Od poprzedniego wydania tego definitywnego tekstu, Rust rozwinął się w prawdziwie globalny i zaufany język. Projekt Rust jest teraz solidnie wspierany przez Fundację Rust, która również inwestuje w kluczowe inicjatywy, aby zapewnić, że Rust jest bezpieczny, stabilny i zrównoważony.
Niniejsze wydanie książki Język programowania Rust jest kompleksową aktualizacją, odzwierciedlającą ewolucję języka na przestrzeni lat i dostarczającą cennych nowych informacji. Ale to nie tylko przewodnik po składni i bibliotekach — to zaproszenie do przyłączenia się do społeczności, która ceni jakość, wydajność i przemyślany projekt. Niezależnie od tego, czy jesteś doświadczonym deweloperem, który po raz pierwszy chce poznać Rusta, czy doświadczonym Rustaceanem, który chce udoskonalić swoje umiejętności, to wydanie oferuje coś dla każdego.
Podróż z Rustem to podróż współpracy, nauki i iteracji. Rozwój języka i jego ekosystemu jest bezpośrednim odzwierciedleniem tętniącej życiem, różnorodnej społeczności, która za nim stoi. Kontrybucje tysięcy deweloperów, od projektantów podstawowych języków po okazjonalnych kontrybutorów, sprawiają, że Rust jest tak wyjątkowym i potężnym narzędziem. Biorąc tę książkę do ręki, nie tylko uczysz się nowego języka programowania — dołączasz do ruchu, który ma na celu ulepszanie oprogramowania, czynienie go bezpieczniejszym i przyjemniejszym w obsłudze.
Witaj w społeczności Rusta!
- Bec Rumbul, dyrektor wykonawcza Fundacji Rust
Wprowadzenie
Uwaga: To wydanie książki jest takie samo jak Język programowania Rust dostępny w formie drukowanej i ebooka od No Starch Press.
Witaj w Języku programowania Rust, książce wprowadzającej do Rusta. Język programowania Rust pomaga pisać szybsze, bardziej niezawodne oprogramowanie. Wysoka ergonomia i niska kontrola są często sprzeczne w projektowaniu języków programowania; Rust kwestionuje ten konflikt. Poprzez równoważenie potężnych możliwości technicznych i wspaniałego doświadczenia deweloperskiego, Rust daje możliwość kontrolowania niskopoziomowych szczegółów (takich jak użycie pamięci) bez wszystkich kłopotów tradycyjnie związanych z taką kontrolą.
Dla kogo jest Rust
Rust jest idealny dla wielu osób z różnych powodów. Przyjrzyjmy się kilku najważniejszym grupom.
Zespoły deweloperskie
Rust okazuje się być produktywnym narzędziem do współpracy między dużymi zespołami deweloperów o różnym poziomie znajomości programowania systemowego. Niskopoziomowy kod jest podatny na różne subtelne błędy, które w większości innych języków można wykryć jedynie poprzez obszerne testy i staranną weryfikację kodu przez doświadczonych deweloperów. W Ruście kompilator pełni rolę strażnika, odmawiając kompilacji kodu z tymi nieuchwytnymi błędami, w tym błędami współbieżności. Pracując obok kompilatora, zespół może poświęcić swój czas na skupienie się na logice programu, zamiast ścigać błędy.
Rust wprowadza również nowoczesne narzędzia dla deweloperów do świata programowania systemowego:
- Cargo, dołączony menedżer zależności i narzędzie do budowania, sprawia, że dodawanie, kompilowanie i zarządzanie zależnościami jest bezbolesne i spójne w całym ekosystemie Rusta.
- Narzędzie formatujące
rustfmtzapewnia spójny styl kodowania wśród deweloperów. - Rust Language Server zasila integrację ze zintegrowanymi środowiskami deweloperskimi (IDE) dla uzupełniania kodu i wbudowanych komunikatów o błędach.
Dzięki tym i innym narzędziom w ekosystemie Rusta, deweloperzy mogą być produktywni podczas pisania kodu na poziomie systemowym.
Studenci
Rust jest dla studentów i tych, którzy są zainteresowani nauką koncepcji systemowych. Używając Rusta, wiele osób uczyło się tematów takich jak rozwój systemów operacyjnych. Społeczność jest bardzo otwarta i chętnie odpowiada na pytania studentów. Poprzez wysiłki takie jak ta książka, zespoły Rusta chcą uczynić koncepcje systemowe bardziej dostępnymi dla większej liczby osób, szczególnie dla tych, którzy dopiero zaczynają programować.
Firmy
Setki firm, dużych i małych, używają Rusta w produkcji do różnych zadań, w tym narzędzi wiersza poleceń, usług sieciowych, narzędzi DevOps, urządzeń wbudowanych, analizy i transkodowania audio i wideo, kryptowalut, bioinformatyki, wyszukiwarek, aplikacji Internetu Rzeczy, uczenia maszynowego, a nawet głównych części przeglądarki internetowej Firefox.
Deweloperzy open source
Rust jest dla ludzi, którzy chcą budować język programowania Rust, społeczność, narzędzia deweloperskie i biblioteki. Chcielibyśmy, abyś wniósł swój wkład w rozwój języka Rust.
Ludzie ceniący szybkość i stabilność
Rust jest dla ludzi, którzy pragną szybkości i stabilności w języku. Przez szybkość rozumiemy zarówno to, jak szybko może działać kod Rusta, jak i szybkość, z jaką Rust pozwala pisać programy. Kontrole kompilatora Rusta zapewniają stabilność poprzez dodawanie funkcji i refaktoryzację. Jest to przeciwieństwo kruchego starego kodu w językach bez tych kontroli, którego deweloperzy często obawiają się modyfikować. Dążąc do abstrakcji zerokosztowych — funkcji wyższego poziomu, które kompilują się do kodu niższego poziomu tak szybko, jak kod napisany ręcznie — Rust stara się, aby bezpieczny kod był również szybkim kodem.
Język Rust ma nadzieję wspierać również wielu innych użytkowników; ci wspomniani tutaj to tylko niektórzy z największych interesariuszy. Ogólnie rzecz biorąc, największą ambicją Rusta jest wyeliminowanie kompromisów, które programiści akceptowali przez dziesięciolecia, zapewniając bezpieczeństwo i produktywność, szybkość i ergonomię. Spróbuj Rusta i zobacz, czy jego wybory sprawdzą się dla Ciebie.
Dla kogo jest ta książka
Ta książka zakłada, że pisałeś już kod w innym języku programowania, ale nie czyni żadnych założeń co do tego, w jakim. Staraliśmy się, aby materiał był szeroko dostępny dla osób z różnych środowisk programistycznych. Nie spędzamy wielu czasu na mówieniu o tym, czym jest programowanie ani jak o nim myśleć. Jeśli jesteś zupełnie początkujący w programowaniu, lepiej będzie, jeśli przeczytasz książkę, która specjalnie wprowadza w programowanie.
Jak korzystać z tej książki
Ogólnie rzecz biorąc, ta książka zakłada, że czytasz ją sekwencyjnie od początku do końca. Późniejsze rozdziały bazują na koncepcjach z wcześniejszych rozdziałów, a wcześniejsze rozdziały mogą nie zagłębiać się w szczegóły konkretnego tematu, ale powrócą do niego w późniejszym rozdziale.
W tej książce znajdziesz dwa rodzaje rozdziałów: rozdziały koncepcyjne i rozdziały projektowe. W rozdziałach koncepcyjnych dowiesz się o pewnym aspekcie Rusta. W rozdziałach projektowych będziemy wspólnie budować małe programy, stosując to, czego nauczyłeś się do tej pory. Rozdział 2, Rozdział 12 i Rozdział 21 to rozdziały projektowe; pozostałe to rozdziały koncepcyjne.
Rozdział 1 wyjaśnia, jak zainstalować Rusta, jak napisać program „Witaj, świecie!” i jak używać Cargo, menedżera pakietów i narzędzia do budowania Rusta. Rozdział 2 to praktyczne wprowadzenie do pisania programu w Ruście, polegające na budowaniu gry w zgadywanie liczb. Tutaj omawiamy koncepcje na wysokim poziomie, a późniejsze rozdziały dostarczą dodatkowych szczegółów. Jeśli chcesz od razu zabrać się do pracy, Rozdział 2 jest do tego idealnym miejscem. Jeśli jesteś szczególnie skrupulatnym uczniem, który woli poznać każdy szczegół przed przejściem do następnego, możesz pominąć Rozdział 2 i przejść bezpośrednio do Rozdziału 3, który obejmuje funkcje Rusta podobne do tych z innych języków programowania; następnie możesz wrócić do Rozdziału 2, kiedy będziesz chciał popracować nad projektem, stosując poznane szczegóły.
W Rozdziale 4 dowiesz się o systemie własności Rusta. Rozdział 5
omawia struktury i metody. Rozdział 6 obejmuje typy wyliczeniowe,
wyrażenia match oraz konstrukcje przepływu sterowania if let i let...else.
Użyjesz struktur i typów wyliczeniowych do tworzenia własnych typów.
W Rozdziale 7 dowiesz się o systemie modułów Rusta i zasadach prywatności dotyczących organizacji kodu i jego publicznego interfejsu programistycznego (API). Rozdział 8 omawia niektóre popularne struktury danych kolekcji dostępne w standardowej bibliotece: wektory, ciągi znaków i mapy haszujące. Rozdział 9 bada filozofię i techniki obsługi błędów Rusta.
Rozdział 10 zagłębia się w generyki, cechy i czasy życia, które dają ci
możliwość definiowania kodu, który stosuje się do wielu typów. Rozdział 11
polega na testowaniu, które nawet przy gwarancjach bezpieczeństwa Rusta jest
konieczne, aby upewnić się, że logika programu jest poprawna. W Rozdziale
12 zbudujemy naszą własną implementację podzbioru funkcjonalności narzędzia
wiersza poleceń grep, które wyszukuje tekst w plikach. W tym celu użyjemy
wielu koncepcji, które omówiliśmy w poprzednich rozdziałach.
Rozdział 13 bada domknięcia i iteratory: cechy Rusta pochodzące z funkcyjnych języków programowania. W Rozdziale 14 dokładniej zbadamy Cargo i porozmawiamy o najlepszych praktykach udostępniania bibliotek innym. Rozdział 15 omawia inteligentne wskaźniki dostępne w standardowej bibliotece oraz cechy, które umożliwiają ich funkcjonalność.
W Rozdziale 16 omówimy różne modele programowania współbieżnego i
porozmawiamy o tym, jak Rust pomaga programować w wielu wątkach bez obaw. W
Rozdziale 17 rozbudujemy to, badając składnię async i await Rusta, wraz
z zadaniami, futures i streams, oraz lekki model współbieżności, który
umożliwiają.
Rozdział 18 przygląda się, jak idiomy Rusta porównują się z zasadami programowania obiektowego, które możesz znać. Rozdział 19 to odniesienie do wzorców i dopasowywania wzorców, które są potężnymi sposobami wyrażania idei w programach Rusta. Rozdział 20 zawiera zbiór zaawansowanych tematów interesujących, w tym niebezpieczny Rust, makra i więcej o czasach życia, cechach, typach, funkcjach i domknięciach.
W Rozdziale 21 ukończymy projekt, w którym zaimplementujemy niskopoziomowy, wielowątkowy serwer WWW!
Na koniec, kilka dodatków zawiera użyteczne informacje o języku w formacie bardziej przypominającym referencje. Dodatek A obejmuje słowa kluczowe Rusta, Dodatek B obejmuje operatory i symbole Rusta, Dodatek C obejmuje cechy możliwe do wyprowadzenia dostarczane przez standardową bibliotekę, Dodatek D obejmuje niektóre użyteczne narzędzia programistyczne, a Dodatek E wyjaśnia wydania Rusta. W Dodatku F znajdziesz tłumaczenia książki, a w Dodatku G omówimy, jak powstaje Rust i czym jest Nightly Rust.
Nie ma złego sposobu na czytanie tej książki: Jeśli chcesz przeskoczyć do przodu, zrób to! Może będziesz musiał wrócić do wcześniejszych rozdziałów, jeśli spotkasz się z jakimkolwiek zamieszaniem. Ale rób to, co działa dla ciebie.
Ważną częścią procesu nauki Rusta jest nauka czytania komunikatów o błędach wyświetlanych przez kompilator: Będą one prowadzić Cię do działającego kodu. W związku z tym, przedstawimy wiele przykładów, które się nie kompilują, wraz z komunikatem o błędzie, który kompilator wyświetli w każdej sytuacji. Pamiętaj, że jeśli wpiszesz i uruchomisz przypadkowy przykład, może się on nie skompilować! Upewnij się, że przeczytałeś otaczający tekst, aby sprawdzić, czy przykład, który próbujesz uruchomić, ma celowo wyświetlić błąd. W większości sytuacji poprowadzimy Cię do poprawnej wersji kodu, który się nie kompiluje. Ferris również pomoże Ci rozróżnić kod, który nie ma działać:
| Ferris | Znaczenie |
|---|---|
 | Ten kod się nie kompiluje! |
 | Ten kod panikuje! |
 | Ten kod nie daje pożądanego zachowania. |
W większości sytuacji poprowadzimy Cię do poprawnej wersji kodu, który się nie kompiluje.
Kod źródłowy
Pliki źródłowe, z których generowana jest ta książka, można znaleźć na GitHubie.
Pierwsze kroki
Rozpocznij swoją podróż z Rustem! Wiele jest do nauczenia, ale każda podróż zaczyna się gdzieś. W tym rozdziale omówimy:
- Instalację Rusta na Linuksie, macOS i Windows
- Pisanie programu, który wypisuje
Witaj, świecie! - Używanie
cargo, menedżera pakietów i systemu budowania Rusta
Instalacja
Instalacja
Pierwszym krokiem jest zainstalowanie Rusta. Pobierzemy Rusta za pośrednictwem
rustup, narzędzia wiersza poleceń do zarządzania wersjami Rusta i
powiązanymi narzędziami. Do pobrania będziesz potrzebować połączenia z
internetem.
Uwaga: Jeśli z jakiegoś powodu wolisz nie używać
rustup, zapoznaj się z stroną Inne metody instalacji Rusta w celu uzyskania dodatkowych opcji.
Poniższe kroki instalują najnowszą stabilną wersję kompilatora Rusta. Gwarancje stabilności Rusta zapewniają, że wszystkie przykłady w książce, które się kompilują, będą nadal kompilować się z nowszymi wersjami Rusta. Wynik może nieznacznie różnić się między wersjami, ponieważ Rust często poprawia komunikaty o błędach i ostrzeżenia. Innymi słowy, każda nowsza, stabilna wersja Rusta zainstalowana za pomocą tych kroków powinna działać zgodnie z oczekiwaniami z treścią tej książki.
Notacja wiersza poleceń
W tym rozdziale i w całej książce będziemy pokazywać niektóre polecenia używane w terminalu. Wiersze, które powinieneś wpisać w terminalu, zaczynają się od
$. Nie musisz wpisywać znaku$; jest to znak zachęty wiersza poleceń, który wskazuje początek każdego polecenia. Wiersze, które nie zaczynają się od$, zazwyczaj pokazują wynik poprzedniego polecenia. Dodatkowo, przykłady specyficzne dla PowerShell będą używać>zamiast$.
Instalacja rustup na Linuksie lub macOS
Jeśli używasz Linuksa lub macOS, otwórz terminal i wprowadź następujące polecenie:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Polecenie pobiera skrypt i rozpoczyna instalację narzędzia rustup, które
instaluje najnowszą stabilną wersję Rusta. Może zostać wyświetlony monit o
hasło. Jeśli instalacja zakończy się pomyślnie, pojawi się następujący wiersz:
Rust jest już zainstalowany. Świetnie!
Będziesz także potrzebował linkera, czyli programu, którego Rust używa do łączenia skompilowanych wyników w jeden plik. Prawdopodobnie już go masz. Jeśli otrzymasz błędy linkera, powinieneś zainstalować kompilator C, który zazwyczaj zawiera linker. Kompilator C jest również przydatny, ponieważ niektóre popularne pakiety Rusta zależą od kodu C i będą wymagały kompilatora C.
Na macOS możesz uzyskać kompilator C, uruchamiając:
$ xcode-select --install
Użytkownicy Linuksa powinni zazwyczaj instalować GCC lub Clang, zgodnie z
dokumentacją swojej dystrybucji. Na przykład, jeśli używasz Ubuntu, możesz
zainstalować pakiet build-essential.
Instalacja rustup na Windows
Na Windows, przejdź na https://www.rust-lang.org/tools/install i postępuj zgodnie z instrukcjami instalacji Rusta. W pewnym momencie instalacji zostaniesz poproszony o zainstalowanie Visual Studio. Zapewnia to linker i natywne biblioteki potrzebne do kompilowania programów. Jeśli potrzebujesz więcej pomocy w tym kroku, zobacz https://rust-lang.github.io/rustup/installation/windows-msvc.html.
Reszta tej książki używa poleceń, które działają zarówno w cmd.exe, jak i PowerShell. Jeśli wystąpią specyficzne różnice, wyjaśnimy, którego użyć.
Rozwiązywanie problemów
Aby sprawdzić, czy Rust jest poprawnie zainstalowany, otwórz powłokę i wrowadź ten wiersz:
$ rustc --version
Ppowinien pojawić się numer wersji, skrót commita i data commita dla najnowszej stabilnej wersji, która została wydana, w następującym formacie:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Jeśli widzisz te informacje, pomyślnie zainstalowałeś Rusta! Jeśli ich nie
widzisz, sprawdź, czy Rust znajduje się w zmiennej systemowej %PATH% w
następujący sposób.
W systemie Windows CMD użyj:
> echo %PATH%
W PowerShellu użyj:
> echo $env:Path
Na Linuksie i macOS użyj:
$ echo $PATH
Jeśli wszystko jest w porządku, a Rust nadal nie działa, istnieje wiele miejsc, w których możesz uzyskać pomoc. Dowiedz się, jak skontaktować się z innymi Rustaceanami (tak się nazywamy) na stronie społeczności.
Aktualizacja i deinstalacja
Po zainstalowaniu Rusta za pomocą rustup, aktualizacja do nowo wydanej
wersji jest łatwa. Z poziomu powłoki uruchom następujący skrypt aktualizacji:
$ rustup update
Aby odinstalować Rusta i rustup, uruchom następujący skrypt odinstalowujący
z poziomu powłoki:
$ rustup self uninstall
Czytanie lokalnej dokumentacji
Instalacja Rusta zawiera również lokalną kopię dokumentacji, dzięki czemu
możesz czytać ją offline. Uruchom rustup doc, aby otworzyć lokalną
dokumentację w przeglądarce.
Zawsze, gdy typ lub funkcja jest dostarczana przez bibliotekę standardową, a nie masz pewności, co robi lub jak jej używać, skorzystaj z dokumentacji interfejsu programowania aplikacji (API), aby się dowiedzieć!
Używanie edytorów tekstu i środowisk IDE
Ta książka nie czyni żadnych założeń co do narzędzi, których używasz do pisania kodu Rusta. Niemal każdy edytor tekstu spełni swoje zadanie! Jednakże wiele edytorów tekstu i zintegrowanych środowisk programistycznych (IDE) posiada wbudowane wsparcie dla Rusta. Zawsze możesz znaleźć dość aktualną listę wielu edytorów i środowisk IDE na stronie z narzędziami na stronie internetowej Rusta.
Praca offline z tą książką
W kilku przykładach będziemy używać pakietów Rusta poza biblioteką standardową.
Aby przećwiczyć te przykłady, będziesz potrzebować połączenia z internetem
lub wcześniejszego pobrania tych zależności. Aby pobrać zależności wcześniej,
możesz uruchomić następujące polecenia. (Wyjaśnimy, czym jest cargo i co robi
każde z tych poleceń szczegółowo później.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Spowoduje to buforowanie pobrań tych pakietów, dzięki czemu nie będziesz
musiał ich później pobierać. Po uruchomieniu tego polecenia nie musisz
zatrzymywać folderu get-dependencies. Jeśli uruchomiłeś to polecenie,
możesz użyć flagi --offline ze wszystkimi poleceniami cargo w pozostałej
części książki, aby użyć tych buforowanych wersji zamiast próbować używać
sieci.
Witaj, świecie!
Witaj, świecie!
Skoro zainstalowałeś Rusta, czas napisać swój pierwszy program w tym języku.
Tradycyjnie, ucząc się nowego języka, pisze się mały program, który wyświetla
tekst Witaj, świecie! na ekranie, więc zrobimy to samo i tutaj!
Uwaga: Ta książka zakłada podstawową znajomość wiersza poleceń. Rust nie stawia żadnych specyficznych wymagań dotyczących edycji, narzędzi ani miejsca przechowywania kodu, więc jeśli wolisz używać IDE zamiast wiersza poleceń, śmiało korzystaj ze swojego ulubionego IDE. Wiele środowisk IDE ma obecnie pewne wsparcie dla Rusta; sprawdź dokumentację IDE, aby uzyskać szczegółowe informacje. Zespół Rusta skupia się na zapewnieniu doskonałego wsparcia IDE za pośrednictwem
rust-analyzer. Więcej szczegółów znajdziesz w Dodatku D.
Konfiguracja katalogu projektu
Zaczniesz od utworzenia katalogu do przechowywania kodu Rusta. Dla Rusta nie ma znaczenia, gdzie znajduje się Twój kod, ale dla ćwiczeń i projektów w tej książce sugerujemy utworzenie katalogu projects w katalogu domowym i przechowywanie tam wszystkich swoich projektów.
Otwórz terminal i wprowadź następujące polecenia, aby utworzyć katalog projects i katalog dla projektu „Witaj, świecie!” w katalogu projects.
Na Linuksie, macOS i w PowerShell na Windows, wprowadź:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
W systemie Windows CMD wprowadź:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Podstawy programu w Ruście
Następnie utwórz nowy plik źródłowy i nazwij go main.rs. Pliki Rusta zawsze kończą się rozszerzeniem .rs. Jeśli używasz więcej niż jednego słowa w nazwie pliku, konwencją jest używanie podkreślenia do ich rozdzielania. Na przykład użyj hello_world.rs zamiast helloworld.rs.
Teraz otwórz nowo utworzony plik main.rs i wprowadź kod z Listingu 1-1.
fn main() {
println!("Hello, world!");
}Zapisz plik i wróć do okna terminala w katalogu ~/projects/hello_world. Na Linuksie lub macOS wprowadź następujące polecenia, aby skompilować i uruchomić plik:
$ rustc main.rs
$ ./main
Hello, world!
Na Windows wprowadź polecenie .\main zamiast ./main:
> rustc main.rs
> .\main
Hello, world!
Niezależnie od systemu operacyjnego, w terminalu powinno pojawić się
Witaj, świecie!. Jeśli nie widzisz tego wyjścia, wróć do części „Rozwiązywanie
problemów” w sekcji Instalacja, aby uzyskać pomoc.
Jeśli Witaj, świecie! zostało wypisane, gratulacje! Oficjalnie napisałeś
program w Ruście. To czyni Cię programistą Rusta – witaj!
Anatomia programu w Ruście
Przejrzyjmy szczegółowo ten program „Witaj, świecie!”. Oto pierwszy element układanki:
fn main() {
}Te wiersze definiują funkcję o nazwie main. Funkcja main jest specjalna:
Zawsze jest pierwszym kodem, który jest uruchamiany w każdym wykonywalnym
programie w Ruście. Tutaj pierwszy wiersz deklaruje funkcję o nazwie main,
która nie ma parametrów i nic nie zwraca. Gdyby były parametry, znalazłyby się
w nawiasach ().
Ciało funkcji jest ujęte w {}. Rust wymaga nawiasów klamrowych wokół
wszystkich ciał funkcji. Dobrym stylem jest umieszczanie otwierającego nawiasu
klamrowego w tym samym wierszu co deklaracja funkcji, dodając jeden odstęp
pomiędzy nimi.
Uwaga: Jeśli chcesz trzymać się standardowego stylu w projektach Rusta, możesz użyć automatycznego narzędzia formatującego o nazwie
rustfmtdo formatowania kodu w określonym stylu (więcej orustfmtw Dodatku D). Zespół Rusta dołączył to narzędzie do standardowej dystrybucji Rusta, podobnie jakrustc, więc powinno być już zainstalowane na Twoim komputerze!
Ciało funkcji main zawiera następujący kod:
#![allow(unused)]
fn main() {
println!("Hello, world!");
}Ten wiersz wykonuje całą pracę w tym małym programie: wyświetla tekst na ekranie. Należy zwrócić uwagę na trzy ważne szczegóły.
Po pierwsze, println! wywołuje makro Rusta. Gdyby wywoływało funkcję, byłoby
wpisane jako println (bez !). Makra Rusta to sposób na pisanie kodu, który
generuje kod w celu rozszerzenia składni Rusta, a omówimy je bardziej
szczegółowo w Rozdziale 20. Na razie wystarczy
wiedzieć, że użycie ! oznacza wywołanie makra zamiast normalnej funkcji, a
makra nie zawsze przestrzegają tych samych zasad co funkcje.
Po drugie, widzisz ciąg znaków "Hello, world!". Przekazujemy ten ciąg jako
argument do println!, a ciąg jest wyświetlany na ekranie.
Po trzecie, kończymy wiersz średnikiem (;), co oznacza, że to wyrażenie
zostało zakończone, a następne jest gotowe do rozpoczęcia. Większość wierszy
kodu Rusta kończy się średnikiem.
Kompilacja i wykonanie
Właśnie uruchomiłeś nowo utworzony program, więc przyjrzyjmy się każdemu krokowi w tym procesie.
Przed uruchomieniem programu w Ruście musisz go skompilować za pomocą
kompilatora Rusta, wpisując polecenie rustc i podając nazwę pliku źródłowego,
w ten sposób:
$ rustc main.rs
Jeśli masz doświadczenie z C lub C++, zauważysz, że jest to podobne do gcc
lub clang. Po pomyślnej kompilacji Rust wypisuje plik wykonywalny.
Na Linuksie, macOS i w PowerShell na Windows, możesz zobaczyć plik wykonywalny,
wpisując polecenie ls w swojej powłoce:
$ ls
main main.rs
Na Linuksie i macOS zobaczysz dwa pliki. W PowerShell na Windows zobaczysz te same trzy pliki, które zobaczyłbyś używając CMD. W CMD na Windows wypisałbyś następujące polecenie:
> dir /B %= opcja /B wyświetla tylko nazwy plików =%
main.exe
main.pdb
main.rs
Pokazuje to plik kodu źródłowego z rozszerzeniem .rs, plik wykonywalny (main.exe na Windows, ale main na wszystkich innych platformach) oraz, w przypadku używania Windows, plik zawierający informacje debugowania z rozszerzeniem .pdb. Stąd uruchamiasz plik main lub main.exe, w ten sposób:
$ ./main # lub .\main na Windows
Jeśli twój main.rs to program „Witaj, świecie!”, ten wiersz wypisze Witaj, świecie! w twoim terminalu.
Jeśli jesteś bardziej zaznajomiony z językami dynamicznymi, takimi jak Ruby, Python lub JavaScript, możesz nie być przyzwyczajony do kompilowania i uruchamiania programu jako oddzielnych kroków. Rust jest językiem kompilowanym z wyprzedzeniem, co oznacza, że możesz skompilować program i przekazać plik wykonywalny komuś innemu, a ta osoba może go uruchomić nawet bez zainstalowanego Rusta. Jeśli przekażesz komuś plik .rb, .py lub .js, ta osoba musi mieć zainstalowaną (odpowiednio) implementację Ruby, Pythona lub JavaScriptu. Ale w tych językach potrzebujesz tylko jednego polecenia, aby skompilować i uruchomić program. Wszystko jest kompromisem w projektowaniu języka.
Samo kompilowanie za pomocą rustc jest wystarczające dla prostych programów,
ale w miarę rozrostu projektu będziesz chciał zarządzać wszystkimi opcjami i
ułatwić udostępnianie kodu. Następnie przedstawimy narzędzie Cargo, które pomoże
Ci pisać rzeczywiste programy w Ruście.
Witaj, Cargo!
Witaj, Cargo!
Cargo to system budowania i menedżer pakietów Rusta. Większość Rustaceanów używa tego narzędzia do zarządzania swoimi projektami w Ruście, ponieważ Cargo obsługuje wiele zadań za Ciebie, takich jak budowanie kodu, pobieranie bibliotek, od których zależy Twój kod, i budowanie tych bibliotek. (Biblioteki, których potrzebuje Twój kod, nazywamy zależnościami.)
Najprostsze programy w Ruście, takie jak ten, który do tej pory napisaliśmy, nie mają żadnych zależności. Gdybyśmy zbudowali projekt „Witaj, świecie!” za pomocą Cargo, używałby on tylko części Cargo, która obsługuje budowanie kodu. W miarę pisania bardziej złożonych programów w Ruście, będziesz dodawać zależności, a jeśli rozpoczniesz projekt za pomocą Cargo, dodawanie zależności będzie znacznie łatwiejsze.
Ponieważ zdecydowana większość projektów w Ruście używa Cargo, reszta tej książki zakłada, że Ty również używasz Cargo. Cargo jest instalowane wraz z Rustem, jeśli użyłeś oficjalnych instalatorów omówionych w sekcji „Instalacja”. Jeśli zainstalowałeś Rusta innymi sposobami, sprawdź, czy Cargo jest zainstalowane, wpisując w terminalu:
$ cargo --version
Jeśli widzisz numer wersji, masz go! Jeśli widzisz błąd, taki jak command not found, poszukaj w dokumentacji swojej metody instalacji, aby ustalić, jak
zainstalować Cargo oddzielnie.
Tworzenie projektu za pomocą Cargo
Utwórzmy nowy projekt za pomocą Cargo i przyjrzyjmy się, jak różni się od naszego oryginalnego projektu „Witaj, świecie!”. Wróć do katalogu projects (lub gdziekolwiek zdecydowałeś się przechowywać swój kod). Następnie, na każdym systemie operacyjnym, uruchom:
$ cargo new hello_cargo
$ cd hello_cargo
Pierwsze polecenie tworzy nowy katalog i projekt o nazwie hello_cargo. Nazwaliśmy nasz projekt hello_cargo, a Cargo tworzy swoje pliki w katalogu o tej samej nazwie.
Przejdź do katalogu hello_cargo i wypisz pliki. Zobaczysz, że Cargo wygenerowało dla nas dwa pliki i jeden katalog: plik Cargo.toml i katalog src z plikiem main.rs w środku.
Zainicjowało również nowe repozytorium Git wraz z plikiem .gitignore.
Pliki Git nie zostaną wygenerowane, jeśli uruchomisz cargo new w istniejącym
repozytorium Git; możesz nadpisać to zachowanie, używając cargo new --vcs=git.
Uwaga: Git to popularny system kontroli wersji. Możesz zmienić
cargo new, aby używać innego systemu kontroli wersji lub żadnego, używając flagi--vcs. Uruchomcargo new --help, aby zobaczyć dostępne opcje.
Otwórz Cargo.toml w swoim ulubionym edytorze tekstu. Powinien wyglądać podobnie do kodu z Listingu 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
Ten plik jest w formacie TOML (Tom’s Obvious, Minimal Language), który jest formatem konfiguracyjnym Cargo.
Pierwszy wiersz, [package], to nagłówek sekcji wskazujący, że następne
instrukcje konfigurują pakiet. W miarę dodawania kolejnych informacji do tego
pliku, będziemy dodawać inne sekcje.
Trzy następne wiersze ustawiają informacje konfiguracyjne, których Cargo
potrzebuje do skompilowania programu: nazwę, wersję i wydanie Rusta do
użycia. Omówimy klucz edition w Dodatku E.
Ostatni wiersz, [dependencies], to początek sekcji, w której możesz wymienić
wszystkie zależności swojego projektu. W Ruście pakiety kodu są nazywane
skrzynkami. Nie będziemy potrzebować żadnych innych skrzynek do tego projektu,
ale będziemy potrzebować ich w pierwszym projekcie w Rozdziale 2, więc
skorzystamy z tej sekcji zależności wtedy.
Teraz otwórz src/main.rs i przyjrzyj się:
Nazwa pliku: src/main.rs
fn main() {
println!("Hello, world!");
}Cargo wygenerowało dla Ciebie program „Witaj, świecie!”, dokładnie taki jak ten, który napisaliśmy w Listingu 1-1! Do tej pory różnice między naszym projektem a projektem wygenerowanym przez Cargo polegały na tym, że Cargo umieściło kod w katalogu src, a my mamy plik konfiguracyjny Cargo.toml w najwyższym katalogu.
Cargo oczekuje, że Twoje pliki źródłowe będą znajdować się w katalogu src. Katalog projektu najwyższego poziomu jest przeznaczony tylko na pliki README, informacje licencyjne, pliki konfiguracyjne i wszystko inne, co nie jest związane z Twoim kodem. Korzystanie z Cargo pomaga w organizacji projektów. Wszystko ma swoje miejsce i wszystko jest na swoim miejscu.
Jeśli rozpocząłeś projekt, który nie używa Cargo, tak jak to zrobiliśmy z
projektem „Witaj, świecie!”, możesz przekonwertować go na projekt, który używa
Cargo. Przenieś kod projektu do katalogu src i utwórz odpowiedni plik
Cargo.toml. Łatwym sposobem na uzyskanie pliku Cargo.toml jest uruchomienie
cargo init, które utworzy go dla Ciebie automatycznie.
Budowanie i uruchamianie projektu Cargo
Teraz przyjrzyjmy się, co się zmieni, gdy zbudujemy i uruchomimy program „Witaj, świecie!” za pomocą Cargo! Z katalogu hello_cargo zbuduj swój projekt, wypisując następujące polecenie:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
To polecenie tworzy plik wykonywalny w target/debug/hello_cargo (lub target\debug\hello_cargo.exe na Windows), a nie w bieżącym katalogu. Ponieważ domyślna kompilacja jest kompilacją debugową, Cargo umieszcza plik binarny w katalogu o nazwie debug. Możesz uruchomić plik wykonywalny za pomocą tego polecenia:
$ ./target/debug/hello_cargo # lub .\target\debug\hello_cargo.exe na Windows
Hello, world!
Jeśli wszystko pójdzie dobrze, w terminalu powinno zostać wyświetlone
Witaj, świecie!. Uruchomienie cargo build po raz pierwszy powoduje również,
że Cargo tworzy nowy plik na najwyższym poziomie: Cargo.lock. Ten plik śledzi
dokładne wersje zależności w Twoim projekcie. Ten projekt nie ma zależności,
więc plik jest nieco skąpy. Nigdy nie będziesz musiał ręcznie zmieniać tego
pliku; Cargo zarządza jego zawartością za Ciebie.
Właśnie zbudowaliśmy projekt za pomocą cargo build i uruchomiliśmy go za
pomocą ./target/debug/hello_cargo, ale możemy również użyć cargo run,
aby skompilować kod, a następnie uruchomić wynikowy plik wykonywalny za
jednym poleceniem:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Używanie cargo run jest wygodniejsze niż konieczność pamiętania o
uruchamianiu cargo build, a następnie używaniu pełnej ścieżki do pliku
binearnego, więc większość deweloperów używa cargo run.
Zauważ, że tym razem nie widzieliśmy wyjścia wskazującego, że Cargo kompiluje
hello_cargo. Cargo ustaliło, że pliki nie uległy zmianie, więc nie
przebudowywało, a jedynie uruchomiło plik binarny. Gdybyś zmodyfikował swój kod
źródłowy, Cargo przebudowałoby projekt przed jego uruchomieniem, a Ty
zobaczyłbyś takie wyjście:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo udostępnia również polecenie cargo check. To polecenie szybko
sprawdza Twój kod, aby upewnić się, że kompiluje się, ale nie tworzy pliku
wykonywalnego:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Dlaczego nie chciałbyś pliku wykonywalnego? Często cargo check jest
zauważalnie szybsze niż cargo build, ponieważ pomija krok tworzenia pliku
wykonywalnego. Jeśli stale sprawdzasz swoją pracę podczas pisania kodu,
użycie cargo check przyspieszy proces informowania Cię, czy Twój projekt
nadal się kompiluje! W związku z tym wielu Rustaceanów uruchamia cargo check
periodycznie podczas pisania programu, aby upewnić się, że się kompiluje.
Następnie uruchamiają cargo build, gdy są gotowi do użycia pliku
wykonywalnego.
Podsumujmy, czego do tej pory nauczyliśmy się o Cargo:
- Możemy utworzyć projekt za pomocą
cargo new. - Możemy zbudować projekt za pomocą
cargo build. - Możemy zbudować i uruchomić projekt w jednym kroku za pomocą
cargo run. - Możemy zbudować projekt bez tworzenia pliku binarnego, aby sprawdzić błędy,
za pomocą
cargo check. - Zamiast zapisywać wynik kompilacji w tym samym katalogu co nasz kod, Cargo przechowuje go w katalogu target/debug.
Dodatkową zaletą używania Cargo jest to, że polecenia są takie same, niezależnie od systemu operacyjnego, na którym pracujesz. Tak więc, w tym momencie nie będziemy już podawać konkretnych instrukcji dla Linuksa i macOS w stosunku do Windows.
Budowanie do wersji produkcyjnej
Kiedy Twój projekt jest wreszcie gotowy do wydania, możesz użyć cargo build --release, aby skompilować go z optymalizacjami. To polecenie utworzy plik
wykonywalny w target/release zamiast target/debug. Optymalizacje sprawiają,
że kod Rusta działa szybciej, ale ich włączenie wydłuża czas kompilacji
programu. Dlatego istnieją dwa różne profile: jeden do rozwoju, gdy chcesz
szybko i często przebudowywać, a drugi do budowania ostatecznego programu,
który przekażesz użytkownikowi, który nie będzie wielokrotnie przebudowywany i
który będzie działał tak szybko, jak to możliwe. Jeśli mierzysz czas
uruchamiania kodu, upewnij się, że uruchamiasz cargo build --release i
mierzysz wydajność z plikiem wykonywalnym w target/release.
Wykorzystanie konwencji Cargo
W przypadku prostych projektów Cargo nie zapewnia dużej wartości w porównaniu
z samym używaniem rustc, ale udowodni swoją wartość, gdy Twoje programy
staną się bardziej złożone. Gdy programy rozrosną się do wielu plików lub
będą wymagały zależności, znacznie łatwiej jest pozwolić Cargo
koordynować budowanie.
Mimo że projekt hello_cargo jest prosty, wykorzystuje teraz wiele
rzeczywistych narzędzi, których będziesz używać w pozostałej części swojej
kariery z Rustem. W rzeczywistości, aby pracować nad istniejącymi projektami,
możesz użyć następujących poleceń, aby pobrać kod za pomocą Git, przejść do
katalogu tego projektu i zbudować:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Więcej informacji na temat Cargo znajdziesz w jego dokumentacji.
Podsumowanie
Już świetnie zacząłeś swoją podróż z Rustem! W tym rozdziale nauczyłeś się:
- Jak zainstalować najnowszą stabilną wersję Rusta za pomocą
rustup. - Jak zaktualizować Rusta do nowszej wersji.
- Jak otworzyć lokalnie zainstalowaną dokumentację.
- Jak napisać i uruchomić program „Witaj, świecie!” bezpośrednio za pomocą
rustc. - Jak utworzyć i uruchomić nowy projekt, korzystając z konwencji Cargo.
To świetny moment, aby zbudować bardziej rozbudowany program, aby przyzwyczaić się do czytania i pisania kodu w Ruście. Tak więc, w Rozdziale 2 zbudujemy program do zgadywania liczb. Jeśli wolisz zacząć od nauki, jak działają powszechne koncepcje programistyczne w Ruście, zobacz Rozdział 3, a następnie wróć do Rozdziału 2.
Programowanie gry w zgadywanie
Zanurzmy się w Rust, realizując wspólnie praktyczny projekt! Ten rozdział
wprowadza cię w kilka popularnych koncepcji Rusta, pokazując, jak używać ich
w prawdziwym programie. Dowiesz się o let, match, metodach, funkcjach
skojarzonych, zewnętrznych “crate’ach” i wielu innych! W kolejnych
rozdziałach będziemy badać te idee bardziej szczegółowo. W tym rozdziale
będziesz ćwiczyć tylko podstawy.
Zaimplementujemy klasyczny problem programistyczny dla początkujących: grę w zgadywanie. Działa to tak: program wygeneruje losową liczbę całkowitą od 1 do 100. Następnie poprosi gracza o podanie strzału. Po wprowadzeniu strzału, program wskaże, czy strzał jest za niski, czy za wysoki. Jeśli strzał jest prawidłowy, gra wyświetli komunikat gratulacyjny i zakończy się.
Konfiguracja nowego projektu
Aby skonfigurować nowy projekt, przejdź do katalogu projects, który utworzyłeś w Rozdziale 1, i utwórz nowy projekt za pomocą Cargo, w następujący sposób:
$ cargo new guessing_game
$ cd guessing_game
Pierwsze polecenie, cargo new, przyjmuje nazwę projektu (guessing_game) jako
pierwszy argument. Drugie polecenie zmienia katalog na katalog nowego projektu.
Spójrz na wygenerowany plik Cargo.toml:
Nazwa pliku: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
Jak widziałeś w Rozdziale 1, cargo new generuje program “Hello, world!” dla
Ciebie. Sprawdź plik src/main.rs:
Nazwa pliku: src/main.rs
fn main() {
println!("Hello, world!");
}Teraz skompilujmy ten program “Hello, world!” i uruchommy go w tym samym kroku,
używając polecenia cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
Polecenie run przydaje się, gdy trzeba szybko iterować nad projektem, tak
jak będziemy to robić w tej grze, szybko testując każdą iterację, zanim
przejdziemy do następnej.
Otwórz ponownie plik src/main.rs. Cały kod będziesz pisać w tym pliku.
Przetwarzanie strzału
Pierwsza część programu do zgadywania liczb poprosi o dane wejściowe od użytkownika, przetworzy je i sprawdzi, czy dane są w oczekiwanej formie. Na początek pozwolimy graczowi wprowadzić strzał. Wprowadź kod z Listingu 2-1 do src/main.rs.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ten kod zawiera wiele informacji, więc przeanalizujmy go linia po linii. Aby
pobrać dane od użytkownika, a następnie wyświetlić wynik, musimy wprowadzić
bibliotekę wejścia/wyjścia io do zakresu. Biblioteka io pochodzi ze
standardowej biblioteki, znanej jako std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Domyślnie Rust ma zestaw elementów zdefiniowanych w standardowej bibliotece, które są wprowadzane do zakresu każdego programu. Ten zestaw nazywa się preludium, a wszystko w nim możesz zobaczyć w dokumentacji biblioteki standardowej.
Jeśli typ, którego chcesz użyć, nie znajduje się w preludium, musisz
explicitnie wprowadzić ten typ do zakresu za pomocą instrukcji use. Użycie
biblioteki std::io zapewnia wiele przydatnych funkcji, w tym możliwość
przyjmowania danych wejściowych od użytkownika.
Jak widziałeś w Rozdziale 1, funkcja main jest punktem wejścia do programu:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Składnia fn deklaruje nową funkcję; nawiasy () wskazują, że nie ma
parametrów; a nawias klamrowy { rozpoczyna ciało funkcji.
Jak również dowiedziałeś się w Rozdziale 1, println! to makro, które
wyświetla ciąg znaków na ekranie:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ten kod wyświetla komunikat informujący, czym jest gra, i prosi użytkownika o wprowadzenie danych.
Przechowywanie wartości w zmiennych
Następnie utworzymy zmienną do przechowywania danych wprowadzonych przez użytkownika, w ten sposób:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Teraz program staje się ciekawszy! W tej krótkiej linii dzieje się dużo. Używamy
instrukcji let do utworzenia zmiennej. Oto inny przykład:
let apples = 5;Ta linia tworzy nową zmienną o nazwie apples i wiąże ją z wartością 5.
W Rust zmienne są domyślnie niezmienne, co oznacza, że gdy raz nadamy
zmiennej wartość, wartość ta nie ulegnie zmianie. Omówimy tę koncepcję
szczegółowo w sekcji „Zmienne i mutowalność”
nazwą zmiennej:
let apples = 5; // niezmienna
let mut bananas = 5; // mutowalnaUwaga: Składnia // rozpoczyna komentarz, który trwa do końca linii. Rust
ignoruje wszystko, co znajduje się w komentarzach. Omówimy komentarze
szczegółowo w Rozdziale 3.
Wracając do programu gry w zgadywanie, wiesz już, że let mut guess wprowadzi
mutowalną zmienną o nazwie guess. Znak równości (=) mówi Rustowi, że
chcemy teraz powiązać coś ze zmienną. Po prawej stronie znaku równości
znajduje się wartość, z którą guess jest powiązane, czyli wynik wywołania
String::new, funkcji, która zwraca nową instancję typu String.
String to typ ciągu znaków dostarczony przez
standardową bibliotekę, który jest rozszerzalnym, kodowanym UTF-8 fragmentem
tekstu.
Składnia :: w linii ::new wskazuje, że new jest funkcją skojarzoną z
typem String. Funkcja skojarzona to funkcja zaimplementowana dla danego
typu, w tym przypadku String. Ta funkcja new tworzy nowy, pusty ciąg
znaków. Funkcję new znajdziesz na wielu typach, ponieważ jest to
powszechna nazwa dla funkcji, która tworzy nową wartość jakiegoś rodzaju.
Podsumowując, linia let mut guess = String::new(); utworzyła mutowalną
zmienną, która jest obecnie powiązana z nową, pustą instancją String. Uff!
Odbieranie danych od użytkownika
Przypomnijmy, że na początku programu dołączyliśmy funkcjonalność wejścia/
wyjścia ze standardowej biblioteki za pomocą use std::io;. Teraz wywołamy
funkcję stdin z modułu io, co pozwoli nam obsługiwać dane wejściowe od
użytkownika:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Gdybyśmy nie zaimportowali modułu io za pomocą use std::io; na początku
programu, nadal moglibyśmy użyć funkcji, pisząc wywołanie funkcji jako
std::io::stdin. Funkcja stdin zwraca instancję
std::io::Stdin, która jest typem
reprezentującym uchwyt do standardowego wejścia dla Twojego terminala.
Następnie, linia .read_line(&mut guess) wywołuje metodę
read_line na uchwycie standardowego wejścia
w celu pobrania danych od użytkownika. Przekazujemy również &mut guess jako
argument do read_line, aby powiedzieć jej, w którym ciągu znaków ma
przechowywać dane wejściowe od użytkownika. Pełnym zadaniem read_line jest
pobranie wszystkiego, co użytkownik wpisze do standardowego wejścia, i
dodanie tego do ciągu znaków (bez nadpisywania jego zawartości), dlatego
przekazujemy ten ciąg znaków jako argument. Argument ciągu znaków musi być
mutowalny, aby metoda mogła zmieniać zawartość ciągu znaków.
Znak & wskazuje, że ten argument jest referencją, co pozwala wielu
częściom Twojego kodu uzyskać dostęp do jednego fragmentu danych bez
konieczności wielokrotnego kopiowania tych danych do pamięci. Referencje są
złożoną funkcją, a jedną z głównych zalet Rusta jest to, jak bezpieczne i
łatwe jest używanie referencji. Nie musisz znać wielu z tych szczegółów, aby
zakończyć ten program. Na razie wystarczy wiedzieć, że podobnie jak zmienne,
referencje są domyślnie niezmienne. Dlatego musisz napisać &mut guess zamiast
&guess, aby uczynić ją mutowalną. (Rozdział 4 wyjaśni referencje bardziej
dokładnie).
Obsługa potencjalnych błędów za pomocą Result
Nadal pracujemy nad tą linią kodu. Teraz omawiamy trzecią linię tekstu, ale zwróć uwagę, że jest to nadal część jednej logicznej linii kodu. Następna część to ta metoda:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ten kod mogliśmy napisać jako:
io::stdin().read_line(&mut guess).expect("Failed to read line");Jednak jedna długa linia jest trudna do odczytania, więc najlepiej jest ją
podzielić. Często rozsądne jest wprowadzenie nowej linii i innych białych
znaków, aby ułatwić czytanie długich linii, gdy wywołujesz metodę za pomocą
składni .method_name(). Teraz omówmy, co ta linia robi.
Jak wspomniano wcześniej, read_line umieszcza wszystko, co użytkownik
wprowadzi, w przekazanym jej ciągu znaków, ale zwraca również wartość Result.
Result to wyliczenie enums,
często nazywane enum, które jest typem mogącym przyjmować jeden z wielu
możliwych stanów. Każdy możliwy stan nazywamy wariantem.
Rozdział 6 omówi szczegółowo enums. Celem tych
typów Result jest kodowanie informacji o obsłudze błędów.
Wariantami Result są Ok i Err. Wariant Ok wskazuje, że operacja
zakończyła się sukcesem i zawiera pomyślnie wygenerowaną wartość. Wariant Err
oznacza, że operacja zakończyła się niepowodzeniem i zawiera informacje o tym,
jak lub dlaczego operacja się nie powiodła.
Wartości typu Result, podobnie jak wartości każdego typu, mają zdefiniowane
na nich metody. Instancja Result ma metodę expect,
którą możesz wywołać. Jeśli ta instancja Result jest wartością Err,
expect spowoduje awarię programu i wyświetli komunikat, który przekazałeś
jako argument do expect. Jeśli metoda read_line zwróci Err, będzie to
prawdopodobnie wynikiem błędu pochodzącego z bazowego systemu operacyjnego.
Jeśli ta instancja Result jest wartością Ok, expect pobierze wartość
zwracaną, którą przechowuje Ok, i zwróci ci tylko tę wartość, abyś mógł jej
użyć. W tym przypadku ta wartość to liczba bajtów w danych wejściowych
użytkownika.
Jeśli nie wywołasz expect, program skompiluje się, ale otrzymasz ostrzeżenie:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust ostrzega, że nie użyłeś wartości Result zwróconej z read_line,
wskazując, że program nie obsłużył możliwego błędu.
Właściwym sposobem na stłumienie ostrzeżenia jest faktyczne napisanie kodu
do obsługi błędów, ale w naszym przypadku chcemy po prostu, aby ten program
uległ awarii, gdy wystąpi problem, więc możemy użyć expect. Dowiesz się o
recoverowaniu z błędów w Rozdziale 9.
Wyświetlanie wartości za pomocą znaczników println!
Poza końcowym nawiasem klamrowym, pozostała tylko jedna linia do omówienia w dotychczasowym kodzie:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ta linia wyświetla ciąg znaków, który teraz zawiera dane wejściowe
użytkownika. Zestaw nawiasów klamrowych {} to znacznik miejsca:
Wyobraź sobie {} jako małe szczypce kraba, które trzymają wartość na miejscu.
Podczas wyświetlania wartości zmiennej nazwa zmiennej może znajdować się w
środku nawiasów klamrowych. Podczas wyświetlania wyniku oceny wyrażenia,
umieść puste nawiasy klamrowe w ciągu formatującym, a następnie po ciągu
formatującym umieść listę wyrażeń oddzielonych przecinkami, które mają być
wyświetlone w każdym pustym znaczniku miejsca w tej samej kolejności.
Wyświetlanie zmiennej i wyniku wyrażenia w jednym wywołaniu println!
wyglądałoby tak:
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} and y + 2 = {}", y + 2);
}Ten kod wydrukowałby x = 5 and y + 2 = 12.
Testowanie pierwszej części
Przetestujmy pierwszą część gry w zgadywanie. Uruchom ją za pomocą cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
W tym momencie pierwsza część gry jest gotowa: pobieramy dane z klawiatury, a następnie je wyświetlamy.
Generowanie tajnej liczby
Następnie musimy wygenerować tajną liczbę, którą użytkownik będzie próbował
zgadnąć. Tajna liczba powinna być inna za każdym razem, aby gra była zabawna
do wielokrotnego grania. Użyjemy losowej liczby od 1 do 100, aby gra nie była
zbyt trudna. Rust nie zawiera jeszcze funkcji do generowania liczb losowych w
standardowej bibliotece. Jednak zespół Rusta udostępnia pakiet rand
crate z tą funkcjonalnością.
Zwiększanie funkcjonalności za pomocą pakietu
Pamiętaj, że crate to zbiór plików źródłowych Rusta. Projekt, który budujemy,
jest binary crate, czyli plikiem wykonywalnym. Crate rand to library
crate, który zawiera kod przeznaczony do użycia w innych programach i nie może
być wykonywany samodzielnie.
Koordynacja zewnętrznych crate'ów przez Cargo to miejsce, w którym Cargo
naprawdę błyszczy. Zanim będziemy mogli napisać kod, który używa rand,
musimy zmodyfikować plik Cargo.toml, aby dodać rand jako zależność.
Otwórz ten plik teraz i dodaj następującą linię na dole, pod nagłówkiem
sekcji [dependencies], który Cargo dla Ciebie utworzył. Upewnij się, że
określasz rand dokładnie tak, jak tutaj, z tym numerem wersji, w przeciwnym
razie przykłady kodu w tym samouczku mogą nie działać:
Nazwa pliku: Cargo.toml
[dependencies]
rand = "0.8.5"
W pliku Cargo.toml wszystko, co następuje po nagłówku, jest częścią tej
sekcji, która trwa, dopóki nie rozpocznie się inna sekcja. W [dependencies]
informujesz Cargo, od których zewnętrznych pakietów zależy Twój projekt i
których wersji tych pakietów potrzebujesz. W tym przypadku określamy pakiet
rand ze specyfikatorem wersji semantycznej 0.8.5. Cargo rozumie Semantic
Versioning (czasami nazywane SemVer), który jest
standardem zapisu numerów wersji. Specyfikator 0.8.5 jest w rzeczywistości
skrótem od ^0.8.5, co oznacza dowolną wersję co najmniej 0.8.5, ale
padającą poniżej 0.9.0.
Cargo uważa, że te wersje mają publiczne API kompatybilne z wersją 0.8.5, a ta specyfikacja gwarantuje, że otrzymasz najnowszą wersję poprawki, która nadal będzie kompilować się z kodem w tym rozdziale. Żadna wersja 0.9.0 lub większa nie gwarantuje tego samego API, co w poniższych przykładach.
Teraz, bez zmiany kodu, zbudujmy projekt, jak pokazano w Listingu 2-2.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
cargo build po dodaniu rand jako zależnościMożesz zobaczyć różne numery wersji (ale wszystkie będą kompatybilne z kodem, dzięki SemVer!) i różne linie (w zależności od systemu operacyjnego), a linie mogą być w innej kolejności.
Gdy dołączamy zewnętrzną zależność, Cargo pobiera najnowsze wersje wszystkiego, czego ta zależność potrzebuje, z rejestru, który jest kopią danych z Crates.io. Crates.io to miejsce, w którym ludzie w ekosystemie Rusta publikują swoje projekty Rust open source, aby inni mogli z nich korzystać.
Po zaktualizowaniu rejestru Cargo sprawdza sekcję [dependencies] i pobiera
wszystkie wymienione pakiety, które nie zostały jeszcze pobrane. W tym
przypadku, choć wymieniliśmy tylko rand jako zależność, Cargo pobrał również
inne pakiety, od których zależy rand, aby działał. Po pobraniu pakietów
Rust kompiluje je, a następnie kompiluje projekt z dostępnymi zależnościami.
Jeśli natychmiast ponownie uruchomisz cargo build bez wprowadzania żadnych
zmian, nie otrzymasz żadnych danych wyjściowych poza linią Finished.
Cargo wie, że już pobrał i skompilował zależności, a Ty nie zmieniłeś nic
w pliku Cargo.toml. Cargo wie również, że nie zmieniłeś nic w swoim kodzie,
więc nie kompiluje go ponownie. Nie mając nic do zrobienia, po prostu
kończy działanie.
Jeśli otworzysz plik src/main.rs, dokonasz trywialnej zmiany, a następnie zapiszesz go i ponownie zbudujesz, zobaczysz tylko dwie linie danych wyjściowych:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Te linie pokazują, że Cargo aktualizuje kompilację tylko o Twoją drobną zmianę w pliku src/main.rs. Twoje zależności nie uległy zmianie, więc Cargo wie, że może ponownie wykorzystać to, co już pobrał i skompilował dla nich.
Zapewnianie powtarzalnych kompilacji za pomocą pliku Cargo.lock
Cargo posiada mechanizm, który zapewnia, że możesz odbudować ten sam artefakt
za każdym razem, gdy Ty lub ktokolwiek inny buduje Twój kod: Cargo będzie używać
tylko tych wersji zależności, które określiłeś, chyba że wskażesz inaczej. Na
przykład, powiedzmy, że w przyszłym tygodniu zostanie wydana wersja 0.8.6 pakietu
rand, a ta wersja zawiera ważną poprawkę błędu, ale zawiera również regresję,
która zepsuje Twój kod. Aby temu zaradzić, Rust tworzy plik Cargo.lock za
pierwszym razem, gdy uruchamiasz cargo build, więc teraz mamy go w katalogu
guessing_game.
Kiedy budujesz projekt po raz pierwszy, Cargo ustala wszystkie wersje zależności, które spełniają kryteria, a następnie zapisuje je do pliku Cargo.lock. Kiedy budujesz swój projekt w przyszłości, Cargo zobaczy, że plik Cargo.lock istnieje i użyje tam określonych wersji, zamiast ponownie wykonywać całej pracy związanej z ustalaniem wersji. Pozwala to na automatyczne powtarzalne budowanie. Innymi słowy, Twój projekt pozostanie w wersji 0.8.5, dopóki wyraźnie go nie zaktualizujesz, dzięki plikowi Cargo.lock. Ponieważ plik Cargo.lock jest ważny dla powtarzalnych kompilacji, często jest dodawany do kontroli wersji wraz z resztą kodu w Twoim projekcie.
Aktualizacja “crate’a”, aby uzyskać nową wersję
Kiedy chcesz zaktualizować pakiet, Cargo udostępnia polecenie update, które
zignoruje plik Cargo.lock i ustali wszystkie najnowsze wersje, które pasują
do twoich specyfikacji w Cargo.toml. Cargo następnie zapisze te wersje do
pliku Cargo.lock. W przeciwnym razie, domyślnie, Cargo będzie szukać tylko
wersji większych niż 0.8.5 i mniejszych niż 0.9.0. Jeśli pakiet rand wydał
dwie nowe wersje 0.8.6 i 0.999.0, zobaczyłbyś następujące, gdybyś uruchomił
cargo update:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.999.0)
Cargo ignoruje wydanie 0.999.0. W tym momencie zauważyłbyś również zmianę w
pliku Cargo.lock, wskazującą, że wersja pakietu rand, której teraz używasz,
to 0.8.6. Aby użyć wersji rand 0.999.0 lub dowolnej wersji z serii 0.999.x,
musiałbyś zamiast tego zaktualizować plik Cargo.toml, aby wyglądał tak (nie
wprowadzaj tej zmiany, ponieważ poniższe przykłady zakładają, że używasz rand
0.8):
[dependencies]
rand = "0.999.0"
Następnym razem, gdy uruchomisz cargo build, Cargo zaktualizuje rejestr
dostępnych pakietów i ponownie oceni Twoje wymagania dotyczące rand zgodnie z
nową wersją, którą określiłeś.
Wiele jest do powiedzenia na temat Cargo i jego ekosystemu, które omówimy w Rozdziale 14, ale na razie to wszystko, co musisz wiedzieć. Cargo bardzo ułatwia ponowne używanie bibliotek, więc Rustowcy mogą pisać mniejsze projekty, które są montowane z wielu pakietów.
Generowanie liczby losowej
Zacznijmy używać rand do generowania liczby do zgadnięcia. Następnym krokiem
jest aktualizacja src/main.rs, jak pokazano w Listingu 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Najpierw dodajemy linię use rand::Rng;. Cecha Rng definiuje metody,
które implementują generatory liczb losowych, i ta cecha musi być w zakresie,
abyśmy mogli używać tych metod. Rozdział 10 szczegółowo omówi cechy.
Następnie dodajemy dwie linie w środku. W pierwszej linii wywołujemy funkcję
rand::thread_rng, która daje nam konkretny generator liczb losowych, którego
będziemy używać: taki, który jest lokalny dla bieżącego wątku wykonawczego
i jest inicjowany przez system operacyjny. Następnie wywołujemy metodę
gen_range na generatorze liczb losowych. Ta metoda jest zdefiniowana przez
cechę Rng, którą wprowadziliśmy do zakresu za pomocą instrukcji
use rand::Rng;. Metoda gen_range przyjmuje wyrażenie zakresu jako argument
i generuje liczbę losową w tym zakresie. Rodzaj wyrażenia zakresu, którego tu
używamy, ma postać start..=end i jest inkluzywny na dolnej i górnej granicy,
więc musimy określić 1..=100, aby zażądać liczby od 1 do 100.
Uwaga: Nie będziesz po prostu wiedział, których cech używać i które metody
i funkcje wywoływać z “crate’a”, więc każdy “crate” ma dokumentację z
instrukcjami jego używania. Inną fajną funkcją Cargo jest to, że uruchomienie
polecenia cargo doc --open zbuduje dokumentację dostarczoną przez wszystkie
Twoje zależności lokalnie i otworzy ją w Twojej przeglądarce. Jeśli interesuje
Cię inna funkcjonalność w “crate’cie” rand, na przykład, uruchom
cargo doc --open i kliknij rand na pasku bocznym po lewej stronie.
Druga nowa linia wyświetla tajną liczbę. Jest to przydatne podczas opracowywania programu, aby móc go przetestować, ale usuniemy ją z ostatecznej wersji. Nie ma sensu grać, jeśli program wyświetla odpowiedź zaraz po uruchomieniu!
Spróbuj uruchomić program kilka razy:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
Powinieneś otrzymać różne liczby losowe, i wszystkie powinny być liczbami pomiędzy 1 a 100. Świetna robota!
Porównywanie strzału z tajną liczbą
Teraz, gdy mamy dane wejściowe od użytkownika i liczbę losową, możemy je porównać. Ten krok jest pokazany w Listingu 2-4. Zauważ, że ten kod na razie się nie skompiluje, co wyjaśnimy.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Najpierw dodajemy kolejną instrukcję use, wprowadzając typ o nazwie
std::cmp::Ordering do zakresu ze standardowej biblioteki. Typ Ordering to
kolejne wyliczenie (enum) i ma warianty Less, Greater i Equal. Są to
trzy możliwe wyniki porównania dwóch wartości.
Następnie dodajemy pięć nowych linii na dole, które używają typu Ordering.
Metoda cmp porównuje dwie wartości i może być wywołana na wszystkim, co
można porównać. Przyjmuje referencję do tego, z czym chcesz porównać: tutaj
porównuje guess z secret_number. Następnie zwraca wariant wyliczenia
Ordering, które wprowadziliśmy do zakresu za pomocą instrukcji use.
Używamy wyrażenia match, aby zdecydować, co zrobić
dalej, w oparciu o to, który wariant Ordering został zwrócony z wywołania
cmp z wartościami w guess i secret_number.
Wyrażenie match składa się z ramion. Ramię składa się z wzorca, z którym
ma być dopasowywana wartość, oraz kodu, który powinien zostać uruchomiony, jeśli
wartość podana do match pasuje do wzorca tego ramienia. Rust pobiera wartość
podaną do match i kolejno przegląda wzorce każdego ramienia. Patrzy na
wzorzec pierwszego ramienia, Ordering::Less, i widzi, że wartość
Ordering::Greater nie pasuje do Ordering::Less, więc ignoruje kod w tym
ramieniu i przechodzi do następnego ramienia. Wzorzec następnego ramienia to
Ordering::Greater, który pasuje do Ordering::Greater! Powiązany kod w
tym ramieniu zostanie wykonany i wyświetli na ekranie Too big!. Wyrażenie
match kończy się po pierwszym udanym dopasowaniu, więc w tym scenariuszu
nie będzie patrzeć na ostatnie ramię.
Jednak kod w Listingu 2-4 jeszcze się nie skompiluje. Spróbujmy:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
Rdzeń błędu stwierdza, że występują niezgodne typy. Rust ma silny, statyczny
system typów. Jednak ma również inferencję typów. Kiedy napisaliśmy
let mut guess = String::new(), Rust był w stanie wywnioskować, że guess
powinno być String i nie kazał nam pisać tego typu. secret_number natomiast
jest typem liczbowym. Kilka typów liczbowych Rusta może mieć wartość pomiędzy
1 a 100: i32, liczba 32-bitowa; u32, niepodpisana liczba 32-bitowa; i64,
liczba 64-bitowa; oraz inne. O ile nie określono inaczej, Rust domyślnie używa
i32, który jest typem secret_number, chyba że dodasz informacje o typie w
innym miejscu, co spowodowałoby, że Rust wywnioskowałby inny typ liczbowy.
Powodem błędu jest to, że Rust nie może porównywać ciągu znaków i typu
liczbowego.
Ostatecznie chcemy przekonwertować String, którą program odczytuje jako dane
wejściowe, na typ liczbowy, abyśmy mogli porównać ją numerycznie z tajną
liczbą. Robimy to, dodając tę linię do ciała funkcji main:
Nazwa pliku: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Linia to:
let guess: u32 = guess.trim().parse().expect("Please type a number!");Tworzymy zmienną o nazwie guess. Ale chwila, czy program nie ma już zmiennej
o nazwie guess? Tak, ale Rust pozwala nam w korzystny sposób zacienić
poprzednią wartość guess nową. Zacienianie pozwala nam ponownie użyć nazwy
zmiennej guess, zamiast zmuszać nas do tworzenia dwóch unikalnych zmiennych,
takich jak guess_str i guess, na przykład. Omówimy to szczegółowo w
Rozdziale 3, ale na razie wiedz, że ta funkcja jest
często używana, gdy chcesz przekonwertować wartość z jednego typu na inny.
Wiązamy tę nową zmienną z wyrażeniem guess.trim().parse(). guess w
wyrażeniu odnosi się do oryginalnej zmiennej guess, która zawierała dane
wejściowe jako ciąg znaków. Metoda trim na instancji String usunie
wszelkie białe znaki na początku i na końcu, co musimy zrobić, zanim
przekonwertujemy ciąg znaków na u32, który może zawierać tylko dane
liczbowe. Użytkownik musi nacisnąć enter, aby zadowolić read_line i
wprowadzić swój strzał, co dodaje znak nowej linii do ciągu znaków. Na
przykład, jeśli użytkownik wpisze 5 i naciśnie enter, guess
będzie wyglądało tak: 5\n. \n oznacza “nową linię”. (W systemie Windows
naciśnięcie enter powoduje powrót karetki i nową linię, \r\n.) Metoda
trim usuwa \n lub \r\n, pozostawiając tylko 5.
Metoda parse na ciągach znaków konwertuje ciąg
znaków na inny typ. Tutaj używamy jej do konwersji z ciągu znaków na liczbę.
Musimy powiedzieć Rustowi dokładny typ liczbowy, którego chcemy, używając
let guess: u32. Dwukropek (:) po guess mówi Rustowi, że będziemy
anotować typ zmiennej. Rust ma kilka wbudowanych typów liczbowych; u32
widziane tutaj to niepodpisana, 32-bitowa liczba całkowita. Jest to dobry
domyślny wybór dla małej liczby dodatniej. O innych typach liczbowych dowiesz
się w Rozdziale 3.
Dodatkowo, adnotacja u32 w tym przykładzie programu i porównanie z
secret_number oznacza, że Rust wywnioskuje, iż secret_number również
powinno być u32. Tak więc, teraz porównanie będzie dotyczyło dwóch wartości
tego samego typu!
Metoda parse będzie działać tylko na znakach, które można logicznie
przekształcić na liczby i dlatego może łatwo powodować błędy. Gdyby, na
przykład, ciąg znaków zawierał A👍%, nie byłoby sposobu na przekształcenie
tego na liczbę. Ponieważ może to zakończyć się niepowodzeniem, metoda parse
zwraca typ Result, podobnie jak metoda read_line (omówiona wcześniej w
sekcji „Obsługa potencjalnych błędów za pomocą Result”).
Będziemy traktować ten Result w ten sam sposób, ponownie używając metody
expect. Jeśli parse zwróci wariant Err Result, ponieważ nie udało się
utworzyć liczby z ciągu znaków, wywołanie expect spowoduje awarię gry i
wyświetli komunikat, który mu podamy. Jeśli parse z powodzeniem przekonwertuje
ciąg znaków na liczbę, zwróci wariant Ok Result, a expect zwróci liczbę,
której chcemy z wartości Ok.
Uruchommy teraz program:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Świetnie! Mimo że przed zgadywaną liczbą dodano spacje, program nadal rozpoznał, że użytkownik zgadł 76. Uruchom program kilka razy, aby sprawdzić różne zachowania z różnymi rodzajami danych wejściowych: zgadnij liczbę poprawnie, zgadnij liczbę, która jest za wysoka, i zgadnij liczbę, która jest za niska.
Mamy już większość gry działającą, ale użytkownik może wykonać tylko jeden strzał. Zmieńmy to, dodając pętlę!
Zezwalanie na wielokrotne zgadywanie za pomocą pętli
Słowo kluczowe loop tworzy nieskończoną pętlę. Dodamy pętlę, aby dać
użytkownikom więcej szans na odgadnięcie liczby:
Nazwa pliku: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}Jak widać, przenieśliśmy wszystko od monitu o wprowadzenie zgadywanej liczby dalej do pętli. Upewnij się, że wciśniesz każdą linię wewnątrz pętli o kolejne cztery spacje i ponownie uruchom program. Program będzie teraz prosił o kolejny strzał w nieskończoność, co wprowadza nowy problem. Wygląda na to, że użytkownik nie może wyjść!
Użytkownik zawsze mógł przerwać program za pomocą skrótu klawiaturowego
ctrl-C. Ale jest inny sposób na ucieczkę przed tym
nienasyconym potworem, jak wspomniano w dyskusji o parse w sekcji
„Porównywanie strzału z tajną liczbą”: jeśli użytkownik wprowadzi
dane nieliczbowe, program ulegnie awarii. Możemy to wykorzystać, aby pozwolić
użytkownikowi wyjść, jak pokazano tutaj:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Wpisanie quit spowoduje wyjście z gry, ale jak zauważysz, tak samo zadziała
wprowadzenie dowolnych innych danych nieliczbowych. Jest to, delikatnie mówiąc,
nieoptymalne; chcemy, aby gra zatrzymywała się również po odgadnięciu
prawidłowej liczby.
Zakończenie po prawidłowym strzale
Zaprogramujmy grę tak, aby kończyła się, gdy użytkownik wygra, dodając instrukcję
break:
Nazwa pliku: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Dodanie linii break po You win! powoduje, że program wychodzi z pętli, gdy
użytkownik poprawnie odgadnie tajną liczbę. Wyjście z pętli oznacza również
wyjście z programu, ponieważ pętla jest ostatnią częścią main.
Obsługa nieprawidłowych danych wejściowych
Aby jeszcze bardziej dopracować zachowanie gry, zamiast zawieszać program,
gdy użytkownik wprowadzi dane nieliczbowe, niech gra ignoruje takie dane,
umożliwiając użytkownikowi dalsze zgadywanie. Możemy to zrobić, zmieniając
linię, w której guess jest konwertowane z String na u32, jak pokazano
w Listingu 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Zmieniamy wywołanie expect na wyrażenie match, aby zamiast zawieszenia
w przypadku błędu, obsłużyć błąd. Pamiętaj, że parse zwraca typ Result,
a Result jest wyliczeniem, które ma warianty Ok i Err. Używamy tutaj
wyrażenia match, tak jak to robiliśmy z wynikiem Ordering metody cmp.
Jeśli parse jest w stanie pomyślnie przekształcić ciąg znaków w liczbę,
zwróci wartość Ok, która będzie zawierać wynikową liczbę. Ta wartość Ok
będzie pasować do wzorca pierwszego ramienia, a wyrażenie match po prostu
zwróci wartość num, którą parse wyprodukowało i umieściło w wartości Ok.
Ta liczba trafi dokładnie tam, gdzie chcemy, do nowej zmiennej guess, którą
tworzymy.
Jeśli parse nie jest w stanie przekształcić ciągu znaków w liczbę,
zwróci wartość Err, która zawiera więcej informacji o błędzie. Wartość Err
nie pasuje do wzorca Ok(num) w pierwszym ramieniu match, ale pasuje do
wzorca Err(_) w drugim ramieniu. Podkreślnik _ to wartość
„chwyć-wszystko”; w tym przykładzie mówimy, że chcemy dopasować wszystkie
wartości Err, niezależnie od tego, jakie informacje zawierają. Zatem program
wykona kod drugiego ramienia, continue, co nakazuje programowi przejść do
następnej iteracji loop i poprosić o kolejny strzał. Tak więc, efektywnie,
program ignoruje wszystkie błędy, jakie parse może napotkać!
Teraz wszystko w programie powinno działać zgodnie z oczekiwaniami. Spróbujmy:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Cudownie! Z drobną, ostatnią poprawką, zakończymy grę w zgadywanie. Przypomnij
sobie, że program nadal wyświetla tajną liczbę. To dobrze działało podczas
testowania, ale psuje grę. Usuńmy println!, które wyświetla tajną liczbę.
Listing 2-6 pokazuje ostateczny kod.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}W tym momencie pomyślnie zbudowałeś grę w zgadywanie. Gratulacje!
Podsumowanie
Ten projekt był praktycznym sposobem na wprowadzenie cię w wiele nowych
koncepcji Rusta: let, match, funkcje, użycie zewnętrznych pakietów i
wiele innych. W kolejnych rozdziałach dowiesz się o tych koncepcjach bardziej
szczegółowo. Rozdział 3 obejmuje koncepcje, które posiadają większość języków
programowania, takie jak zmienne, typy danych i funkcje, i pokazuje, jak ich
używać w Ruście. Rozdział 4 bada własność, cechę, która odróżnia Rusta od
innych języków. Rozdział 5 omawia struktury i składnię metod, a Rozdział 6
wyjaśnia, jak działają wyliczenia (enums).
Podstawowe koncepcje programowania
Ten rozdział obejmuje koncepcje, które pojawiają się w prawie każdym języku programowania i sposób, w jaki działają w Ruście. Wiele języków programowania ma ze sobą wiele wspólnego w swoim rdzeniu. Żadna z koncepcji przedstawionych w tym rozdziale nie jest unikalna dla Rusta, ale omówimy je w kontekście Rusta i wyjaśnimy konwencje dotyczące ich używania.
Konkretnie, dowiesz się o zmiennych, podstawowych typach, funkcjach, komentarzach i przepływie sterowania. Te podstawy znajdą się w każdym programie Rusta, a wczesne ich poznanie da Ci solidny rdzeń, od którego możesz zacząć.
Słowa kluczowe
Język Rust ma zestaw słów kluczowych, które są zarezerwowane wyłącznie dla języka, podobnie jak w innych językach. Pamiętaj, że nie możesz używać tych słów jako nazw zmiennych ani funkcji. Większość słów kluczowych ma specjalne znaczenia, a będziesz ich używać do wykonywania różnych zadań w swoich programach w Ruście; kilka nie ma obecnie żadnej związanej z nimi funkcjonalności, ale zostały zarezerwowane dla funkcjonalności, która może zostać dodana do Rusta w przyszłości. Listę słów kluczowych znajdziesz w Dodatku A.
Zmienne i mutowalność
Zmienne i mutowalność
Jak wspomniano w sekcji „Przechowywanie wartości w zmiennych”, zmienne są domyślnie niezmienne. Jest to jedna z wielu wskazówek, które Rust daje Ci, abyś pisał swój kod w sposób, który wykorzystuje bezpieczeństwo i łatwą współbieżność, jakie oferuje Rust. Jednak nadal masz możliwość uczynienia swoich zmiennych mutowalnymi. Przyjrzyjmy się, jak i dlaczego Rust zachęca do preferowania niezmienności i dlaczego czasami możesz chcieć zrezygnować z tej opcji.
Kiedy zmienna jest niezmienna, po powiązaniu wartości z nazwą nie można
zmienić tej wartości. Aby to zilustrować, wygeneruj nowy projekt o nazwie
variables w swoim katalogu projects za pomocą cargo new variables.
Następnie, w nowym katalogu variables, otwórz src/main.rs i zastąp jego kod następującym kodem, który jeszcze się nie skompiluje:
Nazwa pliku: src/main.rs
fn main() {
let x = 5;
println!("Wartość x to: {x}");
x = 6;
println!("Wartość x to: {x}");
}Zapisz i uruchom program za pomocą cargo run. Powinieneś otrzymać komunikat
o błędzie dotyczący błędu niezmienności, jak pokazano w tym wyjściu:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Ten przykład pokazuje, jak kompilator pomaga znaleźć błędy w Twoich programach. Błędy kompilatora mogą być frustrujące, ale tak naprawdę oznaczają tylko, że Twój program nie działa jeszcze bezpiecznie tak, jak chcesz; nie oznaczają, że nie jesteś dobrym programistą! Doświadczeni Rustaceanie nadal otrzymują błędy kompilatora.
Otrzymałeś komunikat o błędzie cannot assign twice to immutable variable `x`
(nie można przypisać dwa razy do niezmiennej zmiennej x), ponieważ próbowałeś
przypisać drugą wartość do niezmiennej zmiennej x.
Ważne jest, abyśmy otrzymywali błędy kompilacji, gdy próbujemy zmienić wartość, która została oznaczona jako niezmienna, ponieważ ta właśnie sytuacja może prowadzić do błędów. Jeśli jedna część naszego kodu działa w oparciu o założenie, że wartość nigdy się nie zmieni, a inna część naszego kodu zmienia tę wartość, możliwe jest, że pierwsza część kodu nie wykona tego, do czego została zaprojektowana. Przyczynę tego rodzaju błędu może być trudno wyśledzić po fakcie, zwłaszcza gdy druga część kodu zmienia wartość tylko czasami. Kompilator Rusta gwarantuje, że gdy zadeklarujesz, że wartość się nie zmieni, to naprawdę się nie zmieni, więc nie musisz sam tego śledzić. Twój kod jest dzięki temu łatwiejszy do przemyślenia.
Ale mutowalność może być bardzo przydatna i może sprawić, że kod będzie
wygodniejszy w pisaniu. Chociaż zmienne są domyślnie niezmienne, możesz
uczynić je mutowalnymi, dodając mut przed nazwą zmiennej, tak jak to
zrobiłeś w Rozdziale 2.
Dodanie mut również przekazuje intencję przyszłym czytelnikom kodu,
wskazując, że inne części kodu będą zmieniać wartość tej zmiennej.
Na przykład, zmieńmy src/main.rs na następujący kod:
Nazwa pliku: src/main.rs
fn main() {
let mut x = 5;
println!("Wartość x to: {x}");
x = 6;
println!("Wartość x to: {x}");
}Kiedy uruchomimy program teraz, otrzymamy:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
Wartość x to: 5
Wartość x to: 6
Możemy zmienić wartość przypisaną do x z 5 na 6, gdy użyto mut.
Ostatecznie, decyzja o użyciu mutowalności zależy od Ciebie i od tego, co
uważasz za najbardziej przejrzyste w danej sytuacji.
Deklarowanie stałych
Podobnie jak niezmienne zmienne, stałe to wartości, które są powiązane z nazwą i nie mogą być zmieniane, ale istnieją pewne różnice między stałymi a zmiennymi.
Po pierwsze, nie wolno używać mut ze stałymi. Stałe są nie tylko domyślnie
niezmienne — są zawsze niezmienne. Stałe deklaruje się za pomocą słowa
kluczowego const zamiast słowa kluczowego let, a typ wartości musi być
annotowany. Typy i adnotacje typów omówimy w następnej sekcji, „Typy
danych”, więc na razie nie martw się szczegółami.
Wystarczy wiedzieć, że zawsze musisz podawać typ.
Stałe mogą być deklarowane w dowolnym zasięgu, w tym w zasięgu globalnym, co czyni je użytecznymi dla wartości, o których wiele części kodu musi wiedzieć.
Ostatnia różnica polega na tym, że stałe mogą być ustawiane tylko na wyrażenie stałe, a nie na wynik wartości, która mogłaby być obliczona tylko w czasie uruchamiania.
Oto przykład deklaracji stałej:
#![allow(unused)]
fn main() {
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
}Nazwa stałej to THREE_HOURS_IN_SECONDS, a jej wartość jest ustawiona na
wynik pomnożenia 60 (liczby sekund w minucie) przez 60 (liczby minut w
godzinie) przez 3 (liczby godzin, które chcemy policzyć w tym programie).
Konwencją nazewniczą Rusta dla stałych jest używanie samych dużych liter z
podkreśleniami między słowami. Kompilator jest w stanie ocenić ograniczony
zestaw operacji w czasie kompilacji, co pozwala nam zapisać tę wartość w sposób
łatwiejszy do zrozumienia i weryfikacji, zamiast ustawiać tę stałą na wartość
10 800. Więcej informacji na temat operacji, które można stosować przy
deklarowaniu stałych, znajdziesz w sekcji Rust Reference dotyczącej
ewaluacji stałych.
Stałe są ważne przez cały czas działania programu, w zasięgu, w którym zostały zadeklarowane. Ta właściwość sprawia, że stałe są przydatne dla wartości w domenie aplikacji, o których wiele części programu może potrzebować wiedzieć, takich jak maksymalna liczba punktów, jaką każdy gracz może zdobyć, lub prędkość światła.
Nazywanie zakodowanych wartości używanych w całym programie jako stałych jest przydatne w przekazywaniu znaczenia tej wartości przyszłym utrzymującym kod. Pomaga również mieć tylko jedno miejsce w kodzie, które trzeba by zmienić, gdyby zakodowana wartość wymagała aktualizacji w przyszłości.
Przesłanianie
Jak widziałeś w samouczku gry w zgadywanie w Rozdziale
2, możesz
zadeklarować nową zmienną o tej samej nazwie co poprzednia zmienna. Rustaceanie
mówią, że pierwsza zmienna jest przesłonięta przez drugą, co oznacza, że druga
zmienna jest tym, co kompilator będzie widział, gdy użyjesz nazwy zmiennej.
W efekcie druga zmienna przysłania pierwszą, przejmując wszelkie użycia nazwy
zmiennej na siebie, dopóki sama nie zostanie przesłonięta lub zasięg się nie
zakończy. Możemy przesłonić zmienną, używając tej samej nazwy zmiennej i
powtarzając użycie słowa kluczowego let w następujący sposób:
Nazwa pliku: src/main.rs
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("Wartość x w wewnętrznym zasięgu to: {x}");
}
println!("Wartość x to: {x}");
}Ten program najpierw wiąże x z wartością 5. Następnie tworzy nową zmienną
x, powtarzając let x =, biorąc oryginalną wartość i dodając 1 tak, aby
wartość x wynosiła 6. Następnie, wewnątrz wewnętrznego zasięgu
utworzonego za pomocą nawiasów klamrowych, trzecia instrukcja let również
przesłania x i tworzy nową zmienną, mnożąc poprzednią wartość przez 2, aby
nadać x wartość 12. Gdy ten zasięg się kończy, wewnętrzne przesłanianie
zakończy się, a x powróci do 6. Kiedy uruchomimy ten program, wyświetli
się następujący wynik:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
Wartość x w wewnętrznym zasięgu to: 12
Wartość x to: 6
Przesłanianie różni się od oznaczania zmiennej jako mut, ponieważ
otrzymamy błąd kompilacji, jeśli przypadkowo spróbujemy przypisać nową wartość
do tej zmiennej bez użycia słowa kluczowego let. Używając let,
możemy wykonać kilka transformacji na wartości, ale po tych transformacjach
zmienna pozostanie niezmienna.
Inna różnica między mut a przesłanianiem polega na tym, że ponieważ
efektywnie tworzymy nową zmienną, gdy ponownie używamy słowa kluczowego let,
możemy zmienić typ wartości, ale ponownie użyć tej samej nazwy. Na przykład,
powiedzmy, że nasz program prosi użytkownika o podanie liczby spacji,
jakie chce między tekstem, wprowadzając spacje, a następnie chcemy
przechowywać te dane wejściowe jako liczbę:
fn main() {
let spaces = " ";
let spaces = spaces.len();
}Pierwsza zmienna spaces jest typu string, a druga zmienna spaces jest
typu liczbowego. Przesłanianie pozwala nam uniknąć wymyślania różnych nazw,
takich jak spaces_str i spaces_num; zamiast tego możemy ponownie użyć
prostszej nazwy spaces. Jednakże, jeśli spróbujemy użyć mut w tym
przypadku, jak pokazano tutaj, otrzymamy błąd kompilacji:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}Błąd mówi, że nie wolno nam mutować typu zmiennej:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Teraz, gdy zbadaliśmy, jak działają zmienne, przyjrzyjmy się innym typom danych, które mogą mieć.
Typy danych
Typy danych
Każda wartość w Ruście ma określony typ danych, który informuje Rusta, jaki rodzaj danych jest określany, aby wiedział, jak z nimi pracować. Przyjrzymy się dwóm podzbiorom typów danych: skalarnym i złożonym.
Pamiętaj, że Rust jest językiem statycznie typowanym, co oznacza, że musi
znać typy wszystkich zmiennych w czasie kompilacji. Kompilator zazwyczaj może
wywnioskować, jakiego typu chcemy użyć, na podstawie wartości i sposobu jej
użycia. W przypadkach, gdy możliwych jest wiele typów, np. gdy konwertowaliśmy
String na typ numeryczny za pomocą parse w sekcji „Porównywanie strzału z
tajną liczbą”
w Rozdziale 2, musimy dodać adnotację typu, taką jak ta:
#![allow(unused)]
fn main() {
let guess: u32 = "42".parse().expect("Not a number!");
}Jeśli nie dodamy adnotacji typu : u32 pokazanej w poprzednim kodzie, Rust
wyświetli następujący błąd, co oznacza, że kompilator potrzebuje od nas więcej
informacji, aby wiedzieć, jakiego typu chcemy użyć:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Zobaczysz różne adnotacje typów dla innych typów danych.
Typy skalarne
Typ skalarny reprezentuje pojedynczą wartość. Rust ma cztery główne typy skalarne: liczby całkowite, liczby zmiennoprzecinkowe, wartości boolowskie i znaki. Możesz je rozpoznać z innych języków programowania. Przejdźmy do tego, jak działają w Rust.
Typy całkowite
Liczba całkowita to liczba bez części ułamkowej. Użyliśmy jednego typu
całkowitego w Rozdziale 2, typu u32. Ta deklaracja typu wskazuje, że wartość,
z którą jest skojarzona, powinna być niepodpisaną liczbą całkowitą (typy
całkowite ze znakiem zaczynają się od i zamiast u), która zajmuje 32 bity
pamięci. Tabela 3-1 pokazuje wbudowane typy całkowite w Rust. Możemy użyć
dowolnego z tych wariantów do zadeklarowania typu wartości całkowitej.
Tabela 3-1: Typy całkowite w Rust
| Długość | Ze znakiem | Bez znaku |
|---|---|---|
| 8-bitów | i8 | u8 |
| 16-bitów | i16 | u16 |
| 32-bitów | i32 | u32 |
| 64-bitów | i64 | u64 |
| 128-bitów | i128 | u128 |
| Zależne od architektury | isize | usize |
Każdy wariant może być ze znakiem lub bez znaku i ma wyraźny rozmiar. Ze znakiem i bez znaku odnoszą się do tego, czy liczba może być ujemna – inaczej mówiąc, czy liczba musi mieć znak (ze znakiem), czy zawsze będzie dodatnia i dlatego może być reprezentowana bez znaku (bez znaku). To jak pisanie liczb na papierze: gdy znak ma znaczenie, liczba jest pokazywana ze znakiem plus lub minus; jednak, gdy można bezpiecznie założyć, że liczba jest dodatnia, jest pokazywana bez znaku. Liczby ze znakiem są przechowywane za pomocą reprezentacji dopełnienia do dwóch.
Każdy wariant ze znakiem może przechowywać liczby od −(2n − 1) do
2n − 1 − 1 włącznie, gdzie n to liczba bitów, które używa ten wariant.
Tak więc i8 może przechowywać liczby od −(27) do 27 − 1,
co równa się −128 do 127. Warianty bez znaku mogą przechowywać liczby od 0 do
2n − 1, więc u8 może przechowywać liczby od 0 do 28 − 1,
co równa się 0 do 255.
Dodatkowo, typy isize i usize zależą od architektury komputera, na którym
działa Twój program: 64 bity, jeśli jesteś na architekturze 64-bitowej, i 32
bity, jeśli jesteś na architekturze 32-bitowej.
Literały całkowite można zapisywać w dowolnej z form pokazanych w tabeli 3-2.
Zauważ, że literały liczbowe, które mogą być wieloma typami numerycznymi,
dopuszczają sufiks typu, taki jak 57u8, do określenia typu. Literały
liczbowe mogą również używać _ jako wizualnego separatora, aby ułatwić
odczytanie liczby, np. 1_000, która będzie miała taką samą wartość, jakbyś
określił 1000.
Tabela 3-2: Literały całkowite w Rust
| Literały liczbowe | Przykład |
|---|---|
| Dziesiętne | 98_222 |
| Szesnastkowe | 0xff |
| Ósemkowe | 0o77 |
| Binarne | 0b1111_0000 |
Bajtowe (tylko u8) | b'A' |
Więc skąd wiesz, jakiego typu liczby całkowitej użyć? Jeśli nie jesteś pewien,
domyślne ustawienia Rusta są zazwyczaj dobrym punktem wyjścia: typy całkowite
domyślnie przyjmują i32. Główna sytuacja, w której użyłbyś isize lub
usize, to indeksowanie jakiegoś rodzaju kolekcji.
Przepełnienie liczby całkowitej
Załóżmy, że masz zmienną typu u8, która może przechowywać wartości od 0 do
255. Jeśli spróbujesz zmienić zmienną na wartość spoza tego zakresu, taką jak
256, nastąpi przepełnienie liczby całkowitej, co może skutkować jednym z
dwóch zachowań. Podczas kompilacji w trybie debugowania Rust zawiera
sprawdzenia przepełnienia liczby całkowitej, które powodują, że program
panikuje w czasie wykonywania, jeśli wystąpi takie zachowanie. Rust używa
terminu panicking, gdy program kończy działanie z błędem; omówimy paniki
bardziej szczegółowo w sekcji „Błędy nie do odzyskania za pomocą
panic!” w Rozdziale 9.
Podczas kompilacji w trybie wydania z flagą --release, Rust nie zawiera
sprawdzeń przepełnienia liczby całkowitej, które powodują paniki. Zamiast
tego, jeśli wystąpi przepełnienie, Rust wykonuje zawijanie dopełnienia do
dwóch. Krótko mówiąc, wartości większe niż maksymalna wartość, jaką może
przechowywać typ, „zawijają się” do minimalnej wartości, jaką może przechowywać
typ. W przypadku u8, wartość 256 staje się 0, wartość 257 staje się 1 i tak
dalej. Program nie będzie panikował, ale zmienna będzie miała wartość, która
prawdopodobnie nie jest tym, czego się spodziewałeś. Opieranie się na zachowaniu
zawijania przepełnienia liczby całkowitej jest uważane za błąd.
Aby jawnie obsłużyć możliwość przepełnienia, możesz użyć tych rodzin metod dostarczanych przez standardową bibliotekę dla prymitywnych typów liczbowych:
- Zawijaj we wszystkich trybach za pomocą metod
wrapping_*, takich jakwrapping_add. - Zwracaj wartość
None, jeśli wystąpi przepełnienie, za pomocą metodchecked_*. - Zwracaj wartość i wartość boolowską wskazującą, czy wystąpiło
przepełnienie, za pomocą metod
overflowing_*. - Saturuj przy minimalnych lub maksymalnych wartościach typu za pomocą metod
saturating_*.
Typy zmiennoprzecinkowe
Rust ma również dwa prymitywne typy dla liczb zmiennoprzecinkowych, które są
liczbami z punktami dziesiętnymi. Typy zmiennoprzecinkowe Rusta to f32 i f64,
które mają odpowiednio 32 i 64 bity. Domyślnym typem jest f64, ponieważ na
nowoczesnych procesorach ma on w przybliżeniu taką samą prędkość jak f32,
ale jest w stanie zapewnić większą precyzję. Wszystkie typy zmiennoprzecinkowe
są ze znakiem.
Oto przykład, który pokazuje liczby zmiennoprzecinkowe w akcji:
Nazwa pliku: src/main.rs
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}Liczby zmiennoprzecinkowe są reprezentowane zgodnie ze standardem IEEE-754.
Operacje numeryczne
Rust obsługuje podstawowe operacje matematyczne, których można oczekiwać dla
wszystkich typów liczbowych: dodawanie, odejmowanie, mnożenie, dzielenie i
reszta z dzielenia. Dzielenie całkowite obcina w kierunku zera do
najbliższej liczby całkowitej. Poniższy kod pokazuje, jak użyć każdej operacji
numerycznej w instrukcji let:
Nazwa pliku: src/main.rs
fn main() {
// dodawanie
let sum = 5 + 10;
// odejmowanie
let difference = 95.5 - 4.3;
// mnożenie
let product = 4 * 30;
// dzielenie
let quotient = 56.7 / 32.2;
let truncated = -5 / 3; // Wynosi -1
// reszta z dzielenia
let remainder = 43 % 5;
}Każde wyrażenie w tych instrukcjach używa operatora matematycznego i ocenia się do pojedynczej wartości, która następnie jest wiązana ze zmienną. Dodatek B zawiera listę wszystkich operatorów, dostarczanych przez Rusta.
Typ boolowski
Podobnie jak w większości innych języków programowania, typ boolowski w Rust
ma dwie możliwe wartości: true i false. Wartości boolowskie mają rozmiar
jednego bajta. Typ boolowski w Rust jest określany za pomocą bool. Na
przykład:
Nazwa pliku: src/main.rs
fn main() {
let t = true;
let f: bool = false; // z jawną adnotacją typu
}Głównym sposobem używania wartości boolowskich jest poprzez warunki, takie jak
wyrażenie if. Omówimy, jak działają wyrażenia if w Rust w sekcji „Sterowanie
przepływem”.
Typ znakowy
Typ char w Rust jest najbardziej prymitywnym typem alfabetycznym języka.
Oto kilka przykładów deklarowania wartości char:
Nazwa pliku: src/main.rs
fn main() {
let c = 'z';
let z: char = 'ℤ'; // z jawną adnotacją typu
let heart_eyed_cat = '😻';
}Zwróć uwagę, że literały char określamy pojedynczymi cudzysłowami, w
przeciwieństwie do literałów stringowych, które używają podwójnych cudzysłowów.
Typ char w Rust ma rozmiar 4 bajtów i reprezentuje skalarną wartość Unicode,
co oznacza, że może reprezentować znacznie więcej niż tylko ASCII. Litery
akcentowane; znaki chińskie, japońskie i koreańskie; emotikony; oraz spacje o
zerowej szerokości są w Ruście prawidłowymi wartościami char. Skalarne
wartości Unicode mieszczą się w zakresie od U+0000 do U+D7FF oraz od U+E000
do U+10FFFF włącznie. Jednak „znak” nie jest tak naprawdę koncepcją w Unicode,
więc Twoja ludzka intuicja co do tego, czym jest „znak”, może nie pasować do
tego, czym jest char w Rust. Omówimy ten temat szczegółowo w sekcji
„Przechowywanie tekstu kodowanego UTF-8 za pomocą ciągów
znaków” w Rozdziale 8.
Typy złożone
Typy złożone mogą grupować wiele wartości w jeden typ. Rust ma dwa prymitywne typy złożone: krotki i tablice.
Typ krotki
Krotka to ogólny sposób grupowania wielu wartości o różnych typach w jeden typ złożony. Krotki mają stałą długość: po zadeklarowaniu nie mogą rosnąć ani kurczyć się.
Tworzymy krotkę, pisząc listę wartości oddzielonych przecinkami w nawiasach. Każda pozycja w krotce ma typ, a typy różnych wartości w krotce nie muszą być takie same. W tym przykładzie dodaliśmy opcjonalne adnotacje typów:
Nazwa pliku: src/main.rs
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}Zmienna tup wiąże się z całą krotką, ponieważ krotka jest traktowana jako
pojedynczy element złożony. Aby uzyskać poszczególne wartości z krotki, możemy
użyć dopasowania wzorców do dekonstrukcji wartości krotki, w ten sposób:
Nazwa pliku: src/main.rs
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}Ten program najpierw tworzy krotkę i wiąże ją ze zmienną tup. Następnie używa
wzorca z let, aby wziąć tup i zamienić ją w trzy oddzielne zmienne: x, y
i z. Nazywa się to dekonstrukcją, ponieważ rozbija pojedynczą krotkę na
trzy części. Na koniec program wypisuje wartość y, która wynosi 6.4.
Możemy również uzyskać dostęp do elementu krotki bezpośrednio, używając kropki
(.) następującej po indeksie wartości, do której chcemy uzyskać dostęp. Na
przykład:
Nazwa pliku: src/main.rs
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}Ten program tworzy krotkę x, a następnie uzyskuje dostęp do każdego elementu
krotki za pomocą ich odpowiednich indeksów. Podobnie jak w większości języków
programowania, pierwszy indeks w krotce to 0.
Krotka bez żadnych wartości ma specjalną nazwę, jednostka. Ta wartość i jej
odpowiedni typ są zapisywane jako () i reprezentują pustą wartość lub pusty
typ zwracany. Wyrażenia niejawnie zwracają wartość jednostkową, jeśli nie
zwracają żadnej innej wartości.
Typ tablicowy
Innym sposobem posiadania kolekcji wielu wartości jest tablica. W przeciwieństwie do krotki, każdy element tablicy musi mieć ten sam typ. W przeciwieństwie do tablic w niektórych innych językach, tablice w Rust mają stałą długość.
Wartości w tablicy zapisujemy jako listę oddzieloną przecinkami w nawiasach kwadratowych:
Nazwa pliku: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
}Tablice są przydatne, gdy chcesz, aby dane były alokowane na stosie, tak jak inne typy, które widzieliśmy do tej pory, a nie na stercie (omówimy stos i sterę dokładniej w Rozdziale 4) lub gdy chcesz zapewnić, że zawsze będziesz mieć stałą liczbę elementów. Tablica nie jest jednak tak elastyczna jak typ wektora. Wektor to podobny typ kolekcji dostarczany przez standardową bibliotekę, który może rosnąć lub kurczyć się w rozmiarze, ponieważ jego zawartość znajduje się na stercie. Jeśli nie masz pewności, czy użyć tablicy, czy wektora, prawdopodobnie powinieneś użyć wektora. Rozdział 8 omawia wektory bardziej szczegółowo.
Jednak tablice są bardziej przydatne, gdy wiesz, że liczba elementów nie będzie musiała się zmieniać. Na przykład, jeśli używałbyś nazw miesięcy w programie, prawdopodobnie użyłbyś tablicy, a nie wektora, ponieważ wiesz, że zawsze będzie zawierać 12 elementów:
#![allow(unused)]
fn main() {
let months = ["Styczeń", "Luty", "Marzec", "Kwiecień", "Maj", "Czerwiec", "Lipiec",
"Sierpień", "Wrzesień", "Październik", "Listopad", "Grudzień"];
}Typ tablicy zapisujesz, używając nawiasów kwadratowych z typem każdego elementu, średnika, a następnie liczby elementów w tablicy, w ten sposób:
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}Tutaj i32 jest typem każdego elementu. Po średniku liczba 5 wskazuje, że
tablica zawiera pięć elementów.
Możesz również zainicjalizować tablicę tak, aby zawierała tę samą wartość dla każdego elementu, określając wartość początkową, po której następuje średnik, a następnie długość tablicy w nawiasach kwadratowych, jak pokazano tutaj:
#![allow(unused)]
fn main() {
let a = [3; 5];
}Tablica o nazwie a będzie zawierała 5 elementów, z których wszystkie
początkowo zostaną ustawione na wartość 3. Jest to to samo, co napisanie
let a = [3, 3, 3, 3, 3];, ale w bardziej zwięzły sposób.
Dostęp do elementów tablicy
Tablica to pojedynczy blok pamięci o znanej, stałej wielkości, który może być alokowany na stosie. Możesz uzyskać dostęp do elementów tablicy za pomocą indeksowania, w ten sposób:
Nazwa pliku: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0];
let second = a[1];
}W tym przykładzie zmienna o nazwie first otrzyma wartość 1, ponieważ jest
to wartość pod indeksem [0] w tablicy. Zmienna o nazwie second otrzyma
wartość 2 z indeksu [1] w tablicy.
Nieprawidłowy dostęp do elementów tablicy
Zobaczmy, co się stanie, jeśli spróbujesz uzyskać dostęp do elementu tablicy, który wykracza poza jej koniec. Powiedzmy, że uruchamiasz ten kod, podobny do gry w zgadywanie z Rozdziału 2, aby uzyskać indeks tablicy od użytkownika:
Nazwa pliku: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}Ten kod kompiluje się pomyślnie. Jeśli uruchomisz ten kod za pomocą
cargo run i wprowadzisz 0, 1, 2, 3 lub 4, program wyświetli
odpowiednią wartość pod tym indeksem w tablicy. Jeśli zamiast tego wprowadzisz
liczbę wykraczającą poza koniec tablicy, taką jak 10, zobaczysz dane wyjściowe
podobne do tego:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Program spowodował błąd wykonawczy w momencie użycia nieprawidłowej wartości w
operacji indeksowania. Program zakończył działanie z komunikatem o błędzie i
nie wykonał końcowej instrukcji println!. Kiedy próbujesz uzyskać dostęp do
elementu za pomocą indeksowania, Rust sprawdzi, czy podany indeks jest mniejszy
niż długość tablicy. Jeśli indeks jest większy lub równy długości, Rust
spanikuje. To sprawdzenie musi nastąpić w czasie wykonania, szczególnie w tym
przypadku, ponieważ kompilator nie jest w stanie wiedzieć, jaką wartość
użytkownik wprowadzi, gdy uruchomi kod później.
Jest to przykład działania zasad bezpieczeństwa pamięci Rusta. W wielu niskopoziomowych językach ten rodzaj sprawdzenia nie jest wykonywany, a gdy podasz nieprawidłowy indeks, można uzyskać dostęp do nieprawidłowej pamięci. Rust chroni Cię przed tego rodzaju błędami, natychmiast kończąc działanie, zamiast pozwalać na dostęp do pamięci i kontynuować. Rozdział 9 omawia więcej o obsłudze błędów w Rust i o tym, jak pisać czytelny, bezpieczny kod, który ani nie panikuje, ani nie pozwala na dostęp do nieprawidłowej pamięci.
Funkcje
Funkcje
Funkcje są powszechne w kodzie Rusta. Widziałeś już jedną z
najważniejszych funkcji w języku: funkcję main, która jest punktem wejścia
wielu programów. Widziałeś również słowo kluczowe fn, które pozwala
deklarować nowe funkcje.
Kod Rusta używa snake case jako konwencjonalnego stylu dla nazw funkcji i zmiennych, w którym wszystkie litery są małe, a podkreślenia oddzielają słowa. Oto program, który zawiera przykładową definicję funkcji:
Nazwa pliku: src/main.rs
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Inna funkcja.");
}Definiujemy funkcję w Ruście, wpisując fn po której następuje nazwa funkcji i
zestaw nawiasów. Nawiasy klamrowe informują kompilator, gdzie zaczyna się i
kończy ciało funkcji.
Możemy wywołać dowolną zdefiniowaną przez nas funkcję, wpisując jej nazwę,
a następnie zestaw nawiasów. Ponieważ another_function jest zdefiniowana w
programie, może być wywołana z wewnątrz funkcji main. Zauważ, że zdefiniowaliśmy
another_function po funkcji main w kodzie źródłowym; mogliśmy ją również
zdefiniować wcześniej. Rust nie dba o to, gdzie definiujesz swoje funkcje,
a jedynie o to, czy są zdefiniowane w zasięgu, który może być widoczny dla
wywołującego.
Utwórzmy nowy projekt binarny o nazwie functions, aby dokładniej zbadać
funkcje. Umieść przykład another_function w src/main.rs i uruchom go.
Ppowinien pojawić się następujący wynik:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Inna funkcja.
Wiersze wykonują się w kolejności, w jakiej pojawiają się w funkcji main.
Najpierw wypisuje się komunikat „Witaj, świecie!”, a następnie wywoływana jest
another_function i wypisuje się jej komunikat.
Parametry
Możemy definiować funkcje tak, aby miały parametry, które są specjalnymi zmiennymi będącymi częścią sygnatury funkcji. Gdy funkcja ma parametry, można podać jej konkretne wartości dla tych parametrów. Technicznie, konkretne wartości nazywane są argumentami, ale w potocznej rozmowie ludzie mają skłonność do używania słów parametr i argument zamiennie dla zmiennych w definicji funkcji lub konkretnych wartości przekazywanych podczas wywoływania funkcji.
W tej wersji another_function dodajemy parametr:
Nazwa pliku: src/main.rs
fn main() {
another_function(5);
}
fn another_function(x: i32) {
println!("Wartość x to: {x}");
}Spróbuj uruchomić ten program; powinieneś uzyskać następujący wynik:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
Wartość x to: 5
Deklaracja another_function ma jeden parametr o nazwie x. Typ x jest
określony jako i32. Kiedy przekazujemy 5 do another_function, makro
println! umieszcza 5 tam, gdzie w ciągu formatującym znajdowały się nawiasy
klemrowe zawierające x.
W sygnaturach funkcji musisz zadeklarować typ każdego parametru. Jest to świadoma decyzja w projekcie Rusta: Wymaganie adnotacji typów w definicjach funkcji oznacza, że kompilator prawie nigdy nie potrzebuje, abyś używał ich w innym miejscu w kodzie, aby zrozumieć, jaki typ masz na myśli. Kompilator jest również w stanie dostarczyć bardziej pomocne komunikaty o błędach, jeśli wie, jakich typów oczekuje funkcja.
Podczas definiowania wielu parametrów, oddziel deklaracje parametrów przecinkami, w ten sposób:
Nazwa pliku: src/main.rs
fn main() {
print_labeled_measurement(5, 'h');
}
fn print_labeled_measurement(value: i32, unit_label: char) {
println!("Pomiar to: {value}{unit_label}");
}Ten przykład tworzy funkcję o nazwie print_labeled_measurement z dwoma
parametrami. Pierwszy parametr ma nazwę value i jest typu i32. Drugi ma
nazwę unit_label i jest typu char. Funkcja następnie wypisuje tekst
zawierający zarówno value, jak i unit_label.
Spróbuj uruchomić ten kod. Zastąp program znajdujący się obecnie w pliku
src/main.rs projektu functions poprzednim przykładem i uruchom go za
pomocą cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
Pomiar to: 5h
Ponieważ wywołaliśmy funkcję z 5 jako wartością dla value i 'h' jako
wartością dla unit_label, wyjście programu zawiera te wartości.
Instrukcje i wyrażenia
Ciała funkcji składają się z serii instrukcji, opcjonalnie zakończonych wyrażeniem. Do tej pory omówione przez nas funkcje nie zawierały końcowego wyrażenia, ale widziałeś wyrażenie jako część instrukcji. Ponieważ Rust jest językiem opartym na wyrażeniach, jest to ważne rozróżnienie do zrozumienia. Inne języki nie mają tych samych rozróżnień, więc przyjrzyjmy się, czym są instrukcje i wyrażenia oraz jak ich różnice wpływają na ciała funkcji.
- Instrukcje to polecenia, które wykonują jakąś akcję i nie zwracają wartości.
- Wyrażenia obliczają się do wartości wynikowej.
Przyjrzyjmy się kilku przykładom.
W rzeczywistości już używaliśmy instrukcji i wyrażeń. Tworzenie zmiennej i
przypisywanie jej wartości za pomocą słowa kluczowego let jest instrukcją.
W Listingu 3-1, let y = 6; to instrukcja.
fn main() {
let y = 6;
}Definicje funkcji to również instrukcje; cały poprzedni przykład sam w sobie jest instrukcją. (Jak wkrótce zobaczymy, wywoływanie funkcji nie jest instrukcją.)
Instrukcje nie zwracają wartości. Dlatego nie możesz przypisać instrukcji
let do innej zmiennej, tak jak próbuje to zrobić poniższy kod; otrzymasz błąd:
Nazwa pliku: src/main.rs
fn main() {
let x = (let y = 6);
}Po uruchomieniu tego programu otrzymasz następujący błąd:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
Instrukcja let y = 6 nie zwraca wartości, więc nie ma nic, do czego x
mogłoby się związać. Różni się to od tego, co dzieje się w innych językach,
takich jak C i Ruby, gdzie przypisanie zwraca wartość przypisania. W tych
językach można napisać x = y = 6 i sprawić, że zarówno x, jak i y będą
miały wartość 6; tak nie jest w Ruście.
Wyrażenia obliczają się do wartości i stanowią większość pozostałego kodu,
który będziesz pisać w Ruście. Rozważ operację matematyczną, taką jak 5 + 6,
która jest wyrażeniem, które oblicza się do wartości 11. Wyrażenia mogą być
częścią instrukcji: W Listingu 3-1, 6 w instrukcji let y = 6; jest
wyrażeniem, które oblicza się do wartości 6. Wywoływanie funkcji jest
wyrażeniem. Wywoływanie makra jest wyrażeniem. Nowy blok zasięgu utworzony za
pomocą nawiasów klamrowych jest wyrażeniem, na przykład:
Nazwa pliku: src/main.rs
fn main() {
let y = {
let x = 3;
x + 1
};
println!("Wartość y to: {y}");
}To wyrażenie:
{
let x = 3;
x + 1
}jest blokiem, który w tym przypadku oblicza się do 4. Ta wartość zostaje
związana z y jako część instrukcji let. Zauważ wiersz x + 1 bez średnika
na końcu, co różni się od większości dotychczas widzianych wierszy. Wyrażenia
nie zawierają końcowych średników. Jeśli dodasz średnik na końcu wyrażenia,
zmienisz je w instrukcję, a wtedy nie zwróci ono wartości. Miej to na uwadze,
gdy będziesz dalej poznawać wartości zwracane przez funkcje i wyrażenia.
Funkcje zwracające wartości
Funkcje mogą zwracać wartości do wywołującego je kodu. Nie nazywamy wartości
zwracanych, ale musimy zadeklarować ich typ po strzałce (->). W Ruście,
wartość zwracana przez funkcję jest synonimem wartości ostatniego wyrażenia w
bloku ciała funkcji. Możesz zwrócić wartość wcześniej z funkcji, używając
słowa kluczowego return i określając wartość, ale większość funkcji zwraca
ostatnie wyrażenie niejawnie. Oto przykład funkcji, która zwraca wartość:
Nazwa pliku: src/main.rs
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("Wartość x to: {x}");
}Nie ma wywołań funkcji, makr, ani nawet instrukcji let w funkcji five —
tylko sama liczba 5. To jest całkowicie poprawna funkcja w Ruście.
Zauważ, że typ zwracany funkcji jest również określony jako -> i32.
Spróbuj uruchomić ten kod; wyjście powinno wyglądać tak:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
Wartość x to: 5
5 w five jest wartością zwracaną przez funkcję, dlatego typ zwracany to
i32. Zbadajmy to bardziej szczegółowo. Są tu dwa ważne aspekty:
Po pierwsze, wiersz let x = five(); pokazuje, że używamy wartości
zwracanej przez funkcję do inicjalizacji zmiennej. Ponieważ funkcja five
zwraca 5, ten wiersz jest równoważny z następującym:
#![allow(unused)]
fn main() {
let x = 5;
}Po drugie, funkcja five nie ma parametrów i definiuje typ wartości
zwracanej, ale ciało funkcji to samotne 5 bez średnika, ponieważ jest to
wyrażenie, którego wartość chcemy zwrócić.
Przyjrzyjmy się innemu przykładowi:
Nazwa pliku: src/main.rs
fn main() {
let x = plus_one(5);
println!("Wartość x to: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1
}Uruchomienie tego kodu wypisze Wartość x to: 6. Ale co się stanie, jeśli
umieścimy średnik na końcu wiersza zawierającego x + 1, zmieniając go z
wyrażenia w instrukcję?
Nazwa pliku: src/main.rs
fn main() {
let x = plus_one(5);
println!("Wartość x to: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}Skompilowanie tego kodu spowoduje błąd, jak następuje:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Główny komunikat o błędzie, mismatched types (niezgodne typy), ujawnia
sedno problemu z tym kodem. Definicja funkcji plus_one mówi, że zwróci i32,
ale instrukcje nie obliczają się do wartości, co jest wyrażone przez (),
typ jednostkowy. Dlatego nic nie jest zwracane, co jest sprzeczne z definicją
funkcji i skutkuje błędem. W tym wyjściu Rust dostarcza komunikat, który być
może pomoże rozwiązać ten problem: sugeruje usunięcie średnika, co naprawiłoby
błąd.
Komentarze
Komentarze
Wszyscy programiści dążą do tego, aby ich kod był łatwy do zrozumienia, ale czasami wymagane jest dodatkowe wyjaśnienie. W takich przypadkach programiści pozostawiają komentarze w swoim kodzie źródłowym, które kompilator zignoruje, ale które osoby czytające kod źródłowy mogą uznać za przydatne.
Oto prosty komentarz:
#![allow(unused)]
fn main() {
// witaj, świecie
}W Ruście idiomatyczny styl komentarzy rozpoczyna komentarz dwoma ukośnikami,
a komentarz trwa do końca linii. W przypadku komentarzy, które rozciągają się
poza jedną linię, należy umieścić // na każdej linii, w ten sposób:
#![allow(unused)]
fn main() {
// Więc robimy tutaj coś skomplikowanego, na tyle długiego, że potrzebujemy
// wielu linii komentarzy, żeby to zrobić! Uff! Mamy nadzieję, że ten komentarz
// wyjaśni, co się dzieje.
}Komentarze mogą być również umieszczane na końcu wierszy zawierających kod:
Nazwa pliku: src/main.rs
fn main() {
let lucky_number = 7; // Czuję się dzisiaj szczęściarzem
}Ale częściej zobaczysz je używane w tym formacie, z komentarzem w osobnej linii powyżej kodu, który opisuje:
Nazwa pliku: src/main.rs
fn main() {
// Czuję się dzisiaj szczęściarzem
let lucky_number = 7;
}Rust ma również inny rodzaj komentarzy, komentarze dokumentacyjne, które omówimy w sekcji „Publikowanie skrzynki na Crates.io” w Rozdziale 14.
Przepływ sterowania
Przepływ sterowania
Możliwość uruchomienia części kodu w zależności od tego, czy warunek jest
true, oraz możliwość wielokrotnego uruchamiania części kodu, dopóki warunek
jest true, to podstawowe bloki konstrukcyjne w większości języków
programowania. Najczęstsze konstrukcje, które pozwalają kontrolować przepływ
wykonania kodu Rusta, to wyrażenia if i pętle.
Wyrażenia if
Wyrażenie if pozwala rozgałęziać kod w zależności od warunków. Podajesz
warunek, a następnie stwierdzasz: „Jeśli ten warunek jest spełniony, uruchom
ten blok kodu. Jeśli warunek nie jest spełniony, nie uruchamiaj tego bloku
kodu.”
Utwórz nowy projekt o nazwie branches w katalogu projects, aby zbadać
wyrażenie if. W pliku src/main.rs wprowadź następujący kod:
Nazwa pliku: src/main.rs
fn main() {
let number = 3;
if number < 5 {
println!("warunek był prawdziwy");
} else {
println!("warunek był fałszywy");
}
}Wszystkie wyrażenia if zaczynają się od słowa kluczowego if, po którym
następuje warunek. W tym przypadku warunek sprawdza, czy zmienna number ma
wartość mniejszą niż 5. Blok kodu do wykonania, jeśli warunek jest true,
umieszczamy bezpośrednio po warunku w nawiasach klamrowych. Bloki kodu
powiązane z warunkami w wyrażeniach if są czasami nazywane ramionami,
podobnie jak ramiona w wyrażeniach match, które omówiliśmy w sekcji
„Porównywanie zgadywanej liczby z tajną
liczbą” w
Rozdziale 2.
Opcjonalnie możemy również dołączyć wyrażenie else, co tutaj zrobiliśmy, aby
podać programowi alternatywny blok kodu do wykonania, jeśli warunek oceni się
na false. Jeśli nie podasz wyrażenia else, a warunek jest false,
program po prostu pominie blok if i przejdzie do następnej części kodu.
Spróbuj uruchomić ten kod; powinieneś zobaczyć następujący wynik:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
warunek był prawdziwy
Spróbujmy zmienić wartość number na taką, która sprawi, że warunek będzie
false, aby zobaczyć, co się stanie:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Uruchom program ponownie i spójrz na wynik:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
warunek był fałszywy
Warto również zauważyć, że warunek w tym kodzie musi być typu bool.
Jeśli warunek nie jest typu bool, otrzymamy błąd. Na przykład, spróbuj
uruchomić następujący kod:
Nazwa pliku: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}Warunek if tym razem oblicza się do wartości 3, a Rust zwraca błąd:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Błąd wskazuje, że Rust oczekiwał bool, ale otrzymał liczbę całkowitą.
W przeciwieństwie do języków takich jak Ruby i JavaScript, Rust nie będzie
automatycznie próbował konwertować typów niebędących bool na bool.
Musisz być jawny i zawsze dostarczać if z wartością bool jako warunkiem.
Jeśli chcemy, aby blok kodu if był uruchamiany tylko wtedy, gdy liczba nie
jest równa 0, na przykład, możemy zmienić wyrażenie if na następujące:
Nazwa pliku: src/main.rs
fn main() {
let number = 3;
if number != 0 {
println!("number było czymś innym niż zero");
}
}Uruchomienie tego kodu wypisze number było czymś innym niż zero.
Obsługa wielu warunków za pomocą else if
Możesz użyć wielu warunków, łącząc if i else w wyrażeniu else if.
Na przykład:
Nazwa pliku: src/main.rs
fn main() {
let number = 6;
if number % 4 == 0 {
println!("liczba jest podzielna przez 4");
} else if number % 3 == 0 {
println!("liczba jest podzielna przez 3");
} else if number % 2 == 0 {
println!("liczba jest podzielna przez 2");
} else {
println!("liczba nie jest podzielna przez 4, 3 ani 2");
}
}Ten program może podążyć czterema możliwymi ścieżkami. Po jego uruchomieniu powinieneś zobaczyć następujący wynik:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
liczba jest podzielna przez 3
Kiedy ten program się wykonuje, sprawdza kolejno każde wyrażenie if i
wykonuje pierwszy blok, dla którego warunek ocenia się na true. Zauważ, że
mimo że 6 jest podzielne przez 2, nie widzimy wyjścia liczba jest podzielna przez 2, ani tekstu liczba nie jest podzielna przez 4, 3 ani 2 z bloku
else. Dzieje się tak, ponieważ Rust wykonuje blok tylko dla pierwszego
warunku true, a gdy tylko znajdzie taki, nie sprawdza już reszty.
Zbyt wiele wyrażeń else if może zaśmiecać kod, więc jeśli masz ich więcej niż
jeden, możesz chcieć refaktoryzować swój kod. Rozdział 6 opisuje potężną
konstrukcję rozgałęziającą Rusta o nazwie match dla takich przypadków.
Używanie if w instrukcji let
Ponieważ if jest wyrażeniem, możemy go użyć po prawej stronie instrukcji
let, aby przypisać wynik do zmiennej, jak w Listingu 3-2.
fn main() {
let condition = true;
let number = if condition { 5 } else { 6 };
println!("Wartość liczby to: {number}");
}Zmienna number zostanie związana z wartością na podstawie wyniku wyrażenia
if. Uruchom ten kod, aby zobaczyć, co się stanie:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
Wartość liczby to: 5
Pamiętaj, że bloki kodu oceniają się do ostatniego w nich wyrażenia, a same
liczby są również wyrażeniami. W tym przypadku wartość całego wyrażenia if
zależy od tego, który blok kodu zostanie wykonany. Oznacza to, że wartości,
które potencjalnie mogą być wynikami z każdego ramienia if, muszą być tego
samego typu; w Listingu 3-2 wyniki zarówno ramienia if, jak i ramienia
else były liczbami całkowitymi i32. Jeśli typy nie pasują do siebie, jak w
następującym przykładzie, otrzymamy błąd:
Nazwa pliku: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "sześć" };
println!("Wartość liczby to: {number}");
}Kiedy spróbujemy skompilować ten kod, otrzymamy błąd. Ramiona if i else
mają niezgodne typy wartości, a Rust dokładnie wskazuje, gdzie znaleźć problem
w programie:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
Wyrażenie w bloku if oblicza się do liczby całkowitej, a wyrażenie w bloku
else oblicza się do ciągu znaków. To nie zadziała, ponieważ zmienne muszą
mieć pojedynczy typ, a Rust musi wiedzieć jednoznacznie w czasie kompilacji,
jakiego typu jest zmienna number. Znajomość typu number pozwala
kompilatorowi sprawdzić, czy typ jest prawidłowy wszędzie tam, gdzie używamy
number. Rust nie byłby w stanie tego zrobić, gdyby typ number był
określany tylko w czasie działania; kompilator byłby bardziej złożony i dawałby
mniej gwarancji co do kodu, gdyby musiał śledzić wiele hipotetycznych typów
dla dowolnej zmiennej.
Powtarzanie z pętlami
Często przydatne jest wielokrotne wykonanie bloku kodu. Do tego zadania Rust udostępnia kilka pętli, które będą wykonywać kod wewnątrz ciała pętli do końca, a następnie natychmiast wrócą na początek. Aby poeksperymentować z pętlami, utwórzmy nowy projekt o nazwie loops.
Rust ma trzy rodzaje pętli: loop, while i for. Spróbujmy każdej z nich.
Powtarzanie kodu za pomocą loop
Słowo kluczowe loop mówi Rustowi, aby wykonywał blok kodu w kółko, albo w
nieskończoność, albo dopóki jawnie nie powiesz mu, aby się zatrzymał.
Jako przykład, zmień plik src/main.rs w katalogu loops tak, aby wyglądał tak:
Nazwa pliku: src/main.rs
fn main() {
loop {
println!("znowu!");
}
}Kiedy uruchomimy ten program, będziemy widzieć znowu! wypisywane w kółko
nieprzerwanie, dopóki nie zatrzymamy programu ręcznie. Większość terminali
obsługuje skrót klawiaturowy ctrl-C do przerwania
programu, który utknął w nieustannej pętli. Spróbuj:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
znowu!
znowu!
znowu!
znowu!
^Cznowu!
Symbol ^C reprezentuje miejsce, w którym naciśnąłeś ctrl-C.
Możesz, ale nie musisz, zobaczyć słowo znowu! wypisane po ^C, w zależności
od tego, w którym miejscu pętli znajdował się kod, gdy otrzymał sygnał
przerwania.
Na szczęście Rust udostępnia również sposób na wyjście z pętli za pomocą kodu.
Możesz umieścić słowo kluczowe break w pętli, aby powiedzieć programowi,
kiedy ma zakończyć wykonywanie pętli. Przypomnij sobie, że zrobiliśmy to w
grze w zgadywanie w sekcji „Zakończenie po poprawnym
odgadnięciu” w Rozdziale 2,
aby zakończyć program, gdy użytkownik wygrał grę, zgadując poprawną liczbę.
Używaliśmy również continue w grze w zgadywanie, co w pętli mówi programowi,
aby pominął pozostały kod w tej iteracji pętli i przeszedł do następnej
iteracji.
Zwracanie wartości z pętli
Jednym z zastosowań pętli loop jest ponowne wykonanie operacji, o której wiesz,
że może się nie powieść, na przykład sprawdzenie, czy wątek zakończył swoje
zadanie. Może być również konieczne przekazanie wyniku tej operacji poza pętlę
do reszty kodu. Aby to zrobić, możesz dodać wartość, którą chcesz zwrócić, po
wyrażeniu break, którego używasz do zatrzymania pętli; ta wartość zostanie
zwrócona z pętli, abyś mógł jej użyć, jak pokazano tutaj:
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("Wynik to {result}");
}Przed pętlą deklarujemy zmienną counter i inicjalizujemy ją na 0.
Następnie deklarujemy zmienną result, aby przechowywała wartość zwróconą z
pętli. W każdej iteracji pętli dodajemy 1 do zmiennej counter, a następnie
sprawdzamy, czy counter jest równe 10. Gdy tak jest, używamy słowa
kluczowego break z wartością counter * 2. Po pętli używamy średnika,
aby zakończyć instrukcję, która przypisuje wartość do result. Na koniec
wypisujemy wartość w result, która w tym przypadku wynosi 20.
Możesz również return z wnętrza pętli. Podczas gdy break tylko wychodzi z
bieżącej pętli, return zawsze wychodzi z bieżącej funkcji.
Rozróżnianie wielu pętli za pomocą etykiet pętli
Jeśli masz pętle zagnieżdżone w innych pętlach, break i continue dotyczą
aktualnie najbardziej wewnętrznej pętli. Możesz opcjonalnie określić etykietę
pętli dla pętli, którą następnie możesz użyć z break lub continue, aby
określić, że te słowa kluczowe dotyczą oznaczonej pętli, a nie najbardziej
wewnętrznej. Etykiety pętli muszą zaczynać się od pojedynczego cudzysłowu.
Oto przykład z dwoma zagnieżdżonymi pętlami:
fn main() {
let mut count = 0;
'counting_up: loop {
println!("licznik = {count}");
let mut remaining = 10;
loop {
println!("pozostało = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("Końcowy licznik = {count}");
}Zewnętrzna pętla ma etykietę 'counting_up i będzie liczyć od 0 do 2.
Wewnętrzna pętla bez etykiety liczy od 10 do 9. Pierwszy break, który nie
określa etykiety, zakończy tylko wewnętrzną pętlę. Instrukcja break 'counting_up; zakończy zewnętrzną pętlę. Ten kod wypisuje:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
licznik = 0
pozostało = 10
pozostało = 9
licznik = 1
pozostało = 10
pozostało = 9
licznik = 2
pozostało = 10
Końcowy licznik = 2
Upraszczanie pętli warunkowych za pomocą while
Program często musi oceniać warunek wewnątrz pętli. Dopóki warunek jest true,
pętla działa. Gdy warunek przestaje być true, program wywołuje break,
zatrzymując pętlę. Możliwe jest zaimplementowanie takiego zachowania za pomocą
połączenia loop, if, else i break; możesz spróbować tego teraz w
programie, jeśli chcesz. Jednak ten wzorzec jest tak powszechny, że Rust ma
wbudowaną konstrukcję językową dla niego, zwaną pętlą while. W Listingu 3-3
używamy while, aby zapętlić program trzy razy, odliczając za każdym razem,
a następnie, po pętli, wypisać wiadomość i zakończyć działanie.
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("START!!!");
}Ta konstrukcja eliminuje wiele zagnieżdżeń, które byłyby konieczne, gdybyś
używał loop, if, else i break, i jest bardziej przejrzysta.
Dopóki warunek ocenia się na true, kod działa; w przeciwnym razie wychodzi
z pętli.
Przeglądanie kolekcji za pomocą for
Możesz użyć konstrukcji while do iteracji po elementach kolekcji, takiej jak
tablica. Na przykład, pętla w Listingu 3-4 wypisuje każdy element w tablicy a.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("wartość to: {}", a[index]);
index += 1;
}
}Tutaj kod liczy elementy w tablicy. Zaczyna od indeksu 0, a następnie zapętla
się, aż osiągnie ostatni indeks w tablicy (czyli, gdy index < 5 przestaje być
true). Uruchomienie tego kodu wypisze każdy element w tablicy:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
wartość to: 10
wartość to: 20
wartość to: 30
wartość to: 40
wartość to: 50
Wszystkie pięć wartości tablicy pojawia się w terminalu, zgodnie z oczekiwaniami.
Mimo że index osiągnie wartość 5 w pewnym momencie, pętla przestaje się
wykonywać przed próbą pobrania szóstej wartości z tablicy.
Jednak to podejście jest podatne na błędy; moglibyśmy spowodować panikę
programu, jeśli wartość indeksu lub warunek testowy są niepoprawne. Na
przykład, jeśli zmieniłeś definicję tablicy a na cztery elementy, ale
zapomniałeś zaktualizować warunek na while index < 4, kod uległby panice.
Jest to również wolne, ponieważ kompilator dodaje kod wykonawczy do
wykonywania kontroli warunkowej, czy indeks znajduje się w granicach tablicy w
każdej iteracji pętli.
Jako bardziej zwięzłą alternatywę, możesz użyć pętli for i wykonać kod dla
każdego elementu w kolekcji. Pętla for wygląda jak kod w Listingu 3-5.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("wartość to: {element}");
}
}Kiedy uruchomimy ten kod, zobaczymy ten sam wynik co w Listingu 3-4. Co
ważniejsze, zwiększyliśmy teraz bezpieczeństwo kodu i wyeliminowaliśmy
możliwość błędów, które mogłyby wyniknąć z wyjścia poza koniec tablicy lub
niewystarczającego przeszukania i pominięcia niektórych elementów. Kod
maszynowy generowany z pętli for może być również bardziej wydajny,
ponieważ indeks nie musi być porównywany z długością tablicy w każdej
iteracji.
Używając pętli for, nie musiałbyś pamiętać o zmienianiu żadnego innego kodu,
gdybyś zmienił liczbę wartości w tablicy, tak jak to miało miejsce w metodzie
użytej w Listingu 3-4.
Bezpieczeństwo i zwięzłość pętli for sprawiają, że są one najczęściej
używaną konstrukcją pętli w Ruście. Nawet w sytuacjach, gdy chcesz uruchomić
jakiś kod określoną liczbę razy, jak w przykładzie odliczania, który używał
pętli while w Listingu 3-3, większość Rustaceanów użyłaby pętli for. Sposób
na to polegałby na użyciu Range, dostarczanego przez bibliotekę standardową,
który generuje wszystkie liczby w sekwencji, zaczynając od jednej liczby i
kończąc przed inną liczbą.
Oto jak wyglądałoby odliczanie za pomocą pętli for i innej metody, o której
jeszcze nie mówiliśmy, rev, do odwracania zakresu:
Nazwa pliku: src/main.rs
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("START!!!");
}Ten kod jest trochę ładniejszy, prawda?
Podsumowanie
Udało się! Dotarłeś do końca obszernego rozdziału: nauczyłeś się o zmiennych,
skalarnych i złożonych typach danych, funkcjach, komentarzach, wyrażeniach
if i pętlach! Aby poćwiczyć koncepcje omówione w tym rozdziale, spróbuj
zbudować programy, aby wykonać następujące zadania:
- Konwertowanie temperatur między stopniami Fahrenheita i Celsjusza.
- Generowanie n-tej liczby Fibonacciego.
- Wypisywanie tekstu kolędy „The Twelve Days of Christmas”, wykorzystując powtórzenia w piosence.
Kiedy będziesz gotowy, przejdziemy do koncepcji w Ruście, która nie występuje powszechnie w innych językach programowania: własności.
Zrozumienie własności
Własność to najbardziej unikalna cecha Rusta i ma głębokie implikacje dla pozostałej części języka. Umożliwia Rustowi gwarantowanie bezpieczeństwa pamięci bez potrzeby zbierania śmieci, dlatego ważne jest zrozumienie, jak działa własność. W tym rozdziale omówimy własność, a także kilka powiązanych funkcji: pożyczanie, wycinki i sposób, w jaki Rust rozmieszcza dane w pamięci.
Czym jest Własność?
Czym jest Własność?
Własność to zbiór zasad, które określają, w jaki sposób program w Rust zarządza pamięcią.Wszystkie programy muszą zarządzać sposobem, w jaki wykorzystują pamięć komputera podczas działania.Niektóre języki mają zbieranie śmieci, które regularnie szuka nieużywanej już pamięcipamięci podczas działania programu; w innych językach programista musi jawnieprzydzielić i zwolnić pamięć. Rust używa trzeciego podejścia: Pamięć jest zarządzanaprzez system własności z zestawem zasad, które kompilator sprawdza. Jeśliktórakolwiek z zasad zostanie naruszona, program się nie skompiluje. Żadna z funkcjiwłasności nie spowolni programu podczas jego działania.
Ponieważ własność jest nową koncepcją dla wielu programistów, przyzwyczajenie się do niej zajmuje trochę czasu.Dobrą wiadomością jest to, że im bardziej doświadczony będziesz w Rusti zasadach systemu własności, tym łatwiej będzie ci naturalnierozwinąć kod, który jest bezpieczny i wydajny. Trzymaj tak dalej!
Kiedy zrozumiesz własność, będziesz mieć solidne podstawy do zrozumieniafunkcji, które sprawiają, że Rust jest unikalny. W tym rozdziale poznasz własność,pracując nad przykładami, które koncentrują się na bardzo popularnej strukturze danych:ciągach znaków.
Stos i sterta
Wiele języków programowania nie wymaga od ciebie zbyt częstego myślenia o stosie i stercie.Ale w języku programowania systemowego, takim jak Rust, to, czy wartość znajduje się na stosie, czy na stercie,wpływa na zachowanie języka i na to, dlaczego musisz podejmować pewne decyzje.Części własności zostaną opisane w odniesieniu do stosu i stertyw dalszej części tego rozdziału, więc oto krótkie wyjaśnienie w przygotowaniu.
Zarówno stos, jak i sterta są częściami pamięci dostępnymi dla twojego kodu do użyciaw czasie wykonywania, ale są one strukturalizowane w różny sposób. Stos przechowuje wartościw kolejności, w jakiej je otrzymuje, i usuwa wartości w odwrotnej kolejności.Jest to określane jako ostatnie weszło, pierwsze wyszło (LIFO). Pomyśl o stosietalerzy: Kiedy dodajesz więcej talerzy, kładziesz je na wierzchu stosu, a kiedypotrzebujesz talerza, bierzesz jeden z góry. Dodawanie lub usuwanie talerzy ze środka lub z dołu nie działałoby tak dobrze!Dodawanie danych nazywa się wkładaniem na stos, a usuwanie danych nazywa się zdejmowaniem ze stosu.Wszystkie dane przechowywane na stosie muszą mieć znaną, stałą wielkość.Dane o nieznanym rozmiarze w czasie kompilacji lub rozmiarze, który może się zmienić, muszą być przechowywanena stercie.
Sterta jest mniej zorganizowana: Kiedy umieszczasz dane na stercie, żądaszwielkości miejsca. Alokator pamięci znajduje wolne miejsce na stercie,które jest wystarczająco duże, oznacza je jako zajęte i zwraca wskaźnik,który jest adresem tej lokalizacji. Ten proces nazywa się _alokacją na stercie_i jest czasami skracany do samego alokowania (wkładanie wartości na stos nie jest uważane za alokację).Ponieważ wskaźnik do sterty ma znaną, stałą wielkość, możesz przechowywać wskaźnik na stosie,ale kiedy chcesz uzyskać rzeczywiste dane, musisz podążać za wskaźnikiem.Pomyśl o tym, jakbyś siedział w restauracji. Kiedy wchodzisz, podajesz liczbęosób w twojej grupie, a host znajduje pusty stół, który pasuje do wszystkich,i prowadzi cię tam. Jeśli ktoś z twojej grupy spóźni się, może zapytać,gdzie zostałeś usadzony, aby cię znaleźć.
Wkładanie na stos jest szybsze niż alokowanie na stercie, ponieważ alokator nigdy nie musi szukaćmiejsca do przechowywania nowych danych; ta lokalizacja zawsze znajduje się na szczycie stosu.W porównaniu, alokacja miejsca na stercie wymaga więcej pracy, ponieważ alokator musinajpierw znaleźć wystarczająco dużo miejsca, aby pomieścić dane, a następnie wykonać księgowość,aby przygotować się do następnej alokacji.
Dostęp do danych na stercie jest zazwyczaj wolniejszy niż dostęp do danych na stosie,ponieważ musisz podążać za wskaźnikiem, aby tam dotrzeć. Współczesne procesorysą szybsze, jeśli mniej skaczą po pamięci. Kontynuując analogię,rozważ kelnera w restauracji przyjmującego zamówienia od wielu stolików.Najbardziej efektywne jest zebranie wszystkich zamówień przy jednym stole, zanim przejdzie się do następnego.Przyjmowanie zamówienia ze stołu A, następnie zamówienia ze stołu B,następnie ponownie z A, a następnie ponownie z B, byłoby znacznie wolniejszym procesem.W ten sam sposób procesor zazwyczaj lepiej wykonuje swoją pracę, jeślidziała na danych, które są blisko innych danych (jak na stosie),a nie dalej (jak może być na stercie).
Kiedy twój kod wywołuje funkcję, wartości przekazane do funkcji(w tym, potencjalnie, wskaźniki do danych na stercie) i zmienne lokalne funkcji sąwkładane na stos. Kiedy funkcja się kończy, te wartości są usuwane ze stosu.
Śledzenie, które części kodu używają jakich danych na stercie,minimalizowanie ilości zduplikowanych danych na stercie i czyszczenie nieużywanychdanych na stercie, aby nie zabrakło miejsca, to problemyczne kwestie,które adresuje system własności. Kiedy zrozumiesz własność,nie będziesz musiał często myśleć o stosie i stercie.Ale wiedząc, że głównym celem własności jest zarządzanie danymi na stercie,może to pomóc wyjaśnić, dlaczego działa to tak, jak działa.
Zasady Własności
Najpierw przyjrzyjmy się zasadom własności. Pamiętaj o nich,gdy będziemy przechodzić przez przykłady, które je ilustrują:
- Każda wartość w Rust ma właściciela.
- W danym momencie może być tylko jeden właściciel.
- Gdy właściciel wyjdzie poza zasięg, wartość zostanie usunięta (dropped).
Zasięg zmiennych
Teraz, gdy podstawowa składnia Rust jest już za nami, nie będziemy zawierać całego kodu fn main() { w przykładach, więc jeśli śledzisz, upewnij się, że umieściłeś poniższe przykłady ręcznie w funkcji main. W rezultacie nasze przykłady będą nieco bardziej zwięzłe, pozwalając nam skupić się na rzeczywistych szczegółach, a nie na kodzie szablonowym.
Jako pierwszy przykład własności, przyjrzymy się zasięgowi niektórych zmiennych. Zasięg to zakres w programie, w którym element jest ważny. Weźmy następującą zmienną:
#![allow(unused)]
fn main() {
let s = "hello";
}Zmienna s odnosi się do literału ciągu znaków, gdzie wartość ciągu jest zakodowana bezpośrednio w tekście naszego programu. Zmienna jest ważna od momentu jej zadeklarowania do końca bieżącego zasięgu. Listing 4-1 przedstawia program z komentarzami oznaczającymi, gdzie zmienna s byłaby ważna.
fn main() {
{ // s jest tutaj nieważne, ponieważ nie zostało jeszcze zadeklarowane
let s = "hello"; // s jest ważne od tego momentu
// rób coś z s
} // ten zasięg się skończył, a s jest już nieważne
}Innymi słowy, są tutaj dwa ważne momenty w czasie:
- Kiedy
swchodzi w zasięg, jest ważne. - Pozostaje ważne, dopóki nie wyjdzie z zasięgu.
Na tym etapie, związek między zasięgami a ważnością zmiennych jest podobny jak w innych językach programowania. Teraz będziemy budować na tym zrozumieniu, wprowadzając typ String.
Typ String
Aby zilustrować zasady własności, potrzebujemy typu danych, który jest bardziej złożony niż te, które omówiliśmy w sekcji „Typy danych” w Rozdziale 3. Wcześniej omówione typy mają znany rozmiar, mogą być przechowywane na stosie i zdejmowane ze stosu po zakończeniu ich zasięgu, oraz mogą być szybko i trywialnie kopiowane, aby utworzyć nową, niezależną instancję, jeśli inna część kodu musi użyć tej samej wartości w innym zasięgu. Chcemy jednak przyjrzeć się danym przechowywanym na stercie i zbadać, w jaki sposób Rust wie, kiedy te dane posprzątać, a typ String jest doskonałym przykładem.
Skoncentrujemy się na częściach String, które odnoszą się do własności. Te aspekty dotyczą również innych złożonych typów danych, niezależnie od tego, czy są dostarczane przez bibliotekę standardową, czy stworzone przez ciebie. Aspekty String niezwiązane z własnością omówimy w Rozdziale 8.
Widzieliśmy już literały ciągów znaków, gdzie wartość ciągu jest zakodowana na stałe w naszym programie. Literały ciągów znaków są wygodne, ale nie nadają się do każdej sytuacji, w której możemy chcieć użyć tekstu. Jednym z powodów jest to, że są one niezmienne. Inną przyczyną jest to, że nie każda wartość ciągu może być znana, gdy piszemy nasz kod: na przykład, co jeśli chcemy pobrać dane od użytkownika i je zapisać? Właśnie dla takich sytuacji Rust ma typ String. Ten typ zarządza danymi alokowanymi na stercie i jako taki jest w stanie przechowywać ilość tekstu, która jest nam nieznana w czasie kompilacji. Możesz utworzyć String z literału ciągu znaków za pomocą funkcji from, w ten sposób:
#![allow(unused)]
fn main() {
let s = String::from("hello");
}Operator podwójnego dwukropka :: pozwala nam na umieszczenie funkcji from w przestrzeni nazw typu String, zamiast używać nazwy takiej jak string_from. Więcej o tej składni omówimy w sekcji „Metody” w Rozdziale 5, oraz gdy będziemy mówić o przestrzeniach nazw z modułami w sekcji „Ścieżki do odwoływania się do elementu w drzewie modułów” w Rozdziale 7.
Tego rodzaju ciąg może być mutowalny:
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() dodaje literał do String
println!("{s}"); // to wyświetli `hello, world!`
}Więc, jaka jest tutaj różnica? Dlaczego String może być mutowalny, a literały nie? Różnica tkwi w sposobie, w jaki te dwa typy obsługują pamięć.
Pamięć i Alokacja
W przypadku literału ciągu znaków, znamy jego zawartość w czasie kompilacji, więc tekst jest zakodowany bezpośrednio w finalnym pliku wykonywalnym. Dlatego literały ciągów znaków są szybkie i wydajne. Ale te właściwości wynikają tylko z niezmienności literału ciągu znaków. Niestety, nie możemy umieścić bloku pamięci w pliku binarnym dla każdego fragmentu tekstu, którego rozmiar jest nieznany w czasie kompilacji i którego rozmiar może zmieniać się podczas działania programu.
Z typem String, aby obsługiwać zmienny, rozszerzalny fragment tekstu, musimy zaalokować na stercie ilość pamięci, nieznaną w czasie kompilacji, aby pomieścić zawartość. Oznacza to:
- Pamięć musi być żądana od alokatora pamięci w czasie wykonywania.
- Potrzebujemy sposobu na zwrócenie tej pamięci alokatorowi, gdy skończymy z naszym
String.
Ta pierwsza część jest wykonywana przez nas: Kiedy wywołujemy String::from, jego implementacja żąda potrzebnej pamięci. Jest to dość powszechne w językach programowania.
Jednak druga część jest inna. W językach z garbage collector (GC), GC śledzi i usuwa pamięć, która nie jest już używana, i nie musimy o tym myśleć. W większości języków bez GC, to nasza odpowiedzialność, aby zidentyfikować, kiedy pamięć nie jest już używana i wywołać kod, aby jawnie ją zwolnić, tak jak robiliśmy to, aby ją zażądać. Robienie tego poprawnie było historycznie trudnym problemem programistycznym. Jeśli zapomnimy, zmarnujemy pamięć. Jeśli zrobimy to zbyt wcześnie, będziemy mieć nieprawidłową zmienną. Jeśli zrobimy to dwukrotnie, to też jest błąd. Musimy sparować dokładnie jedną allocate z dokładnie jedną free.
Rust obiera inną ścieżkę: Pamięć jest automatycznie zwracana, gdy zmienna, która ją posiada, wyjdzie poza zasięg. Oto wersja naszego przykładu zasięgu z Listingu 4-1, używająca String zamiast literału ciągu znaków:
fn main() {
{
let s = String::from("hello"); // s jest ważne od tego momentu
// rób coś z s
} // ten zasięg się skończył, a s jest już
// nieważne
}Istnieje naturalny moment, w którym możemy zwrócić pamięć potrzebną naszej String alokatorowi: kiedy s wyjdzie poza zasięg. Kiedy zmienna wychodzi poza zasięg, Rust wywołuje dla nas specjalną funkcję. Funkcja ta nazywa się drop i to w niej autor String może umieścić kod do zwracania pamięci. Rust automatycznie wywołuje drop przy zamykającym nawiasie klamrowym.
Uwaga: W C++ ten wzorzec dealokowania zasobów na końcu życia elementu jest czasami nazywany Resource Acquisition Is Initialization (RAII). Funkcja
dropw Rust będzie ci znana, jeśli używałeś wzorców RAII.
Ten wzorzec ma głęboki wpływ na sposób pisania kodu w Rust. Może wydawać się prosty teraz, ale zachowanie kodu może być nieoczekiwane w bardziej skomplikowanych sytuacjach, gdy chcemy, aby wiele zmiennych używało danych, które zaalokowaliśmy na stercie. Przyjrzyjmy się teraz kilku z tych sytuacji.
Zmienne i Dane w Interakcji przez Przeniesienie (Move)
W Rust wiele zmiennych może wchodzić w interakcję z tymi samymi danymi na różne sposoby. Listing 4-2 przedstawia przykład użycia liczby całkowitej.
fn main() {
let x = 5;
let y = x;
}Prawdopodobnie możemy zgadnąć, co to robi: „Przypisz wartość 5 do x; następnie, utwórz kopię wartości z x i przypisz ją do y.” Mamy teraz dwie zmienne, x i y, i obie są równe 5. Tak właśnie się dzieje, ponieważ liczby całkowite są prostymi wartościami o znanym, stałym rozmiarze, a te dwie wartości 5 są umieszczane na stosie.
Teraz przyjrzyjmy się wersji String:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}Wygląda to bardzo podobnie, więc moglibyśmy założyć, że działałoby tak samo: to znaczy, że druga linia utworzyłaby kopię wartości z s1 i przypisała ją do s2. Ale tak się nie dzieje.
Przyjrzyj się Rysunkowi 4-1, aby zobaczyć, co dzieje się z String pod maską. String składa się z trzech części, pokazanych po lewej stronie: wskaźnika do pamięci, która przechowuje zawartość ciągu, długości i pojemności. Ta grupa danych jest przechowywana na stosie. Po prawej stronie znajduje się pamięć na stercie, która przechowuje zawartość.

Rysunek 4-1: Reprezentacja w pamięci String zawierającego wartość "hello" przypisaną do s1
Długość to ilość pamięci, w bajtach, którą aktualnie wykorzystuje zawartość String. Pojemność to całkowita ilość pamięci, w bajtach, którą String otrzymał od alokatora. Różnica między długością a pojemnością ma znaczenie, ale nie w tym kontekście, więc na razie można ją zignorować.
Kiedy przypisujemy s1 do s2, dane String są kopiowane, co oznacza, że kopiujemy wskaźnik, długość i pojemność, które znajdują się na stosie. Nie kopiujemy danych na stercie, do których odwołuje się wskaźnik. Innymi słowy, reprezentacja danych w pamięci wygląda jak na Rysunku 4-2.

Rysunek 4-2: Reprezentacja w pamięci zmiennej s2, która zawiera kopię wskaźnika, długości i pojemności s1
Reprezentacja nie wygląda jak na Rysunku 4-3, który przedstawiałby pamięć, gdyby Rust zamiast tego skopiował również dane na stercie. Gdyby Rust tak zrobił, operacja s2 = s1 mogłaby być bardzo kosztowna pod względem wydajności, gdyby dane na stercie były duże.

Rysunek 4-3: Inna możliwość tego, co s2 = s1 mógłby zrobić, gdyby Rust skopiował również dane ze sterty
Wcześniej powiedzieliśmy, że gdy zmienna wychodzi poza zasięg, Rust automatycznie wywołuje funkcję drop i zwalnia pamięć sterty dla tej zmiennej. Ale Rysunek 4-2 pokazuje, że oba wskaźniki danych wskazują na tę samą lokalizację. To jest problem: kiedy s2 i s1 wyjdą poza zasięg, oba będą próbowały zwolnić tę samą pamięć. Jest to znane jako błąd podwójnego zwolnienia (double free) i jest jednym z błędów bezpieczeństwa pamięci, o których wspomnieliśmy wcześniej. Dwukrotne zwolnienie pamięci może prowadzić do uszkodzenia pamięci, co potencjalnie może prowadzić do luk w zabezpieczeniach.
Aby zapewnić bezpieczeństwo pamięci, po linii let s2 = s1;, Rust uważa s1 za już nieprawidłowe. Dlatego Rust nie musi zwalniać niczego, gdy s1 wychodzi poza zasięg. Sprawdź, co się stanie, gdy spróbujesz użyć s1 po utworzeniu s2; to nie zadziała:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Otrzymasz błąd podobny do tego, ponieważ Rust uniemożliwia użycie unieważnionej referencji:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Jeśli słyszałeś o pojęciach płytka kopia i głęboka kopia pracując z innymi językami, koncepcja kopiowania wskaźnika, długości i pojemności bez kopiowania danych prawdopodobnie brzmi jak tworzenie płytkiej kopii. Ale ponieważ Rust również unieważnia pierwszą zmienną, zamiast nazywać to płytką kopią, nazywa się to przeniesieniem. W tym przykładzie powiedzielibyśmy, że s1 zostało przeniesione do s2. Zatem to, co faktycznie się dzieje, pokazano na Rysunku 4-4.

Rysunek 4-4: Reprezentacja w pamięci po unieważnieniu s1
To rozwiązuje nasz problem! Gdy tylko s2 jest ważne, gdy wyjdzie ono poza zasięg, samo zwolni pamięć, i gotowe.
Dodatkowo, istnieje wynikająca z tego decyzja projektowa: Rust nigdy nie stworzy automatycznie „głębokich” kopii twoich danych. Dlatego wszelkie automatyczne kopiowanie można uznać za tanie pod względem wydajności czasu wykonania.
Zasięg i przypisanie
Odwrotność tego jest również prawdziwa dla związku między zasięgiem, własnością i zwalnianiem pamięci za pomocą funkcji drop. Kiedy przypisujesz całkowicie nową wartość do istniejącej zmiennej, Rust natychmiast wywoła drop i zwolni pamięć oryginalnej wartości. Rozważmy na przykład ten kod:
fn main() {
let mut s = String::from("hello");
s = String::from("ahoy");
println!("{s}, world!");
}Początkowo deklarujemy zmienną s i wiążemy ją z String o wartości "hello". Następnie, natychmiast tworzymy nowy String o wartości "ahoy" i przypisujemy go do s. W tym momencie nic nie odnosi się do oryginalnej wartości na stercie. Rysunek 4-5 ilustruje teraz dane stosu i sterty:

Rysunek 4-5: Reprezentacja w pamięci po całkowitym zastąpieniu wartości początkowej
Oryginalny ciąg znaków natychmiast wychodzi więc poza zasięg. Rust uruchomi na nim funkcję drop i jego pamięć zostanie natychmiast zwolniona. Kiedy na końcu wydrukujemy wartość, będzie ona wynosić „ahoy, world!”.
Zmienne i Dane w Interakcji przez Klonowanie (Clone)
Jeśli chcemy głęboko skopiować dane String ze sterty, a nie tylko dane ze stosu, możemy użyć wspólnej metody clone. Składnię metod omówimy w Rozdziale 5, ale ponieważ metody są wspólną cechą wielu języków programowania, prawdopodobnie widziałeś je już wcześniej.
Oto przykład metody clone w działaniu:
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");
}To działa bez problemów i wyraźnie tworzy zachowanie pokazane na Rysunku 4-3, gdzie dane na stercie są kopiowane.
Kiedy widzisz wywołanie clone, wiesz, że wykonywany jest jakiś dowolny kod i że ten kod może być kosztowny. To wizualny wskaźnik, że dzieje się coś innego.
Dane tylko na stosie: Kopia
Jest jeszcze jedna kwestia, o której jeszcze nie mówiliśmy. Ten kod używający liczb całkowitych — część z nich pokazana w Listingu 4-2 — działa i jest prawidłowy:
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}Ale ten kod wydaje się zaprzeczać temu, czego się właśnie nauczyliśmy: Nie mamy wywołania clone, ale x jest nadal ważne i nie zostało przeniesione do y.
Powodem jest to, że typy takie jak liczby całkowite, które mają znany rozmiar w czasie kompilacji, są przechowywane w całości na stosie, więc kopie rzeczywistych wartości są szybkie do wykonania. Oznacza to, że nie ma powodu, dla którego chcielibyśmy uniemożliwić x bycie ważnym po utworzeniu zmiennej y. Innymi słowy, nie ma tutaj różnicy między kopiowaniem głębokim a płytkim, więc wywołanie clone nie zrobiłoby nic innego niż zwykłe kopiowanie płytkie, i możemy to pominąć.
Rust posiada specjalną adnotację zwaną cechą Copy, którą możemy umieszczać na typach przechowywanych na stosie, tak jak to jest w przypadku liczb całkowitych (więcej o cechach omówimy w Rozdziale 10). Jeśli typ implementuje cechę Copy, zmienne, które jej używają, nie są przenoszone, lecz są trywialnie kopiowane, co sprawia, że pozostają ważne po przypisaniu do innej zmiennej.
Rust nie pozwoli nam zaadnotować typu jako Copy, jeśli typ, lub którakolwiek z jego części, zaimplementował cechę Drop. Jeśli typ potrzebuje, aby coś specjalnego się stało, gdy wartość wyjdzie poza zasięg, a my dodamy adnotację Copy do tego typu, otrzymamy błąd kompilacji. Aby dowiedzieć się, jak dodać adnotację Copy do swojego typu w celu zaimplementowania cechy, zobacz „Cechy pochodne” w Dodatku C.
Więc, jakie typy implementują cechę Copy? Aby być pewnym, możesz sprawdzić dokumentację dla danego typu, ale ogólnie rzecz biorąc, każda grupa prostych wartości skalarnych może implementować Copy, a nic, co wymaga alokacji lub jest jakąś formą zasobu, nie może implementować Copy. Oto niektóre typy, które implementują Copy:
- Wszystkie typy całkowite, takie jak
u32. - Typ boolowski,
bool, z wartościamitrueifalse. - Wszystkie typy zmiennoprzecinkowe, takie jak
f64. - Typ znakowy,
char. - Krotki, jeśli zawierają tylko typy, które również implementują
Copy. Na przykład(i32, i32)implementujeCopy, ale(i32, String)nie.
Własność i Funkcje
Mechanizmy przekazywania wartości do funkcji są podobne do tych, które występują przy przypisywaniu wartości do zmiennej. Przekazanie zmiennej do funkcji spowoduje przeniesienie lub skopiowanie, tak jak przypisanie. Listing 4-3 zawiera przykład z adnotacjami pokazującymi, gdzie zmienne wchodzą w zasięg i wychodzą z niego.
fn main() {
let s = String::from("hello"); // s wchodzi w zasięg
takes_ownership(s); // wartość s przenosi się do funkcji...
// ... i dlatego jest tutaj nieważna
let x = 5; // x wchodzi w zasięg
makes_copy(x); // Ponieważ i32 implementuje cechę Copy,
// x NIE przenosi się do funkcji,
// więc można używać x później.
} // Tutaj x wychodzi z zasięgu, potem s. Jednakże, ponieważ wartość s została przeniesiona,
// nic specjalnego się nie dzieje.
fn takes_ownership(some_string: String) { // some_string wchodzi w zasięg
println!("{some_string}");
} // Tutaj some_string wychodzi z zasięgu i wywoływane jest `drop`. Pamięć bazowa
// jest zwalniana.
fn makes_copy(some_integer: i32) { // some_integer wchodzi w zasięg
println!("{some_integer}");
} // Tutaj some_integer wychodzi z zasięgu. Nic specjalnego się nie dzieje.Jeśli spróbowalibyśmy użyć s po wywołaniu takes_ownership, Rust wyrzuciłby błąd kompilacji. Te statyczne sprawdzenia chronią nas przed błędami. Spróbuj dodać kod do main, który używa s i x, aby zobaczyć, gdzie można ich używać, a gdzie zasady własności uniemożliwiają to.
Wartości zwracane i zasięg
Zwracanie wartości może również przenosić własność. Listing 4-4 przedstawia przykład funkcji, która zwraca pewną wartość, z podobnymi adnotacjami jak te z Listingu 4-3.
fn main() {
let s1 = gives_ownership(); // gives_ownership przenosi swoją wartość
// zwracaną do s1
let s2 = String::from("hello"); // s2 wchodzi w zasięg
let s3 = takes_and_gives_back(s2); // s2 jest przenoszone do
// takes_and_gives_back, które również
// przenosi swoją wartość zwracaną do s3
} // Tutaj s3 wychodzi z zasięgu i jest usuwane. s2 zostało przeniesione, więc nic
// się nie dzieje. s1 wychodzi z zasięgu i jest usuwane.
fn gives_ownership() -> String { // gives_ownership przeniesie swoją
// wartość zwracaną do funkcji,
// która ją wywoła
let some_string = String::from("yours"); // some_string wchodzi w zasięg
some_string // some_string jest zwracane i
// przenosi się do funkcji
// wywołującej
}
// Ta funkcja przyjmuje String i zwraca String.
fn takes_and_gives_back(a_string: String) -> String {
// a_string wchodzi w
// zasięg
a_string // a_string jest zwracane i przenosi się do funkcji wywołującej
}Własność zmiennej zawsze podlega temu samemu wzorcowi: przypisanie wartości do innej zmiennej powoduje jej przeniesienie. Gdy zmienna zawierająca dane na stercie wyjdzie poza zasięg, wartość zostanie posprzątana przez drop, chyba że własność danych została przeniesiona do innej zmiennej.
Chociaż to działa, przejmowanie własności, a następnie zwracanie własności przy każdej funkcji jest trochę męczące. Co, jeśli chcemy pozwolić funkcji użyć wartości, ale nie przejmować własności? Jest to dość denerwujące, że wszystko, co przekazujemy, musi być również zwrócone, jeśli chcemy użyć tego ponownie, oprócz wszelkich danych wynikających z treści funkcji, które również możemy chcieć zwrócić.
Rust pozwala nam zwracać wiele wartości za pomocą krotki, jak pokazano w Listingu 4-5.
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("Długość '{s2}' wynosi {len}.");
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() zwraca długość String
(s, length)
}Ale to zbyt wiele ceremonii i dużo pracy dla koncepcji, która powinna być powszechna. Na szczęście Rust ma funkcję do używania wartości bez przenoszenia własności: referencje.
Referencje i Pożyczanie
Referencje i Pożyczanie
Problem z kodem krotki w Listingu 4-5 polega na tym, że musimy zwrócić String do funkcji wywołującej, abyśmy mogli nadal używać String po wywołaniu calculate_length, ponieważ String zostało przeniesione do calculate_length. Zamiast tego możemy dostarczyć referencję do wartości String. Referencja jest jak wskaźnik w tym sensie, że jest to adres, za którym możemy podążać, aby uzyskać dostęp do danych przechowywanych pod tym adresem; te dane są własnością innej zmiennej. W przeciwieństwie do wskaźnika, referencja gwarantuje, że wskazuje na ważną wartość określonego typu przez cały okres życia tej referencji.
Oto jak zdefiniować i użyć funkcji calculate_length, która jako parametr przyjmuje referencję do obiektu zamiast przejmować własność wartości:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("Długość '{s1}' wynosi {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Po pierwsze, zauważ, że cały kod krotki w deklaracji zmiennej i wartości zwracanej funkcji zniknął. Po drugie, zauważ, że przekazujemy &s1 do calculate_length i, w jej definicji, przyjmujemy &String zamiast String. Te ampersandy reprezentują referencje i pozwalają odwoływać się do pewnej wartości bez przejmowania jej własności. Rysunek 4-6 przedstawia tę koncepcję.

Rysunek 4-6: Diagram &String s wskazującego na String s1
Uwaga: Przeciwieństwem referencji za pomocą
&jest dereferencjowanie, które jest realizowane za pomocą operatora dereferencji,*. Zobaczymy kilka zastosowań operatora dereferencji w Rozdziale 8 i omówimy szczegóły dereferencji w Rozdziale 15.
Przyjrzyjmy się bliżej wywołaniu funkcji:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("Długość '{s1}' wynosi {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Składnia &s1 pozwala nam utworzyć referencję, która odnosi się do wartości s1, ale jej nie posiada. Ponieważ referencja nie jest jej właścicielem, wartość, na którą wskazuje, nie zostanie usunięta, gdy referencja przestanie być używana.
Podobnie, sygnatura funkcji używa & do wskazania, że typ parametru s jest referencją. Dodajmy kilka wyjaśniających adnotacji:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("Długość '{s1}' wynosi {len}.");
}
fn calculate_length(s: &String) -> usize { // s jest referencją do String
s.len()
} // Tutaj s wychodzi z zasięgu. Ale ponieważ s nie posiada własności tego,
// do czego się odnosi, String nie jest usuwane.Zasięg, w którym zmienna s jest ważna, jest taki sam jak zasięg każdego parametru funkcji, ale wartość wskazywana przez referencję nie jest usuwana, gdy s przestaje być używane, ponieważ s nie posiada własności. Gdy funkcje mają referencje jako parametry zamiast rzeczywistych wartości, nie będziemy musieli zwracać wartości, aby oddać własność, ponieważ nigdy jej nie posiadaliśmy.
Nazywamy czynność tworzenia referencji pożyczaniem. Jak w prawdziwym życiu, jeśli ktoś posiada coś, możesz to od niego pożyczyć. Kiedy skończysz, musisz to zwrócić. Nie jesteś jego właścicielem.
Więc co się stanie, jeśli spróbujemy zmodyfikować coś, co pożyczamy? Wypróbuj kod z Listingu 4-6. Uwaga, spoiler: To nie działa!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}Oto błąd:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Tak jak zmienne są domyślnie niezmienne, tak samo referencje. Nie wolno nam modyfikować czegoś, do czego mamy referencję.
Mutowalne referencje
Możemy naprawić kod z Listingu 4-6, aby umożliwić modyfikację pożyczonej wartości za pomocą kilku drobnych zmian, które zamiast tego używają mutowalnej referencji:
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}Najpierw zmieniamy s na mut. Następnie tworzymy mutowalną referencję za pomocą &mut s w miejscu wywołania funkcji change i aktualizujemy sygnaturę funkcji, aby akceptowała mutowalną referencję za pomocą some_string: &mut String. Dzięki temu bardzo jasno wynika, że funkcja change będzie mutować pożyczoną wartość.
Mutowalne referencje mają jedno duże ograniczenie: jeśli masz mutowalną referencję do wartości, nie możesz mieć żadnych innych referencji do tej wartości. Ten kod, który próbuje utworzyć dwie mutowalne referencje do s, zakończy się niepowodzeniem:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Oto błąd:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ten błąd mówi, że ten kod jest nieprawidłowy, ponieważ nie możemy pożyczyć s jako mutowalne więcej niż raz w tym samym czasie. Pierwsze mutowalne pożyczenie następuje w r1 i musi trwać, dopóki nie zostanie użyte w println!, ale między utworzeniem tej mutowalnej referencji a jej użyciem próbowaliśmy utworzyć kolejną mutowalną referencję w r2, która pożycza te same dane co r1.
Ograniczenie zapobiegające równoczesnemu posiadaniu wielu mutowalnych referencji do tych samych danych pozwala na mutację, ale w bardzo kontrolowany sposób. Jest to coś, z czym borykają się nowi Rustaceanowie, ponieważ większość języków pozwala mutować, kiedy tylko chcesz. Korzyścią z tego ograniczenia jest to, że Rust może zapobiegać wyścigom danych w czasie kompilacji. Wyścig danych jest podobny do warunku wyścigu i występuje, gdy zachodzą te trzy zachowania:
- Dwa lub więcej wskaźników uzyskuje dostęp do tych samych danych w tym samym czasie.
- Co najmniej jeden ze wskaźników jest używany do zapisu danych.
- Nie ma mechanizmu synchronizującego dostęp do danych.
Wyścigi danych powodują niezdefiniowane zachowanie i mogą być trudne do zdiagnozowania i naprawienia, gdy próbujesz je śledzić w czasie wykonania; Rust zapobiega temu problemowi, odmawiając kompilacji kodu z wyścigami danych!
Jak zawsze, możemy użyć nawiasów klamrowych do stworzenia nowego zasięgu, co pozwala na wiele mutowalnych referencji, ale nie jednoczesnych:
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 wychodzi z zasięgu tutaj, więc możemy stworzyć nową referencję bez problemów.
let r2 = &mut s;
}Rust narzuca podobną zasadę dla łączenia mutowalnych i niemutowalnych referencji. Ten kod powoduje błąd:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // bez problemu
let r2 = &s; // bez problemu
let r3 = &mut s; // DUŻY PROBLEM
println!("{r1}, {r2}, and {r3}");
}Oto błąd:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Uff! Nie możemy również mieć mutowalnej referencji, gdy mamy niezmienną referencję do tej samej wartości.
Użytkownicy referencji niezmiennej nie spodziewają się, że wartość nagle się zmieni! Jednakże, wiele referencji niezmiennych jest dozwolonych, ponieważ nikt, kto tylko odczytuje dane, nie ma możliwości wpływania na odczytywanie danych przez nikogo innego.
Zauważ, że zasięg referencji rozpoczyna się w miejscu jej wprowadzenia i trwa do ostatniego użycia tej referencji. Na przykład, ten kod skompiluje się, ponieważ ostatnie użycie referencji niezmiennych jest w println!, zanim zostanie wprowadzona referencja mutowalna:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // bez problemu
let r2 = &s; // bez problemu
println!("{r1} i {r2}");
// Zmienne r1 i r2 nie będą używane po tym punkcie.
let r3 = &mut s; // bez problemu
println!("{r3}");
}Zasięgi niezmiennych referencji r1 i r2 kończą się po println!, gdzie są ostatnio używane, co następuje przed utworzeniem mutowalnej referencji r3. Te zasięgi nie nakładają się, więc ten kod jest dozwolony: kompilator może stwierdzić, że referencja nie jest już używana w punkcie przed końcem zasięgu.
Chociaż błędy pożyczania mogą czasem frustrować, pamiętaj, że to kompilator Rust wskazuje potencjalny błąd wcześnie (w czasie kompilacji, a nie w czasie wykonania) i pokazuje dokładnie, gdzie leży problem. Wtedy nie musisz szukać przyczyny, dla której twoje dane nie są tym, czego się spodziewałeś.
Zwisające referencje
W językach ze wskaźnikami łatwo jest błędnie utworzyć zwisający wskaźnik — wskaźnik, który odwołuje się do miejsca w pamięci, które mogło zostać przekazane komuś innemu — zwalniając część pamięci, jednocześnie zachowując wskaźnik do tej pamięci. W Rust, natomiast, kompilator gwarantuje, że referencje nigdy nie będą zwisającymi referencjami: jeśli masz referencję do jakichś danych, kompilator zapewni, że dane te nie wyjdą poza zasięg przed referencją do nich.
Spróbujmy utworzyć zwisającą referencję, aby zobaczyć, jak Rust im zapobiega, sygnalizując błąd kompilacji:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}Oto błąd:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ten komunikat o błędzie odnosi się do funkcji, której jeszcze nie omówiliśmy: czasów życia. Szczegółowo omówimy czasy życia w Rozdziale 10. Ale jeśli zignorujesz części dotyczące czasów życia, komunikat zawiera klucz do tego, dlaczego ten kod jest problemem:
typ zwracany przez tę funkcję zawiera wartość pożyczoną, ale nie ma wartości,
z której można ją pożyczyć
Przyjrzyjmy się bliżej, co dokładnie dzieje się na każdym etapie naszego kodu dangle:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle zwraca referencję do String
let s = String::from("hello"); // s to nowy String
&s // zwracamy referencję do String, s
} // Tutaj s wychodzi z zasięgu i jest usuwane, więc jego pamięć znika.
// Niebezpieczeństwo!Ponieważ s jest tworzone wewnątrz dangle, kiedy kod dangle się zakończy, s zostanie dealokowane. Ale próbowaliśmy zwrócić do niego referencję. Oznacza to, że ta referencja wskazywałaby na nieprawidłowy String. To niedobrze! Rust nam na to nie pozwoli.
Rozwiązaniem jest bezpośrednie zwrócenie String:
fn main() {
let string = no_dangle();
}
fn no_dangle() -> String {
let s = String::from("hello");
s
}To działa bez problemów. Własność zostaje przeniesiona, a nic nie jest dealokowane.
Zasady referencji
Podsumujmy, co omówiliśmy na temat referencji:
- W dowolnym momencie możesz mieć albo jedną mutowalną referencję albo dowolną liczbę niemutowalnych referencji.
- Referencje muszą być zawsze ważne.
Następnie przyjrzymy się innemu rodzajowi referencji: wycinkom (slices).
Typ Wycinak (Slice)
Typ Wycinak (Slice)
Wycinki (Slices) pozwalają odwoływać się do ciągłej sekwencji elementów w kolekcji. Wycinek jest rodzajem referencji, więc nie posiada własności.
Oto mały problem programistyczny: Napisz funkcję, która przyjmuje ciąg słów oddzielonych spacjami i zwraca pierwsze słowo, które znajdzie w tym ciągu. Jeśli funkcja nie znajdzie spacji w ciągu, cały ciąg musi być jednym słowem, więc powinien zostać zwrócony cały ciąg.
Uwaga: Dla celów wprowadzenia wycinków, w tej sekcji zakładamy tylko ASCII; bardziej szczegółowe omówienie obsługi UTF-8 znajduje się w sekcji „Przechowywanie tekstu kodowanego w UTF-8 za pomocą ciągów znaków” w Rozdziale 8.
Przyjrzyjmy się, jak napisalibyśmy sygnaturę tej funkcji bez użycia wycinków, aby zrozumieć problem, który wycinki rozwiążą:
fn first_word(s: &String) -> ?Funkcja first_word ma parametr typu &String. Nie potrzebujemy własności, więc to jest w porządku. (W idiomatycznym Rust, funkcje nie przejmują własności swoich argumentów, chyba że jest to konieczne, a powody tego staną się jasne, gdy będziemy kontynuować.) Ale co powinniśmy zwrócić? Nie mamy tak naprawdę sposobu, aby mówić o części ciągu. Jednak moglibyśmy zwrócić indeks końca słowa, wskazany przez spację. Spróbujmy tego, jak pokazano w Listingu 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Ponieważ musimy przejść przez String element po elemencie i sprawdzić, czy wartość jest spacją, przekształcimy nasz String w tablicę bajtów za pomocą metody as_bytes.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Następnie, tworzymy iterator po tablicy bajtów używając metody iter:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Iteratory omówimy bardziej szczegółowo w Rozdziale 13. Na razie wystarczy wiedzieć, że iter to metoda, która zwraca każdy element w kolekcji, a enumerate opakowuje wynik iter i zwraca każdy element jako część krotki. Pierwszy element krotki zwróconej z enumerate to indeks, a drugi element to referencja do elementu. Jest to nieco wygodniejsze niż samodzielne obliczanie indeksu.
Ponieważ metoda enumerate zwraca krotkę, możemy użyć wzorców do dekonstrukcji tej krotki. Więcej o wzorcach omówimy w Rozdziale 6. W pętli for określamy wzorzec, który ma i dla indeksu w krotce i &item dla pojedynczego bajtu w krotce. Ponieważ otrzymujemy referencję do elementu z .iter().enumerate(), używamy & we wzorcu.
Wewnątrz pętli for szukamy bajtu reprezentującego spację, używając składni literału bajtowego. Jeśli znajdziemy spację, zwracamy pozycję. W przeciwnym razie zwracamy długość ciągu, używając s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Mamy teraz sposób na znalezienie indeksu końca pierwszego słowa w ciągu, ale jest problem. Zwracamy samo usize, ale jest to znacząca liczba tylko w kontekście &String. Innymi słowy, ponieważ jest to oddzielna wartość od String, nie ma gwarancji, że będzie ona nadal ważna w przyszłości. Rozważ program z Listingu 4-8, który używa funkcji first_word z Listingu 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word otrzyma wartość 5
s.clear(); // to opróżnia String, sprawiając, że staje się równy ""
// word nadal ma wartość 5 tutaj, ale s nie ma już żadnej zawartości, której moglibyśmy
// sensownie użyć z wartością 5, więc word jest teraz całkowicie nieważne!
}Ten program kompiluje się bez żadnych błędów i skompilowałby się również, gdybyśmy użyli word po wywołaniu s.clear(). Ponieważ word w żaden sposób nie jest powiązane ze stanem s, word nadal zawiera wartość 5. Moglibyśmy użyć tej wartości 5 ze zmienną s, aby spróbować wyodrębnić pierwsze słowo, ale byłby to błąd, ponieważ zawartość s zmieniła się, odkąd zapisaliśmy 5 w word.
Martwienie się o to, że indeks w word przestaje być zsynchronizowany z danymi w s, jest uciążliwe i podatne na błędy! Zarządzanie tymi indeksami jest jeszcze bardziej kruche, jeśli napiszemy funkcję second_word. Jej sygnatura musiałaby wyglądać tak:
fn second_word(s: &String) -> (usize, usize) {Teraz śledzimy indeks początkowy i końcowy, i mamy jeszcze więcej wartości, które zostały obliczone na podstawie danych w określonym stanie, ale w ogóle nie są z tym stanem powiązane. Mamy trzy niepowiązane zmienne, które muszą być zsynchronizowane.
Na szczęście Rust ma rozwiązanie tego problemu: wycinki ciągów znaków (string slices).
Wycinki ciągów znaków (String Slices)
Wycinek ciągu znaków to referencja do ciągłej sekwencji elementów String i wygląda tak:
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}Zamiast referencji do całego String, hello jest referencją do fragmentu String, określonego dodatkowym fragmentem [0..5]. Wycinki tworzymy za pomocą zakresu w nawiasach kwadratowych, określając [indeks_początkowy..indeks_końcowy], gdzie indeks_początkowy to pierwsza pozycja w wycinku, a indeks_końcowy to jeden więcej niż ostatnia pozycja w wycinku. Wewnętrznie struktura danych wycinka przechowuje pozycję początkową i długość wycinka, co odpowiada indeks_końcowy minus indeks_początkowy. Zatem w przypadku let world = &s[6..11];, world byłby wycinkiem, który zawiera wskaźnik do bajtu o indeksie 6 w s z wartością długości 5.
Rysunek 4-7 przedstawia to na diagramie.

Rysunek 4-7: Wycinek ciągu znaków odnoszący się do części String
Dzięki składni zakresu .. w Rust, jeśli chcesz zacząć od indeksu 0, możesz pominąć wartość przed dwoma kropkami. Innymi słowy, te są równoważne:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
}Analogicznie, jeśli twój wycinek zawiera ostatni bajt String, możesz pominąć końcową liczbę. Oznacza to, że te są równoważne:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
}Możesz również pominąć obie wartości, aby utworzyć wycinek całego ciągu. W ten sposób te są równoważne:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
}Uwaga: Indeksy zakresu wycinka ciągu muszą występować na prawidłowych granicach znaków UTF-8. Jeśli spróbujesz utworzyć wycinek ciągu w środku znaku wielobajtowego, program zakończy się błędem.
Mając na uwadze wszystkie te informacje, przepiszmy first_word, aby zwracało wycinek. Typ, który oznacza „wycinek ciągu znaków”, jest zapisywany jako &str:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {}Indeks końca słowa uzyskujemy w ten sam sposób, jak w Listingu 4-7, szukając pierwszego wystąpienia spacji. Gdy znajdziemy spację, zwracamy wycinek ciągu, używając początku ciągu i indeksu spacji jako indeksów początkowego i końcowego.
Teraz, gdy wywołujemy first_word, otrzymujemy jedną wartość, która jest powiązana z danymi podstawowymi. Wartość ta składa się z referencji do punktu początkowego wycinka i liczby elementów w wycinku.
Zwracanie wycinka działałoby również dla funkcji second_word:
fn second_word(s: &String) -> &str {Mamy teraz prosty interfejs API, który jest znacznie trudniejszy do popsucia, ponieważ kompilator zapewni, że referencje do String pozostaną ważne. Pamiętasz błąd w programie z Listingu 4-8, kiedy uzyskaliśmy indeks końca pierwszego słowa, ale potem wyczyściliśmy ciąg, więc nasz indeks był nieprawidłowy? Ten kod był logicznie niepoprawny, ale nie wykazywał żadnych natychmiastowych błędów. Problemy pojawiłyby się później, gdybyśmy nadal próbowali używać indeksu pierwszego słowa z opróżnionym ciągiem. Wycinki uniemożliwiają ten błąd i pozwalają nam znacznie wcześniej dowiedzieć się, że mamy problem z naszym kodem. Użycie wersji first_word z wycinkiem spowoduje błąd kompilacji:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // błąd!
println!("pierwsze słowo to: {word}");
}Oto błąd kompilatora:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Przypomnij sobie z zasad pożyczania, że jeśli mamy niezmienną referencję do czegoś, nie możemy również wziąć mutowalnej referencji. Ponieważ clear musi skrócić String, potrzebuje mutowalnej referencji. println! po wywołaniu clear używa referencji w word, więc referencja niezmienna musi być nadal aktywna w tym punkcie. Rust zabrania istnienia mutowalnej referencji w clear i niezmiennej referencji w word w tym samym czasie, a kompilacja kończy się niepowodzeniem. Rust nie tylko ułatwił nam korzystanie z API, ale także wyeliminował całą klasę błędów w czasie kompilacji!
Literały ciągów znaków jako wycinki
Przypomnijmy, że mówiliśmy o literałach ciągów znaków przechowywanych wewnątrz pliku binarnego. Teraz, gdy wiemy o wycinkach, możemy właściwie zrozumieć literały ciągów znaków:
#![allow(unused)]
fn main() {
let s = "Hello, world!";
}Typ s to &str: jest to wycinek wskazujący na ten konkretny punkt w pliku binarnym. Jest to również powód, dla którego literały ciągów znaków są niezmienne; &str to niezmienna referencja.
Wycinki ciągów znaków jako parametry
Wiedza o tym, że można tworzyć wycinki z literałów i wartości String, prowadzi nas do jeszcze jednego ulepszenia funkcji first_word, a mianowicie jej sygnatury:
fn first_word(s: &String) -> &str {Bardziej doświadczony Rustacean napisałby sygnaturę pokazaną w Listingu 4-9 zamiast niej, ponieważ pozwala to nam używać tej samej funkcji zarówno dla wartości &String, jak i dla wartości &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` działa na wycinkach `String`ów, częściowych lub całych.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` działa również na referencjach do `String`ów, które są równoważne
// z całymi wycinkami `String`ów.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` działa na wycinkach literałów ciągu znaków, częściowych lub
// całych.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Ponieważ literały ciągu znaków *są* już wycinkami ciągu znaków,
// to również działa, bez składni wycinków!
let word = first_word(my_string_literal);
}Jeśli mamy wycinek ciągu znaków, możemy go przekazać bezpośrednio. Jeśli mamy String, możemy przekazać wycinek String lub referencję do String. Ta elastyczność wykorzystuje konwersje dereferencji, cechę, którą omówimy w sekcji „Używanie konwersji dereferencji w funkcjach i metodach” w Rozdziale 15.
Definiowanie funkcji, która przyjmuje wycinek ciągu znaków zamiast referencji do String, sprawia, że nasze API jest bardziej ogólne i użyteczne bez utraty żadnej funkcjonalności:
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` działa na wycinkach `String`ów, częściowych lub całych.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` działa również na referencjach do `String`ów, które są równoważne
// z całymi wycinkami `String`ów.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` działa na wycinkach literałów ciągu znaków, częściowych lub
// całych.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Ponieważ literały ciągu znaków *są* już wycinkami ciągu znaków,
// to również działa, bez składni wycinków!
let word = first_word(my_string_literal);
}Inne wycinki
Wycinki ciągów znaków, jak można sobie wyobrazić, są specyficzne dla ciągów. Ale istnieje również bardziej ogólny typ wycinka. Rozważmy tę tablicę:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
}Tak samo jak możemy chcieć odwołać się do części ciągu, możemy chcieć odwołać się do części tablicy. Zrobilibyśmy to w ten sposób:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
}Ten wycinek ma typ &[i32]. Działa tak samo jak wycinki ciągów, przechowując referencję do pierwszego elementu i długość. Będziesz używać tego rodzaju wycinków dla wszelkiego rodzaju innych kolekcji. Te kolekcje omówimy szczegółowo, gdy będziemy mówić o wektorach w Rozdziale 8.
Podsumowanie
Koncepcje własności, pożyczania i wycinków zapewniają bezpieczeństwo pamięci w programach Rust w czasie kompilacji. Język Rust daje kontrolę nad wykorzystaniem pamięci w taki sam sposób, jak inne języki programowania systemowego. Ale to, że właściciel danych automatycznie czyści te dane, gdy właściciel wychodzi poza zasięg, oznacza, że nie musisz pisać i debugować dodatkowego kodu, aby uzyskać tę kontrolę.
Własność wpływa na działanie wielu innych części Rust, więc będziemy rozmawiać o tych koncepcjach w dalszej części książki. Przejdźmy do Rozdziału 5 i przyjrzyjmy się grupowaniu fragmentów danych w struct.
Użycie struktur do organizacji powiązanych danych
Struktura to niestandardowy typ danych, który pozwala na grupowanie i nazywanie wielu powiązanych wartości, tworzących spójną grupę. Jeśli znasz języki obiektowe, struktura jest jak atrybuty danych obiektu. W tym rozdziale porównamy krotki ze strukturami, aby rozbudować twoją wiedzę i pokazać, kiedy struktury są lepszym sposobem na grupowanie danych.
Omówimy, jak definiować i tworzyć instancje struktur. Dowiemy się, jak definiować funkcje skojarzone, zwłaszcza metody, aby określać zachowanie związane z typem struktury. Struktury i typy wyliczeniowe (enum, omówione w Rozdziale 6) to elementy składowe do tworzenia nowych typów w domenie twojego programu, aby w pełni wykorzystać sprawdzanie typów w czasie kompilacji w Rust.
Definiowanie i tworzenie instancji struktur
Definiowanie i tworzenie instancji struktur
Struktury są podobne do krotek, omówionych w sekcji „Typ krotki”, w tym, że obie przechowują wiele powiązanych wartości. Podobnie jak krotki, elementy struktury mogą być różnych typów. W przeciwieństwie do krotek, w strukturze nazwiesz każdy element danych, tak aby było jasne, co oznaczają wartości. Dodanie tych nazw sprawia, że struktury są bardziej elastyczne niż krotki: nie musisz polegać na kolejności danych, aby określić lub uzyskać dostęp do wartości instancji.
Aby zdefiniować strukturę, wpisujemy słowo kluczowe struct i nadajemy nazwę całej strukturze. Nazwa struktury powinna opisywać znaczenie grupowanych danych. Następnie, w nawiasach klamrowych, definiujemy nazwy i typy elementów danych, które nazywamy polami. Na przykład, Listing 5-1 przedstawia strukturę, która przechowuje informacje o koncie użytkownika.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {}Aby użyć struktury po jej zdefiniowaniu, tworzymy instancję tej struktury, określając konkretne wartości dla każdego z pól. Tworzymy instancję, podając nazwę struktury, a następnie dodajemy nawiasy klamrowe zawierające pary klucz: wartość, gdzie klucze to nazwy pól, a wartości to dane, które chcemy przechowywać w tych polach. Nie musimy określać pól w tej samej kolejności, w jakiej zadeklarowaliśmy je w strukturze. Innymi słowy, definicja struktury jest jak ogólny szablon dla typu, a instancje wypełniają ten szablon konkretnymi danymi, aby utworzyć wartości tego typu. Na przykład, możemy zadeklarować konkretnego użytkownika, jak pokazano w Listingu 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
}Aby uzyskać konkretną wartość ze struktury, używamy notacji kropkowej. Na przykład, aby uzyskać dostęp do adresu e-mail tego użytkownika, używamy user1.email. Jeśli instancja jest mutowalna, możemy zmienić wartość, używając notacji kropkowej i przypisując ją do konkretnego pola. Listing 5-3 pokazuje, jak zmienić wartość w polu email mutowalnej instancji User.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}Zauważ, że cała instancja musi być mutowalna; Rust nie pozwala nam oznaczać tylko niektórych pól jako mutowalne. Podobnie jak w przypadku każdego wyrażenia, możemy skonstruować nową instancję struktury jako ostatnie wyrażenie w treści funkcji, aby niejawnie zwrócić tę nową instancję.
Listing 5-4 przedstawia funkcję build_user, która zwraca instancję User z podanym adresem e-mail i nazwą użytkownika. Pole active otrzymuje wartość true, a sign_in_count wartość 1.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username: username,
email: email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}Logiczne jest nazwanie parametrów funkcji tak samo jak pól struktury, ale powtarzanie nazw pól email i username oraz zmiennych jest trochę uciążliwe. Gdyby struktura miała więcej pól, powtarzanie każdej nazwy stałoby się jeszcze bardziej irytujące. Na szczęście istnieje wygodna skrócona forma!
Używanie skróconej składni inicjalizacji pola
Ponieważ nazwy parametrów i nazwy pól struktury są dokładnie takie same w Listingu 5-4, możemy użyć składni skróconej inicjalizacji pola do przepisania build_user tak, aby zachowywała się dokładnie tak samo, ale nie powtarzała username i email, jak pokazano w Listingu 5-5.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username,
email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}Tutaj tworzymy nową instancję struktury User, która ma pole o nazwie email. Chcemy ustawić wartość pola email na wartość z parametru email funkcji build_user. Ponieważ pole email i parametr email mają tę samą nazwę, wystarczy napisać email zamiast email: email.
Tworzenie instancji za pomocą składni aktualizacji struktury
Często przydaje się tworzenie nowej instancji struktury, która zawiera większość wartości z innej instancji tego samego typu, ale zmienia niektóre z nich. Możesz to zrobić za pomocą składni aktualizacji struktury.
Najpierw, w Listingu 5-6, pokazujemy, jak utworzyć nową instancję User w user2 w zwykły sposób, bez składni aktualizacji. Ustawiamy nową wartość dla email, ale poza tym używamy tych samych wartości z user1, które utworzyliśmy w Listingu 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
}Używając składni aktualizacji struktury, możemy osiągnąć ten sam efekt za pomocą mniejszej ilości kodu, jak pokazano w Listingu 5-7. Składnia .. określa, że pozostałe pola, które nie zostały jawnie ustawione, powinny mieć taką samą wartość jak pola w danej instancji.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
email: String::from("another@example.com"),
..user1
};
}Kod w Listingu 5-7 również tworzy instancję user2, która ma inną wartość dla email, ale ma te same wartości dla pól username, active i sign_in_count co user1. Instrukcja ..user1 musi znajdować się na końcu, aby określić, że wszelkie pozostałe pola powinny otrzymać swoje wartości z odpowiednich pól w user1, ale możemy wybrać, aby określić wartości dla dowolnej liczby pól w dowolnej kolejności, niezależnie od kolejności pól w definicji struktury.
Zauważ, że składnia aktualizacji struktury używa = jak przypisania; dzieje się tak dlatego, że przenosi ona dane, tak jak widzieliśmy to w sekcji „Zmienne i dane w interakcji przez przeniesienie”. W tym przykładzie nie możemy już używać user1 po utworzeniu user2, ponieważ String z pola username w user1 zostało przeniesione do user2. Gdybyśmy podali user2 nowe wartości String dla email i username, a więc użyli tylko wartości active i sign_in_count z user1, wówczas user1 byłoby nadal ważne po utworzeniu user2. Zarówno active, jak i sign_in_count to typy implementujące cechę Copy, więc zastosowałoby się zachowanie, o którym mówiliśmy w sekcji „Dane tylko na stosie: Kopia”. W tym przykładzie nadal możemy używać user1.email, ponieważ jego wartość nie została przeniesiona z user1.
Tworzenie różnych typów za pomocą struktur krotkowych
Rust obsługuje również struktury, które wyglądają podobnie do krotek, nazywane strukturami krotkowymi. Struktury krotkowe posiadają dodatkowe znaczenie, które nadaje im nazwa struktury, ale nie mają nazw powiązanych z ich polami; zamiast tego mają tylko typy pól. Struktury krotkowe są użyteczne, gdy chcesz nadać całej krotce nazwę i uczynić ją innym typem niż inne krotki, oraz gdy nazwanie każdego pola, jak w zwykłej strukturze, byłoby zbyt rozwlekłe lub redundantne.
Aby zdefiniować strukturę krotkową, zacznij od słowa kluczowego struct i nazwy struktury, a następnie podaj typy w krotce. Na przykład, tutaj definiujemy i używamy dwóch struktur krotkowych o nazwach Color i Point:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}Zauważ, że wartości black i origin są różnych typów, ponieważ są instancjami różnych struktur krotek. Każda zdefiniowana przez ciebie struktura jest swoim własnym typem, mimo że pola w strukturze mogą mieć te same typy. Na przykład, funkcja, która przyjmuje parametr typu Color, nie może przyjąć Point jako argumentu, mimo że oba typy składają się z trzech wartości i32. W przeciwnym razie, instancje struktur krotek są podobne do krotek w tym sensie, że można je dekomponować na pojedyncze elementy i można użyć . po którym następuje indeks, aby uzyskać dostęp do pojedynczej wartości. W przeciwieństwie do krotek, struktury krotki wymagają podania nazwy typu struktury podczas dekompozycji. Na przykład, napisalibyśmy let Point(x, y, z) = origin;, aby dekomponować wartości punktu origin na zmienne o nazwach x, y i z.
Definiowanie struktur podobnych do jednostek
Można również definiować struktury, które nie mają żadnych pól! Nazywa się je strukturami podobnymi do jednostek, ponieważ zachowują się podobnie do (), typu jednostkowego, o którym wspominaliśmy w sekcji „Typ krotki”. Struktury podobne do jednostek mogą być użyteczne, gdy trzeba zaimplementować cechę dla jakiegoś typu, ale nie ma się żadnych danych do przechowywania w samym typie. O cechach omówimy w Rozdziale 10. Oto przykład deklaracji i tworzenia instancji struktury jednostkowej o nazwie AlwaysEqual:
struct AlwaysEqual;
fn main() {
let subject = AlwaysEqual;
}Aby zdefiniować AlwaysEqual, używamy słowa kluczowego struct, wybranej nazwy, a następnie średnika. Nie ma potrzeby używania nawiasów klamrowych ani okrągłych! Następnie możemy uzyskać instancję AlwaysEqual w zmiennej subject w podobny sposób: używając zdefiniowanej nazwy, bez nawiasów klamrowych ani okrągłych. Wyobraź sobie, że później zaimplementujemy zachowanie dla tego typu, tak aby każda instancja AlwaysEqual zawsze była równa każdej instancji dowolnego innego typu, być może w celach testowych. Nie potrzebowalibyśmy żadnych danych, aby zaimplementować to zachowanie! W Rozdziale 10 dowiesz się, jak definiować cechy i implementować je na dowolnym typie, w tym na strukturach podobnych do jednostek.
Własność Danych Struktury
W definicji struktury
Userz Listingu 5-1 użyliśmy własnego typuStringzamiast typu wycinka ciągu&str. Jest to celowy wybór, ponieważ chcemy, aby każda instancja tej struktury posiadała wszystkie swoje dane, a dane te były ważne tak długo, jak ważna jest cała struktura.Możliwe jest również, aby struktury przechowywały referencje do danych należących do czegoś innego, ale do tego wymagane jest użycie czasów życia – funkcji Rust, którą omówimy w Rozdziale 10. Czasy życia zapewniają, że dane, do których odnosi się struktura, są ważne tak długo, jak ważna jest struktura. Powiedzmy, że spróbujesz przechowywać referencję w strukturze bez określania czasów życia, tak jak poniżej w src/main.rs; to nie zadziała:
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: "someusername123", email: "someone@example.2com", sign_in_count: 1, }; }Kompilator będzie narzekał, że potrzebuje specyfikatorów czasu życia:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` (bin "structs") due to 2 previous errorsW Rozdziale 10 omówimy, jak naprawić te błędy, aby można było przechowywać referencje w strukturach, ale na razie będziemy naprawiać takie błędy, używając typów posiadanych, takich jak
String, zamiast referencji, takich jak&str.
Przykładowy program używający struktur
Przykładowy program używający struktur
Aby zrozumieć, kiedy warto używać struktur, napiszmy program, który oblicza pole prostokąta. Zaczniemy od użycia pojedynczych zmiennych, a następnie zrefaktoryzujemy program, aż będziemy używać struktur.
Stwórzmy nowy projekt binarny za pomocą Cargo o nazwie rectangles, który będzie przyjmował szerokość i wysokość prostokąta podane w pikselach i obliczał pole prostokąta. Listing 5-8 przedstawia krótki program z jednym sposobem na zrobienie tego w pliku src/main.rs naszego projektu.
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"Pole prostokąta wynosi {} pikseli kwadratowych.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Teraz uruchom ten program za pomocą cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
Ten kod z powodzeniem oblicza pole prostokąta, wywołując funkcję area z każdym wymiarem, ale możemy zrobić więcej, aby uczynić ten kod bardziej przejrzystym i czytelnym.
Problem z tym kodem jest widoczny w sygnaturze area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"Pole prostokąta wynosi {} pikseli kwadratowych.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Funkcja area ma za zadanie obliczyć pole jednego prostokąta, ale napisana przez nas funkcja ma dwa parametry i nigdzie w naszym programie nie jest jasne, że te parametry są ze sobą powiązane. Byłoby bardziej czytelne i łatwiejsze w zarządzaniu, gdybyśmy zgrupowali szerokość i wysokość. Omówiliśmy już jeden sposób, w jaki moglibyśmy to zrobić w sekcji „Typ krotki” w Rozdziale 3: używając krotek.
Refaktoryzacja za pomocą krotek
Listing 5-9 przedstawia inną wersję naszego programu, która używa krotek.
fn main() {
let rect1 = (30, 50);
println!(
"Pole prostokąta wynosi {} pikseli kwadratowych.",
area(rect1)
);
}
fn area(dimensions: (u32, u32)) -> u32 {
dimensions.0 * dimensions.1
}Pod pewnym względem ten program jest lepszy. Krotki pozwalają nam dodać trochę struktury, a teraz przekazujemy tylko jeden argument. Ale pod innym względem ta wersja jest mniej przejrzysta: krotki nie nazywają swoich elementów, więc musimy indeksować części krotki, co sprawia, że nasze obliczenia są mniej oczywiste.
Pomylenie szerokości i wysokości nie miałoby znaczenia dla obliczania powierzchni, ale gdybyśmy chcieli narysować prostokąt na ekranie, miałoby to znaczenie! Musielibyśmy pamiętać, że width to indeks krotki 0, a height to indeks krotki 1. Byłoby to jeszcze trudniejsze do zrozumienia i zapamiętania dla kogoś innego, kto używałby naszego kodu. Ponieważ nie przekazaliśmy znaczenia naszych danych w naszym kodzie, łatwiej jest teraz wprowadzić błędy.
Refaktoryzacja za pomocą struktur
Używamy struktur, aby dodać znaczenie poprzez etykietowanie danych. Możemy przekształcić krotkę, której używamy, w strukturę z nazwą dla całości, a także nazwami dla części, jak pokazano w Listingu 5-10.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"Pole prostokąta wynosi {} pikseli kwadratowych.",
area(&rect1)
);
}
fn area(rectangle: &Rectangle) -> u32 {
rectangle.width * rectangle.height
}Tutaj zdefiniowaliśmy strukturę i nazwaliśmy ją Rectangle. W nawiasach klamrowych zdefiniowaliśmy pola jako width i height, z których oba mają typ u32. Następnie, w main, utworzyliśmy konkretną instancję Rectangle o szerokości 30 i wysokości 50.
Nasza funkcja area jest teraz zdefiniowana z jednym parametrem, który nazwaliśmy rectangle, którego typem jest niezmienne pożyczenie instancji struktury Rectangle. Jak wspomniano w Rozdziale 4, chcemy pożyczyć strukturę, a nie przejmować jej własności. W ten sposób main zachowuje własność i może nadal używać rect1, co jest powodem, dla którego używamy & w sygnaturze funkcji i tam, gdzie wywołujemy funkcję.
Funkcja area uzyskuje dostęp do pól width i height instancji Rectangle (zauważ, że dostęp do pól pożyczonej instancji struktury nie przenosi wartości pól, dlatego często spotyka się pożyczanie struktur). Nasza sygnatura funkcji area mówi teraz dokładnie, co mamy na myśli: Oblicz pole Rectangle, używając jego pól width i height. Przekazuje to, że szerokość i wysokość są ze sobą powiązane, i nadaje wartościom opisowe nazwy, zamiast używać wartości indeksu krotki 0 i 1. Jest to korzyść dla przejrzystości.
Dodawanie funkcjonalności za pomocą wyprowadzonych cech (derived traits)
Przydałoby się móc wyświetlić instancję Rectangle podczas debugowania programu i zobaczyć wartości wszystkich jej pól. Listing 5-11 próbuje użyć makra println!, tak jak używaliśmy w poprzednich rozdziałach. Jednak to nie zadziała.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 to {rect1}");
}Kiedy skompilujemy ten kod, otrzymamy błąd z następującym głównym komunikatem:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
Makro println! potrafi wiele rodzajów formatowania, a domyślnie nawiasy klamrowe mówią println!, aby użyć formatowania znanego jako Display: wyjście przeznaczone do bezpośredniego użytku przez użytkownika końcowego. Prymitywne typy, które widzieliśmy do tej pory, domyślnie implementują Display, ponieważ istnieje tylko jeden sposób, w jaki chciałbyś pokazać 1 lub inny typ prymitywny użytkownikowi. Ale w przypadku struktur sposób, w jaki println! powinien sformatować wyjście, jest mniej jasny, ponieważ istnieje więcej możliwości wyświetlania: Czy chcesz przecinków, czy nie? Czy chcesz drukować nawiasy klamrowe? Czy wszystkie pola powinny być wyświetlane? Z powodu tej niejednoznaczności Rust nie próbuje zgadywać, czego chcemy, a struktury nie mają dostarczonej implementacji Display do użycia z println! i symbolem zastępczym {}.
Jeśli będziemy dalej czytać błędy, znajdziemy tę pomocną notatkę:
| |`Rectangle` nie może być sformatowany za pomocą domyślnego formatatora
| wymaganego przez ten parametr formatowania
Spróbujmy! Wywołanie makra println! będzie teraz wyglądać tak: println!("rect1 to {rect1:?}");. Umieszczenie specyfikatora :? w nawiasach klamrowych mówi println!, że chcemy użyć formatu wyjściowego o nazwie Debug. Cecha Debug umożliwia nam wyświetlanie naszej struktury w sposób użyteczny dla programistów, dzięki czemu możemy zobaczyć jej wartość podczas debugowania kodu.
Skompiluj kod z tą zmianą. Cholera! Nadal otrzymujemy błąd:
error[E0277]: `Rectangle` nie implementuje `Debug`
Ale znowu, kompilator daje nam pomocną notatkę:
| wymagany przez ten parametr formatowania
|
Rust zawiera funkcjonalność do wyświetlania informacji debugujących, ale musimy jawnie ją włączyć, aby ta funkcjonalność była dostępna dla naszej struktury. Aby to zrobić, dodajemy zewnętrzny atrybut #[derive(Debug)] tuż przed definicją struktury, jak pokazano w Listingu 5-12.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 to {rect1:?}");
}Teraz, gdy uruchomimy program, nie otrzymamy żadnych błędów i zobaczymy następujące wyjście:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Pięknie! To nie jest najładniejsze wyjście, ale pokazuje wartości wszystkich pól dla tej instancji, co z pewnością pomogłoby podczas debugowania. Kiedy mamy większe struktury, przydatne jest, aby wyjście było nieco łatwiejsze do odczytania; w takich przypadkach możemy użyć {:#?} zamiast {:?} w ciągu println!. W tym przykładzie użycie stylu {:#?} spowoduje wyświetlenie następującego komunikatu:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Innym sposobem wydrukowania wartości za pomocą formatu Debug jest użycie makra dbg!, które przejmuje własność wyrażenia (w przeciwieństwie do println!, które przyjmuje referencję), drukuje plik i numer linii, w której występuje wywołanie makra dbg! wraz z wynikową wartością tego wyrażenia i zwraca własność wartości.
Uwaga: Wywołanie makra
dbg!drukuje do standardowego strumienia błędów konsoli (stderr), w przeciwieństwie doprintln!, które drukuje do standardowego strumienia wyjściowego konsoli (stdout). Więcej ostderristdoutomówimy w sekcji „Przekierowywanie błędów do standardowego strumienia błędów” w Rozdziale 12.
Oto przykład, w którym interesuje nas wartość przypisana do pola width, a także wartość całej struktury w rect1:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}Możemy umieścić dbg! wokół wyrażenia 30 * scale i, ponieważ dbg! zwraca własność wartości wyrażenia, pole width otrzyma tę samą wartość, jakbyśmy nie mieli tam wywołania dbg!. Nie chcemy, aby dbg! przejmowało własność rect1, więc w następnym wywołaniu używamy referencji do rect1. Oto jak wygląda wyjście z tego przykładu:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
Widzimy, że pierwsza część wyjścia pochodzi z pliku src/main.rs w linii 10, gdzie debugujemy wyrażenie 30 * scale, a jego wynikowa wartość to 60 (formatowanie Debug zaimplementowane dla liczb całkowitych polega na wydrukowaniu tylko ich wartości). Wywołanie dbg! w linii 14 pliku src/main.rs wyprowadza wartość &rect1, czyli struktury Rectangle. To wyjście wykorzystuje ładne formatowanie Debug typu Rectangle. Makro dbg! może być naprawdę pomocne, gdy próbujesz dowiedzieć się, co robi twój kod!
Oprócz cechy Debug, Rust dostarczył szereg cech, których możemy używać z atrybutem derive, które mogą dodawać użyteczne zachowanie do naszych niestandardowych typów. Te cechy i ich zachowania są wymienione w Dodatku C. Omówimy, jak zaimplementować te cechy z niestandardowym zachowaniem, a także jak tworzyć własne cechy w Rozdziale 10. Istnieje również wiele innych atrybutów niż derive; więcej informacji można znaleźć w sekcji „Atrybuty” w dokumentacji Rust Reference.
Nasza funkcja area jest bardzo specyficzna: oblicza tylko pole prostokątów. Pomocne byłoby powiązanie tego zachowania bliżej z naszą strukturą Rectangle, ponieważ nie będzie ono działać z żadnym innym typem. Przyjrzyjmy się, jak możemy kontynuować refaktoryzację tego kodu, zamieniając funkcję area w metodę area zdefiniowaną dla naszego typu Rectangle.
Metody
Metody
Metody są podobne do funkcji: deklarujemy je słowem kluczowym fn i nazwą, mogą mieć parametry i zwracać wartość, oraz zawierają kod, który jest uruchamiany po wywołaniu metody z innego miejsca. W przeciwieństwie do funkcji, metody są definiowane w kontekście struktury (lub typu wyliczeniowego albo obiektu cechy, które omówimy odpowiednio w Rozdziale 6 i Rozdziale 18), a ich pierwszym parametrem jest zawsze self, które reprezentuje instancję struktury, na której wywoływana jest metoda.
Składnia metody
Zmieńmy funkcję area, która ma instancję Rectangle jako parametr, i zamiast tego stwórzmy metodę area zdefiniowaną w strukturze Rectangle, jak pokazano w Listingu 5-13.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"Pole prostokąta wynosi {} pikseli kwadratowych.",
rect1.area()
);
}Aby zdefiniować funkcję w kontekście Rectangle, rozpoczynamy blok impl (implementacji) dla Rectangle. Wszystko w tym bloku impl będzie powiązane z typem Rectangle. Następnie przenosimy funkcję area do nawiasów klamrowych impl i zmieniamy pierwszy (a w tym przypadku jedyny) parametr na self w sygnaturze i wszędzie w treści. W main, gdzie wywołaliśmy funkcję area i przekazaliśmy rect1 jako argument, możemy zamiast tego użyć składni metody do wywołania metody area na naszej instancji Rectangle. Składnia metody występuje po instancji: dodajemy kropkę, po której następuje nazwa metody, nawiasy i wszelkie argumenty.
W sygnaturze area używamy &self zamiast rectangle: &Rectangle. &self to w rzeczywistości skrót od self: &Self. W bloku impl typ Self jest aliasem dla typu, dla którego jest blok impl. Metody muszą mieć parametr o nazwie self typu Self jako swój pierwszy parametr, więc Rust pozwala na skrócenie tego do samej nazwy self w miejscu pierwszego parametru. Zauważ, że nadal musimy używać & przed skrótem self, aby wskazać, że ta metoda pożycza instancję Self, tak jak zrobiliśmy to w rectangle: &Rectangle. Metody mogą przejmować własność self, pożyczać self niezmiennie, jak to zrobiliśmy tutaj, lub pożyczać self mutowalnie, tak jak każdy inny parametr.
Wybraliśmy &self z tego samego powodu, dla którego użyliśmy &Rectangle w wersji funkcyjnej: nie chcemy przejmować własności i chcemy tylko odczytywać dane ze struktury, a nie do niej zapisywać. Gdybyśmy chcieli zmienić instancję, na której wywołaliśmy metodę, w ramach działania metody, użylibyśmy &mut self jako pierwszego parametru. Posiadanie metody, która przejmuje własność instancji, używając tylko self jako pierwszego parametru, jest rzadkie; ta technika jest zazwyczaj używana, gdy metoda przekształca self w coś innego i chcemy uniemożliwić wywołującemu używanie oryginalnej instancji po transformacji.
Głównym powodem używania metod zamiast funkcji, oprócz zapewnienia składni metody i braku konieczności powtarzania typu self w sygnaturze każdej metody, jest organizacja. Umieściliśmy wszystkie rzeczy, które możemy zrobić z instancją typu, w jednym bloku impl, zamiast zmuszać przyszłych użytkowników naszego kodu do szukania możliwości Rectangle w różnych miejscach dostarczanej przez nas biblioteki.
Zauważ, że możemy nadać metodzie taką samą nazwę jak jednemu z pól struktury. Na przykład, możemy zdefiniować metodę w Rectangle, która również nazywa się width:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn width(&self) -> bool {
self.width > 0
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
if rect1.width() {
println!("Prostokąt ma szerokość różną od zera; wynosi {}", rect1.width);
}
}Tutaj, decydujemy, aby metoda width zwracała true, jeśli wartość w polu width instancji jest większa niż 0, a false, jeśli wartość jest 0: możemy użyć pola o tej samej nazwie w metodzie do dowolnego celu. W main, gdy po rect1.width umieścimy nawiasy, Rust wie, że chodzi nam o metodę width. Gdy nie używamy nawiasów, Rust wie, że chodzi nam o pole width.
Często, choć nie zawsze, gdy nadajemy metodzie taką samą nazwę jak polu, chcemy, aby zwracała tylko wartość z pola i nic więcej. Takie metody nazywane są getterami, a Rust nie implementuje ich automatycznie dla pól struktur, tak jak robią to niektóre inne języki. Gettery są użyteczne, ponieważ można uczynić pole prywatnym, ale metodę publiczną, a tym samym umożliwić dostęp tylko do odczytu do tego pola jako części publicznego API typu. Omówimy, czym są publiczne i prywatne, oraz jak oznaczyć pole lub metodę jako publiczną lub prywatną w Rozdziale 7.
Gdzie jest operator
->?W C i C++ do wywoływania metod używa się dwóch różnych operatorów:
.jeśli wywołuje się metodę bezpośrednio na obiekcie, oraz->jeśli wywołuje się metodę na wskaźniku do obiektu i trzeba najpierw dereferencjować wskaźnik. Innymi słowy, jeśliobjectjest wskaźnikiem,object->something()jest podobne do(*object).something().Rust nie ma odpowiednika operatora
->; zamiast tego, Rust ma funkcję zwaną automatycznym referencjowaniem i dereferencjowaniem. Wywoływanie metod jest jednym z niewielu miejsc w Rust z takim zachowaniem.Działa to w następujący sposób: Kiedy wywołujesz metodę
object.something(), Rust automatycznie dodaje&,&mutlub*, tak abyobjectpasował do sygnatury metody. Innymi słowy, poniższe są takie same:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }Pierwsza z nich wygląda znacznie czyściej. To automatyczne zachowanie referencjonowania działa, ponieważ metody mają wyraźny odbiornik — typ
self. Biorąc pod uwagę odbiornik i nazwę metody, Rust może jednoznacznie określić, czy metoda odczytuje (&self), mutuje (&mut self), czy zużywa (self). Fakt, że Rust sprawia, że pożyczanie jest niejawne dla odbiorników metod, jest dużą częścią sprawiania, że własność jest ergonomiczna w praktyce.
Metody z większą liczbą parametrów
Poćwiczmy używanie metod, implementując drugą metodę w strukturze Rectangle. Tym razem chcemy, aby instancja Rectangle przyjmowała inną instancję Rectangle i zwracała true, jeśli drugi Rectangle może całkowicie zmieścić się w self (pierwszym Rectangle); w przeciwnym razie powinna zwrócić false. Oznacza to, że po zdefiniowaniu metody can_hold, chcemy móc napisać program pokazany w Listingu 5-14.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Czy rect1 może pomieścić rect2? {}", rect1.can_hold(&rect2));
println!("Czy rect1 może pomieścić rect3? {}", rect1.can_hold(&rect3));
}Oczekiwane wyjście wyglądałoby następująco, ponieważ oba wymiary rect2 są mniejsze niż wymiary rect1, ale rect3 jest szerszy niż rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
Wiemy, że chcemy zdefiniować metodę, więc będzie ona w bloku impl Rectangle. Nazwa metody będzie can_hold, i przyjmie niezmienne pożyczenie innego Rectangle jako parametr. Możemy stwierdzić, jaki będzie typ parametru, patrząc na kod, który wywołuje metodę: rect1.can_hold(&rect2) przekazuje &rect2, co jest niezmiennym pożyczeniem rect2, instancji Rectangle. Ma to sens, ponieważ musimy tylko odczytywać rect2 (zamiast zapisywać, co oznaczałoby, że potrzebowalibyśmy mutowalnego pożyczenia), i chcemy, aby main zachowało własność rect2, abyśmy mogli go ponownie użyć po wywołaniu metody can_hold. Wartością zwracaną can_hold będzie Boolean, a implementacja sprawdzi, czy szerokość i wysokość self są większe niż szerokość i wysokość drugiego Rectangle, odpowiednio. Dodajmy nową metodę can_hold do bloku impl z Listingu 5-13, pokazanej w Listingu 5-15.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Czy rect1 może pomieścić rect2? {}", rect1.can_hold(&rect2));
println!("Czy rect1 może pomieścić rect3? {}", rect1.can_hold(&rect3));
}Po uruchomieniu tego kodu z funkcją main z Listingu 5-14, otrzymamy pożądane wyjście. Metody mogą przyjmować wiele parametrów, które dodajemy do sygnatury po parametrze self, a te parametry działają tak samo jak parametry w funkcjach.
Funkcje skojarzone
Wszystkie funkcje zdefiniowane w bloku impl nazywane są funkcjami skojarzonymi, ponieważ są powiązane z typem nazwanym po impl. Możemy definiować funkcje skojarzone, które nie mają self jako swojego pierwszego parametru (i dlatego nie są metodami), ponieważ nie potrzebują instancji typu do działania. Użyliśmy już jednej takiej funkcji: funkcji String::from zdefiniowanej dla typu String.
Funkcje skojarzone, które nie są metodami, są często używane jako konstruktory, które zwracają nową instancję struktury. Są one często nazywane new, ale new nie jest specjalną nazwą i nie jest wbudowane w język. Na przykład, moglibyśmy zapewnić funkcję skojarzoną o nazwie square, która miałaby jeden parametr wymiaru i używałaby go zarówno jako szerokości, jak i wysokości, ułatwiając w ten sposób tworzenie kwadratowego Rectangle zamiast konieczności dwukrotnego określania tej samej wartości:
Nazwa pliku: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
}
fn main() {
let sq = Rectangle::square(3);
}Słowa kluczowe Self w typie zwracanym i w treści funkcji są aliasami dla typu, który pojawia się po słowie kluczowym impl, czyli w tym przypadku Rectangle.
Aby wywołać tę funkcję skojarzoną, używamy składni :: z nazwą struktury; let sq = Rectangle::square(3); jest przykładem. Ta funkcja jest umieszczona w przestrzeni nazw struktury: składnia :: jest używana zarówno dla funkcji skojarzonych, jak i przestrzeni nazw utworzonych przez moduły. Omówimy moduły w Rozdziale 7.
Wiele bloków impl
Każda struktura może mieć wiele bloków impl. Na przykład, Listing 5-15 jest równoważny z kodem pokazanym w Listingu 5-16, który ma każdą metodę w swoim własnym bloku impl.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Czy rect1 może pomieścić rect2? {}", rect1.can_hold(&rect2));
println!("Czy rect1 może pomieścić rect3? {}", rect1.can_hold(&rect3));
}Nie ma powodu, aby rozdzielać te metody na wiele bloków impl w tym przypadku, ale jest to poprawna składnia. Zobaczymy przypadek, w którym wiele bloków impl jest użytecznych w Rozdziale 10, gdzie omówimy typy generyczne i cechy.
Podsumowanie
Struktury pozwalają tworzyć niestandardowe typy, które mają znaczenie dla twojej domeny. Używając struktur, możesz zachować powiązane ze sobą fragmenty danych i nazywać każdy z nich, aby Twój kod był przejrzysty. W blokach impl możesz definiować funkcje powiązane z Twoim typem, a metody są rodzajem funkcji powiązanych, które pozwalają określać zachowanie instancji Twoich struktur.
Ale struktury to nie jedyny sposób, w jaki możesz tworzyć niestandardowe typy: przejdźmy do funkcji enum w Rust, aby dodać kolejne narzędzie do Twojego zestawu.
Typy wyliczeniowe (enum) i dopasowywanie wzorców
W tym rozdziale przyjrzymy się wyliczeniom, zwanym również enumami.Enumy pozwalają zdefiniować typ poprzez wyliczenie jego możliwych wariantów.Najpierw zdefiniujemy i użyjemy enum, aby pokazać, jak enum może kodowaćznaczenie wraz z danymi. Następnie zbadamy szczególnie użyteczny enum,nazwany Option, który wyraża, że wartość może być albo czymś, albo niczym.Następnie przyjrzymy się, jak dopasowywanie wzorców w wyrażeniu matchułatwia uruchamianie różnego kodu dla różnych wartości enum. Na koniecomówimy, jak konstrukcja if let jest kolejnym wygodnym i zwięzłym idiomemdostępnym do obsługi enumów w twoim kodzie.
Definiowanie typu wyliczeniowego
Definiowanie typu wyliczeniowego
Podczas gdy struktury dają ci sposób grupowania powiązanych pól i danych, jak Rectangle z jego width i height, enums dają ci sposób powiedzenia, że wartość jest jedną z możliwych zestawów wartości. Na przykład, możemy chcieć powiedzieć, że Rectangle jest jednym z możliwych kształtów, które obejmują również Circle i Triangle. Aby to zrobić, Rust pozwala nam zakodować te możliwości jako enum.
Przyjrzyjmy się sytuacji, którą możemy chcieć wyrazić w kodzie i zobaczmy, dlaczego enums są użyteczne i bardziej odpowiednie niż struktury w tym przypadku. Powiedzmy, że musimy pracować z adresami IP. Obecnie używane są dwa główne standardy dla adresów IP: wersja czwarta i wersja szósta. Ponieważ są to jedyne możliwości dla adresu IP, z którymi nasz program się spotka, możemy wyliczyć wszystkie możliwe warianty, skąd pochodzi nazwa „enumeration”.
Każdy adres IP może być adresem wersji czwartej lub wersji szóstej, ale nie oboma jednocześnie. Ta właściwość adresów IP sprawia, że struktura danych enum jest odpowiednia, ponieważ wartość enum może być tylko jednym ze swoich wariantów. Zarówno adresy wersji czwartej, jak i wersji szóstej są nadal zasadniczo adresami IP, więc powinny być traktowane jako ten sam typ, gdy kod obsługuje sytuacje, które mają zastosowanie do każdego rodzaju adresu IP.
Możemy wyrazić tę koncepcję w kodzie, definiując wyliczenie IpAddrKind i wymieniając możliwe rodzaje adresów IP, którymi mogą być V4 i V6. Są to warianty enum:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}IpAddrKind to teraz niestandardowy typ danych, którego możemy używać w innych miejscach naszego kodu.
Wartości wyliczeniowe
Możemy tworzyć instancje każdego z dwóch wariantów IpAddrKind w następujący sposób:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Zauważ, że warianty enum są umieszczone w przestrzeni nazw pod jego identyfikatorem, a my używamy podwójnego dwukropka do rozdzielenia tych dwóch. Jest to przydatne, ponieważ teraz obie wartości IpAddrKind::V4 i IpAddrKind::V6 są tego samego typu: IpAddrKind. Możemy wtedy, na przykład, zdefiniować funkcję, która przyjmuje dowolny IpAddrKind:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}I możemy wywołać tę funkcję z dowolnym wariantem:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Używanie typów wyliczeniowych (enums) ma jeszcze więcej zalet. Myśląc więcej o naszym typie adresu IP, w tej chwili nie mamy sposobu na przechowywanie rzeczywistych danych adresu IP; wiemy tylko, jakiego jest rodzaju. Biorąc pod uwagę, że właśnie dowiedziałeś się o strukturach w Rozdziale 5, możesz być skłonny do rozwiązania tego problemu za pomocą struktur, jak pokazano w Listingu 6-1.
fn main() {
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}Tutaj zdefiniowaliśmy strukturę IpAddr, która ma dwa pola: pole kind typu IpAddrKind (enum, które zdefiniowaliśmy wcześniej) i pole address typu String. Mamy dwie instancje tej struktury. Pierwsza to home i ma wartość IpAddrKind::V4 jako swoje kind z powiązanymi danymi adresu 127.0.0.1. Druga instancja to loopback. Ma ona inny wariant IpAddrKind jako swoją wartość kind, V6, i ma powiązany z nim adres ::1. Użyliśmy struktury do połączenia wartości kind i address, więc teraz wariant jest powiązany z wartością.
Jednakże, reprezentowanie tej samej koncepcji używając tylko typu wyliczeniowego jest bardziej zwięzłe: zamiast typu wyliczeniowego wewnątrz struktury, możemy umieścić dane bezpośrednio w każdym wariancie typu wyliczeniowego. Ta nowa definicja typu wyliczeniowego IpAddr mówi, że zarówno warianty V4, jak i V6 będą miały powiązane wartości String:
fn main() {
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
}Dane do każdego wariantu enum dołączamy bezpośrednio, więc nie ma potrzeby używania dodatkowej struktury. W tym przypadku łatwiej jest również zauważyć inną cechę działania enumów: nazwa każdego zdefiniowanego przez nas wariantu enum staje się również funkcją, która konstruuje instancję enum. Oznacza to, że IpAddr::V4() jest wywołaniem funkcji, która przyjmuje argument String i zwraca instancję typu IpAddr. Tę funkcję konstruującą otrzymujemy automatycznie w wyniku zdefiniowania enum.
Istnieje jeszcze jedna zaleta używania typu wyliczeniowego zamiast struktury: każdy wariant może mieć różne typy i ilości powiązanych danych. Adresy IP wersji czwartej zawsze będą miały cztery komponenty numeryczne o wartościach od 0 do 255. Gdybyśmy chcieli przechowywać adresy V4 jako cztery wartości u8, ale nadal wyrażać adresy V6 jako pojedynczą wartość String, nie bylibyśmy w stanie tego zrobić za pomocą struktury. Typy wyliczeniowe z łatwością radzą sobie z tym przypadkiem:
fn main() {
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
}Pokazaliśmy kilka różnych sposobów definiowania struktur danych do przechowywania adresów IP wersji czwartej i szóstej. Jednak, jak się okazuje, chęć przechowywania adresów IP i kodowania ich rodzaju jest tak powszechna, że biblioteka standardowa ma definicję, której możemy użyć! Przyjrzyjmy się, jak biblioteka standardowa definiuje IpAddr. Ma ona dokładnie ten sam typ wyliczeniowy i warianty, które zdefiniowaliśmy i użyliśmy, ale osadza dane adresowe w wariantach w postaci dwóch różnych struktur, które są definiowane inaczej dla każdego wariantu:
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}Ten kod ilustruje, że wariant enum może zawierać dowolny rodzaj danych: ciągi znaków, typy numeryczne lub struktury, na przykład. Może nawet zawierać inny enum! Ponadto, typy biblioteki standardowej często nie są o wiele bardziej skomplikowane niż to, co sam byś wymyślił.
Zauważ, że choć biblioteka standardowa zawiera definicję dla IpAddr, nadal możemy tworzyć i używać własnej definicji bez konfliktu, ponieważ nie wprowadziliśmy definicji z biblioteki standardowej do naszego zasięgu. Więcej o wprowadzaniu typów do zasięgu omówimy w Rozdziale 7.
Przyjrzyjmy się innemu przykładowi typu wyliczeniowego w Listingu 6-2: ten ma szeroką gamę typów osadzonych w swoich wariantach.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Ten typ wyliczeniowy ma cztery warianty o różnych typach:
Quit: Nie ma z nim związanych żadnych danychMove: Ma nazwane pola, podobnie jak strukturaWrite: Zawiera pojedynczyStringChangeColor: Zawiera trzy wartościi32
Definiowanie enum z wariantami takimi jak te w Listingu 6-2 jest podobne do definiowania różnych rodzajów definicji struktur, z tą różnicą, że enum nie używa słowa kluczowego struct, a wszystkie warianty są zgrupowane pod typem Message. Następujące struktury mogłyby przechowywać te same dane, co poprzednie warianty enum:
struct QuitMessage; // struktura jednostkowa
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // struktura krotki
struct ChangeColorMessage(i32, i32, i32); // struktura krotki
fn main() {}Ale gdybyśmy użyli różnych struktur, z których każda ma swój własny typ, nie moglibyśmy tak łatwo zdefiniować funkcji, która przyjmowałaby dowolny z tych rodzajów wiadomości, jak w przypadku typu wyliczeniowego Message zdefiniowanego w Listingu 6-2, który jest pojedynczym typem.
Istnieje jeszcze jedno podobieństwo między typami wyliczeniowymi a strukturami: tak jak jesteśmy w stanie definiować metody w strukturach za pomocą impl, tak samo jesteśmy w stanie definiować metody w typach wyliczeniowych. Oto metoda o nazwie call, którą moglibyśmy zdefiniować w naszym typie wyliczeniowym Message:
fn main() {
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// treść metody zostałaby zdefiniowana tutaj
}
}
let m = Message::Write(String::from("hello"));
m.call();
}Treść metody użyłaby self, aby uzyskać wartość, na której wywołaliśmy metodę. W tym przykładzie utworzyliśmy zmienną m, która ma wartość Message::Write(String::from("hello")), i to właśnie będzie self w treści metody call, gdy zostanie uruchomione m.call().
Przyjrzyjmy się innemu enumowi w bibliotece standardowej, który jest bardzo powszechny i użyteczny: Option.
Typ wyliczeniowy Option
Ta sekcja bada studium przypadku Option, które jest innym typem wyliczeniowym zdefiniowanym przez bibliotekę standardową. Typ Option koduje bardzo powszechny scenariusz, w którym wartość może być czymś, albo może być niczym.
Na przykład, jeśli zażądasz pierwszego elementu z niepustej listy, otrzymasz wartość. Jeśli zażądasz pierwszego elementu z pustej listy, otrzymasz nic. Wyrażenie tej koncepcji w kategoriach systemu typów oznacza, że kompilator może sprawdzić, czy obsłużyłeś wszystkie przypadki, które powinieneś obsłużyć; ta funkcjonalność może zapobiegać błędom, które są niezwykle powszechne w innych językach programowania.
Projektowanie języków programowania często rozpatruje się w kategoriach tego, jakie funkcje się uwzględnia, ale funkcje, które się wyklucza, również są ważne. Rust nie posiada funkcji null, którą ma wiele innych języków. Null to wartość, która oznacza, że nie ma tam żadnej wartości. W językach z null, zmienne mogą zawsze być w jednym z dwóch stanów: null lub nie-null.
W swojej prezentacji z 2009 roku „Null References: The Billion Dollar Mistake” Tony Hoare, wynalazca wartości null, powiedział:
Nazywam to moim miliardowym błędem. W tamtym czasie projektowałem pierwszy kompleksowy system typów dla referencji w języku obiektowym. Moim celem było zapewnienie, że wszelkie użycie referencji powinno być absolutnie bezpieczne, z automatycznym sprawdzaniem wykonywanym przez kompilator. Ale nie mogłem oprzeć się pokusie wprowadzenia referencji null, po prostu dlatego, że była tak łatwa do zaimplementowania. Doprowadziło to do niezliczonych błędów, luk w zabezpieczeniach i awarii systemów, które prawdopodobnie spowodowały miliard dolarów bólu i szkód w ciągu ostatnich czterdziestu lat.
Problem z wartościami null polega na tym, że jeśli spróbujesz użyć wartości null jako wartości nie-null, otrzymasz jakiś błąd. Ponieważ ta właściwość null lub nie-null jest wszechobecna, niezwykle łatwo jest popełnić tego rodzaju błąd.
Jednak koncepcja, którą null próbuje wyrazić, jest nadal użyteczna: null to wartość, która jest obecnie nieprawidłowa lub nieobecna z jakiegoś powodu.
Problem nie leży w samej koncepcji, lecz w konkretnej implementacji. W związku z tym Rust nie posiada wartości null, ale ma enum, który może kodować koncepcję obecności lub braku wartości. Tym enumem jest Option<T>, i jest on zdefiniowany przez bibliotekę standardową w następujący sposób:
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}Typ wyliczeniowy Option<T> jest tak użyteczny, że jest nawet włączony do preambuly; nie musisz jawnie wprowadzać go do zasięgu. Jego warianty są również włączone do preambuly: możesz używać Some i None bezpośrednio bez prefiksu Option::. Typ wyliczeniowy Option<T> jest nadal zwykłym typem wyliczeniowym, a Some(T) i None są nadal wariantami typu Option<T>.
Składnia <T> to cecha Rust, o której jeszcze nie mówiliśmy. Jest to ogólny parametr typu, a o ogólnych typach szerzej omówimy w Rozdziale 10. Na razie musisz wiedzieć, że <T> oznacza, że wariant Some typu wyliczeniowego Option może przechowywać pojedynczy element danych dowolnego typu, a każdy konkretny typ, który zostanie użyty zamiast T, sprawia, że cały typ Option<T> staje się innym typem. Oto kilka przykładów użycia wartości Option do przechowywania typów liczbowych i znakowych:
fn main() {
let some_number = Some(5);
let some_char = Some('e');
let absent_number: Option<i32> = None;
}Typ some_number to Option<i32>. Typ some_char to Option<char>, co jest innym typem. Rust może wywnioskować te typy, ponieważ określiliśmy wartość w wariancie Some. Dla absent_number, Rust wymaga od nas adnotacji całego typu Option: kompilator nie może wywnioskować typu, który będzie przechowywał odpowiadający mu wariant Some, patrząc tylko na wartość None. Tutaj mówimy Rustowi, że chcemy, aby absent_number był typu Option<i32>.
Kiedy mamy wartość Some, wiemy, że wartość jest obecna, a wartość jest przechowywana w Some. Kiedy mamy wartość None, w pewnym sensie oznacza to to samo co null: nie mamy ważnej wartości. Dlaczego więc Option<T> jest lepsze niż null?
Krótko mówiąc, ponieważ Option<T> i T (gdzie T może być dowolnym typem) są różnymi typami, kompilator nie pozwoli nam użyć wartości Option<T> tak, jakby była ona na pewno prawidłową wartością. Na przykład ten kod nie skompiluje się, ponieważ próbuje dodać i8 do Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}Jeśli uruchomimy ten kod, otrzymamy komunikat o błędzie podobny do tego:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` do `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ brak implementacji dla `i8 + Option<i8>`
|
= help: cecha `Add<Option<i8>>` nie jest zaimplementowana dla `i8`
= help: następujące inne typy implementują cechę `Add<Rhs>`:
`&i8` implementuje `Add<i8>`
`&i8` implementuje `Add`
`i8` implementuje `Add<&i8>`
`i8` implementuje `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Intensywnie! W efekcie ten komunikat o błędzie oznacza, że Rust nie rozumie, jak dodać i8 i Option<i8>, ponieważ są to różne typy. Kiedy mamy wartość typu takiego jak i8 w Rust, kompilator zapewni, że zawsze mamy prawidłową wartość. Możemy postępować pewnie, nie musząc sprawdzać wartości null przed użyciem tej wartości. Tylko wtedy, gdy mamy Option<i8> (lub dowolny typ wartości, z którym pracujemy), musimy martwić się o ewentualny brak wartości, a kompilator upewni się, że obsłużymy ten przypadek przed użyciem wartości.
Innymi słowy, musisz przekonwertować Option<T> na T, zanim będziesz mógł wykonywać operacje T. Ogólnie rzecz biorąc, pomaga to wychwycić jeden z najczęstszych problemów z null: założenie, że coś nie jest null, gdy w rzeczywistości jest.
Eliminowanie ryzyka błędnego założenia wartości nie-null pomaga ci być pewniejszym swojego kodu. Aby mieć wartość, która potencjalnie może być null, musisz jawnie się na to zgodzić, czyniąc typ tej wartości Option<T>. Następnie, gdy używasz tej wartości, musisz jawnie obsłużyć przypadek, gdy wartość jest null. Wszędzie tam, gdzie wartość ma typ, który nie jest Option<T>, możesz bezpiecznie założyć, że wartość nie jest null. Była to celowa decyzja projektowa dla Rust, aby ograniczyć wszechobecność wartości null i zwiększyć bezpieczeństwo kodu w Rust.
Więc jak wyciągnąć wartość T z wariantu Some, gdy masz wartość typu Option<T>, aby móc jej użyć? Enum Option<T> ma wiele metod, które są przydatne w różnych sytuacjach; możesz je sprawdzić w jej dokumentacji. Zapoznanie się z metodami w Option<T> będzie niezwykle pomocne w Twojej podróży z Rust.
Ogólnie rzecz biorąc, aby użyć wartości Option<T>, chcesz mieć kod, który obsłuży każdy wariant. Chcesz, aby pewien kod uruchamiał się tylko wtedy, gdy masz wartość Some(T), i ten kod może używać wewnętrznego T. Chcesz, aby inny kod uruchamiał się tylko wtedy, gdy masz wartość None, a ten kod nie ma dostępnej wartości T. Wyrażenie match jest konstrukcją przepływu sterowania, która robi to właśnie w przypadku enumów: uruchamia inny kod w zależności od wariantu enum, który posiada, a ten kod może używać danych zawartych w pasującej wartości.
Konstrukcja kontroli przepływu `match`
Konstrukcja kontroli przepływu match
Rust ma niezwykle potężną konstrukcję kontroli przepływu o nazwie match, która pozwala porównywać wartość z serią wzorców, a następnie wykonywać kod na podstawie pasującego wzorca. Wzorce mogą składać się z literałów, nazw zmiennych, symboli wieloznacznych i wielu innych rzeczy; Rozdział 19 obejmuje wszystkie różne rodzaje wzorców i to, co robią. Siła match pochodzi z ekspresywności wzorców i faktu, że kompilator potwierdza, że wszystkie możliwe przypadki są obsługiwane.
Pomyśl o wyrażeniu match jak o maszynie do sortowania monet: monety zjeżdżają po torze z otworami o różnej wielkości, a każda moneta wpada przez pierwszy otwór, do którego pasuje. W ten sam sposób wartości przechodzą przez każdy wzorzec w match, a przy pierwszym wzorcu, do którego wartość „pasuje”, wartość wpada do skojarzonego bloku kodu, aby zostać użyta podczas wykonania.
Skoro mowa o monetach, użyjmy ich jako przykładu z match! Możemy napisać funkcję, która przyjmuje nieznaną monetę amerykańską i, podobnie jak maszyna licząca, określa, jaka to moneta i zwraca jej wartość w centach, jak pokazano w Listingu 6-3.
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}Rozłóżmy match w funkcji value_in_cents. Najpierw wymieniamy słowo kluczowe match, po którym następuje wyrażenie, które w tym przypadku jest wartością coin. To wydaje się bardzo podobne do wyrażenia warunkowego używanego z if, ale jest duża różnica: z if warunek musi ewaluować do wartości boolowskiej, ale tutaj może to być dowolny typ. Typ coin w tym przykładzie to enum Coin, który zdefiniowaliśmy w pierwszej linii.
Następne są ramiona match. Ramka składa się z dwóch części: wzorca i pewnego kodu. Pierwsza ramka ma wzorzec, którym jest wartość Coin::Penny, a następnie operator =>, który oddziela wzorzec od kodu do uruchomienia. Kod w tym przypadku to po prostu wartość 1. Każda ramka jest oddzielona od następnej przecinkiem.
Kiedy wyrażenie match jest wykonywane, porównuje ono wynikową wartość z wzorcem każdej gałęzi, po kolei. Jeśli wzorzec pasuje do wartości, kod skojarzony z tym wzorcem jest wykonywany. Jeśli ten wzorzec nie pasuje do wartości, wykonanie przechodzi do następnej gałęzi, podobnie jak w maszynie do sortowania monet. Możemy mieć tyle gałęzi, ile potrzebujemy: w Listingu 6-3, nasz match ma cztery gałęzie.
Kod skojarzony z każdym ramieniem jest wyrażeniem, a wynikowa wartość wyrażenia w pasującym ramieniu jest wartością, która jest zwracana dla całego wyrażenia match.
Zazwyczaj nie używamy nawiasów klamrowych, jeśli kod gałęzi match jest krótki, jak w Listingu 6-3, gdzie każda gałąź po prostu zwraca wartość. Jeśli chcesz uruchomić wiele linii kodu w gałęzi match, musisz użyć nawiasów klamrowych, a przecinek po gałęzi jest wtedy opcjonalny. Na przykład, poniższy kod drukuje „Lucky penny!” za każdym razem, gdy metoda jest wywoływana z Coin::Penny, ale nadal zwraca ostatnią wartość bloku, 1:
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
println!("Szczęśliwy grosz!");
1
}
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}Wzorce, które wiążą się z wartościami
Inną przydatną cechą ramion match jest to, że mogą one wiązać się z częściami wartości, które pasują do wzorca. W ten sposób możemy wyodrębniać wartości z wariantów enum.
Na przykład, zmieńmy jeden z naszych wariantów enum, aby przechowywał w sobie dane. Od 1999 do 2008 roku Stany Zjednoczone biły ćwierćdolarówki z różnymi wzorami dla każdego z 50 stanów po jednej stronie. Żadne inne monety nie otrzymały wzorów stanów, więc tylko ćwierćdolarówki mają tę dodatkową wartość. Możemy dodać tę informację do naszego enum, zmieniając wariant Quarter tak, aby zawierał wartość UsState przechowywaną w środku, co zrobiliśmy w Listingu 6-4.
#[derive(Debug)] // abyśmy mogli za chwilę sprawdzić stan
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {}Wyobraźmy sobie, że przyjaciel próbuje zebrać wszystkie 50 monet stanowych. Podczas gdy my sortujemy naszą drobną monetę według typu monety, będziemy również wywoływać nazwę stanu związanego z każdą monetą, tak aby jeśli jest to moneta, której nasz przyjaciel nie ma, mógł ją dodać do swojej kolekcji.
W wyrażeniu match dla tego kodu dodajemy zmienną o nazwie state do wzorca, który pasuje do wartości wariantu Coin::Quarter. Gdy pasuje Coin::Quarter, zmienna state zostanie powiązana z wartością stanu tej ćwiartki. Następnie możemy użyć state w kodzie dla tego ramienia, w ten sposób:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("Moneta stanowa z {state:?}!");
25
}
}
}
fn main() {
value_in_cents(Coin::Quarter(UsState::Alaska));
}Gdybyśmy wywołali value_in_cents(Coin::Quarter(UsState::Alaska)), coin byłby Coin::Quarter(UsState::Alaska). Kiedy porównamy tę wartość z każdym z ramion match, żadne z nich nie pasuje, dopóki nie dotrzemy do Coin::Quarter(state). W tym momencie wiązanie dla state będzie wartością UsState::Alaska. Możemy następnie użyć tego wiązania w wyrażeniu println!, uzyskując w ten sposób wewnętrzną wartość stanu z wariantu enum Coin dla Quarter.
Wzorzec Option<T> match
W poprzedniej sekcji chcieliśmy wydobyć wewnętrzną wartość T z przypadku Some podczas używania Option<T>; możemy również obsługiwać Option<T> za pomocą match, tak jak zrobiliśmy to z enumem Coin! Zamiast porównywać monety, będziemy porównywać warianty Option<T>, ale sposób działania wyrażenia match pozostaje taki sam.
Powiedzmy, że chcemy napisać funkcję, która przyjmuje Option<i32> i, jeśli w środku jest wartość, dodaje do niej 1. Jeśli w środku nie ma wartości, funkcja powinna zwrócić wartość None i nie próbować wykonywać żadnych operacji.
Tę funkcję bardzo łatwo napisać, dzięki match, i będzie ona wyglądać jak Listing 6-5.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Przyjrzyjmy się dokładniej pierwszemu wykonaniu plus_one. Kiedy wywołujemy plus_one(five), zmienna x w ciele plus_one będzie miała wartość Some(5). Następnie porównujemy ją z każdym ramieniem match:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Wartość Some(5) nie pasuje do wzorca None, więc przechodzimy do następnego ramienia:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Czy Some(5) pasuje do Some(i)? Tak! Mamy ten sam wariant. i wiąże się z wartością zawartą w Some, więc i przyjmuje wartość 5. Następnie kod w ramieniu match jest wykonywany, więc dodajemy 1 do wartości i i tworzymy nową wartość Some z naszym łącznym 6 w środku.
Rozważmy teraz drugie wywołanie plus_one w Listingu 6-5, gdzie x jest None. Wchodzimy do match i porównujemy z pierwszym ramieniem:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Pasuje! Nie ma wartości do dodania, więc program zatrzymuje się i zwraca wartość None po prawej stronie =>. Ponieważ pierwsze ramię pasowało, żadne inne ramiona nie są porównywane.
Łączenie match i enumów jest przydatne w wielu sytuacjach. Będziesz często widział ten wzorzec w kodzie Rust: match z enumem, powiązanie zmiennej z danymi wewnątrz, a następnie wykonanie kodu na tej podstawie. Na początku jest to trochę trudne, ale gdy się do tego przyzwyczaisz, będziesz żałował, że nie miałeś tego we wszystkich językach. Jest to konsekwentnie ulubiona funkcja użytkowników.
Dopasowania są wyczerpujące
Jest jeszcze jeden aspekt match, który musimy omówić: wzorce ramion muszą obejmować wszystkie możliwości. Rozważmy tę wersję naszej funkcji plus_one, która zawiera błąd i nie skompiluje się:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Nie obsłużyliśmy przypadku None, więc ten kod spowoduje błąd. Na szczęście jest to błąd, który Rust potrafi wyłapać. Jeśli spróbujemy skompilować ten kod, otrzymamy taki błąd:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` nie pokryto
--> src/main.rs:3:15
|
3 | match x {
| ^ wzorzec `None` nie pokryto
|
note: `Option<i32>` zdefiniowano tutaj
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: nie pokryto
= note: dopasowana wartość jest typu `Option<i32>`
help: upewnij się, że wszystkie możliwe przypadki są obsługiwane, dodając ramię dopasowania z wzorcem wieloznacznym lub jawnym wzorcem, jak pokazano
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust wie, że nie objęliśmy każdego możliwego przypadku i nawet wie, który wzorzec pominęliśmy! Dopasowania w Rust są wyczerpujące: Musimy wyczerpać każdą ostatnią możliwość, aby kod był poprawny. Zwłaszcza w przypadku Option<T>, gdy Rust uniemożliwia nam zapomnienie o jawnej obsłudze przypadku None, chroni nas przed zakładaniem, że mamy wartość, gdy możemy mieć null, co uniemożliwia popełnienie błędu miliarda dolarów, o którym mówiliśmy wcześniej.
Wzorce ogólne (Catch-All) i symbol zastępczy _
Używając typów wyliczeniowych, możemy również podejmować specjalne działania dla kilku konkretnych wartości, ale dla wszystkich innych wartości podjąć jedno domyślne działanie. Wyobraźmy sobie, że implementujemy grę, w której, jeśli na rzucie kostką wypadnie 3, gracz nie rusza się, ale zamiast tego dostaje fantazyjny nowy kapelusz. Jeśli wypadnie 7, gracz traci fantazyjny kapelusz. Dla wszystkich innych wartości, gracz przesuwa się o tę liczbę pól na planszy. Oto match, który implementuje tę logikę, z wynikiem rzutu kostką zakodowanym na stałe, a nie wartością losową, a cała inna logika jest reprezentowana przez funkcje bez ciał, ponieważ ich faktyczne zaimplementowanie wykracza poza zakres tego przykładu:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),
}
fn add_fancy_hat() {}
fn fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
}Dla pierwszych dwóch gałęzi wzorcami są literały 3 i 7. Dla ostatniej gałęzi, która obejmuje wszystkie inne możliwe wartości, wzorcem jest zmienna, którą nazwaliśmy other. Kod uruchamiany dla gałęzi other używa zmiennej, przekazując ją do funkcji move_player.
Ten kod kompiluje się, chociaż nie wymieniliśmy wszystkich możliwych wartości, jakie może mieć u8, ponieważ ostatni wzorzec będzie pasował do wszystkich wartości, które nie zostały specjalnie wymienione. Ten wzorzec typu catch-all spełnia wymóg, że match musi być wyczerpujące. Zauważ, że musimy umieścić ramię typu catch-all na końcu, ponieważ wzorce są oceniane po kolei. Gdybyśmy umieścili ramię typu catch-all wcześniej, inne ramiona nigdy by się nie uruchomiły, więc Rust ostrzeże nas, jeśli dodamy ramiona po catch-all!
Rust posiada również wzorzec, którego możemy użyć, gdy chcemy zastosować wzorzec ogólny, ale nie chcemy używać wartości w tym wzorcu: _ to specjalny wzorzec, który pasuje do dowolnej wartości i nie wiąże się z tą wartością. To mówi Rustowi, że nie będziemy używać tej wartości, więc Rust nie ostrzeże nas o nieużywanej zmiennej.
Zmieńmy zasady gry: teraz, jeśli wyrzucisz coś innego niż 3 lub 7, musisz rzucić ponownie. Nie potrzebujemy już używać wartości typu catch-all, więc możemy zmienić nasz kod, aby używał _ zamiast zmiennej o nazwie other:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => reroll(),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
}Ten przykład również spełnia wymóg wyczerpującego dopasowania, ponieważ jawnie ignorujemy wszystkie inne wartości w ostatnim ramieniu; niczego nie pominęliśmy.
Na koniec zmienimy zasady gry jeszcze raz, tak aby nic innego nie działo się w Twojej turze, jeśli wyrzucisz coś innego niż 3 lub 7. Możemy to wyrazić, używając wartości jednostkowej (typu pustej krotki, o której wspominaliśmy w sekcji „Typ krotki”) jako kodu, który towarzyszy ramieniu _:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
}Tutaj jawnie mówimy Rustowi, że nie zamierzamy używać żadnej innej wartości, która nie pasuje do wzorca w poprzednim ramieniu, i nie chcemy uruchamiać żadnego kodu w tym przypadku.
Więcej o wzorcach i dopasowywaniu omówimy w Rozdziale 19. Na razie przejdziemy do składni if let, która może być użyteczna w sytuacjach, gdy wyrażenie match jest nieco rozwlekłe.
Zwięzła kontrola przepływu z `if let` i `let...else`
Zwięzła kontrola przepływu z if let i let...else
Składnia if let pozwala połączyć if i let w mniej rozwlekły sposób obsługi wartości pasujących do jednego wzorca, ignorując pozostałe. Rozważ program z Listingu 6-6, który dopasowuje wartość Option<u8> w zmiennej config_max, ale chce wykonać kod tylko wtedy, gdy wartość jest wariantem Some.
fn main() {
let config_max = Some(3u8);
match config_max {
Some(max) => println!("Maksymalna wartość skonfigurowana to {max}"),
_ => (),
}
}Jeśli wartość jest Some, drukujemy wartość z wariantu Some, wiążąc ją ze zmienną max we wzorcu. Nie chcemy nic robić z wartością None. Aby spełnić wyrażenie match, musimy dodać _ => () po przetworzeniu tylko jednego wariantu, co jest irytującym, powtarzalnym kodem do dodania.
Zamiast tego, moglibyśmy to napisać w krótszy sposób za pomocą if let. Poniższy kod zachowuje się tak samo jak match w Listingu 6-6:
fn main() {
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("Maksymalna wartość skonfigurowana to {max}");
}
}Składnia if let przyjmuje wzorzec i wyrażenie oddzielone znakiem równości. Działa tak samo jak match, gdzie wyrażenie jest przekazywane do match, a wzorzec jest jego pierwszym ramieniem. W tym przypadku wzorzec to Some(max), a max wiąże się z wartością wewnątrz Some. Możemy następnie użyć max w ciele bloku if let w ten sam sposób, w jaki użyliśmy max w odpowiadającym ramieniu match. Kod w bloku if let jest wykonywany tylko wtedy, gdy wartość pasuje do wzorca.
Używanie if let oznacza mniej pisania, mniej wcięć i mniej kodu szablonowego. Tracisz jednak wyczerpujące sprawdzanie, które wymusza match, a które gwarantuje, że nie zapomnisz obsłużyć żadnych przypadków. Wybór między match a if let zależy od tego, co robisz w konkretnej sytuacji i czy zyskanie zwięzłości jest odpowiednim kompromisem za utratę wyczerpującego sprawdzania.
Innymi słowy, if let można traktować jako składnię cukrową dla match, która uruchamia kod, gdy wartość pasuje do jednego wzorca, a następnie ignoruje wszystkie inne wartości.
Możemy dołączyć else do if let. Blok kodu, który towarzyszy else, jest taki sam jak blok kodu, który towarzyszyłby przypadkowi _ w wyrażeniu match równoważnym if let i else. Przypomnij sobie definicję enum Coin w Listingu 6-4, gdzie wariant Quarter zawierał również wartość UsState. Gdybyśmy chcieli zliczać wszystkie monety inne niż ćwierćdolarówki, jednocześnie ogłaszając stan ćwierćdolarówek, moglibyśmy to zrobić za pomocą wyrażenia match, tak jak to:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
match coin {
Coin::Quarter(state) => println!("Moneta stanowa z {state:?}!"),
_ => count += 1,
}
}Albo moglibyśmy użyć wyrażenia if let i else, w ten sposób:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("Moneta stanowa z {state:?}!");
} else {
count += 1;
}
}Pozostawanie na „szczęśliwej ścieżce” z let...else
Częstym wzorcem jest wykonanie pewnego obliczenia, gdy wartość jest obecna, a w przeciwnym razie zwrócenie wartości domyślnej. Kontynuując nasz przykład monet z wartością UsState, gdybyśmy chcieli powiedzieć coś zabawnego w zależności od wieku stanu na monecie, moglibyśmy wprowadzić metodę w UsState do sprawdzania wieku stanu, w ten sposób:
#[derive(Debug)] // abyśmy mogli za chwilę sprawdzić stan
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} jest dość stare, jak na Amerykę!"))
} else {
Some(format!("{state:?} jest stosunkowo nowe."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Następnie, moglibyśmy użyć if let, aby dopasować typ monety, wprowadzając zmienną state w treści warunku, jak w Listingu 6-7.
#[derive(Debug)] // abyśmy mogli za chwilę sprawdzić stan
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} jest dość stare, jak na Amerykę!"))
} else {
Some(format!("{state:?} jest stosunkowo nowe."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}To załatwia sprawę, ale przenosi pracę do ciała instrukcji if let, a jeśli praca do wykonania jest bardziej skomplikowana, trudno może być dokładnie śledzić, jak gałęzie najwyższego poziomu się ze sobą łączą. Moglibyśmy również wykorzystać fakt, że wyrażenia produkują wartość, aby albo wyprodukować state z if let, albo zwrócić wcześnie, jak w Listingu 6-8. (Podobną rzecz można by zrobić z match.)
#[derive(Debug)] // abyśmy mogli za chwilę sprawdzić stan
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let state = if let Coin::Quarter(state) = coin {
state
} else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} jest dość stare, jak na Amerykę!"))
} else {
Some(format!("{state:?} jest stosunkowo nowe."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}To jest w pewnym sensie trochę irytujące! Jedna gałąź if let produkuje wartość, a druga całkowicie zwraca z funkcji.
Aby ten powszechny wzorzec był łatwiejszy do wyrażenia, Rust posiada let...else. Składnia let...else przyjmuje wzorzec po lewej stronie i wyrażenie po prawej, bardzo podobnie do if let, ale nie ma gałęzi if, tylko gałąź else. Jeśli wzorzec pasuje, to wiąże wartość ze wzorca w zewnętrznym zasięgu. Jeśli wzorzec nie pasuje, program przechodzi do gałęzi else, która musi zwrócić wartość z funkcji.
W Listingu 6-9 możesz zobaczyć, jak wygląda Listing 6-8, gdy używamy let...else zamiast if let.
#[derive(Debug)] // abyśmy mogli za chwilę sprawdzić stan
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let Coin::Quarter(state) = coin else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} jest dość stare, jak na Amerykę!"))
} else {
Some(format!("{state:?} jest stosunkowo nowe."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Zauważ, że w ten sposób pozostaje ona na „szczęśliwej ścieżce” w głównym ciele funkcji, bez znacząco różniącego się przepływu sterowania dla dwóch gałęzi, tak jak to było w przypadku if let.
Jeśli znajdziesz się w sytuacji, w której logika Twojego programu jest zbyt rozwlekła, aby wyrazić ją za pomocą match, pamiętaj, że if let i let...else również są w Twojej skrzynce narzędziowej Rust.
Podsumowanie
Omówiliśmy, jak używać typów wyliczeniowych do tworzenia niestandardowych typów, które mogą być jednym z zestawu wyliczonych wartości. Pokazaliśmy, jak typ Option<T> z biblioteki standardowej pomaga używać systemu typów do zapobiegania błędom. Gdy wartości wyliczeniowe zawierają dane, możesz użyć match lub if let do wyodrębnienia i użycia tych wartości, w zależności od liczby przypadków, które musisz obsłużyć.
Twoje programy w Rust mogą teraz wyrażać koncepcje w Twojej dziedzinie za pomocą struktur i typów wyliczeniowych. Tworzenie niestandardowych typów do użycia w Twoim API zapewnia bezpieczeństwo typów: kompilator upewni się, że Twoje funkcje otrzymują tylko wartości typu, którego oczekuje każda funkcja.
Aby zapewnić użytkownikom dobrze zorganizowane API, które jest proste w użyciu i eksponuje dokładnie to, czego będą potrzebować, przejdźmy teraz do modułów Rust.
Pakiety, Kapsuły (Crate) i Moduły
W miarę pisania dużych programów organizacja kodu staje się coraz ważniejsza.Grupując powiązane funkcjonalności i oddzielając kod o różnych cechach,wyjaśnisz, gdzie znaleźć kod implementujący określoną funkcję i gdzieudać się, aby zmienić sposób działania funkcji.
Napisane do tej pory programy znajdowały się w jednym module w jednym pliku. W miarę rozrastania się projektu, kod powinien być dzielony na wiele modułów, a następnie na wiele plików. Pakiet może zawierać wiele kapsuł binarnych i opcjonalnie jedną kapsułę biblioteczną. W miarę rozrastania się pakietu, można wyodrębnić jego części do osobnych kapsuł, które stają się zewnętrznymi zależnościami. Ten rozdział obejmuje wszystkie te techniki. Dla bardzo dużych projektów składających się z zestawu powiązanych ze sobą pakietów, które ewoluują razem, Cargo oferuje obszary robocze, które omówimy w sekcji „Obszary robocze Cargo” w Rozdziale 14.
Omówimy również hermetyzację szczegółów implementacji, co pozwala na ponowne wykorzystanie kodu na wyższym poziomie: po zaimplementowaniu operacji, inny kod może wywołać twój kod za pośrednictwem jego publicznego interfejsu, bez konieczności znajomości działania implementacji. Sposób, w jaki piszesz kod, określa, które części są publiczne do użytku przez inny kod, a które są prywatnymi szczegółami implementacji, które zastrzegasz sobie prawo do zmiany. Jest to kolejny sposób na ograniczenie ilości szczegółów, które musisz mieć w głowie.
Powiązaną koncepcją jest zasięg: zagnieżdżony kontekst, w którym pisany jest kod, ma zestaw nazw, które są zdefiniowane jako „w zasięgu”. Podczas czytania, pisania i kompilowania kodu, programiści i kompilatory muszą wiedzieć, czy dana nazwa w danym miejscu odnosi się do zmiennej, funkcji, struktury, typu wyliczeniowego, modułu, stałej lub innego elementu i co ten element oznacza. Możesz tworzyć zasięgi i zmieniać, które nazwy są w zasięgu lub poza nim. Nie możesz mieć dwóch elementów o tej samej nazwie w tym samym zasięgu; dostępne są narzędzia do rozwiązywania konfliktów nazw.
Rust ma szereg funkcji, które pozwalają zarządzać organizacją kodu, w tym to, które szczegóły są ujawniane, które są prywatne i jakie nazwy znajdują się w każdym zasięgu w twoich programach. Te funkcje, czasami zbiorczo nazywane systemem modułów, obejmują:
- Pakiety: Funkcja Cargo, która umożliwia budowanie, testowanie i udostępnianie kapsuł (crates)
- Kapsuły (Crates): Drzewo modułów, które produkuje bibliotekę lub plik wykonywalny
- Moduły i
use: Pozwalają kontrolować organizację, zasięg i prywatność ścieżek - Ścieżki: Sposób nazywania elementu, takiego jak struktura, funkcja lub moduł
W tym rozdziale omówimy wszystkie te funkcje, dowiemy się, jak ze sobą współdziałają i wyjaśnimy, jak używać ich do zarządzania zasięgiem. Na koniec powinieneś mieć solidne zrozumienie systemu modułów i być w stanie pracować z zasięgami jak profesjonalista!
Pakiety i Kapsuły (Crate)
Pakiety i Kapsuły (Crate)
Pierwsze części systemu modułów, które omówimy, to pakiety i kapsuły.
Kapsuła (crate) to najmniejsza ilość kodu, jaką kompilator Rust rozważa w danym momencie. Nawet jeśli uruchomisz rustc zamiast cargo i przekażesz pojedynczy plik źródłowy (tak jak zrobiliśmy to w sekcji „Podstawy programu w Rust” w Rozdziale 1), kompilator traktuje ten plik jako kapsułę. Kapsuły mogą zawierać moduły, a moduły mogą być zdefiniowane w innych plikach, które są kompilowane razem z kapsułą, jak zobaczymy w kolejnych sekcjach.
Kapsuła może występować w jednej z dwóch form: kapsuła binarna lub kapsuła biblioteczna. Kapsuły binarne to programy, które można skompilować do pliku wykonywalnego, który można uruchomić, na przykład program wiersza poleceń lub serwer. Każda z nich musi mieć funkcję o nazwie main, która definiuje, co dzieje się, gdy plik wykonywalny jest uruchamiany. Wszystkie kapsuły, które do tej pory utworzyliśmy, były kapsułami binarnymi.
Kapsuły biblioteczne nie mają funkcji main i nie kompilują się do pliku wykonywalnego. Zamiast tego definiują funkcjonalność przeznaczoną do współdzielenia z wieloma projektami. Na przykład, kapsuła rand, której użyliśmy w Rozdziale 2, zapewnia funkcjonalność generowania liczb losowych. Przez większość czasu, gdy Rustaceans mówią „kapsuła”, mają na myśli kapsułę biblioteczną, i używają „kapsuły” zamiennie z ogólną koncepcją programistyczną „biblioteka”.
Katalog główny kapsuły (crate root) to plik źródłowy, od którego kompilator Rust zaczyna i który stanowi moduł główny twojej kapsuły (szczegółowo wyjaśnimy moduły w sekcji „Kontrola zasięgu i prywatności za pomocą modułów”).
Pakiet to zbiór jednej lub więcej kapsuł (crates), które zapewniają zestaw funkcjonalności. Pakiet zawiera plik Cargo.toml, który opisuje, jak zbudować te kapsuły. Cargo jest faktycznie pakietem, który zawiera kapsułę binarną dla narzędzia wiersza poleceń, którego używałeś do budowania swojego kodu. Pakiet Cargo zawiera również kapsułę biblioteczną, od której zależy kapsuła binarna. Inne projekty mogą zależeć od kapsuły bibliotecznej Cargo, aby używać tej samej logiki, której używa narzędzie wiersza poleceń Cargo.
Pakiet może zawierać dowolną liczbę kapsuł binarnych, ale co najwyżej jedną kapsułę biblioteczną. Pakiet musi zawierać co najmniej jedną kapsułę, niezależnie od tego, czy jest to kapsuła biblioteczna, czy binarna.
Przeanalizujmy, co dzieje się, gdy tworzymy pakiet. Najpierw wpisujemy polecenie cargo new my-project:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
Po uruchomieniu cargo new my-project używamy ls, aby zobaczyć, co Cargo tworzy. W katalogu my-project znajduje się plik Cargo.toml, dając nam pakiet. Jest też katalog src, który zawiera main.rs. Otwórz Cargo.toml w swoim edytorze tekstu i zauważ, że nie ma tam wzmianki o src/main.rs. Cargo przestrzega konwencji, że src/main.rs jest katalogiem głównym kapsuły binarnej o tej samej nazwie co pakiet. Podobnie, Cargo wie, że jeśli katalog pakietu zawiera src/lib.rs, pakiet zawiera kapsułę biblioteczną o tej samej nazwie co pakiet, a src/lib.rs jest jej katalogiem głównym. Cargo przekazuje pliki katalogu głównego kapsuły do rustc w celu zbudowania biblioteki lub pliku binarnego.
Tutaj mamy pakiet, który zawiera tylko src/main.rs, co oznacza, że zawiera tylko kapsułę binarną o nazwie my-project. Jeśli pakiet zawiera src/main.rs i src/lib.rs, ma dwie kapsuły: binarną i biblioteczną, obie o tej samej nazwie co pakiet. Pakiet może mieć wiele kapsuł binarnych, umieszczając pliki w katalogu src/bin: każdy plik będzie osobną kapsułą binarną.
Kontrola zasięgu i prywatności za pomocą modułów
Kontrola zasięgu i prywatności za pomocą modułów
W tej sekcji omówimy moduły i inne części systemu modułów, a mianowicie ścieżki, które pozwalają nadawać nazwy elementom; słowo kluczowe use, które wprowadza ścieżkę do zasięgu; oraz słowo kluczowe pub, aby uczynić elementy publicznymi. Omówimy również słowo kluczowe as, pakiety zewnętrzne i operator glob.
Ściągawka z modułów
Zanim przejdziemy do szczegółów modułów i ścieżek, przedstawiamy tutaj szybkie odniesienie do tego, jak działają moduły, ścieżki, słowo kluczowe use i słowo kluczowe pub w kompilatorze, oraz jak większość programistów organizuje swój kod. Przejdziemy przez przykłady każdej z tych reguł w tym rozdziale, ale jest to świetne miejsce, aby odwołać się do nich jako przypomnienie o tym, jak działają moduły.
- Zacznij od korzenia kapsuły (crate root): Podczas kompilowania kapsuły, kompilator najpierw szuka kodu do skompilowania w pliku korzenia kapsuły (zazwyczaj src/lib.rs dla kapsuły bibliotecznej i src/main.rs dla kapsuły binarnej).
- Deklarowanie modułów: W pliku korzenia kapsuły możesz zadeklarować nowe moduły; powiedzmy, że deklarujesz moduł „garden” za pomocą
mod garden;. Kompilator będzie szukał kodu modułu w tych miejscach:- Wbudowane, w nawiasach klamrowych, które zastępują średnik po
mod garden - W pliku src/garden.rs
- W pliku src/garden/mod.rs
- Wbudowane, w nawiasach klamrowych, które zastępują średnik po
- Deklarowanie podmodułów: W dowolnym pliku innym niż korzeń kapsuły możesz deklarować podmoduły. Na przykład, możesz zadeklarować
mod vegetables;w src/garden.rs. Kompilator będzie szukał kodu podmodułu w katalogu nazwanym dla modułu rodzicielskiego w tych miejscach:- Wbudowane, bezpośrednio po
mod vegetables, w nawiasach klamrowych zamiast średnika - W pliku src/garden/vegetables.rs
- W pliku src/garden/vegetables/mod.rs
- Wbudowane, bezpośrednio po
- Ścieżki do kodu w modułach: Gdy moduł jest częścią twojej kapsuły, możesz odwoływać się do kodu w tym module z dowolnego innego miejsca w tej samej kapsule, o ile zasady prywatności na to pozwalają, używając ścieżki do kodu. Na przykład, typ
Asparagusw module warzyw ogrodowych znajdowałby się podcrate::garden::vegetables::Asparagus. - Prywatne vs publiczne: Kod w module jest domyślnie prywatny dla jego modułów nadrzędnych. Aby moduł był publiczny, zadeklaruj go za pomocą
pub modzamiastmod. Aby elementy w publicznym module były również publiczne, użyjpubprzed ich deklaracjami. - Słowo kluczowe
use: W zasięgu, słowo kluczoweusetworzy skróty do elementów, aby zmniejszyć powtarzanie długich ścieżek. W każdym zasięgu, który może odwoływać się docrate::garden::vegetables::Asparagus, możesz utworzyć skrót za pomocąuse crate::garden::vegetables::Asparagus;, a odtąd musisz tylko napisaćAsparagus, aby użyć tego typu w zasięgu.
Tutaj tworzymy binarną kapsułę o nazwie backyard, która ilustruje te zasady. Katalog kapsuły, również nazwany backyard, zawiera następujące pliki i katalogi:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
Plik główny kapsuły w tym przypadku to src/main.rs, i zawiera:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("Rosnę {plant:?}!");
}Linia pub mod garden; informuje kompilator, aby uwzględnił kod znajdujący się w pliku src/garden.rs, który to plik zawiera:
pub mod vegetables;Tutaj, pub mod vegetables; oznacza, że kod z src/garden/vegetables.rs również jest włączony. Ten kod to:
#[derive(Debug)]
pub struct Asparagus {}Teraz przejdźmy do szczegółów tych zasad i pokażmy je w działaniu!
Grupowanie powiązanego kodu w modułach
Moduły pozwalają nam organizować kod w ramach kapsuły w celu zwiększenia czytelności i łatwego ponownego użycia. Moduły pozwalają nam również kontrolować prywatność elementów, ponieważ kod w module jest domyślnie prywatny. Prywatne elementy to wewnętrzne szczegóły implementacji niedostępne do użytku zewnętrznego. Możemy zdecydować się na uczynienie modułów i elementów w nich publicznymi, co udostępnia je, aby umożliwić zewnętrznemu kodowi ich używanie i zależność od nich.
Na przykład, napiszmy bibliotekę, która zapewnia funkcjonalność restauracji. Zdefiniujemy sygnatury funkcji, ale pozostawimy ich ciała puste, aby skoncentrować się na organizacji kodu, a nie na implementacji restauracji.
W branży restauracyjnej niektóre części restauracji są nazywane „front of house”, a inne „back of house”. Front of house to miejsce, gdzie są klienci; obejmuje to miejsca, gdzie gospodarze sadzają klientów, kelnerzy przyjmują zamówienia i płatności, a barmani przygotowują napoje. Back of house to miejsce, gdzie szefowie kuchni i kucharze pracują w kuchni, zmywacze naczyń sprzątają, a menedżerowie wykonują prace administracyjne.
Aby ustrukturyzować naszą kapsułę w ten sposób, możemy zorganizować jej funkcje w zagnieżdżone moduły. Utwórz nową bibliotekę o nazwie restaurant, uruchamiając cargo new restaurant --lib. Następnie wprowadź kod z Listingu 7-1 do pliku src/lib.rs, aby zdefiniować niektóre moduły i sygnatury funkcji; ten kod to sekcja „front of house”.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}Definiujemy moduł za pomocą słowa kluczowego mod, a następnie nazwę modułu (w tym przypadku front_of_house). Ciało modułu znajduje się następnie w nawiasach klamrowych. Wewnątrz modułów możemy umieszczać inne moduły, jak w tym przypadku moduły hosting i serving. Moduły mogą również zawierać definicje innych elementów, takich jak struktury, typy wyliczeniowe, stałe, cechy, oraz, jak w Listingu 7-1, funkcje.
Używając modułów, możemy grupować powiązane definicje i nazywać ich relacje. Programiści korzystający z tego kodu mogą nawigować po kodzie na podstawie grup, zamiast czytać wszystkie definicje, co ułatwia im znalezienie odpowiednich definicji. Programiści dodający nową funkcjonalność do tego kodu wiedzieliby, gdzie umieścić kod, aby program pozostał uporządkowany.
Wcześniej wspomnieliśmy, że pliki src/main.rs i src/lib.rs nazywane są katalogami głównymi kapsuł (crate roots). Powodem ich nazwy jest to, że zawartość któregokolwiek z tych dwóch plików tworzy moduł o nazwie crate w katalogu głównym struktury modułów kapsuły, znanego jako drzewo modułów.
Listing 7-2 przedstawia drzewo modułów dla struktury z Listingu 7-1.
kapsuła (crate)
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
To drzewo pokazuje, jak niektóre moduły zagnieżdżają się w innych modułach; na przykład, hosting zagnieżdża się w front_of_house. Drzewo pokazuje również, że niektóre moduły są sąsiadami, co oznacza, że są zdefiniowane w tym samym module; hosting i serving są sąsiadami zdefiniowanymi w front_of_house. Jeśli moduł A jest zawarty w module B, mówimy, że moduł A jest dzieckiem modułu B, a moduł B jest rodzicem modułu A. Zauważ, że całe drzewo modułów jest zakorzenione pod niejawnym modułem o nazwie crate.
Drzewo modułów może przypominać drzewo katalogów systemu plików na Twoim komputerze; to bardzo trafne porównanie! Podobnie jak katalogi w systemie plików, używasz modułów do organizacji kodu. I podobnie jak pliki w katalogu, potrzebujemy sposobu na znalezienie naszych modułów.
Ścieżki do odwoływania się do elementu w drzewie modułów
Ścieżki do odwoływania się do elementu w drzewie modułów
Aby wskazać Rustowi, gdzie znaleźć element w drzewie modułów, używamy ścieżki w taki sam sposób, jak używamy ścieżki podczas nawigowania po systemie plików. Aby wywołać funkcję, musimy znać jej ścieżkę.
Ścieżka może przyjmować dwie formy:
- Ścieżka absolutna to pełna ścieżka zaczynająca się od korzenia pakietu;
dla kodu z zewnętrznego pakietu ścieżka absolutna zaczyna się od nazwy
pakietu, a dla kodu z bieżącego pakietu zaczyna się od literału
crate. - Ścieżka względna zaczyna się od bieżącego modułu i używa
self,superlub identyfikatora w bieżącym module.
Zarówno ścieżki absolutne, jak i względne są poprzedzone jednym lub większą
liczbą identyfikatorów oddzielonych podwójnymi dwukropkami (::).
Wracając do Listingu 7-1, powiedzmy, że chcemy wywołać funkcję
add_to_waitlist. To samo, co zapytać: Jaka jest ścieżka do funkcji
add_to_waitlist? Listing 7-3 zawiera Listing 7-1 z usuniętymi niektórymi
modułami i funkcjami.
Pokażemy dwa sposoby wywołania funkcji add_to_waitlist z nowej funkcji,
eat_at_restaurant, zdefiniowanej w korzeniu pakietu. Te ścieżki są poprawne,
ale pozostaje jeszcze jeden problem, który uniemożliwi kompilację tego
przykładu w obecnej postaci. Wyjaśnimy dlaczego za chwilę.
Funkcja eat_at_restaurant jest częścią publicznego API naszego pakietu
bibliotecznego, dlatego oznaczamy ją słowem kluczowym pub. W sekcji
„Udostępnianie ścieżek za pomocą słowa kluczowego
pub” omówimy pub bardziej szczegółowo.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Ścieżka absolutna
crate::front_of_house::hosting::add_to_waitlist();
// Ścieżka względna
front_of_house::hosting::add_to_waitlist();
}add_to_waitlist za pomocą ścieżek absolutnych i względnychZa pierwszym razem, gdy wywołujemy funkcję add_to_waitlist w
eat_at_restaurant, używamy ścieżki absolutnej. Funkcja add_to_waitlist jest
zdefiniowana w tym samym pakiecie co eat_at_restaurant, co oznacza, że możemy
użyć słowa kluczowego crate do rozpoczęcia ścieżki absolutnej. Następnie
dołączamy każdy kolejny moduł, aż dotrzemy do add_to_waitlist. Można sobie
wyobrazić system plików o tej samej strukturze: określilibyśmy ścieżkę
/front_of_house/hosting/add_to_waitlist, aby uruchomić program
add_to_waitlist; użycie nazwy crate do rozpoczęcia od korzenia pakietu jest
podobne do użycia / do rozpoczęcia od korzenia systemu plików w Twojej
shellu.
Za drugim razem, gdy wywołujemy add_to_waitlist w eat_at_restaurant,
używamy ścieżki względnej. Ścieżka zaczyna się od front_of_house, nazwy
modułu zdefiniowanego na tym samym poziomie drzewa modułów co
eat_at_restaurant. Tutaj odpowiednikiem w systemie plików byłaby ścieżka
front_of_house/hosting/add_to_waitlist. Rozpoczęcie od nazwy modułu oznacza,
że ścieżka jest względna.
Wybór między ścieżką względną a absolutną to decyzja, którą podejmiesz w
zależności od projektu i od tego, czy bardziej prawdopodobne jest, że będziesz
przenosić kod definicji elementu oddzielnie od kodu, który go używa, czy też
razem z nim. Na przykład, gdybyśmy przenieśli moduł front_of_house i funkcję
eat_at_restaurant do modułu o nazwie customer_experience, musielibyśmy
zaktualizować ścieżkę absolutną do add_to_waitlist, ale ścieżka względna
nadal byłaby prawidłowa. Jednak gdybyśmy przenieśli funkcję
eat_at_restaurant oddzielnie do modułu o nazwie dining, ścieżka absolutna
do wywołania add_to_waitlist pozostałaby taka sama, ale ścieżka względna
musiałaby zostać zaktualizowana. Ogólnie preferujemy określanie ścieżek
absolutnych, ponieważ bardziej prawdopodobne jest, że będziemy chcieli
przenosić definicje kodu i wywołania elementów niezależnie od siebie.
Spróbujmy skompilować Listing 7-3 i dowiedzmy się, dlaczego jeszcze się nie skompiluje! Błędy, które otrzymujemy, są pokazane w Listingu 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Komunikaty o błędach mówią, że moduł hosting jest prywatny. Innymi słowy,
mamy poprawne ścieżki do modułu hosting i funkcji add_to_waitlist, ale
Rust nie pozwala nam ich używać, ponieważ nie ma dostępu do prywatnych sekcji.
W Rust wszystkie elementy (funkcje, metody, struktury, wyliczenia, moduły
i stałe) są domyślnie prywatne dla modułów nadrzędnych. Jeśli chcesz
uczynić element, taki jak funkcja lub struktura, prywatnym, umieszczasz go
w module.
Elementy w module nadrzędnym nie mogą używać prywatnych elementów w modułach podrzędnych, ale elementy w modułach podrzędnych mogą używać elementów w modułach nadrzędnych. Dzieje się tak, ponieważ moduły podrzędne opakowują i ukrywają swoje szczegóły implementacji, ale moduły podrzędne mogą widzieć kontekst, w którym są zdefiniowane. Aby kontynuować naszą metaforę, pomyśl o zasadach prywatności jako o zapleczu restauracji: to, co się tam dzieje, jest prywatne dla klientów restauracji, ale menedżerowie biura mogą widzieć i robić wszystko w restauracji, którą prowadzą.
Rust zdecydował, aby system modułów działał w ten sposób, aby domyślnie ukrywać
wewnętrzne szczegóły implementacji. W ten sposób wiesz, które części kodu
wewnętrznego możesz zmienić bez uszkadzania kodu zewnętrznego. Jednak Rust
daje możliwość udostępniania wewnętrznych części kodu modułów podrzędnych
modułom nadrzędnym za pomocą słowa kluczowego pub, aby uczynić element
publicznym.
Udostępnianie ścieżek za pomocą słowa kluczowego pub
Wróćmy do błędu z Listingu 7-4, który informował nas, że moduł hosting jest
prywatny. Chcemy, aby funkcja eat_at_restaurant w module nadrzędnym miała
dostęp do funkcji add_to_waitlist w module potomnym, więc oznaczamy moduł
hosting słowem kluczowym pub, jak pokazano w Listingu 7-5.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}hosting jako pub w celu użycia go z eat_at_restaurantNiestety, kod w Listingu 7-5 nadal skutkuje błędami kompilatora, jak pokazano w Listingu 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Co się stało? Dodanie słowa kluczowego pub przed mod hosting sprawia, że
moduł staje się publiczny. Dzięki tej zmianie, jeśli mamy dostęp do
front_of_house, możemy uzyskać dostęp do hosting. Ale zawartość hosting
jest nadal prywatna; uczynienie modułu publicznym nie sprawia, że jego
zawartość staje się publiczna. Słowo kluczowe pub na module pozwala tylko
kodowi w jego modułach nadrzędnych odwoływać się do niego, a nie uzyskiwać
dostępu do jego wewnętrznego kodu. Ponieważ moduły są kontenerami, nie możemy
wiele zdziałać, jedynie upubliczniając moduł; musimy pójść dalej i
zdecydować się na upublicznienie jednego lub więcej elementów w module.
Błędy w Listingu 7-6 mówią, że funkcja add_to_waitlist jest prywatna.
Zasady prywatności dotyczą również struktur, wyliczeń, funkcji i metod, a także
modułów.
Upublicznijmy również funkcję add_to_waitlist, dodając słowo kluczowe pub
przed jej definicją, jak w Listingu 7-7.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}pub do mod hosting i fn add_to_waitlist pozwala nam wywołać funkcję z eat_at_restaurant.Teraz kod się skompiluje! Aby zobaczyć, dlaczego dodanie słowa kluczowego pub
pozwala nam używać tych ścieżek w eat_at_restaurant w odniesieniu do zasad
prywatności, spójrzmy na ścieżki absolutne i względne.
W ścieżce absolutnej zaczynamy od crate, korzenia drzewa modułów naszego
pakietu. Moduł front_of_house jest zdefiniowany w korzeniu pakietu. Chociaż
front_of_house nie jest publiczny, ponieważ funkcja eat_at_restaurant jest
zdefiniowana w tym samym module co front_of_house (czyli eat_at_restaurant
i front_of_house są rodzeństwem), możemy odwoływać się do front_of_house
z eat_at_restaurant. Następny jest moduł hosting oznaczony pub. Mamy
dostęp do modułu nadrzędnego hosting, więc możemy uzyskać dostęp do
hosting. Na koniec, funkcja add_to_waitlist jest oznaczona pub, a my
mamy dostęp do jej modułu nadrzędnego, więc to wywołanie funkcji działa!
W ścieżce względnej logika jest taka sama jak w ścieżce absolutnej, z wyjątkiem
pierwszego kroku: zamiast zaczynać od korzenia pakietu, ścieżka zaczyna się od
front_of_house. Moduł front_of_house jest zdefiniowany w tym samym module
co eat_at_restaurant, więc ścieżka względna zaczynająca się od modułu, w
którym zdefiniowano eat_at_restaurant, działa. Następnie, ponieważ hosting
i add_to_waitlist są oznaczone jako pub, reszta ścieżki działa, a to
wywołanie funkcji jest prawidłowe!
Jeśli planujesz udostępnić swój pakiet biblioteczny, aby inne projekty mogły używać Twojego kodu, Twój publiczny interfejs API jest Twoją umową z użytkownikami Twojego pakietu, która określa, w jaki sposób mogą wchodzić w interakcje z Twoim kodem. Istnieje wiele kwestii związanych z zarządzaniem zmianami w Twoim publicznym interfejsie API, aby ułatwić innym poleganie na Twoim pakiecie. Te rozważania wykraczają poza zakres tej książki; jeśli interesuje Cię ten temat, zobacz Rust API Guidelines.
Najlepsze praktyki dla pakietów z binarnym i bibliotecznym
Wspomnieliśmy, że pakiet może zawierać zarówno korzeń pakietu binarnego src/main.rs, jak i korzeń pakietu bibliotecznego src/lib.rs, a oba pakiety będą domyślnie miały nazwę pakietu. Zazwyczaj pakiety z takim patternem, zawierające zarówno bibliotekę, jak i pakiet binarny, będą miały w pakiecie binarnym wystarczająco dużo kodu, aby uruchomić plik wykonywalny, który wywołuje kod zdefiniowany w pakiecie bibliotecznym. Pozwala to innym projektom korzystać z większości funkcjonalności, którą pakiet zapewnia, ponieważ kod pakietu bibliotecznego może być współdzielony.
Drzewo modułów powinno być zdefiniowane w src/lib.rs. Następnie wszelkie publiczne elementy mogą być używane w pakiecie binarnym, zaczynając ścieżki od nazwy pakietu. Pakiet binarny staje się użytkownikiem pakietu bibliotecznego, tak jak całkowicie zewnętrzny pakiet używałby pakietu bibliotecznego: może używać tylko publicznego API. Pomaga to zaprojektować dobre API; jesteś nie tylko autorem, ale także klientem!
W Rozdziale 12 zademonstrujemy tę praktykę organizacyjną za pomocą programu wiersza poleceń, który będzie zawierał zarówno pakiet binarny, jak i pakiet biblioteczny.
Rozpoczynanie ścieżek względnych za pomocą super
Możemy konstruować ścieżki względne, które zaczynają się w module nadrzędnym,
a nie w bieżącym module lub korzeniu pakietu, używając super na początku
ścieżki. Jest to podobne do rozpoczynania ścieżki systemu plików składnią ..,
która oznacza przejście do katalogu nadrzędnego. Użycie super pozwala nam
odwołać się do elementu, o którym wiemy, że znajduje się w module nadrzędnym,
co może ułatwić reorganizację drzewa modułów, gdy moduł jest ściśle powiązany z
nadrzędnym, ale rodzic może zostać kiedyś przeniesiony w inne miejsce w
drzewie modułów.
Rozważmy kod w Listingu 7-8, który modeluje sytuację, w której szef kuchni
poprawia nieprawidłowe zamówienie i osobiście dostarcza je klientowi. Funkcja
fix_incorrect_order zdefiniowana w module back_of_house wywołuje funkcję
deliver_order zdefiniowaną w module nadrzędnym, określając ścieżkę do
deliver_order, zaczynając od super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}superFunkcja fix_incorrect_order znajduje się w module back_of_house, więc
możemy użyć super, aby przejść do modułu nadrzędnego back_of_house, który
w tym przypadku jest crate, czyli korzeń. Stamtąd szukamy deliver_order
i znajdujemy ją. Sukces! Uważamy, że moduł back_of_house i funkcja
deliver_order prawdopodobnie pozostaną w tej samej relacji do siebie i
zostaną przeniesione razem, jeśli zdecydujemy się na reorganizację drzewa
modułów pakietu. Dlatego użyliśmy super, aby w przyszłości, w przypadku
przeniesienia tego kodu do innego modułu, było mniej miejsc do aktualizacji
kodu.
Upublicznianie struktur i wyliczeń
Możemy również użyć pub do oznaczenia struktur i wyliczeń jako publicznych,
ale istnieje kilka dodatkowych szczegółów dotyczących użycia pub ze
strukturami i wyliczeniami. Jeśli użyjemy pub przed definicją struktury,
uczynimy ją publiczną, ale pola struktury nadal będą prywatne. Możemy
uczynić każde pole publicznym lub nie, w zależności od przypadku. W Listingu
7-9 zdefiniowaliśmy publiczną strukturę back_of_house::Breakfast z
publicznym polem toast, ale prywatnym polem seasonal_fruit. To
modeluje sytuację w restauracji, gdzie klient może wybrać rodzaj pieczywa,
które jest podawane do posiłku, ale szef kuchni decyduje, jakie owoce
towarzyszą posiłkowi, w zależności od sezonu i dostępności w magazynie.
Dostępne owoce szybko się zmieniają, więc klienci nie mogą wybierać owoców
ani nawet widzieć, jakie owoce otrzymają.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Zamów śniadanie latem z tostami żytnimi.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Zmieniamy zdanie co do rodzaju pieczywa.
meal.toast = String::from("Wheat");
println!("Poproszę tost {} ", meal.toast);
// Następna linia się nie skompiluje, jeśli ją odkomentujemy; nie możemy
// zobaczyć ani modyfikować sezonowych owoców, które są podawane do posiłku.
// meal.seasonal_fruit = String::from("blueberries");
}Ponieważ pole toast w strukturze back_of_house::Breakfast jest publiczne,
w eat_at_restaurant możemy zapisywać i odczytywać do pola toast używając
notacji kropkowej. Zauważ, że nie możemy użyć pola seasonal_fruit w
eat_at_restaurant, ponieważ seasonal_fruit jest prywatne. Spróbuj
odkomentować linię modyfikującą wartość pola seasonal_fruit, aby zobaczyć,
jaki błąd otrzymasz!
Należy również zauważyć, że ponieważ back_of_house::Breakfast ma prywatne
pole, struktura musi udostępniać publiczną funkcję skojarzoną, która
konstruuje instancję Breakfast (nazwaliśmy ją tutaj summer). Gdyby
Breakfast nie miała takiej funkcji, nie moglibyśmy utworzyć instancji
Breakfast w eat_at_restaurant, ponieważ nie moglibyśmy ustawić wartości
prywatnego pola seasonal_fruit w eat_at_restaurant.
W przeciwieństwie do tego, jeśli upublicznimy wyliczenie, wszystkie jego
warianty stają się publiczne. Potrzebujemy tylko pub przed słowem kluczowym
enum, jak pokazano w Listingu 7-10.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}Ponieważ upubliczniliśmy wyliczenie Appetizer, możemy używać wariantów Soup
i Salad w eat_at_restaurant.
Wyliczenia nie są zbyt użyteczne, chyba że ich warianty są publiczne; byłoby
uciążliwe, gdybyśmy musieli annotować wszystkie warianty wyliczeń za pomocą
pub w każdym przypadku, dlatego domyślnie warianty wyliczeń są publiczne.
Struktury są często użyteczne bez publicznych pól, więc pola struktur
podlegają ogólnej zasadzie, że wszystko jest domyślnie prywatne, chyba że jest
anotowane za pomocą pub.
Istnieje jeszcze jedna sytuacja związana z pub, której nie omówiliśmy, i jest
to nasza ostatnia funkcja systemu modułów: słowo kluczowe use. Najpierw
omówimy use samo w sobie, a następnie pokażemy, jak łączyć pub i use.
Wprowadzanie ścieżek do zasięgu za pomocą słowa kluczowego use
Wprowadzanie ścieżek do zasięgu za pomocą słowa kluczowego use
Konieczność wypisywania pełnych ścieżek do wywoływania funkcji może być uciążliwa i powtarzalna. W Listing 7-7, niezależnie od tego, czy wybraliśmy ścieżkę absolutną, czy względną do funkcji add_to_waitlist, za każdym razem, gdy chcieliśmy wywołać add_to_waitlist, musieliśmy również określać front_of_house i hosting. Na szczęście istnieje sposób na uproszczenie tego procesu: Możemy utworzyć skrót do ścieżki za pomocą słowa kluczowego use raz, a następnie używać krótszej nazwy wszędzie indziej w danym zasięgu.
W Listing 7-11 wprowadzamy moduł crate::front_of_house::hosting do zasięgu funkcji eat_at_restaurant, tak abyśmy musieli określać jedynie hosting::add_to_waitlist, aby wywołać funkcję add_to_waitlist w eat_at_restaurant.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Dodanie use i ścieżki w zasięgu jest podobne do tworzenia dowiązania symbolicznego w systemie plików. Dodając use crate::front_of_house::hosting w katalogu głównym skrzynki, hosting jest teraz prawidłową nazwą w tym zasięgu, tak jakby moduł hosting został zdefiniowany w katalogu głównym skrzynki. Ścieżki wprowadzone do zasięgu za pomocą use również sprawdzają prywatność, tak jak każda inna ścieżka.
Zwróć uwagę, że use tworzy skrót tylko dla konkretnego zasięgu, w którym występuje use. Listing 7-12 przenosi funkcję eat_at_restaurant do nowego modułu potomnego o nazwie customer, który jest wówczas innym zasięgiem niż instrukcja use, więc ciało funkcji nie skompiluje się.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}Błąd kompilatora pokazuje, że skrót nie ma już zastosowania w module customer:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of unresolved module or unlinked crate `hosting`
|
= help: if you wanted to use a crate named `hosting`, use `cargo add hosting` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Zauważ, że pojawiło się również ostrzeżenie, że use nie jest już używane w swoim zasięgu! Aby rozwiązać ten problem, przenieś use również do modułu customer lub odwołaj się do skrótu w module nadrzędnym za pomocą super::hosting w module potomnym customer.
Tworzenie idiomatycznych ścieżek use
W Listing 7-11 mogłeś się zastanawiać, dlaczego określiliśmy use crate::front_of_house::hosting, a następnie wywołaliśmy hosting::add_to_waitlist w eat_at_restaurant, zamiast określać ścieżkę use aż do funkcji add_to_waitlist, aby osiągnąć ten sam rezultat, jak w Listing 7-13.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}Chociaż zarówno Listing 7-11, jak i Listing 7-13 wykonują to samo zadanie, Listing 7-11 jest idiomatycznym sposobem wprowadzania funkcji do zasięgu za pomocą use. Wprowadzenie modułu nadrzędnego funkcji do zasięgu za pomocą use oznacza, że musimy określić moduł nadrzędny podczas wywoływania funkcji. Określanie modułu nadrzędnego podczas wywoływania funkcji jasno informuje, że funkcja nie jest zdefiniowana lokalnie, jednocześnie minimalizując powtarzanie pełnej ścieżki. Kod w Listing 7-13 niejasno określa, gdzie zdefiniowano add_to_waitlist.
Z drugiej strony, podczas wprowadzania struktur, wyliczeń i innych elementów za pomocą use, idiomatyczne jest określanie pełnej ścieżki. Listing 7-14 pokazuje idiomatyczny sposób wprowadzania struktury HashMap ze standardowej biblioteki do zasięgu skrzynki binarnej.
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, 2);
}Nie ma mocnego powodu, dla którego ten idiom: to po prostu konwencja, która się wykształciła, a ludzie przyzwyczaili się do czytania i pisania kodu w Rust w ten sposób.
Wyjątkiem od tego idiomu jest sytuacja, gdy wprowadzamy dwa elementy o tej samej nazwie do zasięgu za pomocą instrukcji use, ponieważ Rust na to nie pozwala. Listing 7-15 pokazuje, jak wprowadzić dwa typy Result do zasięgu, które mają tę samą nazwę, ale różne moduły nadrzędne, oraz jak się do nich odwoływać.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}Jak widać, użycie modułów nadrzędnych odróżnia dwa typy Result. Gdybyśmy zamiast tego określili use std::fmt::Result i use std::io::Result, mielibyśmy dwa typy Result w tym samym zasięgu, a Rust nie wiedziałby, o który nam chodzi, gdybyśmy użyli Result.
Nadawanie nowych nazw za pomocą słowa kluczowego as
Istnieje inne rozwiązanie problemu wprowadzania dwóch typów o tej samej nazwie do tego samego zasięgu za pomocą use: Po ścieżce możemy określić as i nową lokalną nazwę, czyli alias, dla typu. Listing 7-16 pokazuje inny sposób napisania kodu z Listing 7-15 poprzez zmianę nazwy jednego z dwóch typów Result za pomocą as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}W drugiej instrukcji use wybraliśmy nową nazwę IoResult dla typu std::io::Result, która nie będzie kolidować z Result z std::fmt, który również wprowadziliśmy do zasięgu. Listing 7-15 i Listing 7-16 są uważane za idiomatyczne, więc wybór należy do Ciebie!
Ponowne eksportowanie nazw za pomocą pub use
Kiedy wprowadzamy nazwę do zasięgu za pomocą słowa kluczowego use, nazwa jest prywatna dla zasięgu, do którego ją zaimportowaliśmy. Aby umożliwić kodowi spoza tego zasięgu odwoływanie się do tej nazwy tak, jakby została zdefiniowana w tym zasięgu, możemy połączyć pub i use. Ta technika nazywa się re-eksportowaniem, ponieważ wprowadzamy element do zasięgu, ale także udostępniamy ten element innym, aby mogli go wprowadzić do swojego zasięgu.
Listing 7-17 pokazuje kod z Listing 7-11, w którym use w module głównym zostało zmienione na pub use.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Przed tą zmianą, kod zewnętrzny musiałby wywoływać funkcję add_to_waitlist używając ścieżki restaurant::front_of_house::hosting::add_to_waitlist(), co wymagałoby również, aby moduł front_of_house był oznaczony jako pub. Teraz, gdy pub use ponownie wyeksportowało moduł hosting z modułu głównego, kod zewnętrzny może zamiast tego używać ścieżki restaurant::hosting::add_to_waitlist().
Ponowny eksport jest przydatny, gdy wewnętrzna struktura kodu różni się od sposobu, w jaki programiści wywołujący kod myśleliby o domenie. Na przykład, w tej metaforze restauracji, osoby prowadzące restaurację myślą o „front of house” i „back of house”. Ale klienci odwiedzający restaurację prawdopodobnie nie będą myśleć o częściach restauracji w tych kategoriach. Dzięki pub use możemy pisać kod o jednej strukturze, ale udostępniać inną strukturę. Dzięki temu nasza biblioteka jest dobrze zorganizowana dla programistów pracujących nad biblioteką i programistów wywołujących bibliotekę. Inny przykład pub use i jego wpływu na dokumentację skrzynki omówimy w rozdziale 14 w sekcji „Eksportowanie wygodnego publicznego API”.
Używanie pakietów zewnętrznych
W Rozdziale 2 programowaliśmy projekt gry zgadywanek, który używał zewnętrznego pakietu rand do generowania liczb losowych. Aby użyć rand w naszym projekcie, dodaliśmy następującą linię do Cargo.toml:
rand = "0.8.5"
Dodanie rand jako zależności w Cargo.toml informuje Cargo, aby pobrał pakiet rand i wszystkie jego zależności z crates.io i udostępnił rand naszemu projektowi.
Następnie, aby wprowadzić definicje rand do zasięgu naszego pakietu, dodaliśmy linię use zaczynającą się od nazwy skrzynki, rand, i wymieniliśmy elementy, które chcieliśmy wprowadzić do zasięgu. Przypomnij sobie, że w sekcji „Generowanie liczby losowej” w Rozdziale 2 wprowadziliśmy cechę Rng do zasięgu i wywołaliśmy funkcję rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Członkowie społeczności Rust udostępnili wiele pakietów na crates.io, a włączenie któregokolwiek z nich do Twojego pakietu obejmuje te same kroki: wymienienie ich w pliku Cargo.toml Twojego pakietu i użycie use do wprowadzenia elementów z ich skrzynek do zasięgu.
Zauważ, że standardowa biblioteka std jest również skrzynką zewnętrzną dla naszego pakietu. Ponieważ standardowa biblioteka jest dostarczana z językiem Rust, nie musimy zmieniać Cargo.toml, aby uwzględnić std. Musimy jednak odwołać się do niej za pomocą use, aby wprowadzić z niej elementy do zasięgu naszego pakietu. Na przykład, w przypadku HashMap użylibyśmy tej linii:
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}Jest to ścieżka absolutna zaczynająca się od std, nazwy skrzynki standardowej biblioteki.
Używanie zagnieżdżonych ścieżek do porządkowania list use
Jeśli używamy wielu elementów zdefiniowanych w tej samej skrzynce lub tym samym module, wymienianie każdego elementu w osobnej linii może zajmować dużo miejsca w naszych plikach. Na przykład, te dwie instrukcje use z gry zgadywanek w Listing 2-4 wprowadzają elementy z std do zasięgu:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Zamiast tego możemy użyć zagnieżdżonych ścieżek, aby wprowadzić te same elementy do zasięgu w jednej linii. Robimy to, określając wspólną część ścieżki, po której następują dwa dwukropki, a następnie nawiasy klamrowe wokół listy części ścieżek, które się różnią, jak pokazano w Listing 7-18.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}W większych programach wprowadzanie wielu elementów do zasięgu z tej samej skrzynki lub modułu za pomocą zagnieżdżonych ścieżek może znacznie zmniejszyć liczbę oddzielnych instrukcji use!
Możemy używać zagnieżdżonych ścieżek na dowolnym poziomie ścieżki, co jest przydatne przy łączeniu dwóch instrukcji use, które współdzielą podścieżkę. Na przykład, Listing 7-19 pokazuje dwie instrukcje use: jedna, która wprowadza std::io do zasięgu, i druga, która wprowadza std::io::Write do zasięgu.
use std::io;
use std::io::Write;Wspólną częścią tych dwóch ścieżek jest std::io, i to jest kompletna pierwsza ścieżka. Aby połączyć te dwie ścieżki w jedną instrukcję use, możemy użyć self w zagnieżdżonej ścieżce, jak pokazano w Listing 7-20.
use std::io::{self, Write};Ta linia wprowadza std::io i std::io::Write do zasięgu.
Importowanie elementów za pomocą operatora glob
Jeśli chcemy wprowadzić wszystkie publiczne elementy zdefiniowane w ścieżce do zasięgu, możemy określić tę ścieżkę, po której następuje operator glob *:
#![allow(unused)]
fn main() {
use std::collections::*;
}Ta instrukcja use wprowadza wszystkie publiczne elementy zdefiniowane w std::collections do bieżącego zasięgu. Zachowaj ostrożność podczas używania operatora glob! Glob może utrudnić określenie, jakie nazwy są w zasięgu i gdzie nazwa użyta w programie została zdefiniowana. Dodatkowo, jeśli zależność zmieni swoje definicje, to co zostało zaimportowane, również się zmieni, co może prowadzić do błędów kompilatora podczas aktualizacji zależności, jeśli zależność doda definicję o tej samej nazwie co Twoja definicja w tym samym zasięgu, na przykład.
Operator glob jest często używany podczas testowania, aby wprowadzić wszystko, co jest testowane, do modułu tests; omówimy to w sekcji „Jak pisać testy” w Rozdziale 11. Operator glob jest również czasami używany jako część wzorca preludium: zobacz dokumentację standardowej biblioteki, aby uzyskać więcej informacji na temat tego wzorca.
Dzielenie modułów na różne pliki
Dzielenie modułów na różne pliki
Do tej pory wszystkie przykłady w tym rozdziale definiowały wiele modułów w jednym pliku. Kiedy moduły stają się duże, możesz chcieć przenieść ich definicje do oddzielnego pliku, aby ułatwić nawigację po kodzie.
Na przykład, zacznijmy od kodu z Listing 7-17, który miał wiele modułów restauracji. Wyodrębnimy moduły do plików zamiast definiować wszystkie moduły w pliku głównym skrzynki. W tym przypadku plikiem głównym skrzynki jest src/lib.rs, ale ta procedura działa również w przypadku skrzynek binarnych, których plikiem głównym skrzynki jest src/main.rs.
Najpierw wyodrębnimy moduł front_of_house do jego własnego pliku. Usuń kod w nawiasach klamrowych dla modułu front_of_house, pozostawiając tylko deklarację mod front_of_house;, tak aby src/lib.rs zawierał kod pokazany w Listing 7-21. Zauważ, że to nie skompiluje się, dopóki nie utworzymy pliku src/front_of_house.rs w Listing 7-22.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Następnie umieść kod, który znajdował się w nawiasach klamrowych, w nowym pliku o nazwie src/front_of_house.rs, jak pokazano w Listing 7-22. Kompilator wie, aby szukać w tym pliku, ponieważ napotkał deklarację modułu w katalogu głównym skrzynki o nazwie front_of_house.
pub mod hosting {
pub fn add_to_waitlist() {}
}Zauważ, że plik należy załadować za pomocą deklaracji mod tylko raz w drzewie modułów. Kiedy kompilator dowie się, że plik jest częścią projektu (i wie, gdzie w drzewie modułów znajduje się kod, ze względu na miejsce, w którym umieszczono instrukcję mod), inne pliki w projekcie powinny odwoływać się do kodu załadowanego pliku, używając ścieżki do miejsca, w którym został zadeklarowany, jak opisano w sekcji „Ścieżki do odwoływania się do elementu w drzewie modułów”. Innymi słowy, mod nie jest operacją „include”, którą mogłeś widzieć w innych językach programowania.
Następnie wyodrębnimy moduł hosting do jego własnego pliku. Proces jest nieco inny, ponieważ hosting jest modułem podrzędnym front_of_house, a nie modułu głównego. Plik dla hosting umieścimy w nowym katalogu, który będzie nazwany od jego przodków w drzewie modułów, w tym przypadku src/front_of_house.
Aby rozpocząć przenoszenie hosting, zmieniamy src/front_of_house.rs, tak aby zawierał tylko deklarację modułu hosting:
pub mod hosting;Następnie tworzymy katalog src/front_of_house i plik hosting.rs, aby zawierać definicje z modułu hosting:
pub fn add_to_waitlist() {}Gdybyśmy zamiast tego umieścili hosting.rs w katalogu src, kompilator oczekiwałby, że kod hosting.rs będzie w module hosting zadeklarowanym w katalogu głównym skrzynki, a nie zadeklarowanym jako dziecko modułu front_of_house. Zasady kompilatora dotyczące tego, które pliki sprawdzić pod kątem kodu poszczególnych modułów, oznaczają, że katalogi i pliki bardziej ściśle odpowiadają drzewu modułów.
Alternatywne ścieżki plików
Do tej pory omówiliśmy najbardziej idiomatyczne ścieżki plików używane przez kompilator Rust, ale Rust obsługuje również starszy styl ścieżek plików. Dla modułu o nazwie
front_of_housezadeklarowanego w katalogu głównym skrzynki, kompilator będzie szukał kodu modułu w:
- src/front_of_house.rs (to, co omówiliśmy)
- src/front_of_house/mod.rs (starszy styl, nadal obsługiwana ścieżka)
Dla modułu o nazwie
hosting, który jest podmodułemfront_of_house, kompilator będzie szukał kodu modułu w:
- src/front_of_house/hosting.rs (to, co omówiliśmy)
- src/front_of_house/hosting/mod.rs (starszy styl, nadal obsługiwana ścieżka)
Jeśli użyjesz obu stylów dla tego samego modułu, otrzymasz błąd kompilacji. Mieszanie obu stylów dla różnych modułów w tym samym projekcie jest dozwolone, ale może być mylące dla osób nawigujących po Twoim projekcie.
Główną wadą stylu, który używa plików o nazwie mod.rs, jest to, że projekt może zawierać wiele plików o nazwie mod.rs, co może prowadzić do zamieszania, gdy masz je otwarte w edytorze w tym samym czasie.
Przenieśliśmy kod każdego modułu do osobnego pliku, a drzewo modułów pozostało takie samo. Wywołania funkcji w eat_at_restaurant będą działać bez żadnych modyfikacji, mimo że definicje znajdują się w różnych plikach. Ta technika pozwala przenosić moduły do nowych plików, gdy rosną.
Zauważ, że instrukcja pub use crate::front_of_house::hosting w src/lib.rs również nie uległa zmianie, ani use nie ma wpływu na to, które pliki są kompilowane jako część skrzynki. Słowo kluczowe mod deklaruje moduły, a Rust szuka w pliku o tej samej nazwie co moduł kodu, który należy do tego modułu.
Podsumowanie
Rust pozwala dzielić pakiet na wiele skrzynek, a skrzynkę na moduły, tak aby można było odwoływać się do elementów zdefiniowanych w jednym module z innego modułu. Można to zrobić, określając ścieżki absolutne lub względne. Te ścieżki można wprowadzić do zasięgu za pomocą instrukcji use, aby można było używać krótszej ścieżki dla wielokrotnego użycia elementu w tym zasięgu. Kod modułu jest domyślnie prywatny, ale można uczynić definicje publicznymi, dodając słowo kluczowe pub.
W następnym rozdziale przyjrzymy się niektórym strukturom danych kolekcji w standardowej bibliotece, których można użyć w swoim schludnie zorganizowanym kodzie.
Wspólne kolekcje
Standardowa biblioteka Rusta zawiera szereg bardzo przydatnych struktur danych zwanych kolekcjami. Większość innych typów danych reprezentuje jedną konkretną wartość, ale kolekcje mogą zawierać wiele wartości. W przeciwieństwie do wbudowanych typów tablicowych i krotkowych, dane, na które wskazują te kolekcje, są przechowywane na stercie, co oznacza, że ilość danych nie musi być znana w czasie kompilacji i może rosnąć lub zmniejszać się w trakcie działania programu. Każdy rodzaj kolekcji ma inne możliwości i koszty, a wybór odpowiedniej dla bieżącej sytuacji to umiejętność, którą rozwiniesz z czasem. W tym rozdziale omówimy trzy kolekcje, które są bardzo często używane w programach Rust:
- Wektor umożliwia przechowywanie zmiennej liczby wartości obok siebie.
- Ciąg znaków to kolekcja znaków. Wspomnieliśmy już o typie
String, ale w tym rozdziale omówimy go szczegółowo. - Mapa haszująca umożliwia powiązanie wartości z konkretnym kluczem. Jest to szczególna implementacja bardziej ogólnej struktury danych zwanej mapą.
Aby dowiedzieć się o innych rodzajach kolekcji dostarczanych przez standardową bibliotekę, zobacz dokumentację.
Omówimy, jak tworzyć i aktualizować wektory, ciągi znaków i mapy haszujące, a także co sprawia, że każda z nich jest wyjątkowa.
Przechowywanie list wartości za pomocą wektorów
Przechowywanie list wartości za pomocą wektorów
Pierwszym typem kolekcji, który omówimy, jest Vec<T>, znany również jako wektor. Wektory umożliwiają przechowywanie wielu wartości w jednej strukturze danych, która umieszcza wszystkie wartości obok siebie w pamięci. Wektory mogą przechowywać tylko wartości tego samego typu. Są przydatne, gdy masz listę elementów, takich jak linie tekstu w pliku lub ceny przedmiotów w koszyku na zakupy.
Tworzenie nowego wektora
Aby utworzyć nowy, pusty wektor, wywołujemy funkcję Vec::new, jak pokazano w Listing 8-1.
fn main() {
let v: Vec<i32> = Vec::new();
}Zauważ, że dodaliśmy tutaj adnotację typu. Ponieważ nie wstawiamy żadnych wartości do tego wektora, Rust nie wie, jakiego rodzaju elementy zamierzamy przechowywać. Jest to ważna uwaga. Wektory są implementowane przy użyciu generyków; jak używać generyków z własnymi typami, omówimy w Rozdziale 10. Na razie wiedz, że typ Vec<T> dostarczany przez standardową bibliotekę może przechowywać dowolny typ. Kiedy tworzymy wektor do przechowywania określonego typu, możemy określić typ w nawiasach ostrych. W Listing 8-1 poinformowaliśmy Rusta, że Vec<T> w v będzie przechowywać elementy typu i32.
Częściej będziesz tworzyć Vec<T> z wartościami początkowymi, a Rust wywnioskuje typ wartości, którą chcesz przechowywać, więc rzadko będziesz musiał dodawać adnotacje typu. Rust wygodnie udostępnia makro vec!, które utworzy nowy wektor przechowujący podane wartości. Listing 8-2 tworzy nowy Vec<i32> przechowujący wartości 1, 2 i 3. Typ liczby całkowitej to i32, ponieważ jest to domyślny typ liczby całkowitej, jak omówiliśmy w sekcji „Typy danych” w Rozdziale 3.
fn main() {
let v = vec![1, 2, 3];
}Ponieważ podaliśmy początkowe wartości i32, Rust może wywnioskować, że typ v to Vec<i32>, a adnotacja typu nie jest konieczna. Następnie przyjrzymy się, jak modyfikować wektor.
Aktualizowanie wektora
Aby utworzyć wektor, a następnie dodać do niego elementy, możemy użyć metody push, jak pokazano w Listing 8-3.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}Jak w przypadku każdej zmiennej, jeśli chcemy móc zmieniać jej wartość, musimy uczynić ją mutowalną za pomocą słowa kluczowego mut, jak omówiono w Rozdziale 3. Liczby, które umieszczamy wewnątrz, są wszystkie typu i32, a Rust wnioskuje to z danych, więc nie potrzebujemy adnotacji Vec<i32>.
Odczytywanie elementów wektorów
Istnieją dwa sposoby odwoływania się do wartości przechowywanej w wektorze: poprzez indeksowanie lub za pomocą metody get. W poniższych przykładach dodaliśmy adnotacje typów wartości zwracanych przez te funkcje dla dodatkowej przejrzystości.
Listing 8-4 pokazuje obie metody dostępu do wartości w wektorze, ze składnią indeksowania i metodą get.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("Trzeci element to {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("Trzeci element to {third}"),
None => println!("Nie ma trzeciego elementu."),
}
}Zauważmy kilka szczegółów. Używamy wartości indeksu 2, aby uzyskać trzeci element, ponieważ wektory są indeksowane liczbami, zaczynając od zera. Użycie & i [] daje nam odniesienie do elementu o wartości indeksu. Kiedy używamy metody get z indeksem przekazanym jako argument, otrzymujemy Option<&T>, którego możemy użyć z match.
Rust udostępnia te dwa sposoby odwoływania się do elementu, abyś mógł wybrać, jak program zachowa się, gdy spróbujesz użyć wartości indeksu spoza zakresu istniejących elementów. Na przykład, zobaczmy, co się stanie, gdy mamy wektor pięciu elementów, a następnie spróbujemy uzyskać dostęp do elementu o indeksie 100 za pomocą każdej techniki, jak pokazano w Listing 8-5.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);
}Kiedy uruchomimy ten kod, pierwsza metoda [] spowoduje panikę programu, ponieważ odwołuje się do nieistniejącego elementu. Ta metoda jest najlepiej używana, gdy chcesz, aby program uległ awarii, jeśli istnieje próba dostępu do elementu poza końcem wektora.
Jeśli do metody get zostanie przekazany indeks spoza zakresu wektora, zwraca None bez paniki. Użyłbyś tej metody, jeśli dostęp do elementu spoza zakresu wektora może sporadycznie występować w normalnych okolicznościach. Twój kod będzie wtedy zawierał logikę do obsługi Some(&element) lub None, jak omówiono w Rozdziale 6. Na przykład, indeks może pochodzić od osoby wpisującej liczbę. Jeśli przypadkowo wpisze zbyt dużą liczbę, a program otrzyma wartość None, możesz poinformować użytkownika, ile elementów znajduje się w bieżącym wektorze i dać mu kolejną szansę na wprowadzenie prawidłowej wartości. Byłoby to bardziej przyjazne dla użytkownika niż awaria programu z powodu literówki!
Gdy program ma prawidłową referencję, sprawdzanie pożyczek (borrow checker) egzekwuje zasady własności i pożyczania (omówione w Rozdziale 4), aby upewnić się, że ta referencja i wszelkie inne referencje do zawartości wektora pozostają prawidłowe. Przypomnijmy sobie zasadę, która mówi, że nie można mieć jednocześnie mutowalnych i niemutowalnych referencji w tym samym zakresie. Ta zasada ma zastosowanie w Listing 8-6, gdzie trzymamy niemutowalną referencję do pierwszego elementu w wektorze i próbujemy dodać element na końcu. Ten program nie zadziała, jeśli później spróbujemy odwołać się do tego elementu w funkcji.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("Pierwszy element to: {first}");
}Kompilowanie tego kodu spowoduje następujący błąd:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Kod w Listing 8-6 może wyglądać, jakby powinien działać: Dlaczego referencja do pierwszego elementu miałaby przejmować się zmianami na końcu wektora? Ten błąd wynika ze sposobu działania wektorów: Ponieważ wektory umieszczają wartości obok siebie w pamięci, dodanie nowego elementu na końcu wektora może wymagać alokacji nowej pamięci i skopiowania starych elementów do nowej przestrzeni, jeśli nie ma wystarczająco dużo miejsca, aby umieścić wszystkie elementy obok siebie tam, gdzie wektor jest obecnie przechowywany. W takim przypadku referencja do pierwszego elementu wskazywałaby na zwolnioną pamięć. Zasady pożyczania zapobiegają programom wpadaniu w taką sytuację.
Uwaga: Aby uzyskać więcej informacji na temat szczegółów implementacji typu
Vec<T>, zobacz „Rustonomicon”.
Iteracja po wartościach w wektorze
Aby kolejno uzyskiwać dostęp do każdego elementu w wektorze, iterowalibyśmy po wszystkich elementach, zamiast używać indeksów do jednoczesnego dostępu do jednego. Listing 8-7 pokazuje, jak użyć pętli for do uzyskania niemutowalnych referencji do każdego elementu w wektorze wartości i32 i ich wydrukowania.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}Możemy również iterować po mutowalnych referencjach do każdego elementu w mutowalnym wektorze, aby wprowadzić zmiany do wszystkich elementów. Pętla for w Listing 8-8 doda 50 do każdego elementu.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}Aby zmienić wartość, do której odwołuje się mutowalna referencja, musimy użyć operatora dereferencji *, aby uzyskać dostęp do wartości w i, zanim będziemy mogli użyć operatora +=. Więcej o operatorze dereferencji omówimy w sekcji „Śledzenie referencji do wartości” w Rozdziale 15.
Iteracja po wektorze, niezależnie od tego, czy jest niemutowalna, czy mutowalna, jest bezpieczna dzięki zasadom sprawdzania pożyczek. Gdybyśmy próbowali wstawiać lub usuwać elementy w treściach pętli for w Listing 8-7 i Listing 8-8, otrzymalibyśmy błąd kompilacji podobny do tego, który otrzymaliśmy w kodzie w Listing 8-6. Referencja do wektora, którą przechowuje pętla for, zapobiega jednoczesnej modyfikacji całego wektora.
Używanie Enum do przechowywania wielu typów
Wektory mogą przechowywać tylko wartości tego samego typu. Może to być niewygodne; z pewnością istnieją przypadki użycia, w których trzeba przechowywać listę elementów różnych typów. Na szczęście warianty enum są zdefiniowane pod tym samym typem enum, więc gdy potrzebujemy jednego typu do reprezentowania elementów różnych typów, możemy zdefiniować i użyć enum!
Na przykład, powiedzmy, że chcemy pobrać wartości z wiersza w arkuszu kalkulacyjnym, w którym niektóre kolumny w wierszu zawierają liczby całkowite, niektóre liczby zmiennoprzecinkowe, a niektóre ciągi znaków. Możemy zdefiniować enum, którego warianty będą przechowywać różne typy wartości, a wszystkie warianty enum będą traktowane jako ten sam typ: typ enum. Następnie możemy utworzyć wektor do przechowywania tego enum i w ten sposób ostatecznie przechowywać różne typy. Zilustrowaliśmy to w Listing 8-9.
fn main() {
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("niebieski")),
SpreadsheetCell::Float(10.12),
];
}Rust musi znać typy, które będą znajdować się w wektorze w czasie kompilacji, aby dokładnie wiedzieć, ile pamięci na stercie będzie potrzebne do przechowywania każdego elementu. Musimy również wyraźnie określić, jakie typy są dozwolone w tym wektorze. Gdyby Rust pozwalał na przechowywanie dowolnego typu w wektorze, istniałoby ryzyko, że jeden lub więcej typów spowodowałoby błędy w operacjach wykonywanych na elementach wektora. Użycie enum plus wyrażenia match oznacza, że Rust zapewni w czasie kompilacji, że każdy możliwy przypadek zostanie obsłużony, jak omówiono w Rozdziale 6.
Jeśli nie znasz wyczerpującego zestawu typów, które program otrzyma w czasie wykonywania, aby przechowywać w wektorze, technika enum nie zadziała. Zamiast tego możesz użyć obiektu cechy, który omówimy w Rozdziale 18.
Teraz, gdy omówiliśmy niektóre z najczęstszych sposobów użycia wektorów, upewnij się, że zapoznałeś się z dokumentacją API, aby zapoznać się ze wszystkimi wieloma przydatnymi metodami zdefiniowanymi w Vec<T> przez standardową bibliotekę. Na przykład, oprócz push, metoda pop usuwa i zwraca ostatni element.
Usuwanie wektora usuwa jego elementy
Podobnie jak każda inna struct, wektor jest zwalniany, gdy wychodzi poza zasięg, jak to zanotowano w Listing 8-10.
fn main() {
{
let v = vec![1, 2, 3, 4];
// rób coś z v
} // <- v wychodzi z zasięgu i jest zwalniane tutaj
}Kiedy wektor zostaje usunięty, cała jego zawartość również zostaje usunięta, co oznacza, że przechowywane w nim liczby całkowite zostaną posprzątane. Sprawdzający pożyczki zapewnia, że wszelkie referencje do zawartości wektora są używane tylko wtedy, gdy sam wektor jest prawidłowy.
Przejdźmy do następnego typu kolekcji: String!
Przechowywanie tekstu zakodowanego w UTF-8 za pomocą ciągów znaków
Przechowywanie tekstu zakodowanego w UTF-8 za pomocą ciągów znaków
O ciągach znaków rozmawialiśmy w Rozdziale 4, ale teraz przyjrzymy się im bardziej szczegółowo. Nowi użytkownicy Rusta często mają problemy z ciągami znaków z powodu połączenia trzech czynników: skłonności Rusta do ujawniania możliwych błędów, ciągów znaków będących bardziej skomplikowaną strukturą danych, niż wielu programistów im przypisuje, oraz UTF-8. Czynniki te łączą się w sposób, który może wydawać się trudny, gdy pochodzisz z innych języków programowania.
Ciągi znaków omawiamy w kontekście kolekcji, ponieważ są one implementowane jako kolekcja bajtów, plus kilka metod zapewniających użyteczną funkcjonalność, gdy te bajty są interpretowane jako tekst. W tej sekcji omówimy operacje na String, które posiada każdy typ kolekcji, takie jak tworzenie, aktualizowanie i odczytywanie. Omówimy również różnice między String a innymi kolekcjami, a mianowicie, jak indeksowanie String jest skomplikowane przez różnice między tym, jak ludzie i komputery interpretują dane String.
Definiowanie ciągów znaków
Najpierw zdefiniujemy, co rozumiemy przez termin ciąg znaków. Rust ma tylko jeden typ ciągu znaków w podstawowym języku, który jest wycinkiem ciągu str, zazwyczaj występującym w formie pożyczonej, &str. W Rozdziale 4 rozmawialiśmy o wycinkach ciągów znaków, które są referencjami do danych ciągu znaków zakodowanych w UTF-8, przechowywanych gdzie indziej. Literały ciągów znaków, na przykład, są przechowywane w binarnym pliku programu i dlatego są wycinkami ciągów znaków.
Typ String, który jest dostarczany przez standardową bibliotekę Rusta, a nie zakodowany w podstawowym języku, jest rosnącym, mutowalnym, posiadającym własność, zakodowanym w UTF-8 typem ciągu znaków. Kiedy użytkownicy Rusta odwołują się do „ciągów znaków” w Rust, mogą odnosić się zarówno do typów String, jak i wycinków ciągu &str, a nie tylko do jednego z tych typów. Chociaż ta sekcja dotyczy głównie String, oba typy są intensywnie używane w standardowej bibliotece Rusta, a zarówno String, jak i wycinki ciągów znaków są zakodowane w UTF-8.
Tworzenie nowego ciągu znaków
Wiele z tych samych operacji dostępnych dla Vec<T> jest również dostępnych dla String, ponieważ String jest faktycznie implementowane jako opakowanie wokół wektora bajtów z dodatkowymi gwarancjami, ograniczeniami i możliwościami. Przykładem funkcji, która działa w ten sam sposób z Vec<T> i String, jest funkcja new do tworzenia instancji, pokazana w Listing 8-11.
fn main() {
let mut s = String::new();
}Ta linia tworzy nowy, pusty ciąg znaków o nazwie s, do którego możemy następnie załadować dane. Często będziemy mieli pewne początkowe dane, którymi chcemy rozpocząć ciąg znaków. W tym celu używamy metody to_string, która jest dostępna dla każdego typu implementującego cechę Display, tak jak literały ciągów znaków. Listing 8-12 pokazuje dwa przykłady.
fn main() {
let data = "początkowa zawartość";
let s = data.to_string();
// Metoda działa również bezpośrednio na literale:
let s = "początkowa zawartość".to_string();
}Ten kod tworzy ciąg znaków zawierający początkową zawartość.
Możemy również użyć funkcji String::from do utworzenia String z literału ciągu znaków. Kod w Listing 8-13 jest równoważny kodowi w Listing 8-12, który używa to_string.
fn main() {
let s = String::from("początkowa zawartość");
}Ponieważ ciągi znaków są używane do wielu rzeczy, możemy używać wielu różnych generycznych API dla ciągów znaków, co daje nam wiele opcji. Niektóre z nich mogą wydawać się nadmiarowe, ale wszystkie mają swoje miejsce! W tym przypadku String::from i to_string robią to samo, więc wybór zależy od stylu i czytelności.
Pamiętaj, że ciągi znaków są zakodowane w UTF-8, więc możemy w nich zawrzeć dowolne poprawnie zakodowane dane, jak pokazano w Listing 8-14.
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Wszystkie te wartości String są prawidłowe.
Aktualizowanie ciągu znaków
String może rosnąć i zmieniać swoją zawartość, podobnie jak zawartość Vec<T>, jeśli dodasz do niego więcej danych. Ponadto możesz wygodnie użyć operatora + lub makra format! do łączenia wartości String.
Dołączanie za pomocą push_str lub push
Możemy powiększyć String, używając metody push_str do dołączenia wycinka ciągu znaków, jak pokazano w Listing 8-15.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}Po tych dwóch liniach s będzie zawierać foobar. Metoda push_str przyjmuje wycinek ciągu znaków, ponieważ niekoniecznie chcemy przejąć własność parametru. Na przykład w kodzie w Listing 8-16 chcemy móc użyć s2 po dołączeniu jego zawartości do s1.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 to {s2}");
}Gdyby metoda push_str przejęła własność s2, nie moglibyśmy wydrukować jego wartości w ostatniej linii. Jednak ten kod działa zgodnie z oczekiwaniami!
Metoda push przyjmuje pojedynczy znak jako parametr i dodaje go do String. Listing 8-17 dodaje literę l do String za pomocą metody push.
fn main() {
let mut s = String::from("lo");
s.push('l');
}W rezultacie s będzie zawierać lol.
Łączenie za pomocą + lub format!
Często będziesz chciał połączyć dwa istniejące ciągi znaków. Jednym ze sposobów na to jest użycie operatora +, jak pokazano w Listing 8-18.
fn main() {
let s1 = String::from("Witaj, ");
let s2 = String::from("świecie!");
let s3 = s1 + &s2; // uwaga, s1 zostało przeniesione i nie może być już użyte
}Ciąg s3 będzie zawierał Witaj, świecie!. Powód, dla którego s1 jest już nieważne po dodaniu, oraz powód, dla którego użyliśmy referencji do s2, ma związek z sygnaturą metody, która jest wywoływana, gdy używamy operatora +. Operator + używa metody add, której sygnatura wygląda mniej więcej tak:
fn add(self, s: &str) -> String {W standardowej bibliotece zobaczysz add zdefiniowane przy użyciu generyków i typów skojarzonych. Tutaj podstawiliśmy konkretne typy, co dzieje się, gdy wywołujemy tę metodę z wartościami String. Generyki omówimy w Rozdziale 10. Ta sygnatura daje nam wskazówki potrzebne do zrozumienia trudnych aspektów operatora +.
Po pierwsze, s2 ma &, co oznacza, że dodajemy referencję drugiego ciągu znaków do pierwszego ciągu znaków. Dzieje się tak z powodu parametru s w funkcji add: możemy dodać tylko wycinek ciągu znaków do String; nie możemy dodać dwóch wartości String razem. Ale czekaj – typ &s2 to &String, a nie &str, jak określono w drugim parametrze add. Dlaczego więc Listing 8-18 kompiluje się?
Powodem, dla którego możemy użyć &s2 w wywołaniu add, jest to, że kompilator może wymusić konwersję argumentu &String na &str. Kiedy wywołujemy metodę add, Rust używa deref coercion, która tutaj zmienia &s2 na &s2[..]. Omówimy deref coercion szczegółowo w Rozdziale 15. Ponieważ add nie przejmuje własności parametru s, s2 nadal będzie prawidłowym String po tej operacji.
Po drugie, w sygnaturze widzimy, że add przejmuje własność self, ponieważ self nie ma &. Oznacza to, że s1 w Listing 8-18 zostanie przeniesione do wywołania add i po tym nie będzie już ważne. Tak więc, chociaż let s3 = s1 + &s2; wygląda na to, że skopiuje oba ciągi i stworzy nowy, to faktycznie przejmuje własność s1, dołącza kopię zawartości s2, a następnie zwraca własność wyniku. Innymi słowy, wygląda na to, że wykonuje wiele kopii, ale tak nie jest; implementacja jest bardziej wydajna niż kopiowanie.
Jeśli potrzebujemy połączyć wiele ciągów znaków, zachowanie operatora + staje się nieporęczne:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}W tym momencie s będzie tic-tac-toe. Z tymi wszystkimi znakami + i " trudno jest zrozumieć, co się dzieje. Do łączenia ciągów znaków w bardziej skomplikowany sposób możemy zamiast tego użyć makra format!:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}Ten kod również ustawia s na tic-tac-toe. Makro format! działa jak println!, ale zamiast drukować wynik na ekranie, zwraca String z zawartością. Wersja kodu używająca format! jest znacznie łatwiejsza do odczytania, a kod generowany przez makro format! używa referencji, dzięki czemu to wywołanie nie przejmuje własności żadnego z jego parametrów.
Indeksowanie w ciągach znaków
W wielu innych językach programowania, dostęp do pojedynczych znaków w ciągu znaków poprzez odwoływanie się do nich za pomocą indeksu jest prawidłową i powszechną operacją. Jednakże, jeśli spróbujesz uzyskać dostęp do części String za pomocą składni indeksowania w Rust, otrzymasz błąd. Rozważ nieprawidłowy kod w Listing 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}Ten kod spowoduje następujący błąd:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Błąd opowiada historię: ciągi znaków w Rust nie obsługują indeksowania. Ale dlaczego? Aby odpowiedzieć na to pytanie, musimy omówić, jak Rust przechowuje ciągi znaków w pamięci.
Reprezentacja wewnętrzna
String jest opakowaniem na Vec<u8>. Spójrzmy na niektóre z naszych poprawnie zakodowanych przykładów ciągów znaków UTF-8 z Listing 8-14. Najpierw ten:
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}W tym przypadku len będzie równe 4, co oznacza, że wektor przechowujący ciąg znaków "Hola" ma 4 bajty długości. Każda z tych liter zajmuje 1 bajt po zakodowaniu w UTF-8. Następna linia może Cię jednak zaskoczyć (zauważ, że ten ciąg zaczyna się od wielkiej cyrylicznej litery Ze, a nie liczby 3):
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Gdybyś został zapytany, jak długi jest ten ciąg znaków, mógłbyś powiedzieć 12. W rzeczywistości odpowiedź Rusta to 24: to liczba bajtów potrzebna do zakodowania „Здравствуйте” w UTF-8, ponieważ każda skalarna wartość Unicode w tym ciągu zajmuje 2 bajty pamięci. Dlatego indeksowanie bajtów ciągu nie zawsze będzie korelować z prawidłową skalarną wartością Unicode. Aby to zademonstrować, rozważ ten nieprawidłowy kod w Rust:
let hello = "Здравствуйте";
let answer = &hello[0];Wiesz już, że answer nie będzie З, pierwszą literą. Po zakodowaniu w UTF-8 pierwszy bajt З to 208, a drugi to 151, więc wydawałoby się, że answer powinien faktycznie wynosić 208, ale 208 sam w sobie nie jest prawidłowym znakiem. Zwracanie 208 prawdopodobnie nie jest tym, czego użytkownik chciałby, gdyby poprosił o pierwszą literę tego ciągu; jednak to jedyne dane, które Rust ma pod indeksem bajtowym 0. Użytkownicy generalnie nie chcą, aby zwracana była wartość bajtowa, nawet jeśli ciąg zawiera tylko litery łacińskie: Gdyby &"hi"[0] był prawidłowym kodem zwracającym wartość bajtową, zwróciłby 104, a nie h.
Odpowiedź brzmi zatem, że aby uniknąć zwracania nieoczekiwanej wartości i powodowania błędów, które mogą nie zostać natychmiast wykryte, Rust w ogóle nie kompiluje tego kodu i zapobiega nieporozumieniom na wczesnym etapie procesu rozwoju.
Bajty, wartości skalarne i klastry grafemów
Inną kwestią dotyczącą UTF-8 jest to, że istnieją faktycznie trzy istotne sposoby patrzenia na ciągi znaków z perspektywy Rusta: jako bajty, wartości skalarne i klastry grafemów (najbliższe temu, co nazwalibyśmy literami).
Jeśli spojrzymy na hinduskie słowo „नमस्ते” napisane pismem dewanagari, jest ono przechowywane jako wektor wartości u8, który wygląda tak:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
To 18 bajtów i tak ostatecznie komputery przechowują te dane. Jeśli spojrzymy na nie jako skalarne wartości Unicode, czyli to, czym jest typ char w Rust, te bajty wyglądają tak:
['न', 'म', 'स', '्', 'त', 'े']
Jest tu sześć wartości char, ale czwarta i szósta nie są literami: to znaki diakrytyczne, które same w sobie nie mają sensu. W końcu, jeśli spojrzymy na nie jako klastry grafemów, otrzymamy to, co człowiek nazwałby czterema literami tworzącymi hinduskie słowo:
["न", "म", "स्", "ते"]
Rust udostępnia różne sposoby interpretacji surowych danych ciągu znaków, które przechowują komputery, tak aby każdy program mógł wybrać interpretację, której potrzebuje, niezależnie od tego, w jakim języku ludzkim są dane.
Ostatnim powodem, dla którego Rust nie pozwala nam indeksować String w celu uzyskania znaku, jest to, że operacje indeksowania mają zawsze zajmować stały czas (O(1)). Nie jest jednak możliwe zagwarantowanie takiej wydajności w przypadku String, ponieważ Rust musiałby przechodzić przez zawartość od początku do indeksu, aby określić, ile jest prawidłowych znaków.
Krojenie ciągów znaków
Indeksowanie ciągu znaków jest często złym pomysłem, ponieważ nie jest jasne, jaki powinien być typ zwracany przez operację indeksowania ciągu znaków: wartość bajtowa, znak, klaster grafemów czy wycinek ciągu znaków. Jeśli naprawdę potrzebujesz używać indeksów do tworzenia wycinków ciągu znaków, Rust prosi o większą precyzję.
Zamiast indeksowania za pomocą [] z pojedynczą liczbą, możesz użyć [] z zakresem, aby utworzyć wycinek ciągu znaków zawierający określone bajty:
#![allow(unused)]
fn main() {
let hello = "Здравствуйте";
let s = &hello[0..4];
}W tym przypadku s będzie &str, który zawiera pierwsze 4 bajty ciągu. Wcześniej wspomnieliśmy, że każdy z tych znaków miał 2 bajty, co oznacza, że s będzie Зд.
Gdybyśmy spróbowali podzielić tylko część bajtów znaku za pomocą czegoś takiego jak &hello[0..1], Rust panikowałby w czasie wykonywania w taki sam sposób, jakbyśmy uzyskali dostęp do nieprawidłowego indeksu w wektorze:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Powinieneś zachować ostrożność podczas tworzenia wycinków ciągów znaków za pomocą zakresów, ponieważ może to spowodować awarię programu.
Iterowanie po ciągach znaków
Najlepszym sposobem na operowanie na fragmentach ciągów znaków jest wyraźne określenie, czy chcemy znaków, czy bajtów. W przypadku pojedynczych skalarnych wartości Unicode, użyj metody chars. Wywołanie chars na „Зд” rozdziela i zwraca dwie wartości typu char, i możesz iterować po wyniku, aby uzyskać dostęp do każdego elementu:
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}Ten kod wydrukuje następujące:
З
д
Alternatywnie, metoda bytes zwraca każdy surowy bajt, co może być odpowiednie dla twojej domeny:
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}Ten kod wydrukuje 4 bajty, które składają się na ten ciąg znaków:
208
151
208
180
Ale pamiętaj, że prawidłowe skalarne wartości Unicode mogą składać się z więcej niż 1 bajta.
Uzyskiwanie klastrów grafemów z ciągów znaków, tak jak w przypadku pisma dewanagari, jest złożone, dlatego ta funkcjonalność nie jest dostarczana przez standardową bibliotekę. Skrzynki są dostępne na crates.io, jeśli to jest funkcjonalność, której potrzebujesz.
Obsługa złożoności ciągów znaków
Podsumowując, ciągi znaków są skomplikowane. Różne języki programowania podejmują różne decyzje dotyczące tego, jak przedstawić tę złożoność programistom. Rust wybrał, aby prawidłowe obchodzenie się z danymi String było domyślnym zachowaniem dla wszystkich programów Rust, co oznacza, że programiści muszą z wyprzedzeniem poświęcić więcej uwagi obsłudze danych UTF-8. Ten kompromis ujawnia więcej złożoności ciągów znaków, niż jest to widoczne w innych językach programowania, ale zapobiega konieczności obsługi błędów związanych ze znakami spoza ASCII w późniejszym cyklu rozwoju.
Dobrą wiadomością jest to, że standardowa biblioteka oferuje wiele funkcjonalności zbudowanych na typach String i &str, aby pomóc w prawidłowym radzeniu sobie z tymi złożonymi sytuacjami. Koniecznie sprawdź dokumentację pod kątem przydatnych metod, takich jak contains do wyszukiwania w ciągu znaków i replace do zastępowania części ciągu znaków innym ciągiem znaków.
Przejdźmy do czegoś nieco mniej skomplikowanego: mapy haszujące!
Przechowywanie kluczy z powiązanymi wartościami w mapach haszujących
Przechowywanie kluczy z powiązanymi wartościami w mapach haszujących
Ostatnią z naszych wspólnych kolekcji jest mapa haszująca. Typ HashMap<K, V> przechowuje mapowanie kluczy typu K na wartości typu V za pomocą funkcji haszującej, która określa, w jaki sposób umieszcza te klucze i wartości w pamięci. Wiele języków programowania obsługuje tego rodzaju strukturę danych, ale często używają innej nazwy, takiej jak hash, map, object, hash table, dictionary lub associative array, by wymienić tylko kilka.
Mapy haszujące są przydatne, gdy chcesz wyszukiwać dane nie za pomocą indeksu, jak w przypadku wektorów, ale za pomocą klucza, który może być dowolnego typu. Na przykład w grze możesz śledzić wyniki każdej drużyny w mapie haszującej, w której każdy klucz to nazwa drużyny, a wartości to wyniki każdej drużyny. Mając nazwę drużyny, możesz pobrać jej wynik.
W tej sekcji omówimy podstawowe API map haszujących, ale wiele innych dobrodziejstw kryje się w funkcjach zdefiniowanych dla HashMap<K, V> przez standardową bibliotekę. Jak zawsze, sprawdź dokumentację standardowej biblioteki, aby uzyskać więcej informacji.
Tworzenie nowej mapy haszującej
Jednym ze sposobów utworzenia pustej mapy haszującej jest użycie new i dodanie elementów za pomocą insert. W Listing 8-20 śledzimy wyniki dwóch drużyn, których nazwy to Niebiescy i Żółci. Drużyna Niebieskich zaczyna z 10 punktami, a drużyna Żółtych z 50.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Niebiescy"), 10);
scores.insert(String::from("Żółci"), 50);
}Zauważ, że musimy najpierw use HashMap z części kolekcji standardowej biblioteki. Spośród naszych trzech wspólnych kolekcji, ta jest najrzadziej używana, więc nie jest ona domyślnie dołączana do zasięgu w preludium. Mapy haszujące mają również mniejsze wsparcie ze strony standardowej biblioteki; nie ma na przykład wbudowanego makra do ich konstruowania.
Podobnie jak wektory, mapy haszujące przechowują swoje dane na stercie. Ta HashMap ma klucze typu String i wartości typu i32. Podobnie jak wektory, mapy haszujące są jednorodne: wszystkie klucze muszą mieć ten sam typ, a wszystkie wartości muszą mieć ten sam typ.
Dostęp do wartości w mapie haszującej
Możemy pobrać wartość z mapy haszującej, podając jej klucz do metody get, jak pokazano w Listing 8-21.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Niebiescy"), 10);
scores.insert(String::from("Żółci"), 50);
let team_name = String::from("Niebiescy");
let score = scores.get(&team_name).copied().unwrap_or(0);
}Tutaj score będzie miało wartość powiązaną z drużyną Niebieskich, a wynik będzie wynosił 10. Metoda get zwraca Option<&V>; jeśli dla tego klucza nie ma wartości w mapie haszującej, get zwróci None. Ten program obsługuje Option wywołując copied, aby uzyskać Option<i32> zamiast Option<&i32>, a następnie unwrap_or, aby ustawić score na zero, jeśli scores nie ma wpisu dla klucza.
Możemy iterować po każdej parze klucz-wartość w mapie haszującej w podobny sposób, jak to robimy z wektorami, używając pętli for:
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Niebiescy"), 10);
scores.insert(String::from("Żółci"), 50);
for (key, value) in &scores {
println!("{key}: {value}");
}
}Ten kod wydrukuje każdą parę w dowolnej kolejności:
Żółci: 50
Niebiescy: 10
Zarządzanie własnością w mapach haszujących
W przypadku typów implementujących cechę Copy, takich jak i32, wartości są kopiowane do mapy haszującej. W przypadku wartości posiadanych, takich jak String, wartości zostaną przeniesione, a mapa haszująca będzie właścicielem tych wartości, jak pokazano w Listing 8-22.
fn main() {
use std::collections::HashMap;
let field_name = String::from("Ulubiony kolor");
let field_value = String::from("Niebieski");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// field_name i field_value są w tym momencie nieprawidłowe, spróbuj ich użyć i
// zobacz, jaki błąd kompilacji otrzymasz!
}Nie możemy używać zmiennych field_name i field_value po ich przeniesieniu do mapy haszującej za pomocą wywołania insert.
Jeśli wstawimy referencje do wartości do mapy haszującej, wartości nie zostaną przeniesione do mapy haszującej. Wartości, na które wskazują referencje, muszą być ważne przynajmniej tak długo, jak długo ważna jest mapa haszująca. Więcej o tych problemach omówimy w sekcji „Walidacja referencji za pomocą czasów życia” w Rozdziale 10.
Aktualizowanie mapy haszującej
Chociaż liczba par klucz-wartość może rosnąć, każdy unikalny klucz może mieć w danym momencie tylko jedną powiązaną wartość (ale nie na odwrót: na przykład, zarówno drużyna Niebieskich, jak i drużyna Żółtych mogłyby mieć wartość 10 przechowywaną w mapie haszującej scores).
Kiedy chcesz zmienić dane w mapie haszującej, musisz zdecydować, jak postąpić w przypadku, gdy klucz już ma przypisaną wartość. Możesz zastąpić starą wartość nową, całkowicie ignorując starą wartość. Możesz zachować starą wartość i zignorować nową wartość, dodając nową wartość tylko wtedy, gdy klucz nie ma jeszcze wartości. Lub możesz połączyć starą wartość i nową wartość. Przyjrzyjmy się, jak wykonać każdą z tych czynności!
Nadpisywanie wartości
Jeśli wstawimy klucz i wartość do mapy haszującej, a następnie wstawimy ten sam klucz z inną wartością, wartość powiązana z tym kluczem zostanie zastąpiona. Mimo że kod w Listing 8-23 wywołuje insert dwukrotnie, mapa haszująca będzie zawierać tylko jedną parę klucz-wartość, ponieważ dwukrotnie wstawiamy wartość dla klucza drużyny Niebieskich.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Niebiescy"), 10);
scores.insert(String::from("Niebiescy"), 25);
println!("{scores:?}");
}Ten kod wydrukuje {"Niebiescy": 25}. Pierwotna wartość 10 została nadpisana.
Dodawanie klucza i wartości tylko wtedy, gdy klucz nie jest obecny
Często sprawdza się, czy dany klucz już istnieje w mapie haszującej z wartością, a następnie wykonuje następujące działania: Jeśli klucz istnieje w mapie haszującej, istniejąca wartość powinna pozostać taka, jaka jest; jeśli klucz nie istnieje, wstawia się go i wartość dla niego.
Mapy haszujące posiadają specjalne API do tego celu, zwane entry, które jako parametr przyjmuje klucz, który chcesz sprawdzić. Wartością zwracaną przez metodę entry jest enum o nazwie Entry, który reprezentuje wartość, która może istnieć lub nie. Załóżmy, że chcemy sprawdzić, czy klucz dla drużyny Żółtych ma przypisaną wartość. Jeśli nie, chcemy wstawić wartość 50, i to samo dla drużyny Niebieskich. Używając API entry, kod wygląda jak w Listing 8-24.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Niebiescy"), 10);
scores.entry(String::from("Żółci")).or_insert(50);
scores.entry(String::from("Niebiescy")).or_insert(50);
println!("{scores:?}");
}Metoda or_insert w Entry jest zdefiniowana tak, aby zwracać mutowalną referencję do wartości dla odpowiadającego klucza Entry, jeśli ten klucz istnieje, a jeśli nie, wstawia parametr jako nową wartość dla tego klucza i zwraca mutowalną referencję do nowej wartości. Ta technika jest znacznie czystsza niż samodzielne pisanie logiki i, co więcej, lepiej współpracuje z mechanizmem sprawdzania pożyczek.
Uruchomienie kodu w Listing 8-24 wydrukuje {"Żółci": 50, "Niebiescy": 10}. Pierwsze wywołanie entry wstawi klucz dla drużyny Żółtych z wartością 50, ponieważ drużyna Żółtych nie ma jeszcze wartości. Drugie wywołanie entry nie zmieni mapy haszującej, ponieważ drużyna Niebieskich ma już wartość 10.
Aktualizowanie wartości na podstawie starej wartości
Innym częstym przypadkiem użycia map haszujących jest wyszukiwanie wartości klucza, a następnie aktualizowanie jej na podstawie starej wartości. Na przykład, Listing 8-25 pokazuje kod, który zlicza, ile razy każde słowo pojawia się w tekście. Używamy mapy haszującej ze słowami jako kluczami i inkrementujemy wartość, aby śledzić, ile razy widzieliśmy to słowo. Jeśli jest to pierwszy raz, kiedy widzieliśmy słowo, najpierw wstawimy wartość 0.
fn main() {
use std::collections::HashMap;
let text = "cześć świat cudowny świat";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{map:?}");
}Ten kod wydrukuje {"świat": 2, "cześć": 1, "cudowny": 1}. Możesz zobaczyć te same pary klucz-wartość wydrukowane w innej kolejności: przypomnij sobie z sekcji „Dostęp do wartości w mapie haszującej”, że iteracja po mapie haszującej odbywa się w dowolnej kolejności.
Metoda split_whitespace zwraca iterator po podsekcjach, rozdzielonych spacjami, wartości w text. Metoda or_insert zwraca mutowalną referencję (&mut V) do wartości dla określonego klucza. Tutaj przechowujemy tę mutowalną referencję w zmiennej count, więc aby przypisać do tej wartości, musimy najpierw dereferencjować count za pomocą gwiazdki (*). Mutowalna referencja wychodzi poza zasięg na końcu pętli for, więc wszystkie te zmiany są bezpieczne i dozwolone przez zasady pożyczania.
Funkcje haszujące
Domyślnie HashMap używa funkcji haszującej zwanej SipHash, która może zapewnić odporność na ataki typu denial-of-service (DoS) związane z tabelami haszującymi1. Nie jest to najszybszy dostępny algorytm haszujący, ale kompromis między lepszym bezpieczeństwem a spadkiem wydajności jest tego wart. Jeśli profilujesz swój kod i stwierdzisz, że domyślna funkcja haszująca jest zbyt wolna dla Twoich celów, możesz przełączyć się na inną funkcję, określając inny haszer. Haszer to typ, który implementuje cechę BuildHasher. O cechach i sposobie ich implementacji omówimy w Rozdziale 10. Nie musisz koniecznie implementować własnego haszera od podstaw; crates.io posiada biblioteki udostępnione przez innych użytkowników Rusta, które dostarczają haszerów implementujących wiele popularnych algorytmów haszujących.
Podsumowanie
Wektory, ciągi znaków i mapy haszujące zapewnią dużą funkcjonalność niezbędną w programach, gdy trzeba przechowywać, uzyskiwać dostęp i modyfikować dane. Oto kilka ćwiczeń, które powinieneś być teraz w stanie rozwiązać:
- Mając listę liczb całkowitych, użyj wektora i zwróć medianę (po posortowaniu, wartość na środkowej pozycji) i dominantę (wartość, która występuje najczęściej; tutaj pomocna będzie mapa haszująca) listy.
- Przekształć ciągi znaków na języka Pig Latin. Pierwsza spółgłoska każdego słowa jest przenoszona na koniec słowa i dodawane jest ay, więc first staje się irst-fay. Słowa, które zaczynają się samogłoską, mają dodane hay na końcu (apple staje się apple-hay). Pamiętaj o szczegółach kodowania UTF-8!
- Korzystając z mapy haszującej i wektorów, stwórz interfejs tekstowy, aby umożliwić użytkownikowi dodawanie nazw pracowników do działu w firmie; na przykład „Dodaj Sally do Inżynierii” lub „Dodaj Amira do Sprzedaży”. Następnie pozwól użytkownikowi pobrać listę wszystkich osób w dziale lub wszystkich osób w firmie według działu, posortowanych alfabetycznie.
Dokumentacja API standardowej biblioteki opisuje metody, które mają wektory, ciągi znaków i mapy haszujące, które będą pomocne w tych ćwiczeniach!
Przechodzimy do bardziej złożonych programów, w których operacje mogą zakończyć się niepowodzeniem, więc to idealny czas, aby omówić obsługę błędów. Zrobimy to w następnej kolejności!
Obsługa błędów
Błędy są faktem w oprogramowaniu, dlatego Rust posiada szereg funkcji do obsługi sytuacji, w których coś idzie nie tak. W wielu przypadkach Rust wymaga od Ciebie uznania możliwości błędu i podjęcia pewnych działań, zanim Twój kod się skompiluje. Ten wymóg sprawia, że Twój program jest bardziej niezawodny, zapewniając, że odkryjesz błędy i obsłużysz je odpowiednio, zanim wdrożysz swój kod do produkcji!
Rust dzieli błędy na dwie główne kategorie: błędy odzyskiwalne i nieodzyskiwalne. W przypadku błędu odzyskiwalnego, takiego jak błąd pliku nie znaleziono, najprawdopodobniej chcemy po prostu zgłosić problem użytkownikowi i ponowić operację. Błędy nieodzyskiwalne są zawsze objawami błędów, takich jak próba dostępu do lokalizacji poza końcem tablicy, dlatego chcemy natychmiast zatrzymać program.
Większość języków nie rozróżnia tych dwóch rodzajów błędów i obsługuje oba w ten sam sposób, używając mechanizmów takich jak wyjątki. Rust nie ma wyjątków. Zamiast tego, ma typ Result<T, E> dla błędów odzyskiwalnych i makro panic! które zatrzymuje wykonanie, gdy program napotka błąd nieodzyskiwalny. Ten rozdział najpierw omawia wywoływanie panic!, a następnie mówi o zwracaniu wartości Result<T, E>. Dodatkowo, zbadamy rozważania przy podejmowaniu decyzji, czy spróbować odzyskać się po błędzie, czy zatrzymać wykonanie.
Nieodwracalne błędy z panic!
Nieodwracalne błędy z panic!
Czasami w twoim kodzie dzieją się złe rzeczy i nic nie możesz na to poradzić. W takich przypadkach Rust ma makro panic!. W praktyce istnieją dwa sposoby wywołania paniki: poprzez wykonanie akcji, która powoduje panikę kodu (takiej jak dostęp do tablicy poza jej zakresem) lub poprzez jawne wywołanie makra panic!. W obu przypadkach powodujemy panikę w naszym programie. Domyślnie te paniki wyświetlą komunikat o błędzie, rozwiną stos, wyczyszczą stos i zakończą działanie. Za pomocą zmiennej środowiskowej możesz również sprawić, że Rust wyświetli stos wywołań, gdy wystąpi panika, co ułatwi śledzenie źródła paniki.
Rozwijanie stosu lub przerywanie działania w odpowiedzi na panikę
Domyślnie, gdy wystąpi panika, program zaczyna się rozwijać, co oznacza, że Rust cofa się po stosie i czyści dane z każdej napotkanej funkcji. Jednak cofanie się i czyszczenie to dużo pracy. Rust pozwala zatem wybrać alternatywę natychmiastowego przerwania, które kończy program bez czyszczenia.
Pamięć używana przez program będzie musiała zostać wyczyszczona przez system operacyjny. Jeśli w twoim projekcie musisz sprawić, aby wynikowy plik binarny był jak najmniejszy, możesz przełączyć się z rozwijania na przerwanie po panice, dodając
panic = 'abort'do odpowiednich sekcji[profile]w pliku Cargo.toml. Na przykład, jeśli chcesz przerwać działanie po panice w trybie wydania, dodaj to:[profile.release] panic = 'abort'
Spróbujmy wywołać panic! w prostym programie:
fn main() {
panic!("awaria i spalenie");
}Po uruchomieniu programu zobaczysz coś takiego:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Wywołanie panic! powoduje komunikat o błędzie zawarty w ostatnich dwóch liniach. Pierwsza linia pokazuje nasz komunikat paniki i miejsce w kodzie źródłowym, gdzie nastąpiła panika: src/main.rs:2:5 wskazuje, że jest to druga linia, piąty znak naszego pliku src/main.rs.
W tym przypadku wskazana linia jest częścią naszego kodu, a jeśli przejdziemy do tej linii, zobaczymy wywołanie makra panic!. W innych przypadkach wywołanie panic! może znajdować się w kodzie, który wywołuje nasz kod, a nazwa pliku i numer linii zgłoszone przez komunikat o błędzie będą kodem kogoś innego, gdzie wywołano makro panic!, a nie linią naszego kodu, która ostatecznie doprowadziła do wywołania panic!.
Możemy użyć śledzenia stosu funkcji, z których pochodzi wywołanie panic!, aby ustalić, która część naszego kodu powoduje problem. Aby zrozumieć, jak używać śledzenia stosu panic!, przyjrzyjmy się innemu przykładowi i zobaczmy, jak to wygląda, gdy wywołanie panic! pochodzi z biblioteki z powodu błędu w naszym kodzie, a nie z naszego kodu bezpośrednio wywołującego makro. Listing 9-1 zawiera kod, który próbuje uzyskać dostęp do indeksu w wektorze poza zakresem prawidłowych indeksów.
fn main() {
let v = vec![1, 2, 3];
v[99];
}Tutaj próbujemy uzyskać dostęp do 100. elementu naszego wektora (który znajduje się pod indeksem 99, ponieważ indeksowanie zaczyna się od zera), ale wektor ma tylko trzy elementy. W tej sytuacji Rust wywoła panikę. Użycie [] ma zwrócić element, ale jeśli podasz nieprawidłowy indeks, Rust nie mógłby zwrócić żadnego prawidłowego elementu.
W C, próba odczytu poza końcem struktury danych jest niezdefiniowanym zachowaniem. Możesz otrzymać cokolwiek, co znajduje się w miejscu w pamięci, które odpowiadałoby temu elementowi w strukturze danych, mimo że pamięć nie należy do tej struktury. Nazywa się to przepełnieniem bufora i może prowadzić do luk w zabezpieczeniach, jeśli atakujący jest w stanie manipulować indeksem w taki sposób, aby odczytać dane, do których nie powinien mieć dostępu, a które są przechowywane po strukturze danych.
Aby chronić program przed tego rodzaju lukami, jeśli spróbujesz odczytać element o indeksie, który nie istnieje, Rust zatrzyma wykonanie i odmówi kontynuowania. Spróbujmy i zobaczmy:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ten błąd wskazuje na linię 4 naszego main.rs, gdzie próbujemy uzyskać dostęp do indeksu 99 wektora w v.
Linia note: mówi nam, że możemy ustawić zmienną środowiskową RUST_BACKTRACE na dowolną wartość inną niż 0, aby uzyskać śledzenie stosu (backtrace) dokładnie tego, co się stało, aby spowodować błąd. Śledzenie stosu to lista wszystkich funkcji, które zostały wywołane, aby dojść do tego punktu. Śledzenia stosu w Rust działają tak samo jak w innych językach: kluczem do odczytania śledzenia stosu jest rozpoczęcie od góry i czytanie, aż zobaczysz pliki, które napisałeś. To jest miejsce, w którym problem się rozpoczął. Linie powyżej tego miejsca to kod, który wywołał Twój kod; linie poniżej to kod, który wywołał Twój kod. Te linie przed i po mogą zawierać podstawowy kod Rust, kod standardowej biblioteki lub skrzynki, których używasz. Spróbujmy uzyskać śledzenie stosu, ustawiając zmienną środowiskową RUST_BACKTRACE na dowolną wartość inną niż 0. Listing 9-2 pokazuje wyjście podobne do tego, co zobaczysz.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
To dużo danych wyjściowych! Dokładne dane wyjściowe mogą się różnić w zależności od systemu operacyjnego i wersji Rusta. Aby uzyskać śledzenia stosu z tymi informacjami, symbole debugowania muszą być włączone. Symbole debugowania są domyślnie włączone przy użyciu cargo build lub cargo run bez flagi --release, jak to zrobiliśmy tutaj.
W danych wyjściowych w Listing 9-2, linia 6 śledzenia stosu wskazuje na linię w naszym projekcie, która powoduje problem: linia 4 pliku src/main.rs. Jeśli nie chcemy, aby nasz program panikował, powinniśmy rozpocząć nasze dochodzenie w miejscu wskazanym przez pierwszą linię wspomniającą o pliku, który napisaliśmy. W Listing 9-1, gdzie celowo napisaliśmy kod, który wywołałby panikę, sposobem na naprawienie paniki jest nie żądanie elementu poza zakresem indeksów wektora. Gdy Twój kod panikuje w przyszłości, będziesz musiał dowiedzieć się, jaką akcję podejmuje kod z jakimi wartościami, aby spowodować panikę, i co kod powinien zrobić zamiast tego.
Powrócimy do panic! i do tego, kiedy powinniśmy, a kiedy nie powinniśmy używać panic! do obsługi warunków błędu, w sekcji „Panikować czy nie panikować!” w dalszej części tego rozdziału. Następnie przyjrzymy się, jak odzyskać się po błędzie za pomocą Result.
Błędy odzyskiwalne za pomocą Result
Błędy odzyskiwalne za pomocą Result
Większość błędów nie jest na tyle poważna, aby wymagać całkowitego zatrzymania programu. Czasami, gdy funkcja zawodzi, dzieje się tak z powodu, który można łatwo zinterpretować i na niego zareagować. Na przykład, jeśli próbujesz otworzyć plik, a ta operacja kończy się niepowodzeniem, ponieważ plik nie istnieje, możesz chcieć utworzyć plik zamiast zakończyć proces.
Przypomnij sobie z sekcji „Obsługa potencjalnych awarii za pomocą Result” w Rozdziale 2, że enum Result jest zdefiniowany tak, aby miał dwa warianty, Ok i Err, w następujący sposób:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}T i E to generyczne parametry typu: bardziej szczegółowo omówimy generyki w Rozdziale 10. To, co musisz teraz wiedzieć, to to, że T reprezentuje typ wartości, która zostanie zwrócona w przypadku sukcesu w wariancie Ok, a E reprezentuje typ błędu, który zostanie zwrócony w przypadku niepowodzenia w wariancie Err. Ponieważ Result ma te generyczne parametry typu, możemy używać typu Result i zdefiniowanych na nim funkcji w wielu różnych sytuacjach, gdy wartość sukcesu i wartość błędu, którą chcemy zwrócić, mogą się różnić.
Wywołajmy funkcję, która zwraca wartość Result, ponieważ funkcja może zawieść. W Listing 9-3 próbujemy otworzyć plik.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
}Typ zwracany przez File::open to Result<T, E>. Generyczny parametr T został wypełniony przez implementację File::open typem wartości sukcesu, std::fs::File, który jest uchwytem pliku. Typ E używany w wartości błędu to std::io::Error. Ten typ zwracany oznacza, że wywołanie File::open może zakończyć się sukcesem i zwrócić uchwyt pliku, z którego możemy czytać lub do którego możemy pisać. Wywołanie funkcji może również zakończyć się niepowodzeniem: na przykład plik może nie istnieć lub możemy nie mieć uprawnień do dostępu do pliku. Funkcja File::open musi mieć sposób, aby poinformować nas, czy zakończyła się sukcesem, czy niepowodzeniem, i jednocześnie podać nam uchwyt pliku lub informacje o błędzie. Te informacje to dokładnie to, co przekazuje enum Result.
W przypadku, gdy File::open zakończy się sukcesem, wartość w zmiennej greeting_file_result będzie instancją Ok, która zawiera uchwyt pliku. W przypadku, gdy zawiedzie, wartość w greeting_file_result będzie instancją Err, która zawiera więcej informacji o rodzaju błędu, który wystąpił.
Musimy uzupełnić kod w Listing 9-3, aby podejmować różne działania w zależności od wartości zwracanej przez File::open. Listing 9-4 pokazuje jeden ze sposobów obsługi Result za pomocą podstawowego narzędzia, wyrażenia match, które omówiliśmy w Rozdziale 6.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem z otwarciem pliku: {error:?}"),
};
}Zauważ, że, podobnie jak enum Option, enum Result i jego warianty zostały wprowadzone do zasięgu przez preludium, więc nie musimy określać Result:: przed wariantami Ok i Err w ramionach match.
Kiedy wynik jest Ok, ten kod zwróci wewnętrzną wartość file z wariantu Ok, a następnie przypisujemy tę wartość uchwytu pliku do zmiennej greeting_file. Po match możemy użyć uchwytu pliku do odczytu lub zapisu.
Drugie ramię match obsługuje przypadek, w którym otrzymujemy wartość Err z File::open. W tym przykładzie zdecydowaliśmy się wywołać makro panic!. Jeśli w naszym bieżącym katalogu nie ma pliku o nazwie hello.txt i uruchomimy ten kod, zobaczymy następujące dane wyjściowe z makra panic!:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Jak zwykle, to wyjście mówi nam dokładnie, co poszło nie tak.
Dopasowywanie różnych błędów
Kod w Listing 9-4 spowoduje panic! niezależnie od tego, dlaczego File::open zakończyło się niepowodzeniem. My jednak chcemy podejmować różne działania z różnych powodów awarii. Jeśli File::open zakończyło się niepowodzeniem, ponieważ plik nie istnieje, chcemy utworzyć plik i zwrócić uchwyt do nowego pliku. Jeśli File::open zakończyło się niepowodzeniem z jakiegokolwiek innego powodu — na przykład, ponieważ nie mieliśmy uprawnień do otwarcia pliku — nadal chcemy, aby kod spowodował panic! w ten sam sposób, jak w Listing 9-4. W tym celu dodajemy wewnętrzne wyrażenie match, pokazane w Listing 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem z tworzeniem pliku: {e:?}"),
},
_ => {
panic!("Problem z otwarciem pliku: {error:?}");
}
},
};
}Typ wartości zwracanej przez File::open w wariancie Err to io::Error, który jest strukturą dostarczaną przez standardową bibliotekę. Ta struktura posiada metodę kind, którą możemy wywołać, aby uzyskać wartość io::ErrorKind. Enum io::ErrorKind jest dostarczany przez standardową bibliotekę i ma warianty reprezentujące różne rodzaje błędów, które mogą wynikać z operacji io. Wariant, którego chcemy użyć, to ErrorKind::NotFound, który wskazuje, że plik, który próbujemy otworzyć, jeszcze nie istnieje. Zatem dopasowujemy greeting_file_result, ale mamy również wewnętrzne dopasowanie na error.kind().
Warunkiem, który chcemy sprawdzić w wewnętrznym dopasowaniu, jest to, czy wartość zwrócona przez error.kind() jest wariantem NotFound enum ErrorKind. Jeśli tak, próbujemy utworzyć plik za pomocą File::create. Jednakże, ponieważ File::create również może zakończyć się niepowodzeniem, potrzebujemy drugiego ramienia w wewnętrznym wyrażeniu match. Kiedy plik nie może zostać utworzony, wyświetlany jest inny komunikat o błędzie. Drugie ramię zewnętrznego match pozostaje takie samo, więc program panikuje przy każdym błędzie innym niż błąd braku pliku.
Alternatywy dla używania
matchzResult<T, E>To dużo
match! Wyrażeniematchjest bardzo przydatne, ale także bardzo prymitywne. W Rozdziale 13 poznasz domknięcia, które są używane z wieloma metodami zdefiniowanymi dlaResult<T, E>. Te metody mogą być bardziej zwięzłe niż używaniematchpodczas obsługi wartościResult<T, E>w Twoim kodzie.Na przykład, oto inny sposób napisania tej samej logiki, jak pokazano w Listing 9-5, tym razem używając domknięć i metody
unwrap_or_else:use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem z tworzeniem pliku: {error:?}"); }) } else { panic!("Problem z otwarciem pliku: {error:?}"); } }); }Chociaż ten kod ma takie samo zachowanie jak Listing 9-5, nie zawiera żadnych wyrażeń
matchi jest czytelniejszy. Wróć do tego przykładu po przeczytaniu Rozdziału 13 i wyszukaj metodęunwrap_or_elsew dokumentacji standardowej biblioteki. Wiele innych z tych metod może uporządkować ogromne, zagnieżdżone wyrażeniamatch, gdy masz do czynienia z błędami.
Skróty do paniki przy błędzie: unwrap i expect
Użycie match działa wystarczająco dobrze, ale może być nieco gadatliwe i nie zawsze dobrze komunikuje intencje. Typ Result<T, E> ma wiele pomocniczych metod zdefiniowanych na nim do wykonywania różnych, bardziej specyficznych zadań. Metoda unwrap jest skrótem zaimplementowanym tak samo jak wyrażenie match, które napisaliśmy w Listing 9-4. Jeśli wartość Result jest wariantem Ok, unwrap zwróci wartość wewnątrz Ok. Jeśli Result jest wariantem Err, unwrap wywoła dla nas makro panic!. Oto przykład unwrap w działaniu:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt").unwrap();
}Jeśli uruchomimy ten kod bez pliku hello.txt, zobaczymy komunikat o błędzie z wywołania panic!, które wykonuje metoda unwrap:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Podobnie, metoda expect pozwala nam również wybrać komunikat o błędzie panic!. Użycie expect zamiast unwrap i dostarczenie dobrych komunikatów o błędach może przekazać twoje intencje i ułatwić śledzenie źródła paniki. Składnia expect wygląda tak:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")
.expect("hello.txt powinien być dołączony do tego projektu");
}Używamy expect w ten sam sposób co unwrap: aby zwrócić uchwyt pliku lub wywołać makro panic!. Komunikat o błędzie używany przez expect w jego wywołaniu panic! będzie parametrem, który przekazujemy do expect, zamiast domyślnego komunikatu panic!, którego używa unwrap. Oto jak to wygląda:
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
W kodzie produkcyjnym większość Rustacean preferuje expect zamiast unwrap i podaje więcej kontekstu, dlaczego operacja ma zawsze zakończyć się sukcesem. W ten sposób, jeśli twoje założenia kiedykolwiek okażą się błędne, masz więcej informacji do wykorzystania w debugowaniu.
Propagacja błędów
Kiedy implementacja funkcji wywołuje coś, co może zawieść, zamiast obsługiwać błąd w samej funkcji, możesz zwrócić błąd do kodu wywołującego, aby ten mógł zdecydować, co zrobić. Jest to znane jako propagacja błędu i daje większą kontrolę kodowi wywołującemu, gdzie może być więcej informacji lub logiki, która dyktuje, jak błąd powinien być obsłużony, niż to, co masz dostępne w kontekście swojego kodu.
Na przykład, Listing 9-6 pokazuje funkcję, która odczytuje nazwę użytkownika z pliku. Jeśli plik nie istnieje lub nie można go odczytać, funkcja zwróci te błędy do kodu, który wywołał funkcję.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let username_file_result = File::open("hello.txt");
let mut username_file = match username_file_result {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
}Ta funkcja może być napisana w znacznie krótszy sposób, ale zaczniemy od jej ręcznego implementowania, aby zbadać obsługę błędów; na końcu pokażemy krótszy sposób. Spójrzmy najpierw na typ zwracany przez funkcję: Result<String, io::Error>. Oznacza to, że funkcja zwraca wartość typu Result<T, E>, gdzie generyczny parametr T został wypełniony konkretnym typem String, a generyczny typ E został wypełniony konkretnym typem io::Error.
Jeśli ta funkcja zakończy się sukcesem bez żadnych problemów, kod, który ją wywołuje, otrzyma wartość Ok, która zawiera String – username, który ta funkcja odczytała z pliku. Jeśli ta funkcja napotka jakiekolwiek problemy, kod wywołujący otrzyma wartość Err, która zawiera więcej informacji o tym, jakie były problemy. Wybraliśmy io::Error jako typ zwracany tej funkcji, ponieważ jest to typ wartości błędu zwracany przez obie operacje, które wywołujemy w treści tej funkcji i które mogą zawieść: funkcja File::open i metoda read_to_string.
Ciało funkcji zaczyna się od wywołania funkcji File::open. Następnie obsługujemy wartość Result za pomocą match, podobnego do match w Listing 9-4. Jeśli File::open zakończy się sukcesem, uchwyt pliku w zmiennej wzorca file staje się wartością w mutowalnej zmiennej username_file, a funkcja kontynuuje. W przypadku Err, zamiast wywoływać panic!, używamy słowa kluczowego return, aby natychmiast wyjść z funkcji i przekazać wartość błędu z File::open, teraz w zmiennej wzorca e, z powrotem do kodu wywołującego jako wartość błędu tej funkcji.
Zatem, jeśli mamy uchwyt pliku w username_file, funkcja następnie tworzy nowy String w zmiennej username i wywołuje metodę read_to_string na uchwycie pliku w username_file, aby odczytać zawartość pliku do username. Metoda read_to_string również zwraca Result, ponieważ może zawieść, nawet jeśli File::open zakończyło się sukcesem. Musimy więc użyć kolejnego match do obsługi tego Result: Jeśli read_to_string zakończy się sukcesem, to nasza funkcja zakończyła się sukcesem, i zwracamy nazwę użytkownika z pliku, która jest teraz w username, zawiniętą w Ok. Jeśli read_to_string zawiedzie, zwracamy wartość błędu w taki sam sposób, w jaki zwróciliśmy wartość błędu w match, które obsługiwało wartość zwracaną przez File::open. Nie musimy jednak jawnie mówić return, ponieważ jest to ostatnie wyrażenie w funkcji.
Kod wywołujący ten kod będzie następnie obsługiwał otrzymanie wartości Ok, która zawiera nazwę użytkownika, lub wartości Err, która zawiera io::Error. To od kodu wywołującego zależy, co zrobić z tymi wartościami. Jeśli kod wywołujący otrzyma wartość Err, mógłby wywołać panic! i zniszczyć program, użyć domyślnej nazwy użytkownika lub wyszukać nazwę użytkownika gdzie indziej niż w pliku, na przykład. Nie mamy wystarczających informacji o tym, co kod wywołujący faktycznie próbuje zrobić, więc propagujemy wszystkie informacje o sukcesie lub błędzie w górę, aby zostały odpowiednio obsłużone.
Ten wzorzec propagacji błędów jest tak powszechny w Rust, że Rust udostępnia operator znak zapytania ?, aby to ułatwić.
Skrót operatora ? do propagacji błędów
Listing 9-7 pokazuje implementację read_username_from_file, która ma tę samą funkcjonalność co w Listing 9-6, ale ta implementacja używa operatora ?.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
}Operator ? umieszczony po wartości Result działa prawie tak samo jak wyrażenia match, które zdefiniowaliśmy do obsługi wartości Result w Listing 9-6. Jeśli wartość Result to Ok, wartość wewnątrz Ok zostanie zwrócona z tego wyrażenia, a program będzie kontynuował. Jeśli wartość to Err, Err zostanie zwrócone z całej funkcji tak, jakbyśmy użyli słowa kluczowego return, tak aby wartość błędu została propagowana do kodu wywołującego.
Istnieje różnica między tym, co robi wyrażenie match z Listing 9-6, a tym, co robi operator ?: wartości błędów, na których wywołano operator ?, przechodzą przez funkcję from, zdefiniowaną w cesze From w standardowej bibliotece, która jest używana do konwertowania wartości z jednego typu na inny. Gdy operator ? wywołuje funkcję from, otrzymany typ błędu jest konwertowany na typ błędu zdefiniowany w typie zwracanym bieżącej funkcji. Jest to przydatne, gdy funkcja zwraca jeden typ błędu, aby reprezentować wszystkie sposoby, w jakie funkcja może zawieść, nawet jeśli części mogą zawieść z wielu różnych powodów.
Na przykład, moglibyśmy zmienić funkcję read_username_from_file w Listing 9-7 tak, aby zwracała niestandardowy typ błędu o nazwie OurError, który zdefiniujemy. Jeśli zdefiniujemy również impl From<io::Error> for OurError, aby skonstruować instancję OurError z io::Error, to wywołania operatora ? w ciele read_username_from_file wywołają from i przekonwertują typy błędów bez potrzeby dodawania do funkcji żadnego dodatkowego kodu.
W kontekście Listing 9-7, ? na końcu wywołania File::open zwróci wartość wewnątrz Ok do zmiennej username_file. Jeśli wystąpi błąd, operator ? natychmiast wyjdzie z całej funkcji i przekaże dowolną wartość Err do kodu wywołującego. To samo dotyczy ? na końcu wywołania read_to_string.
Operator ? eliminuje wiele szablonowego kodu i upraszcza implementację tej funkcji. Moglibyśmy nawet skrócić ten kod, łącząc wywołania metod bezpośrednio po ?, jak pokazano w Listing 9-8.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
File::open("hello.txt")?.read_to_string(&mut username)?;
Ok(username)
}
}Tworzenie nowego String w username przenieśliśmy na początek funkcji; ta część nie uległa zmianie. Zamiast tworzyć zmienną username_file, połączyliśmy wywołanie read_to_string bezpośrednio z wynikiem File::open("hello.txt")?. Nadal mamy ? na końcu wywołania read_to_string i nadal zwracamy wartość Ok zawierającą username, gdy zarówno File::open, jak i read_to_string zakończą się sukcesem, zamiast zwracać błędy. Funkcjonalność jest ponownie taka sama jak w Listing 9-6 i Listing 9-7; jest to po prostu inny, bardziej ergonomiczny sposób zapisu.
Listing 9-9 pokazuje sposób na jeszcze większe skrócenie tego za pomocą fs::read_to_string.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn read_username_from_file() -> Result<String, io::Error> {
fs::read_to_string("hello.txt")
}
}Odczytywanie pliku do ciągu znaków jest dość powszechną operacją, dlatego standardowa biblioteka udostępnia wygodną funkcję fs::read_to_string, która otwiera plik, tworzy nowy String, odczytuje zawartość pliku, umieszcza zawartość w tym String i zwraca go. Oczywiście, użycie fs::read_to_string nie daje nam możliwości wyjaśnienia całej obsługi błędów, dlatego najpierw zrobiliśmy to w dłuższy sposób.
Gdzie można używać operatora ?
Operator ? może być używany tylko w funkcjach, których typ zwracany jest zgodny z wartością, na której użyto ?. Dzieje się tak, ponieważ operator ? jest zdefiniowany do wykonania wczesnego zwrócenia wartości z funkcji, w ten sam sposób, co wyrażenie match, które zdefiniowaliśmy w Listing 9-6. W Listing 9-6 match używał wartości Result, a ramię wczesnego zwrócenia zwracało wartość Err(e). Typ zwracany funkcji musi być Result, aby był zgodny z tym return.
W Listing 9-10 przyjrzyjmy się błędowi, który otrzymamy, jeśli użyjemy operatora ? w funkcji main z typem zwracanym niezgodnym z typem wartości, na której używamy ?.
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}Ten kod otwiera plik, co może zakończyć się niepowodzeniem. Operator ? następuje po wartości Result zwracanej przez File::open, ale ta funkcja main ma typ zwracany (), a nie Result. Kiedy skompilujemy ten kod, otrzymamy następujący komunikat o błędzie:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
Ten błąd wskazuje, że możemy używać operatora ? tylko w funkcji, która zwraca Result, Option lub inny typ implementujący FromResidual.
Aby naprawić błąd, masz dwie możliwości. Jedna to zmiana typu zwracanego przez funkcję, aby był zgodny z wartością, na której używasz operatora ?, o ile nie ma żadnych ograniczeń, które by to uniemożliwiały. Druga to użycie match lub jednej z metod Result<T, E>, aby obsłużyć Result<T, E> w dowolny odpowiedni sposób.
Komunikat o błędzie wspominał również, że ? może być używany z wartościami Option<T>. Podobnie jak w przypadku użycia ? na Result, możesz używać ? na Option tylko w funkcji, która zwraca Option. Zachowanie operatora ? wywoływanego na Option<T> jest podobne do jego zachowania wywoływanego na Result<T, E>: Jeśli wartość to None, None zostanie zwrócone z funkcji w tym momencie. Jeśli wartość to Some, wartość wewnątrz Some jest wartością wynikową wyrażenia, a funkcja kontynuuje. Listing 9-11 zawiera przykład funkcji, która znajduje ostatni znak pierwszej linii w danym tekście.
fn last_char_of_first_line(text: &str) -> Option<char> {
text.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
last_char_of_first_line("Witaj, świecie\nJak się masz dzisiaj?"),
Some('e')
);
assert_eq!(last_char_of_first_line(""), None);
assert_eq!(last_char_of_first_line("\nhi"), None);
}Ta funkcja zwraca Option<char>, ponieważ możliwe jest, że tam jest znak, ale możliwe jest również, że go nie ma. Ten kod pobiera argument wycinka ciągu text i wywołuje na nim metodę lines, która zwraca iterator po liniach w ciągu. Ponieważ ta funkcja chce zbadać pierwszą linię, wywołuje next na iteratorze, aby uzyskać pierwszą wartość z iteratora. Jeśli text jest pustym ciągiem, to wywołanie next zwróci None, w którym to przypadku używamy ?, aby zatrzymać i zwrócić None z last_char_of_first_line. Jeśli text nie jest pustym ciągiem, next zwróci wartość Some zawierającą wycinek ciągu pierwszej linii w text.
Operator ? wyodrębnia wycinek ciągu znaków, a my możemy wywołać chars na tym wycinku ciągu znaków, aby uzyskać iterator jego znaków. Interesuje nas ostatni znak w tej pierwszej linii, więc wywołujemy last, aby zwrócić ostatni element w iteratorze. Jest to Option, ponieważ możliwe jest, że pierwsza linia jest pustym ciągiem; na przykład, jeśli text zaczyna się od pustej linii, ale ma znaki w innych liniach, jak w "\nhi". Jednakże, jeśli istnieje ostatni znak w pierwszej linii, zostanie on zwrócony w wariancie Some. Operator ? w środku daje nam zwięzły sposób wyrażenia tej logiki, pozwalając nam zaimplementować funkcję w jednej linii. Gdybyśmy nie mogli użyć operatora ? na Option, musielibyśmy zaimplementować tę logikę, używając większej liczby wywołań metod lub wyrażenia match.
Zauważ, że możesz używać operatora ? na Result w funkcji, która zwraca Result, i możesz używać operatora ? na Option w funkcji, która zwraca Option, ale nie możesz ich mieszać. Operator ? nie przekonwertuje automatycznie Result na Option ani na odwrót; w tych przypadkach możesz użyć metod, takich jak metoda ok na Result lub metoda ok_or na Option, aby wykonać konwersję jawnie.
Do tej pory wszystkie używane przez nas funkcje main zwracały (). Funkcja main jest specjalna, ponieważ jest punktem wejścia i wyjścia programu wykonywalnego, a istnieją ograniczenia dotyczące jej typu zwracanego, aby program działał zgodnie z oczekiwaniami.
Na szczęście, main może również zwrócić Result<(), E>. Listing 9-12 zawiera kod z Listing 9-10, ale zmieniliśmy typ zwracany main na Result<(), Box<dyn Error>> i dodaliśmy wartość zwracaną Ok(()) na końcu. Ten kod teraz się skompiluje.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}Typ Box<dyn Error> to obiekt cechy, o którym będziemy mówić w sekcji „Używanie obiektów cech do abstrakcji wspólnego zachowania” w Rozdziale 18. Na razie możesz czytać Box<dyn Error> jako „dowolny rodzaj błędu”. Użycie ? na wartości Result w funkcji main z typem błędu Box<dyn Error> jest dozwolone, ponieważ pozwala to na wczesne zwrócenie dowolnej wartości Err. Mimo że ciało tej funkcji main zawsze będzie zwracać błędy typu std::io::Error, poprzez określenie Box<dyn Error>, ta sygnatura będzie nadal poprawna, nawet jeśli do ciała main zostanie dodany więcej kodu, który zwraca inne błędy.
Kiedy funkcja main zwraca Result<(), E>, plik wykonywalny zakończy działanie z wartością 0, jeśli main zwróci Ok(()), a zakończy działanie z wartością różną od zera, jeśli main zwróci wartość Err. Pliki wykonywalne napisane w C zwracają liczby całkowite po zakończeniu działania: programy, które zakończyły działanie pomyślnie, zwracają liczbę całkowitą 0, a programy, które zakończyły się błędem, zwracają jakąś liczbę całkowitą inną niż 0. Rust również zwraca liczby całkowite z plików wykonywalnych, aby być zgodnym z tą konwencją.
Funkcja main może zwracać dowolne typy implementujące cechę std::process::Termination, która zawiera funkcję report zwracającą ExitCode. Zapoznaj się z dokumentacją standardowej biblioteki, aby uzyskać więcej informacji na temat implementacji cechy Termination dla własnych typów.
Teraz, gdy omówiliśmy szczegóły wywoływania panic! lub zwracania Result, wróćmy do tematu, jak zdecydować, który z nich jest odpowiedni do użycia w jakich przypadkach.
Panikować czy nie panikować!
Panikować czy nie panikować!
Jak więc zdecydować, kiedy należy wywołać panic!, a kiedy zwrócić Result? Kiedy kod panikuje, nie ma sposobu na odzyskanie. Możesz wywołać panic! w każdej sytuacji błędu, niezależnie od tego, czy istnieje możliwość odzyskania, czy nie, ale wtedy podejmujesz decyzję, że sytuacja jest nie do odzyskania w imieniu kodu wywołującego. Kiedy zdecydujesz się zwrócić wartość Result, dajesz kodowi wywołującemu opcje. Kod wywołujący może spróbować odzyskać się w sposób odpowiedni dla swojej sytuacji, lub może zdecydować, że wartość Err w tym przypadku jest nie do odzyskania, więc może wywołać panic! i zmienić Twój odzyskiwalny błąd w błąd nie do odzyskania. Dlatego zwracanie Result jest dobrym domyślnym wyborem, gdy definiujesz funkcję, która może zawieść.
W sytuacjach takich jak przykłady, kod prototypowy i testy, bardziej odpowiednie jest pisanie kodu, który panikuje zamiast zwracać Result. Zbadajmy dlaczego, a następnie omówmy sytuacje, w których kompilator nie może stwierdzić, że awaria jest niemożliwa, ale Ty jako człowiek możesz. Rozdział zakończy się ogólnymi wytycznymi dotyczącymi tego, jak zdecydować, czy panikować w kodzie biblioteki.
Przykłady, kod prototypowy i testy
Kiedy piszesz przykład, aby zilustrować jakąś koncepcję, również uwzględnianie solidnego kodu do obsługi błędów może uczynić przykład mniej jasnym. W przykładach rozumie się, że wywołanie metody, takiej jak unwrap, która może spowodować panikę, ma być jedynie symulatorem sposobu, w jaki Twoja aplikacja obsługiwałaby błędy, co może się różnić w zależności od tego, co robi reszta Twojego kodu.
Podobnie, metody unwrap i expect są bardzo przydatne, gdy prototypujesz i nie jesteś jeszcze gotowy, aby zdecydować, jak obsługiwać błędy. Pozostawiają one jasne znaczniki w kodzie, na wypadek gdy będziesz gotowy, aby uczynić swój program bardziej niezawodnym.
Jeśli wywołanie metody zakończy się niepowodzeniem w teście, chciałbyś, aby cały test zakończył się niepowodzeniem, nawet jeśli ta metoda nie jest testowaną funkcjonalnością. Ponieważ panic! oznacza, że test zakończył się niepowodzeniem, wywołanie unwrap lub expect jest dokładnie tym, co powinno się stać.
Kiedy masz więcej informacji niż kompilator
Odpowiednie byłoby również wywołanie expect, gdy masz inną logikę, która gwarantuje, że Result będzie miał wartość Ok, ale logika nie jest czymś, co kompilator rozumie. Nadal będziesz mieć wartość Result, którą musisz obsłużyć: każda operacja, którą wywołujesz, nadal ma możliwość ogólnego niepowodzenia, nawet jeśli jest to logicznie niemożliwe w Twojej konkretnej sytuacji. Jeśli możesz upewnić się, ręcznie sprawdzając kod, że nigdy nie będziesz mieć wariantu Err, jest całkowicie dopuszczalne wywołanie expect i udokumentowanie powodu, dla którego uważasz, że nigdy nie będziesz mieć wariantu Err w tekście argumentu. Oto przykład:
fn main() {
use std::net::IpAddr;
let home: IpAddr = "127.0.0.1"
.parse()
.expect("Zakodowany na stałe adres IP powinien być prawidłowy");
}Tworzymy instancję IpAddr poprzez parsowanie zakodowanego na stałe ciągu znaków. Widzimy, że 127.0.0.1 jest prawidłowym adresem IP, więc w tym przypadku użycie expect jest dopuszczalne. Jednak posiadanie zakodowanego na stałe, prawidłowego ciągu znaków nie zmienia typu zwracanego przez metodę parse: nadal otrzymujemy wartość Result, a kompilator nadal będzie nas zmuszał do obsługi Result, tak jakby wariant Err był możliwy, ponieważ kompilator nie jest wystarczająco sprytny, aby zobaczyć, że ten ciąg znaków jest zawsze prawidłowym adresem IP. Gdyby ciąg znaków adresu IP pochodził od użytkownika, a nie był zakodowany na stałe w programie i dlatego miał możliwość awarii, z pewnością chcielibyśmy obsłużyć Result w bardziej niezawodny sposób.
Wspomnienie o założeniu, że ten adres IP jest zakodowany na stałe, skłoni nas do zmiany expect na lepszy kod obsługi błędów, jeśli w przyszłości będziemy musieli uzyskać adres IP z innego źródła.
Wytyczne dotyczące obsługi błędów
Zaleca się, aby kod panikował, gdy możliwe jest, że kod może znaleźć się w złym stanie. W tym kontekście zły stan to sytuacja, w której zostało naruszone jakieś założenie, gwarancja, kontrakt lub niezmiennik, na przykład, gdy do kodu przekazywane są nieprawidłowe wartości, wartości sprzeczne lub brakujące wartości — plus jeden lub więcej z poniższych:
- Zły stan jest czymś nieoczekiwanym, w przeciwieństwie do czegoś, co prawdopodobnie będzie się sporadycznie zdarzać, jak na przykład użytkownik wprowadzający dane w niewłaściwym formacie.
- Twój kod po tym punkcie musi polegać na tym, że nie jest w tym złym stanie, zamiast sprawdzać problem na każdym kroku.
- Nie ma dobrego sposobu na zakodowanie tych informacji w używanych typach. Omówimy przykład tego, co mamy na myśli, w sekcji „Kodowanie stanów i zachowań jako typy” w Rozdziale 18.
Jeśli ktoś wywoła Twój kod i przekaże wartości, które nie mają sensu, najlepiej jest zwrócić błąd, jeśli to możliwe, aby użytkownik biblioteki mógł zdecydować, co chce zrobić w takim przypadku. Jednak w przypadkach, gdy kontynuowanie mogłoby być niebezpieczne lub szkodliwe, najlepszym wyborem może być wywołanie panic! i ostrzeżenie osoby używającej Twojej biblioteki o błędzie w jej kodzie, aby mogła go naprawić podczas developmentu. Podobnie, panic! jest często odpowiednie, jeśli wywołujesz kod zewnętrzny, który jest poza Twoją kontrolą i zwraca nieprawidłowy stan, którego nie masz jak naprawić.
Jednakże, gdy awaria jest oczekiwana, bardziej odpowiednie jest zwrócenie Result niż wywołanie panic!. Przykłady obejmują parser, który otrzymuje źle sformatowane dane, lub żądanie HTTP zwracające status wskazujący, że osiągnięto limit szybkości. W takich przypadkach zwrócenie Result wskazuje, że awaria jest oczekiwaną możliwością, którą kod wywołujący musi zdecydować, jak obsłużyć.
Kiedy Twój kod wykonuje operację, która mogłaby narazić użytkownika na ryzyko, jeśli zostanie wywołana z nieprawidłowymi wartościami, Twój kod powinien najpierw zweryfikować, czy wartości są prawidłowe, i wywołać panikę, jeśli wartości są nieprawidłowe. Jest to głównie ze względów bezpieczeństwa: próba operowania na nieprawidłowych danych może narazić Twój kod na luki. To główny powód, dla którego standardowa biblioteka wywoła panic!, jeśli spróbujesz uzyskać dostęp do pamięci poza jej granicami: próba dostępu do pamięci, która nie należy do bieżącej struktury danych, jest częstym problemem bezpieczeństwa. Funkcje często mają kontrakty: ich zachowanie jest gwarantowane tylko wtedy, gdy dane wejściowe spełniają określone wymagania. Panika, gdy kontrakt jest naruszony, ma sens, ponieważ naruszenie kontraktu zawsze wskazuje na błąd po stronie wywołującego, i nie jest to rodzaj błędu, który kod wywołujący powinien jawnie obsługiwać. W rzeczywistości nie ma rozsądnego sposobu, aby kod wywołujący się odzyskał; programiści wywołujący muszą naprawić kod. Kontrakty funkcji, zwłaszcza gdy naruszenie spowoduje panikę, powinny być wyjaśnione w dokumentacji API funkcji.
Jednakże, posiadanie wielu kontroli błędów we wszystkich funkcjach byłoby rozbudowane i uciążliwe. Na szczęście, możesz użyć systemu typów Rusta (a co za tym idzie, sprawdzania typów wykonywanego przez kompilator), aby wykonać wiele kontroli za Ciebie. Jeśli Twoja funkcja ma określony typ jako parametr, możesz kontynuować logikę kodu, wiedząc, że kompilator już zapewnił, że masz prawidłową wartość. Na przykład, jeśli masz typ zamiast Option, Twój program oczekuje czegoś zamiast niczego. Twój kod nie musi wtedy obsługiwać dwóch przypadków dla wariantów Some i None: będzie miał tylko jeden przypadek dla zdecydowanego posiadania wartości. Kod próbujący przekazać nic do Twojej funkcji nawet się nie skompiluje, więc Twoja funkcja nie musi sprawdzać tego przypadku w czasie wykonywania. Innym przykładem jest użycie typu liczby całkowitej bez znaku, takiego jak u32, co zapewnia, że parametr nigdy nie jest ujemny.
Niestandardowe typy do walidacji
Rozwińmy ideę używania systemu typów Rusta do zapewnienia, że mamy prawidłową wartość, idąc o krok dalej i przyjrzyjmy się tworzeniu niestandardowego typu do walidacji. Przypomnij sobie grę zgadywanek z Rozdziału 2, w której nasz kod prosił użytkownika o odgadnięcie liczby od 1 do 100. Nigdy nie walidowaliśmy, czy odgadnięta przez użytkownika liczba mieściła się w tym zakresie, zanim porównaliśmy ją z naszą tajną liczbą; walidowaliśmy tylko, czy odgadnięta liczba była dodatnia. W tym przypadku konsekwencje nie były zbyt poważne: nasze komunikaty „Za mała” lub „Za duża” nadal byłyby poprawne. Ale przydatnym ulepszeniem byłoby pokierowanie użytkownika w stronę prawidłowych zgadywanek i zapewnienie innego zachowania, gdy użytkownik odgadnie liczbę spoza zakresu, niż gdy użytkownik wpisze na przykład litery.
Jednym ze sposobów na to byłoby parsowanie odgadniętej liczby jako i32 zamiast tylko u32, aby umożliwić potencjalnie ujemne liczby, a następnie dodanie sprawdzenia, czy liczba mieści się w zakresie, tak jak poniżej:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Odgadnij liczbę!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Wprowadź swoje odgadnięcie.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Nie udało się odczytać linii");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("Tajny numer będzie między 1 a 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Za mała!"),
Ordering::Greater => println!("Za duża!"),
Ordering::Equal => {
println!("Wygrałeś!");
break;
}
}
}
}Wyrażenie if sprawdza, czy nasza wartość jest poza zakresem, informuje użytkownika o problemie i wywołuje continue, aby rozpocząć kolejną iterację pętli i poprosić o kolejne odgadnięcie. Po wyrażeniu if możemy kontynuować porównania między guess a tajną liczbą, wiedząc, że guess znajduje się między 1 a 100.
Jednak to nie jest idealne rozwiązanie: gdyby absolutnie kluczowe było to, aby program operował tylko na wartościach od 1 do 100, i miał wiele funkcji z tym wymogiem, posiadanie takiego sprawdzenia w każdej funkcji byłoby uciążliwe (i mogłoby wpłynąć na wydajność).
Zamiast tego, możemy utworzyć nowy typ w dedykowanym module i umieścić walidacje w funkcji, aby utworzyć instancję tego typu, zamiast powtarzać walidacje wszędzie. W ten sposób funkcje będą mogły bezpiecznie używać nowego typu w swoich sygnaturach i śmiało używać otrzymanych wartości. Listing 9-13 pokazuje jeden ze sposobów definiowania typu Guess, który utworzy instancję Guess tylko wtedy, gdy funkcja new otrzyma wartość z zakresu od 1 do 100.
#![allow(unused)]
fn main() {
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Wartość odgadnięcia musi być między 1 a 100, otrzymano {value}.");
}
Guess { value }
}
pub fn value(&self) -> i32 {
self.value
}
}
}Zauważ, że ten kod w src/guessing_game.rs zależy od dodania deklaracji modułu mod guessing_game; w src/lib.rs, której tutaj nie pokazaliśmy. W pliku tego nowego modułu definiujemy strukturę o nazwie Guess, która ma pole o nazwie value, przechowujące i32. Tutaj będzie przechowywana liczba.
Następnie implementujemy funkcję skojarzoną o nazwie new dla Guess, która tworzy instancje wartości Guess. Funkcja new jest zdefiniowana tak, aby miała jeden parametr o nazwie value typu i32 i zwracała Guess. Kod w treści funkcji new testuje value, aby upewnić się, że mieści się ono w zakresie od 1 do 100. Jeśli value nie przejdzie tego testu, wywołujemy panic!, co ostrzeże programistę piszącego kod wywołujący, że ma błąd do naprawienia, ponieważ utworzenie Guess z value spoza tego zakresu naruszyłoby kontrakt, na którym polega Guess::new. Warunki, w których Guess::new może panikować, powinny być omówione w jego publicznie dostępnej dokumentacji API; konwencje dokumentacji wskazujące na możliwość paniki w dokumentacji API, którą tworzysz, omówimy w rozdziale 14. Jeśli value przejdzie test, tworzymy nowy Guess z jego polem value ustawionym na parametr value i zwracamy Guess.
Następnie implementujemy metodę o nazwie value, która pożycza self, nie ma żadnych innych parametrów i zwraca i32. Taki rodzaj metody jest czasami nazywany getterem, ponieważ jego celem jest pobranie danych z pól i zwrócenie ich. Ta publiczna metoda jest niezbędna, ponieważ pole value struktury Guess jest prywatne. Ważne jest, aby pole value było prywatne, aby kod używający struktury Guess nie mógł bezpośrednio ustawiać value: kod spoza modułu guessing_game musi używać funkcji Guess::new do tworzenia instancji Guess, zapewniając w ten sposób, że nie ma możliwości, aby Guess miało value, które nie zostało sprawdzone przez warunki w funkcji Guess::new.
Funkcja, która ma parametr lub zwraca tylko liczby z zakresu od 1 do 100, mogłaby następnie zadeklarować w swojej sygnaturze, że przyjmuje lub zwraca Guess zamiast i32 i nie musiałaby wykonywać żadnych dodatkowych sprawdzeń w swoim ciele.
Podsumowanie
Funkcje obsługi błędów w Rust są zaprojektowane tak, aby pomóc Ci pisać bardziej niezawodny kod. Makro panic! sygnalizuje, że Twój program jest w stanie, którego nie jest w stanie obsłużyć, i pozwala Ci nakazać procesowi zatrzymanie się, zamiast próbować kontynuować z nieprawidłowymi lub błędnymi wartościami. Enum Result używa systemu typów Rusta, aby wskazać, że operacje mogą zakończyć się niepowodzeniem w sposób, który Twój kod mógłby odzyskać. Możesz użyć Result, aby powiedzieć kodowi, który wywołuje Twój kod, że musi on również obsłużyć potencjalny sukces lub niepowodzenie. Użycie panic! i Result w odpowiednich sytuacjach sprawi, że Twój kod będzie bardziej niezawodny w obliczu nieuniknionych problemów.
Teraz, gdy widziałeś przydatne sposoby, w jakie standardowa biblioteka używa generyków z enumami Option i Result, porozmawiamy o tym, jak działają generyki i jak możesz ich używać w swoim kodzie.
Typy generyczne, cechy i czasy życia
Każdy język programowania posiada narzędzia do efektywnego zarządzania powtarzalnością koncepcji. W Rust, jednym z takich narzędzi są generyki: abstrakcyjne zamienniki dla konkretnych typów lub innych właściwości. Możemy wyrazić zachowanie generyków lub ich relacje z innymi generykami, nie wiedząc, co znajdzie się na ich miejscu podczas kompilacji i uruchamiania kodu.
Funkcje mogą przyjmować parametry jakiegoś typu generycznego, zamiast konkretnego typu, takiego jak i32 lub String, w ten sam sposób, w jaki przyjmują parametry o nieznanych wartościach, aby uruchamiać ten sam kod na wielu konkretnych wartościach. W rzeczywistości, już używaliśmy generyków w Rozdziale 6 z Option<T>, w Rozdziale 8 z Vec<T> i HashMap<K, V>, oraz w Rozdziale 9 z Result<T, E>. W tym rozdziale poznasz, jak definiować własne typy, funkcje i metody za pomocą generyków!
Najpierw przypomnimy, jak wyodrębnić funkcję, aby zmniejszyć duplikację kodu. Następnie użyjemy tej samej techniki, aby stworzyć funkcję generyczną z dwóch funkcji, które różnią się tylko typami swoich parametrów. Wyjaśnimy również, jak używać typów generycznych w definicjach struktur i wyliczeń.
Następnie dowiesz się, jak używać cech (traits) do definiowania zachowania w sposób generyczny. Możesz łączyć cechy z typami generycznymi, aby ograniczyć typ generyczny do akceptowania tylko tych typów, które mają określone zachowanie, w przeciwieństwie do dowolnego typu.
Na koniec omówimy czasy życia: odmianę generyków, która dostarcza kompilatorowi informacji o tym, jak referencje odnoszą się do siebie. Czasy życia pozwalają nam dostarczyć kompilatorowi wystarczających informacji o pożyczonych wartościach, aby mógł on zapewnić, że referencje będą ważne w większej liczbie sytuacji, niż byłoby to możliwe bez naszej pomocy.
Usuwanie duplikacji poprzez wyodrębnianie funkcji
Generyki pozwalają nam zastępować konkretne typy przez placeholder, który reprezentuje wiele typów, aby usunąć duplikację kodu. Zanim zagłębimy się w składnię generyków, najpierw przyjrzyjmy się, jak usunąć duplikację w sposób, który nie obejmuje typów generycznych, poprzez wyodrębnienie funkcji, która zastępuje konkretne wartości przez placeholder reprezentujący wiele wartości. Następnie zastosujemy tę samą technikę do wyodrębnienia funkcji generycznej! Patrząc na to, jak rozpoznać zduplikowany kod, który można wyodrębnić do funkcji, zaczniesz rozpoznawać zduplikowany kod, który może używać generyków.
Zaczniemy od krótkiego programu w Listing 10-1, który znajduje największą liczbę na liście.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("Największa liczba to {largest}");
assert_eq!(*largest, 100);
}Przechowujemy listę liczb całkowitych w zmiennej number_list i umieszczamy referencję do pierwszej liczby na liście w zmiennej o nazwie largest. Następnie iterujemy po wszystkich liczbach na liście, a jeśli bieżąca liczba jest większa niż liczba przechowywana w largest, zastępujemy referencję w tej zmiennej. Jednakże, jeśli bieżąca liczba jest mniejsza lub równa największej liczbie widzianej do tej pory, zmienna nie zmienia się, a kod przechodzi do następnej liczby na liście. Po rozważeniu wszystkich liczb na liście, largest powinien odnosić się do największej liczby, która w tym przypadku wynosi 100.
Teraz postawiono nam zadanie znalezienia największej liczby na dwóch różnych listach liczb. Aby to zrobić, możemy zdecydować się na zduplikowanie kodu z Listing 10-1 i użycie tej samej logiki w dwóch różnych miejscach w programie, jak pokazano w Listing 10-2.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("Największa liczba to {largest}");
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("Największa liczba to {largest}");
}Chociaż ten kod działa, duplikowanie kodu jest uciążliwe i podatne na błędy. Musimy również pamiętać o aktualizowaniu kodu w wielu miejscach, gdy chcemy go zmienić.
Aby wyeliminować tę duplikację, stworzymy abstrakcję, definiując funkcję, która operuje na dowolnej liście liczb całkowitych przekazanej jako parametr. To rozwiązanie czyni nasz kod jaśniejszym i pozwala nam abstrakcyjnie wyrazić koncepcję znajdowania największej liczby na liście.
W Listing 10-3 wyodrębniamy kod, który znajduje największą liczbę, do funkcji o nazwie largest. Następnie wywołujemy funkcję, aby znaleźć największą liczbę na dwóch listach z Listing 10-2. Moglibyśmy również użyć tej funkcji na dowolnej innej liście wartości i32, które moglibyśmy mieć w przyszłości.
fn largest(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("Największa liczba to {result}");
assert_eq!(*result, 100);
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let result = largest(&number_list);
println!("Największa liczba to {result}");
assert_eq!(*result, 6000);
}Funkcja largest ma parametr list, który reprezentuje dowolny konkretny wycinek wartości i32, który możemy przekazać do funkcji. W rezultacie, gdy wywołujemy funkcję, kod działa na konkretnych wartościach, które przekazujemy.
Podsumowując, oto kroki, które podjęliśmy, aby zmienić kod z Listing 10-2 na Listing 10-3:
- Zidentyfikuj zduplikowany kod.
- Wyodrębnij zduplikowany kod do ciała funkcji i określ wejścia i wartości zwracane tego kodu w sygnaturze funkcji.
- Zaktualizuj dwa wystąpienia zduplikowanego kodu, aby zamiast tego wywoływały funkcję.
Następnie użyjemy tych samych kroków z generykami, aby zmniejszyć duplikację kodu. W ten sam sposób, w jaki ciało funkcji może działać na abstrakcyjnej liście zamiast na konkretnych wartościach, generyki pozwalają kodowi działać na abstrakcyjnych typach.
Na przykład, powiedzmy, że mieliśmy dwie funkcje: jedną, która znajduje największy element w wycinku wartości i32, i drugą, która znajduje największy element w wycinku wartości char. Jak wyeliminowalibyśmy tę duplikację? Dowiedzmy się!
Generyczne typy danych
Generyczne typy danych
Używamy generyków do tworzenia definicji dla elementów, takich jak sygnatury funkcji lub struktury, które możemy następnie wykorzystać z wieloma różnymi konkretnymi typami danych. Najpierw przyjrzymy się, jak definiować funkcje, struktury, wyliczenia i metody za pomocą generyków. Następnie omówimy, jak generyki wpływają na wydajność kodu.
W definicjach funkcji
Podczas definiowania funkcji używającej generyków, umieszczamy generyki w sygnaturze funkcji, tam gdzie zazwyczaj określamy typy danych parametrów i wartość zwracaną. Dzięki temu nasz kod jest bardziej elastyczny i zapewnia większą funkcjonalność wywołującym naszą funkcję, jednocześnie zapobiegając duplikacji kodu.
Kontynuując naszą funkcję largest, Listing 10-4 pokazuje dwie funkcje, które obie znajdują największą wartość w wycinku. Następnie połączymy je w jedną funkcję, która używa generyków.
fn largest_i32(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> &char {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("Największa liczba to {result}");
assert_eq!(*result, 100);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("Największy znak to {result}");
assert_eq!(*result, 'y');
}Funkcja largest_i32 jest tą, którą wyodrębniliśmy w Listing 10-3, która znajduje największą i32 w wycinku. Funkcja largest_char znajduje największy char w wycinku. Ciała funkcji mają ten sam kod, więc wyeliminujmy duplikację, wprowadzając generyczny parametr typu w jednej funkcji.
Aby sparametryzować typy w nowej pojedynczej funkcji, musimy nadać nazwę parametrowi typu, tak jak to robimy dla parametrów wartości funkcji. Możesz użyć dowolnego identyfikatora jako nazwy parametru typu. My jednak użyjemy T, ponieważ, zgodnie z konwencją, nazwy parametrów typu w Rust są krótkie, często składają się tylko z jednej litery, a konwencja nazewnictwa typów w Rust to UpperCamelCase. T (skrót od type) jest domyślnym wyborem większości programistów Rusta.
Kiedy używamy parametru w ciele funkcji, musimy zadeklarować nazwę parametru w sygnaturze, aby kompilator wiedział, co ta nazwa oznacza. Podobnie, kiedy używamy nazwy parametru typu w sygnaturze funkcji, musimy zadeklarować nazwę parametru typu, zanim jej użyjemy. Aby zdefiniować generyczną funkcję largest, umieszczamy deklaracje nazw typów w nawiasach ostrych, <>, między nazwą funkcji a listą parametrów, tak:
fn largest<T>(list: &[T]) -> &T {Tę definicję czytamy jako „funkcja largest jest generyczna względem jakiegoś typu T”. Ta funkcja ma jeden parametr o nazwie list, który jest wycinkiem wartości typu T. Funkcja largest zwróci referencję do wartości tego samego typu T.
Listing 10-5 pokazuje połączoną definicję funkcji largest używającą generycznego typu danych w swojej sygnaturze. Listing pokazuje również, jak możemy wywołać funkcję z wycinkiem wartości i32 lub char. Zauważ, że ten kod jeszcze się nie skompiluje.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("Największa liczba to {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("Największy znak to {result}");
}Jeśli skompilujemy ten kod teraz, otrzymamy następujący błąd:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Tekst pomocy wspomina o std::cmp::PartialOrd, który jest cechą (trait), a o cechach będziemy mówić w następnej sekcji. Na razie wiedz, że ten błąd oznacza, że ciało funkcji largest nie zadziała dla wszystkich możliwych typów, którymi mogłoby być T. Ponieważ chcemy porównywać wartości typu T w ciele funkcji, możemy używać tylko typów, których wartości można uporządkować. Aby umożliwić porównania, standardowa biblioteka posiada cechę std::cmp::PartialOrd, którą można zaimplementować na typach (więcej na temat tej cechy znajdziesz w Dodatku C). Aby naprawić Listing 10-5, możemy zastosować się do sugestii tekstu pomocy i ograniczyć typy dozwolone dla T tylko do tych, które implementują PartialOrd. Listing następnie się skompiluje, ponieważ standardowa biblioteka implementuje PartialOrd zarówno dla i32, jak i char.
W definicjach struktur
Możemy również definiować struktury, aby używały generycznego parametru typu w jednym lub więcej polach, używając składni <>. Listing 10-6 definiuje strukturę Point<T> do przechowywania wartości współrzędnych x i y dowolnego typu.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}Składnia używania generyków w definicjach struktur jest podobna do tej używanej w definicjach funkcji. Najpierw deklarujemy nazwę parametru typu w nawiasach ostrych tuż po nazwie struktury. Następnie używamy typu generycznego w definicji struktury tam, gdzie w przeciwnym razie określilibyśmy konkretne typy danych.
Zauważ, że ponieważ użyliśmy tylko jednego typu generycznego do zdefiniowania Point<T>, ta definicja mówi, że struktura Point<T> jest generyczna względem jakiegoś typu T, a pola x i y są obydwa tego samego typu, niezależnie od tego, jaki to typ. Jeśli stworzymy instancję Point<T>, która ma wartości różnych typów, jak w Listing 10-7, nasz kod się nie skompiluje.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}W tym przykładzie, gdy przypisujemy wartość całkowitą 5 do x, informujemy kompilator, że generyczny typ T będzie liczbą całkowitą dla tej instancji Point<T>. Następnie, gdy określamy 4.0 dla y, które zdefiniowaliśmy jako mające ten sam typ co x, otrzymamy błąd niezgodności typów, taki jak ten:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Aby zdefiniować strukturę Point, w której x i y są obydwa generyczne, ale mogą mieć różne typy, możemy użyć wielu generycznych parametrów typu. Na przykład, w Listing 10-8 zmieniamy definicję Point tak, aby była generyczna względem typów T i U, gdzie x jest typu T, a y jest typu U.
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}Teraz wszystkie pokazane instancje Point są dozwolone! Możesz używać tylu generycznych parametrów typu w definicji, ile chcesz, ale używanie więcej niż kilku utrudnia czytanie kodu. Jeśli okaże się, że potrzebujesz wielu typów generycznych w swoim kodzie, może to wskazywać na potrzebę restrukturyzacji kodu na mniejsze części.
W definicjach wyliczeń
Podobnie jak w przypadku struktur, możemy definiować wyliczenia, aby zawierały generyczne typy danych w swoich wariantach. Przyjrzyjmy się ponownie wyliczeniu Option<T> dostarczanemu przez standardową bibliotekę, którego użyliśmy w Rozdziale 6:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Ta definicja powinna być teraz bardziej zrozumiała. Jak widać, enum Option<T> jest generyczny względem typu T i ma dwa warianty: Some, który przechowuje jedną wartość typu T, oraz wariant None, który nie przechowuje żadnej wartości. Używając enum Option<T>, możemy wyrazić abstrakcyjną koncepcję wartości opcjonalnej, a ponieważ Option<T> jest generyczny, możemy używać tej abstrakcji niezależnie od typu wartości opcjonalnej.
Wyliczenia mogą również używać wielu typów generycznych. Definicja wyliczenia Result, którego użyliśmy w Rozdziale 9, jest jednym z przykładów:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}Enum Result jest generyczny względem dwóch typów, T i E, i ma dwa warianty: Ok, który przechowuje wartość typu T, oraz Err, który przechowuje wartość typu E. Ta definicja sprawia, że wygodnie jest używać enum Result wszędzie tam, gdzie mamy operację, która może zakończyć się sukcesem (zwrócić wartość jakiegoś typu T) lub niepowodzeniem (zwrócić błąd jakiegoś typu E). W rzeczywistości, tego właśnie użyliśmy do otwarcia pliku w Listing 9-3, gdzie T zostało wypełnione typem std::fs::File, gdy plik został pomyślnie otwarty, a E zostało wypełnione typem std::io::Error, gdy wystąpiły problemy z otwarciem pliku.
Kiedy rozpoznajesz sytuacje w swoim kodzie z wieloma definicjami struktur lub wyliczeń, które różnią się tylko typami przechowywanych wartości, możesz uniknąć duplikacji, używając zamiast tego typów generycznych.
W definicjach metod
Możemy implementować metody na strukturach i wyliczeniach (jak to zrobiliśmy w Rozdziale 5) i używać generycznych typów również w ich definicjach. Listing 10-9 pokazuje strukturę Point<T>, którą zdefiniowaliśmy w Listing 10-6 z zaimplementowaną na niej metodą o nazwie x.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}Tutaj zdefiniowaliśmy metodę o nazwie x na Point<T>, która zwraca referencję do danych w polu x.
Zauważ, że musimy zadeklarować T tuż po impl, abyśmy mogli użyć T do określenia, że implementujemy metody na typie Point<T>. Deklarując T jako typ generyczny po impl, Rust może zidentyfikować, że typ w nawiasach ostrych w Point jest typem generycznym, a nie typem konkretnym. Moglibyśmy wybrać inną nazwę dla tego parametru generycznego niż parametr generyczny zadeklarowany w definicji struktury, ale używanie tej samej nazwy jest konwencjonalne. Jeśli napiszesz metodę w impl, która deklaruje typ generyczny, ta metoda zostanie zdefiniowana dla każdej instancji typu, niezależnie od tego, jaki konkretny typ ostatecznie zastąpi typ generyczny.
Możemy również określać ograniczenia dla typów generycznych podczas definiowania metod na tym typie. Moglibyśmy, na przykład, zaimplementować metody tylko na instancjach Point<f32> zamiast na instancjach Point<T> z dowolnym typem generycznym. W Listing 10-10 używamy konkretnego typu f32, co oznacza, że nie deklarujemy żadnych typów po impl.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}Ten kod oznacza, że typ Point<f32> będzie miał metodę distance_from_origin; inne instancje Point<T>, gdzie T nie jest typu f32, nie będą miały tej metody zdefiniowanej. Metoda mierzy, jak daleko nasz punkt znajduje się od punktu o współrzędnych (0.0, 0.0) i używa operacji matematycznych, które są dostępne tylko dla typów zmiennoprzecinkowych.
Generyczne parametry typu w definicji struktury nie zawsze są takie same, jak te, których używasz w sygnaturach metod tej samej struktury. Listing 10-11 używa generycznych typów X1 i Y1 dla struktury Point oraz X2 i Y2 dla sygnatury metody mixup, aby przykład był jaśniejszy. Metoda tworzy nową instancję Point z wartością x z self Point (typu X1) i wartością y z przekazanego Point (typu Y2).
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Witaj", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}W funkcji main zdefiniowaliśmy Point, który ma i32 dla x (o wartości 5) i f64 dla y (o wartości 10.4). Zmienna p2 to struktura Point, która ma wycinek ciągu znaków dla x (o wartości "Witaj") i char dla y (o wartości c). Wywołanie mixup na p1 z argumentem p2 daje nam p3, który będzie miał i32 dla x, ponieważ x pochodzi z p1. Zmienna p3 będzie miała char dla y, ponieważ y pochodzi z p2. Wywołanie makra println! wydrukuje p3.x = 5, p3.y = c.
Celem tego przykładu jest zademonstrowanie sytuacji, w której niektóre parametry generyczne są zadeklarowane za pomocą impl, a niektóre za pomocą definicji metody. Tutaj parametry generyczne X1 i Y1 są zadeklarowane po impl, ponieważ pasują do definicji struktury. Parametry generyczne X2 i Y2 są zadeklarowane po fn mixup, ponieważ są istotne tylko dla metody.
Wydajność kodu używającego generyków
Możesz zastanawiać się, czy istnieje koszt czasu wykonania przy używaniu generycznych parametrów typu. Dobra wiadomość jest taka, że używanie typów generycznych nie spowolni programu bardziej niż użycie konkretnych typów.
Rust osiąga to, wykonując monomorfizację kodu używającego generyków w czasie kompilacji. Monomorfizacja to proces przekształcania kodu generycznego w kod specyficzny poprzez wypełnienie konkretnych typów używanych podczas kompilacji. W tym procesie kompilator wykonuje przeciwieństwo kroków, których użyliśmy do utworzenia funkcji generycznej w Listing 10-5: kompilator przegląda wszystkie miejsca, w których wywoływany jest kod generyczny, i generuje kod dla konkretnych typów, z którymi wywoływany jest kod generyczny.
Przyjrzyjmy się, jak to działa, używając generycznego enum Option<T> ze standardowej biblioteki:
#![allow(unused)]
fn main() {
let integer = Some(5);
let float = Some(5.0);
}Kiedy Rust kompiluje ten kod, wykonuje monomorfizację. Podczas tego procesu kompilator odczytuje wartości, które zostały użyte w instancjach Option<T>, i identyfikuje dwa rodzaje Option<T>: jeden to i32, a drugi to f64. W związku z tym rozszerza generyczną definicję Option<T> na dwie definicje wyspecjalizowane dla i32 i f64, zastępując w ten sposób generyczną definicję specyficznymi.
Monomorfizowana wersja kodu wygląda podobnie do następującej (kompilator używa innych nazw niż te, których używamy tutaj dla ilustracji):
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}Generyczny Option<T> jest zastępowany przez specyficzne definicje utworzone przez kompilator. Ponieważ Rust kompiluje kod generyczny do kodu, który określa typ w każdej instancji, nie ponosimy kosztów wykonania za używanie generyków. Gdy kod działa, zachowuje się tak samo, jakbyśmy ręcznie zduplikowali każdą definicję. Proces monomorfizacji sprawia, że generyki Rusta są niezwykle wydajne w czasie wykonywania.
Definiowanie wspólnego zachowania za pomocą cech
Definiowanie wspólnego zachowania za pomocą cech
Cecha (trait) definiuje funkcjonalność, którą posiada dany typ i którą może dzielić z innymi typami. Możemy używać cech do definiowania wspólnego zachowania w sposób abstrakcyjny. Możemy używać ograniczeń cech (trait bounds) do określania, że typ generyczny może być dowolnym typem, który ma określone zachowanie.
Uwaga: Cechy są podobne do funkcji często nazywanych interfejsami w innych językach, choć z pewnymi różnicami.
Definiowanie cechy
Zachowanie typu składa się z metod, które możemy wywołać dla tego typu. Różne typy dzielą to samo zachowanie, jeśli możemy wywołać te same metody dla wszystkich tych typów. Definicje cech to sposób grupowania sygnatur metod w celu zdefiniowania zestawu zachowań niezbędnych do osiągnięcia pewnego celu.
Na przykład, powiedzmy, że mamy wiele struktur, które przechowują różne rodzaje i ilości tekstu: struktura NewsArticle, która przechowuje artykuł informacyjny z określonej lokalizacji, i SocialPost, która może mieć co najwyżej 280 znaków wraz z metadanymi wskazującymi, czy był to nowy post, repost, czy odpowiedź na inny post.
Chcemy stworzyć skrzynkę biblioteczną agregującą media o nazwie aggregator, która będzie mogła wyświetlać podsumowania danych przechowywanych w instancji NewsArticle lub SocialPost. Aby to zrobić, potrzebujemy podsumowania z każdego typu, a to podsumowanie uzyskamy, wywołując metodę summarize na instancji. Listing 10-12 pokazuje definicję publicznej cechy Summary, która wyraża to zachowanie.
pub trait Summary {
fn summarize(&self) -> String;
}Tutaj deklarujemy cechę za pomocą słowa kluczowego trait, a następnie nazwę cechy, która w tym przypadku to Summary. Deklarujemy również cechę jako pub, aby skrzynki zależne od tej skrzynki mogły również korzystać z tej cechy, jak zobaczymy w kilku przykładach. W nawiasach klamrowych deklarujemy sygnatury metod, które opisują zachowania typów implementujących tę cechę, co w tym przypadku jest fn summarize(&self) -> String.
Po sygnaturze metody, zamiast dostarczać implementacji w nawiasach klamrowych, używamy średnika. Każdy typ implementujący tę cechę musi dostarczyć własne, niestandardowe zachowanie dla ciała metody. Kompilator wymusi, aby każdy typ posiadający cechę Summary miał metodę summarize zdefiniowaną dokładnie z tą sygnaturą.
Cecha może mieć wiele metod w swoim ciele: sygnatury metod są wymienione jedna na linię, a każda linia kończy się średnikiem.
Implementowanie cechy na typie
Teraz, gdy zdefiniowaliśmy pożądane sygnatury metod cechy Summary, możemy zaimplementować ją na typach w naszym agregatorze mediów. Listing 10-13 pokazuje implementację cechy Summary na strukturze NewsArticle, która używa nagłówka, autora i lokalizacji do utworzenia wartości zwracanej przez summarize. Dla struktury SocialPost definiujemy summarize jako nazwę użytkownika, a następnie cały tekst posta, zakładając, że zawartość posta jest już ograniczona do 280 znaków.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Implementowanie cechy na typie jest podobne do implementowania zwykłych metod. Różnica polega na tym, że po impl umieszczamy nazwę cechy, którą chcemy zaimplementować, następnie używamy słowa kluczowego for, a następnie określamy nazwę typu, dla którego chcemy zaimplementować cechę. W bloku impl umieszczamy sygnatury metod, które zdefiniowano w definicji cechy. Zamiast dodawać średnik po każdej sygnaturze, używamy nawiasów klamrowych i wypełniamy ciało metody konkretnym zachowaniem, które chcemy, aby metody cechy miały dla danego typu.
Teraz, gdy biblioteka zaimplementowała cechę Summary dla NewsArticle i SocialPost, użytkownicy skrzynki mogą wywoływać metody cech na instancjach NewsArticle i SocialPost w taki sam sposób, jak wywołujemy zwykłe metody. Jedyną różnicą jest to, że użytkownik musi wprowadzić cechę do zasięgu, a także typy. Oto przykład, jak skrzynka binarna mogłaby użyć naszej skrzynki bibliotecznej aggregator:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"oczywiście, jak zapewne już wiesz, ludzie",
),
reply: false,
repost: false,
};
println!("1 nowy post: {}", post.summarize());
}Ten kod drukuje 1 nowy post: horse_ebooks: oczywiście, jak zapewne już wiesz, ludzie.
Inne skrzynki zależne od skrzynki aggregator mogą również wprowadzić cechę Summary do zasięgu, aby zaimplementować Summary na swoich własnych typach. Jednym z ograniczeń jest to, że możemy zaimplementować cechę na typie tylko wtedy, gdy cecha lub typ, albo oba, są lokalne dla naszej skrzynki. Na przykład, możemy zaimplementować cechy standardowej biblioteki, takie jak Display, na niestandardowym typie, takim jak SocialPost, jako część funkcjonalności naszej skrzynki aggregator, ponieważ typ SocialPost jest lokalny dla naszej skrzynki aggregator. Możemy również zaimplementować Summary na Vec<T> w naszej skrzynce aggregator, ponieważ cecha Summary jest lokalna dla naszej skrzynki aggregator.
Ale nie możemy implementować zewnętrznych cech na zewnętrznych typach. Na przykład, nie możemy implementować cechy Display na Vec<T> w naszej skrzynce aggregator, ponieważ Display i Vec<T> są zdefiniowane w standardowej bibliotece i nie są lokalne dla naszej skrzynki aggregator. To ograniczenie jest częścią właściwości zwanej spójnością, a dokładniej zasadą sieroty (orphan rule), nazwaną tak, ponieważ typ nadrzędny nie jest obecny. Ta zasada zapewnia, że kod innych ludzi nie może zepsuć twojego kodu i vice versa. Bez tej zasady, dwie skrzynki mogłyby zaimplementować tę samą cechę dla tego samego typu, a Rust nie wiedziałby, której implementacji użyć.
Używanie domyślnych implementacji
Czasami przydatne jest posiadanie domyślnego zachowania dla niektórych lub wszystkich metod w cesze, zamiast wymagać implementacji dla wszystkich metod na każdym typie. Następnie, implementując cechę na konkretnym typie, możemy zachować lub nadpisać domyślne zachowanie każdej metody.
W Listing 10-14 określamy domyślny ciąg znaków dla metody summarize cechy Summary, zamiast definiować tylko sygnaturę metody, jak to zrobiliśmy w Listing 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Czytaj więcej...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Aby użyć domyślnej implementacji do podsumowywania instancji NewsArticle, określamy pusty blok impl za pomocą impl Summary for NewsArticle {}.
Chociaż nie definiujemy już bezpośrednio metody summarize w NewsArticle, dostarczyliśmy domyślną implementację i określiliśmy, że NewsArticle implementuje cechę Summary. W rezultacie nadal możemy wywołać metodę summarize na instancji NewsArticle, tak jak poniżej:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Pingwiny wygrywają Puchar Stanleya!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"Pittsburgh Penguins po raz kolejny są najlepszą \
drużyną hokejową w NHL.",
),
};
println!("Nowy artykuł dostępny! {}", article.summarize());
}Ten kod drukuje Nowy artykuł dostępny! (Czytaj więcej...).
Stworzenie domyślnej implementacji nie wymaga od nas zmiany czegokolwiek w implementacji Summary na SocialPost w Listing 10-13. Powodem jest to, że składnia nadpisywania domyślnej implementacji jest taka sama jak składnia implementacji metody cechy, która nie ma domyślnej implementacji.
Domyślne implementacje mogą wywoływać inne metody w tej samej cesze, nawet jeśli te inne metody nie mają domyślnej implementacji. W ten sposób cecha może dostarczyć wiele użytecznej funkcjonalności i wymagać od implementatorów jedynie określenia jej małej części. Na przykład, moglibyśmy zdefiniować cechę Summary tak, aby miała metodę summarize_author, której implementacja jest wymagana, a następnie zdefiniować metodę summarize, która ma domyślną implementację, która wywołuje metodę summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Czytaj więcej od {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Aby użyć tej wersji Summary, wystarczy zdefiniować summarize_author podczas implementacji cechy na typie:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Czytaj więcej od {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Po zdefiniowaniu summarize_author możemy wywołać summarize na instancjach struktury SocialPost, a domyślna implementacja summarize wywoła zdefiniowaną przez nas summarize_author. Ponieważ zaimplementowaliśmy summarize_author, cecha Summary dała nam zachowanie metody summarize bez konieczności pisania dodatkowego kodu. Oto jak to wygląda:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"oczywiście, jak zapewne już wiesz, ludzie",
),
reply: false,
repost: false,
};
println!("1 nowy post: {}", post.summarize());
}Ten kod drukuje 1 nowy post: (Czytaj więcej od @horse_ebooks...).
Zauważ, że nie jest możliwe wywołanie domyślnej implementacji z nadpisującej implementacji tej samej metody.
Używanie cech jako parametrów
Teraz, gdy wiesz, jak definiować i implementować cechy, możemy zbadać, jak używać cech do definiowania funkcji, które akceptują wiele różnych typów. Użyjemy cechy Summary, którą zaimplementowaliśmy na typach NewsArticle i SocialPost w Listing 10-13, aby zdefiniować funkcję notify, która wywołuje metodę summarize na swoim parametrze item, który jest jakiegoś typu implementującego cechę Summary. Aby to zrobić, używamy składni impl Trait, tak jak poniżej:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Najświeższe wiadomości! {}", item.summarize());
}Zamiast konkretnego typu dla parametru item, określamy słowo kluczowe impl i nazwę cechy. Ten parametr akceptuje dowolny typ, który implementuje określoną cechę. W ciele notify możemy wywołać dowolne metody na item, które pochodzą z cechy Summary, takie jak summarize. Możemy wywołać notify i przekazać dowolną instancję NewsArticle lub SocialPost. Kod, który wywołuje funkcję z dowolnym innym typem, takim jak String lub i32, nie skompiluje się, ponieważ te typy nie implementują Summary.
Składnia ograniczeń cech
Składnia impl Trait działa w prostych przypadkach, ale w rzeczywistości jest to cukier syntaktyczny dla dłuższej formy znanej jako ograniczenie cechy (trait bound); wygląda to tak:
pub fn notify<T: Summary>(item: &T) {
println!("Najświeższe wiadomości! {}", item.summarize());
}Ta dłuższa forma jest równoważna przykładowi z poprzedniej sekcji, ale jest bardziej rozwlekła. Ograniczenia cech umieszczamy wraz z deklaracją generycznego parametru typu po dwukropku i w nawiasach ostrych.
Składnia impl Trait jest wygodna i sprawia, że kod jest bardziej zwięzły w prostych przypadkach, podczas gdy pełniejsza składnia ograniczeń cech może wyrażać większą złożoność w innych przypadkach. Na przykład, możemy mieć dwa parametry, które implementują Summary. Użycie składni impl Trait wygląda tak:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Użycie impl Trait jest odpowiednie, jeśli chcemy, aby ta funkcja pozwalała item1 i item2 na posiadanie różnych typów (o ile oba typy implementują Summary). Jeśli jednak chcemy wymusić, aby oba parametry miały ten sam typ, musimy użyć ograniczenia cechy, tak jak poniżej:
pub fn notify<T: Summary>(item1: &T, item2: &T) {Generyczny typ T określony jako typ parametrów item1 i item2 ogranicza funkcję tak, że konkretny typ wartości przekazanej jako argument dla item1 i item2 musi być taki sam.
Wiele ograniczeń cech za pomocą składni +
Możemy również określić więcej niż jedno ograniczenie cechy. Powiedzmy, że chcieliśmy, aby notify używało formatowania wyświetlania, a także summarize na item: określamy w definicji notify, że item musi implementować zarówno Display, jak i Summary. Możemy to zrobić za pomocą składni +:
pub fn notify(item: &(impl Summary + Display)) {Składnia + jest również prawidłowa z ograniczeniami cech na typach generycznych:
pub fn notify<T: Summary + Display>(item: &T) {Dzięki dwóm określonym ograniczeniom cech, ciało notify może wywoływać summarize i używać {} do formatowania item.
Jaśniejsze ograniczenia cech za pomocą klauzul where
Zbyt wiele ograniczeń cech ma swoje wady. Każdy typ generyczny ma swoje własne ograniczenia cech, więc funkcje z wieloma generycznymi parametrami typu mogą zawierać wiele informacji o ograniczeniach cech między nazwą funkcji a listą jej parametrów, co utrudnia czytanie sygnatury funkcji. Z tego powodu Rust ma alternatywną składnię do określania ograniczeń cech w klauzuli where po sygnaturze funkcji. Tak więc, zamiast pisać tak:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {możemy użyć klauzuli where, tak jak poniżej:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Sygnatura tej funkcji jest mniej zaśmiecona: nazwa funkcji, lista parametrów i typ zwracany są blisko siebie, podobnie jak w funkcji bez wielu ograniczeń cech.
Zwracanie typów, które implementują cechy
Możemy również użyć składni impl Trait w pozycji zwracanej, aby zwrócić wartość jakiegoś typu, który implementuje cechę, jak pokazano tutaj:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"oczywiście, jak zapewne już wiesz, ludzie",
),
reply: false,
repost: false,
}
}Używając impl Summary jako typu zwracanego, określamy, że funkcja returns_summarizable zwraca pewien typ, który implementuje cechę Summary, bez nazywania konkretnego typu. W tym przypadku returns_summarizable zwraca SocialPost, ale kod wywołujący tę funkcję nie musi o tym wiedzieć.
Możliwość określenia typu zwracanego tylko przez cechę, którą implementuje, jest szczególnie przydatna w kontekście domknięć i iteratorów, które omówimy w Rozdziale 13. Domknięcia i iteratory tworzą typy, które zna tylko kompilator, lub typy, które są bardzo długie do określenia. Składnia impl Trait pozwala zwięźle określić, że funkcja zwraca jakiś typ, który implementuje cechę Iterator, bez konieczności wypisywania bardzo długiego typu.
Możesz jednak używać impl Trait tylko wtedy, gdy zwracasz pojedynczy typ. Na przykład, ten kod, który zwraca NewsArticle lub SocialPost z typem zwracanym określonym jako impl Summary, nie zadziała:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Pingwiny wygrywają Puchar Stanleya!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"Pittsburgh Penguins po raz kolejny są najlepszą \
drużyną hokejową w NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"oczywiście, jak zapewne już wiesz, ludzie",
),
reply: false,
repost: false,
}
}
}Zwracanie NewsArticle lub SocialPost nie jest dozwolone z powodu ograniczeń związanych z implementacją składni impl Trait w kompilatorze. Omówimy, jak napisać funkcję o takim zachowaniu w sekcji „Używanie obiektów cech do abstrakcji wspólnego zachowania” w Rozdziale 18.
Używanie ograniczeń cech do warunkowej implementacji metod
Używając ograniczenia cechy z blokiem impl, który używa generycznych parametrów typu, możemy warunkowo implementować metody dla typów, które implementują określone cechy. Na przykład, typ Pair<T> w Listing 10-15 zawsze implementuje funkcję new, aby zwrócić nową instancję Pair<T> (przypomnij sobie z sekcji „Składnia metody” w Rozdziale 5, że Self jest aliasem typu dla typu bloku impl, który w tym przypadku to Pair<T>). Ale w następnym bloku impl, Pair<T> implementuje metodę cmp_display tylko wtedy, gdy jej wewnętrzny typ T implementuje cechę PartialOrd, która umożliwia porównanie i cechę Display, która umożliwia drukowanie.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("Największy element to x = {}", self.x);
} else {
println!("Największy element to y = {}", self.y);
}
}
}Możemy również warunkowo implementować cechę dla dowolnego typu, który implementuje inną cechę. Implementacje cechy na dowolnym typie, który spełnia ograniczenia cechy, nazywane są implementacjami ogólnymi (blanket implementations) i są szeroko stosowane w standardowej bibliotece Rusta. Na przykład, standardowa biblioteka implementuje cechę ToString dla każdego typu, który implementuje cechę Display. Blok impl w standardowej bibliotece wygląda podobnie do tego kodu:
impl<T: Display> ToString for T {
// --snip--
}Ponieważ standardowa biblioteka ma tę ogólną implementację, możemy wywołać metodę to_string zdefiniowaną przez cechę ToString na dowolnym typie, który implementuje cechę Display. Na przykład, możemy zamienić liczby całkowite na odpowiadające im wartości String w ten sposób, ponieważ liczby całkowite implementują Display:
#![allow(unused)]
fn main() {
let s = 3.to_string();
}Implementacje ogólne pojawiają się w dokumentacji cechy w sekcji „Implementacje”.
Cechy i ograniczenia cech pozwalają nam pisać kod, który używa generycznych parametrów typu, aby zmniejszyć duplikację, ale także określać kompilatorowi, że chcemy, aby generyczny typ miał określone zachowanie. Kompilator może następnie użyć informacji o ograniczeniach cech, aby sprawdzić, czy wszystkie konkretne typy używane z naszym kodem zapewniają prawidłowe zachowanie. W językach z dynamicznym typowaniem otrzymalibyśmy błąd w czasie wykonywania, gdybyśmy wywołali metodę na typie, który nie definiuje tej metody. Ale Rust przenosi te błędy do czasu kompilacji, tak abyśmy byli zmuszeni do naprawienia problemów, zanim nasz kod w ogóle będzie mógł działać. Dodatkowo, nie musimy pisać kodu, który sprawdza zachowanie w czasie wykonywania, ponieważ sprawdziliśmy to już w czasie kompilacji. Robienie tego poprawia wydajność bez konieczności rezygnacji z elastyczności generyków.
Walidacja referencji za pomocą czasów życia
Walidacja referencji za pomocą czasów życia
Czasy życia to kolejny rodzaj generyków, których już używaliśmy. Zamiast zapewniać, że typ ma pożądane przez nas zachowanie, czasy życia zapewniają, że referencje są ważne tak długo, jak tego potrzebujemy.
Jednym szczegółem, o którym nie rozmawialiśmy w sekcji „Referencje i pożyczanie” w Rozdziale 4, jest to, że każda referencja w Rust ma czas życia, który jest zasięgiem, w którym ta referencja jest ważna. Przez większość czasu, czasy życia są domyślne i wnioskowane, tak jak przez większość czasu, typy są wnioskowane. Jesteśmy zobowiązani do adnotowania typów tylko wtedy, gdy możliwych jest wiele typów. W podobny sposób musimy adnotować czasy życia, gdy czasy życia referencji mogą być powiązane na kilka różnych sposobów. Rust wymaga od nas adnotowania relacji za pomocą ogólnych parametrów czasów życia, aby zapewnić, że rzeczywiste referencje używane w czasie wykonania będą z pewnością ważne.
Adnotowanie czasów życia nie jest nawet koncepcją, którą posiada większość innych języków programowania, więc będzie to wydawać się nieznane. Chociaż w tym rozdziale nie omówimy czasów życia w całości, to jednak przedstawimy typowe sposoby, w jakie można napotkać składnię czasów życia, aby można było się z nią oswoić.
Wiszące referencje
Głównym celem czasów życia jest zapobieganie wiszącym referencjom, które, gdyby były dozwolone, spowodowałyby, że program odnosiłby się do danych innych niż te, do których miał się odnosić. Rozważ program z Listingu 10-16, który ma zasięg zewnętrzny i zasięg wewnętrzny.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Uwaga: Przykłady z Listingów 10-16, 10-17 i 10-23 deklarują zmienne bez nadawania im wartości początkowej, więc nazwa zmiennej istnieje w zasięgu zewnętrznym. Na pierwszy rzut oka może to wydawać się sprzeczne z tym, że Rust nie ma wartości null. Jednakże, jeśli spróbujemy użyć zmiennej przed nadaniem jej wartości, otrzymamy błąd kompilacji, co pokazuje, że Rust faktycznie nie zezwala na wartości null.
Zasięg zewnętrzny deklaruje zmienną r bez wartości początkowej, a zasięg wewnętrzny deklaruje zmienną x z wartością początkową 5. Wewnątrz zasięgu wewnętrznego próbujemy ustawić wartość r jako referencję do x. Następnie zasięg wewnętrzny kończy się, a my próbujemy wypisać wartość r. Ten kod nie skompiluje się, ponieważ wartość, do której odnosi się r, wyszła poza zasięg, zanim spróbowaliśmy jej użyć. Oto komunikat o błędzie:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Komunikat o błędzie mówi, że zmienna x „nie żyje wystarczająco długo”. Powodem jest to, że x wyjdzie poza zasięg, gdy zasięg wewnętrzny zakończy się w wierszu 7. Ale r jest nadal ważne dla zasięgu zewnętrznego; ponieważ jego zasięg jest większy, mówimy, że „żyje dłużej”. Gdyby Rust pozwolił na działanie tego kodu, r odwoływałoby się do pamięci, która została zwolniona, gdy x wyszło poza zasięg, a wszystko, co próbowalibyśmy zrobić z r, nie działałoby poprawnie. Jak więc Rust ustala, że ten kod jest nieprawidłowy? Używa sprawdzacza pożyczeń.
Sprawdzacz pożyczeń
Kompilator Rust posiada sprawdzacz pożyczeń, który porównuje zasięgi, aby określić, czy wszystkie pożyczki są ważne. Listing 10-17 przedstawia ten sam kod co Listing 10-16, ale z adnotacjami pokazującymi czasy życia zmiennych.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+Tutaj oznaczyliśmy czas życia r jako 'a, a czas życia x jako 'b. Jak widać, wewnętrzny blok 'b jest znacznie mniejszy niż zewnętrzny blok czasu życia 'a. W czasie kompilacji Rust porównuje rozmiar tych dwóch czasów życia i widzi, że r ma czas życia 'a, ale odnosi się do pamięci z czasem życia 'b. Program jest odrzucany, ponieważ 'b jest krótsze niż 'a: podmiot referencji nie żyje tak długo, jak sama referencja.
Listing 10-18 naprawia kod, tak aby nie miał wiszącej referencji i kompilował się bez żadnych błędów.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+Tutaj x ma czas życia 'b, który w tym przypadku jest większy niż 'a. Oznacza to, że r może odwoływać się do x, ponieważ Rust wie, że referencja w r zawsze będzie ważna, dopóki x jest ważne.
Teraz, gdy wiesz, gdzie znajdują się czasy życia referencji i jak Rust analizuje czasy życia, aby zapewnić, że referencje zawsze będą ważne, przejdźmy do ogólnych czasów życia w parametrach funkcji i wartościach zwracanych.
Ogólne czasy życia w funkcjach
Napiszemy funkcję, która zwraca dłuższy z dwóch wycinków ciągów znaków. Funkcja ta przyjmie dwa wycinki ciągów znaków i zwróci pojedynczy wycinek ciągu znaków. Po zaimplementowaniu funkcji longest, kod z Listingu 10-19 powinien wypisać The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}Zauważ, że chcemy, aby funkcja przyjmowała wycinki ciągów znaków, które są referencjami, a nie ciągami znaków, ponieważ nie chcemy, aby funkcja longest przejmowała własność swoich parametrów. Więcej informacji na temat tego, dlaczego parametry użyte w Listingu 10-19 są tymi, których chcemy, znajduje się w sekcji „Wycinki ciągów znaków jako parametry” w Rozdziale 4.
Jeśli spróbujemy zaimplementować funkcję longest tak, jak pokazano w Listingu 10-20, nie skompiluje się ona.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}Zamiast tego otrzymujemy następujący błąd, który dotyczy czasów życia:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Tekst pomocy ujawnia, że typ zwracany wymaga parametru ogólnego czasu życia, ponieważ Rust nie może określić, czy zwracana referencja odnosi się do x czy do y. Tak naprawdę my też tego nie wiemy, ponieważ blok if w ciele tej funkcji zwraca referencję do x, a blok else zwraca referencję do y!
Kiedy definiujemy tę funkcję, nie znamy konkretnych wartości, które zostaną do niej przekazane, więc nie wiemy, czy wykona się przypadek if czy else. Nie znamy również konkretnych czasów życia referencji, które zostaną przekazane, więc nie możemy spojrzeć na zasięgi, jak to zrobiliśmy w Listingach 10-17 i 10-18, aby określić, czy zwracana referencja będzie zawsze ważna. Sprawdzacz pożyczeń również nie może tego ustalić, ponieważ nie wie, jak czasy życia x i y odnoszą się do czasu życia wartości zwracanej. Aby naprawić ten błąd, dodamy ogólne parametry czasów życia, które zdefiniują relację między referencjami, aby sprawdzacz pożyczeń mógł przeprowadzić swoją analizę.
Składnia adnotacji czasów życia
Adnotacje czasów życia nie zmieniają długości życia żadnych referencji. Raczej opisują one relacje między czasami życia wielu referencji, nie wpływając na same czasy życia. Tak jak funkcje mogą przyjmować dowolny typ, gdy sygnatura określa ogólny parametr typu, tak samo funkcje mogą przyjmować referencje z dowolnym czasem życia, określając ogólny parametr czasu życia.
Adnotacje czasów życia mają nieco nietypową składnię: nazwy parametrów czasu życia muszą zaczynać się od apostrofu (') i zazwyczaj są małymi literami i bardzo krótkie, podobnie jak typy ogólne. Większość ludzi używa nazwy 'a dla pierwszej adnotacji czasu życia. Adnotacje parametrów czasu życia umieszczamy po & referencji, używając spacji do oddzielenia adnotacji od typu referencji.
Oto kilka przykładów – referencja do i32 bez parametru czasu życia, referencja do i32 z parametrem czasu życia o nazwie 'a, oraz zmienna referencja do i32, która również ma czas życia 'a:
&i32 // referencja
&'a i32 // referencja z jawnym czasem życia
&'a mut i32 // zmienna referencja z jawnym czasem życiaJedna adnotacja czasu życia sama w sobie nie ma większego znaczenia, ponieważ adnotacje mają na celu poinformowanie Rust, jak ogólne parametry czasu życia wielu referencji odnoszą się do siebie. Przyjrzyjmy się, jak adnotacje czasu życia odnoszą się do siebie w kontekście funkcji longest.
W sygnaturach funkcji
Aby używać adnotacji czasów życia w sygnaturach funkcji, musimy zadeklarować ogólne parametry czasów życia w nawiasach kątowych między nazwą funkcji a listą parametrów, tak jak robiliśmy to z ogólnymi parametrami typów.
Chcemy, aby sygnatura wyrażała następujące ograniczenie: zwracana referencja będzie ważna tak długo, jak długo oba parametry są ważne. Jest to relacja między czasami życia parametrów a wartością zwracaną. Nazwiemy czas życia 'a, a następnie dodamy go do każdej referencji, jak pokazano w Listingu 10-21.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Ten kod powinien się skompilować i dać pożądany rezultat, gdy użyjemy go z funkcją main z Listingu 10-19.
Sygnatura funkcji informuje teraz Rust, że dla pewnego czasu życia 'a, funkcja przyjmuje dwa parametry, z których oba są wycinkami ciągów znaków, które żyją co najmniej tak długo, jak czas życia 'a. Sygnatura funkcji informuje również Rust, że wycinek ciągu znaków zwrócony z funkcji będzie żył co najmniej tak długo, jak czas życia 'a. W praktyce oznacza to, że czas życia referencji zwróconej przez funkcję longest jest taki sam, jak krótszy z czasów życia wartości, do których odwołują się argumenty funkcji. Te relacje to to, czego chcemy, aby Rust używał podczas analizy tego kodu.
Pamiętaj, że kiedy określamy parametry czasu życia w sygnaturze tej funkcji, nie zmieniamy czasów życia żadnych wartości przekazanych ani zwracanych. Raczej określamy, że sprawdzacz pożyczeń powinien odrzucić wszelkie wartości, które nie przestrzegają tych ograniczeń. Zauważ, że funkcja longest nie musi dokładnie wiedzieć, jak długo będą żyły x i y, tylko że pewien zasięg może zostać podstawiony za 'a, który spełni tę sygnaturę.
Podczas adnotowania czasów życia w funkcjach, adnotacje umieszcza się w sygnaturze funkcji, a nie w jej ciele. Adnotacje czasów życia stają się częścią kontraktu funkcji, podobnie jak typy w sygnaturze. Posiadanie sygnatur funkcji zawierających kontrakt czasów życia oznacza, że analiza wykonywana przez kompilator Rust może być prostsza. Jeśli wystąpi problem z adnotacją funkcji lub sposobem jej wywołania, błędy kompilatora mogą wskazać precyzyjniej na część naszego kodu i ograniczenia. Gdyby kompilator Rust wyciągał więcej wniosków na temat tego, jakie relacje czasów życia zamierzaliśmy, kompilator mógłby wskazać tylko na użycie naszego kodu wiele kroków od przyczyny problemu.
Kiedy przekazujemy konkretne referencje do longest, konkretny czas życia, który jest podstawiany za 'a, to część zasięgu x, która nakłada się na zasięg y. Innymi słowy, ogólny czas życia 'a przyjmie konkretny czas życia, który jest równy krótszemu z czasów życia x i y. Ponieważ oznaczyliśmy zwracaną referencję tym samym parametrem czasu życia 'a, zwracana referencja będzie również ważna przez czas trwania krótszego z czasów życia x i y.
Przyjrzyjmy się, jak adnotacje czasów życia ograniczają funkcję longest poprzez przekazywanie referencji, które mają różne konkretne czasy życia. Listing 10-22 to prosty przykład.
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {result}");
}
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}W tym przykładzie string1 jest ważne do końca zewnętrznego zasięgu, string2 jest ważne do końca wewnętrznego zasięgu, a result odwołuje się do czegoś, co jest ważne do końca wewnętrznego zasięgu. Uruchom ten kod, a zobaczysz, że sprawdzacz pożyczeń zatwierdza; skompiluje się i wypisze The longest string is long string is long.
Następnie spróbujmy przykładu, który pokazuje, że czas życia referencji w result musi być krótszym czasem życia z dwóch argumentów. Przeniesiemy deklarację zmiennej result poza zasięg wewnętrzny, ale pozostawimy przypisanie wartości do zmiennej result wewnątrz zasięgu z string2. Następnie przeniesiemy println!, które używa result, poza zasięg wewnętrzny, po zakończeniu zasięgu wewnętrznego. Kod z Listingu 10-23 nie skompiluje się.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Kiedy próbujemy skompilować ten kod, otrzymujemy następujący błąd:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Błąd pokazuje, że aby result było ważne dla instrukcji println!, string2 musiałoby być ważne do końca zasięgu zewnętrznego. Rust wie o tym, ponieważ oznaczyliśmy czasy życia parametrów funkcji i wartości zwracanych, używając tego samego parametru czasu życia 'a.
Jako ludzie, możemy spojrzeć na ten kod i zobaczyć, że string1 jest dłuższe niż string2, a zatem result będzie zawierać referencję do string1. Ponieważ string1 nie wyszło jeszcze poza zasięg, referencja do string1 będzie nadal ważna dla instrukcji println!. Jednak kompilator nie widzi, że referencja jest ważna w tym przypadku. Powiedzieliśmy Rust, że czas życia referencji zwróconej przez funkcję longest jest taki sam, jak krótszy z czasów życia referencji przekazanych. Dlatego sprawdzacz pożyczeń nie zezwala na kod z Listingu 10-23, ponieważ może on zawierać nieprawidłową referencję.
Spróbuj zaprojektować więcej eksperymentów, które zmieniają wartości i czasy życia referencji przekazywanych do funkcji longest oraz sposób użycia zwróconej referencji. Postaw hipotezy, czy Twoje eksperymenty przejdą sprawdzacz pożyczeń, zanim skompilujesz; następnie sprawdź, czy masz rację!
Relacje
Sposób, w jaki musisz określić parametry czasu życia, zależy od tego, co robi twoja funkcja. Na przykład, gdybyśmy zmienili implementację funkcji longest tak, aby zawsze zwracała pierwszy parametr zamiast najdłuższego wycinka ciągu znaków, nie musielibyśmy określać czasu życia dla parametru y. Poniższy kod skompiluje się:
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}Określiliśmy parametr czasu życia 'a dla parametru x i typu zwracanego, ale nie dla parametru y, ponieważ czas życia y nie ma żadnego związku z czasem życia x ani wartością zwracaną.
Podczas zwracania referencji z funkcji, parametr czasu życia dla typu zwracanego musi odpowiadać parametrowi czasu życia jednego z parametrów. Jeśli zwracana referencja nie odnosi się do jednego z parametrów, musi odnosić się do wartości utworzonej wewnątrz tej funkcji. Byłaby to jednak wisząca referencja, ponieważ wartość wyjdzie poza zasięg na końcu funkcji. Rozważ tę próbę implementacji funkcji longest, która się nie skompiluje:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Tutaj, mimo że określiliśmy parametr czasu życia 'a dla typu zwracanego, ta implementacja nie skompiluje się, ponieważ czas życia wartości zwracanej nie jest w ogóle powiązany z czasem życia parametrów. Oto komunikat o błędzie, który otrzymujemy:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Problem polega na tym, że result wychodzi poza zasięg i zostaje oczyszczone na końcu funkcji longest. Próbujemy również zwrócić referencję do result z funkcji. Nie ma sposobu, abyśmy mogli określić parametry czasu życia, które zmieniłyby wiszącą referencję, a Rust nie pozwoli nam na utworzenie wiszącej referencji. W tym przypadku najlepszym rozwiązaniem byłoby zwrócenie własnego typu danych zamiast referencji, tak aby funkcja wywołująca była odpowiedzialna za oczyszczenie wartości.
Ostatecznie składnia czasów życia służy do łączenia czasów życia różnych parametrów i wartości zwracanych funkcji. Po ich połączeniu Rust ma wystarczające informacje, aby zezwalać na operacje bezpieczne dla pamięci i odrzucać operacje, które mogłyby stworzyć wiszące wskaźniki lub w inny sposób naruszyć bezpieczeństwo pamięci.
W definicjach struktur
Dotychczasowe struktury, które zdefiniowaliśmy, zawsze przechowywały typy posiadane. Możemy zdefiniować struktury, które przechowują referencje, ale w takim przypadku musielibyśmy dodać adnotację czasu życia do każdej referencji w definicji struktury. Listing 10-24 przedstawia strukturę o nazwie ImportantExcerpt, która przechowuje wycinek ciągu znaków.
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Ta struktura ma jedno pole part, które przechowuje wycinek ciągu znaków, czyli referencję. Podobnie jak w przypadku ogólnych typów danych, nazwę ogólnego parametru czasu życia deklarujemy w nawiasach kątowych po nazwie struktury, abyśmy mogli użyć parametru czasu życia w ciele definicji struktury. Ta adnotacja oznacza, że instancja ImportantExcerpt nie może przeżyć referencji, którą przechowuje w swoim polu part.
Funkcja main tworzy tutaj instancję struktury ImportantExcerpt, która przechowuje referencję do pierwszego zdania String będącego własnością zmiennej novel. Dane w novel istnieją przed utworzeniem instancji ImportantExcerpt. Ponadto novel nie wychodzi poza zasięg, dopóki ImportantExcerpt nie wyjdzie poza zasięg, więc referencja w instancji ImportantExcerpt jest ważna.
Elizja czasów życia
Dowiedziałeś się, że każda referencja ma czas życia i że musisz określić parametry czasu życia dla funkcji lub struktur, które używają referencji. Jednak w Listingu 4-9 mieliśmy funkcję, ponownie pokazaną w Listingu 10-25, która kompilowała się bez adnotacji czasów życia.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// first_word works on slices of `String`s
let word = first_word(&my_string[..]);
let my_string_literal = "hello world";
// first_word works on slices of string literals
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Powodem, dla którego ta funkcja kompiluje się bez adnotacji czasów życia, jest historia: we wczesnych wersjach (przed 1.0) Rust, ten kod by się nie skompilował, ponieważ każda referencja wymagała jawnego czasu życia. W tamtym czasie sygnatura funkcji byłaby napisana tak:
fn first_word<'a>(s: &'a str) -> &'a str {Po napisaniu dużej ilości kodu w Rust, zespół Rust odkrył, że programiści Rust wpisywali te same adnotacje czasów życia wielokrotnie w konkretnych sytuacjach. Sytuacje te były przewidywalne i postępowały zgodnie z kilkoma deterministycznymi wzorcami. Deweloperzy zaprogramowali te wzorce w kodzie kompilatora, aby sprawdzacz pożyczeń mógł wnioskować o czasach życia w tych sytuacjach i nie potrzebował jawnych adnotacji.
Ten kawałek historii Rust jest istotny, ponieważ możliwe jest, że pojawi się więcej deterministycznych wzorców i zostanie dodanych do kompilatora. W przyszłości może być wymagane jeszcze mniej adnotacji czasów życia.
Wzorce zaprogramowane w analizie referencji przez Rust nazywane są zasadami elizji czasów życia. Nie są to zasady, którymi programiści mają się kierować; to zbiór konkretnych przypadków, które kompilator weźmie pod uwagę, a jeśli twój kod pasuje do tych przypadków, nie musisz jawnie pisać czasów życia.
Zasady elizji nie zapewniają pełnego wnioskowania. Jeśli po zastosowaniu zasad nadal istnieje niejasność co do czasów życia referencji, kompilator nie zgadnie, jakie powinny być czasy życia pozostałych referencji. Zamiast zgadywać, kompilator wyświetli błąd, który można rozwiązać, dodając adnotacje czasów życia.
Czasy życia na parametrach funkcji lub metod nazywane są czasami życia wejściowymi, a czasy życia na wartościach zwracanych nazywane są czasami życia wyjściowymi.
Kompilator używa trzech zasad, aby ustalić czasy życia referencji, gdy nie ma jawnych adnotacji. Pierwsza zasada dotyczy czasów życia wejściowych, a druga i trzecia zasada dotyczą czasów życia wyjściowych. Jeśli kompilator dojdzie do końca trzech zasad, a nadal istnieją referencje, dla których nie może ustalić czasów życia, kompilator zatrzyma się z błędem. Zasady te mają zastosowanie zarówno do definicji fn, jak i bloków impl.
Pierwsza zasada mówi, że kompilator przypisuje parametr czasu życia każdemu parametrowi, który jest referencją. Innymi słowy, funkcja z jednym parametrem otrzymuje jeden parametr czasu życia: fn foo<'a>(x: &'a i32); funkcja z dwoma parametrami otrzymuje dwa oddzielne parametry czasu życia: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); i tak dalej.
Druga zasada mówi, że jeśli istnieje dokładnie jeden parametr czasu życia wejściowego, to ten czas życia jest przypisywany do wszystkich parametrów czasu życia wyjściowego: fn foo<'a>(x: &'a i32) -> &'a i32.
Trzecia zasada mówi, że jeśli istnieje wiele parametrów czasu życia wejściowego, ale jeden z nich to &self lub &mut self, ponieważ jest to metoda, czas życia self jest przypisywany do wszystkich parametrów czasu życia wyjściowego. Ta trzecia zasada sprawia, że metody są znacznie przyjemniejsze w czytaniu i pisaniu, ponieważ potrzeba mniej symboli.
Udawajmy, że jesteśmy kompilatorem. Zastosujemy te zasady, aby ustalić czasy życia referencji w sygnaturze funkcji first_word z Listingu 10-25. Sygnatura zaczyna się bez żadnych czasów życia przypisanych do referencji:
fn first_word(s: &str) -> &str {Następnie kompilator stosuje pierwszą zasadę, która określa, że każdy parametr otrzymuje swój własny czas życia. Nazwiemy go jak zwykle 'a, więc sygnatura wygląda teraz tak:
fn first_word<'a>(s: &'a str) -> &str {Druga zasada ma zastosowanie, ponieważ istnieje dokładnie jeden czas życia wejściowego. Druga zasada określa, że czas życia jednego parametru wejściowego jest przypisywany do czasu życia wyjściowego, więc sygnatura wygląda teraz tak:
fn first_word<'a>(s: &'a str) -> &'a str {Teraz wszystkie referencje w sygnaturze tej funkcji mają czasy życia, a kompilator może kontynuować swoją analizę bez potrzeby, aby programista adnotował czasy życia w sygnaturze tej funkcji.
Przyjrzyjmy się innemu przykładowi, tym razem używając funkcji longest, która nie miała parametrów czasu życia, kiedy zaczęliśmy z nią pracować w Listingu 10-20:
fn longest(x: &str, y: &str) -> &str {Zastosujmy pierwszą zasadę: każdy parametr otrzymuje swój własny czas życia. Tym razem mamy dwa parametry zamiast jednego, więc mamy dwa czasy życia:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {Widzisz, że druga zasada nie ma zastosowania, ponieważ istnieje więcej niż jeden czas życia wejściowego. Trzecia zasada również nie ma zastosowania, ponieważ longest jest funkcją, a nie metodą, więc żaden z parametrów nie jest self. Po przejściu przez wszystkie trzy zasady, nadal nie ustaliliśmy, jaki jest czas życia typu zwracanego. Dlatego otrzymaliśmy błąd podczas próby kompilacji kodu z Listingu 10-20: kompilator przeanalizował zasady elizji czasów życia, ale nadal nie był w stanie ustalić wszystkich czasów życia referencji w sygnaturze.
Ponieważ trzecia zasada dotyczy tak naprawdę tylko sygnatur metod, przyjrzyjmy się teraz czasom życia w tym kontekście, aby zobaczyć, dlaczego trzecia zasada oznacza, że nie musimy zbyt często adnotować czasów życia w sygnaturach metod.
W definicjach metod
Kiedy implementujemy metody w strukturze z czasami życia, używamy tej samej składni co w przypadku ogólnych parametrów typów, jak pokazano w Listingu 10-11. Gdzie deklarujemy i używamy parametrów czasu życia, zależy od tego, czy są one związane z polami struktury, czy z parametrami metody i wartościami zwracanymi.
Nazwy czasów życia dla pól struktury zawsze muszą być deklarowane po słowie kluczowym impl, a następnie używane po nazwie struktury, ponieważ te czasy życia są częścią typu struktury.
W sygnaturach metod w bloku impl, referencje mogą być powiązane z czasem życia referencji w polach struktury, lub mogą być niezależne. Ponadto, zasady elizji czasów życia często powodują, że adnotacje czasów życia nie są konieczne w sygnaturach metod. Przyjrzyjmy się kilku przykładom, używając struktury ImportantExcerpt, którą zdefiniowaliśmy w Listingu 10-24.
Najpierw użyjemy metody o nazwie level, której jedynym parametrem jest referencja do self, a zwracana wartość to i32, która nie jest referencją do niczego:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Deklaracja parametru czasu życia po impl i jego użycie po nazwie typu są wymagane, ale ze względu na pierwszą zasadę elizji, nie musimy adnotować czasu życia referencji do self.
Oto przykład, w którym ma zastosowanie trzecia zasada elizji czasu życia:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Istnieją dwa wejściowe czasy życia, więc Rust stosuje pierwszą zasadę elizji czasu życia i nadaje zarówno &self, jak i announcement ich własne czasy życia. Następnie, ponieważ jeden z parametrów to &self, typ zwracany otrzymuje czas życia &self, a wszystkie czasy życia zostały uwzględnione.
Statyczny czas życia
Jeden specjalny czas życia, o którym musimy porozmawiać, to 'static, który oznacza, że dotknięta referencja może żyć przez cały czas trwania programu. Wszystkie literały ciągów znaków mają czas życia 'static, który możemy adnotować w następujący sposób:
#![allow(unused)]
fn main() {
let s: &'static str = "I have a static lifetime.";
}Tekst tego ciągu znaków jest przechowywany bezpośrednio w pliku binarnym programu, który jest zawsze dostępny. Dlatego czas życia wszystkich literałów ciągów znaków jest 'static.
Możesz zobaczyć sugestie w komunikatach o błędach, aby użyć czasu życia 'static. Ale zanim określisz 'static jako czas życia dla referencji, zastanów się, czy referencja, którą masz, faktycznie żyje przez cały czas trwania twojego programu i czy tego chcesz. Przez większość czasu komunikat o błędzie sugerujący czas życia 'static wynika z próby utworzenia wiszącej referencji lub niezgodności dostępnych czasów życia. W takich przypadkach rozwiązaniem jest naprawienie tych problemów, a nie określanie czasu życia 'static.
Ogólne parametry typów, ograniczenia cech i czasy życia
Przyjrzyjmy się krótko składni określania ogólnych parametrów typów, ograniczeń cech i czasów życia w jednej funkcji!
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest_with_an_announcement(
string1.as_str(),
string2,
"Today is someone's birthday!",
);
println!("The longest string is {result}");
}
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Announcement! {ann}");
if x.len() > y.len() { x } else { y }
}To funkcja longest z Listingu 10-21, która zwraca dłuższy z dwóch wycinków ciągów znaków. Ale teraz ma dodatkowy parametr o nazwie ann typu ogólnego T, który może być wypełniony dowolnym typem implementującym cechę Display, zgodnie z klauzulą where. Ten dodatkowy parametr zostanie wypisany za pomocą {}, dlatego konieczne jest ograniczenie cechy Display. Ponieważ czasy życia są rodzajem generyków, deklaracje parametru czasu życia 'a i ogólnego parametru typu T znajdują się na tej samej liście w nawiasach kątowych po nazwie funkcji.
Podsumowanie
W tym rozdziale omówiliśmy wiele zagadnień! Teraz, gdy znasz ogólne parametry typów, cechy i ograniczenia cech oraz ogólne parametry czasów życia, jesteś gotowy do pisania kodu bez powtórzeń, który działa w wielu różnych sytuacjach. Ogólne parametry typów pozwalają zastosować kod do różnych typów. Cechy i ograniczenia cech zapewniają, że mimo iż typy są ogólne, będą miały zachowanie, którego kod potrzebuje. Nauczyłeś się, jak używać adnotacji czasów życia, aby zapewnić, że ten elastyczny kod nie będzie miał żadnych wiszących referencji. I cała ta analiza odbywa się w czasie kompilacji, co nie wpływa na wydajność w czasie wykonania!
Wierz lub nie, ale jest znacznie więcej do nauczenia się na tematy, które omówiliśmy w tym rozdziale: Rozdział 18 omawia obiekty cech, które są innym sposobem używania cech. Istnieją również bardziej złożone scenariusze związane z adnotacjami czasów życia, które będą ci potrzebne tylko w bardzo zaawansowanych przypadkach; w ich przypadku powinieneś przeczytać Rust Reference. Ale następnie dowiesz się, jak pisać testy w Rust, aby upewnić się, że twój kod działa tak, jak powinien.
Pisanie automatycznych testów
W swoim eseju „Skromny programista” z 1972 roku, Edsger W. Dijkstra powiedział, że „testowanie programu może być bardzo efektywnym sposobem na wykazanie obecności błędów, ale jest beznadziejnie niewystarczające do wykazania ich braku”. To nie znaczy, że nie powinniśmy próbować testować jak najwięcej!
Poprawność w naszych programach to zakres, w jakim nasz kod robi to, co zamierzamy. Rust został zaprojektowany z dużą troską o poprawność programów, ale poprawność jest złożona i niełatwa do udowodnienia. System typów Rust bierze na siebie dużą część tego ciężaru, ale system typów nie jest w stanie wyłapać wszystkiego. W związku z tym Rust zawiera wsparcie dla pisania automatycznych testów oprogramowania.
Powiedzmy, że piszemy funkcję add_two, która dodaje 2 do dowolnej liczby przekazanej do niej. Sygnatura tej funkcji akceptuje liczbę całkowitą jako parametr i zwraca liczbę całkowitą jako wynik. Kiedy implementujemy i kompilujemy tę funkcję, Rust wykonuje wszystkie sprawdzanie typów i sprawdzanie pożyczeń, o których uczyłeś się do tej pory, aby zapewnić, że na przykład nie przekazujemy wartości String ani nieprawidłowej referencji do tej funkcji. Ale Rust nie jest w stanie sprawdzić, czy ta funkcja zrobi dokładnie to, co zamierzamy, czyli zwróci parametr plus 2, a nie na przykład parametr plus 10 lub parametr minus 50! Właśnie tutaj wchodzą testy.
Możemy pisać testy, które potwierdzają, na przykład, że gdy przekazujemy 3 do funkcji add_two, zwrócona wartość to 5. Możemy uruchamiać te testy za każdym razem, gdy wprowadzamy zmiany w naszym kodzie, aby upewnić się, że istniejące prawidłowe zachowanie nie uległo zmianie.
Testowanie to złożona umiejętność: Chociaż w jednym rozdziale nie możemy omówić każdego szczegółu dotyczącego tego, jak pisać dobre testy, w tym rozdziale omówimy mechanikę funkcji testowych Rust. Porozmawiamy o dostępnych adnotacjach i makrach podczas pisania testów, domyślnym zachowaniu i opcjach dostępnych do uruchamiania testów oraz o tym, jak organizować testy w testy jednostkowe i testy integracyjne.
Jak pisać testy
Jak pisać testy
Testy to funkcje Rusta, które weryfikują, czy kod poza testami działa zgodnie z oczekiwaniami. Ciała funkcji testowych zazwyczaj wykonują trzy działania:
- Przygotowanie potrzebnych danych lub stanu.
- Uruchomienie kodu, który chcesz przetestować.
- Sprawdzenie, czy wyniki są zgodne z oczekiwaniami.
Przyjrzyjmy się funkcjom, które Rust dostarcza specjalnie do pisania testów
wykonujących te działania, w tym atrybutowi test, kilku makrom i atrybutowi
should_panic.
Struktura funkcji testowych
Najprościej rzecz ujmując, test w Rust to funkcja opatrzona atrybutem test.
Atrybuty to metadane dotyczące fragmentów kodu Rust; jednym z przykładów jest
atrybut derive, którego używaliśmy ze strukturami w Rozdziale 5. Aby
zmienić funkcję w funkcję testową, dodaj #[test] w linii przed fn. Kiedy
uruchamiasz testy za pomocą polecenia cargo test, Rust buduje binarny
runner testów, który uruchamia adnotowane funkcje i raportuje, czy każda
funkcja testowa przeszła, czy nie powiodła się.
Ilekroć tworzymy nowy projekt biblioteczny za pomocą Cargo, automatycznie generowany jest dla nas moduł testowy z funkcją testową. Moduł ten udostępnia szablon do pisania testów, dzięki czemu nie musisz za każdym razem, gdy zaczynasz nowy projekt, szukać dokładnej struktury i składni. Możesz dodać tyle dodatkowych funkcji testowych i modułów testowych, ile tylko chcesz!
Przeanalizujemy niektóre aspekty działania testów, eksperymentując z szablonowym testem, zanim faktycznie przetestujemy jakikolwiek kod. Następnie napiszemy kilka rzeczywistych testów, które wywołają napisany przez nas kod i sprawdzą, czy jego zachowanie jest prawidłowe.
Stwórzmy nowy projekt biblioteczny o nazwie adder, który będzie dodawał
dwie liczby:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
Zawartość pliku src/lib.rs w Twojej bibliotece adder powinna wyglądać jak
Listing 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}cargo newPlik zaczyna się od przykładowej funkcji add, abyśmy mieli coś do
testowania.
Na razie skupmy się wyłącznie na funkcji it_works. Zwróć uwagę na adnotację
#[test]: Ten atrybut wskazuje, że jest to funkcja testowa, więc
program uruchamiający testy wie, aby traktować tę funkcję jako test. Możemy
również mieć funkcje nietestowe w module tests, aby pomóc w
konfigurowaniu typowych scenariuszy lub wykonywaniu typowych operacji, więc
zawsze musimy wskazywać, które funkcje są testami.
Przykładowe ciało funkcji używa makra assert_eq!, aby sprawdzić, czy
result, które zawiera wynik wywołania add z argumentami 2 i 2, jest równe
4. To twierdzenie służy jako przykład formatu typowego testu. Uruchommy je,
aby zobaczyć, że ten test przechodzi.
Polecenie cargo test uruchamia wszystkie testy w naszym projekcie, jak
pokazano w Listingu 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo skompilował i uruchomił test. Widzimy linię running 1 test. Następna
linia pokazuje nazwę wygenerowanej funkcji testowej, nazwanej
tests::it_works, oraz że wynik uruchomienia tego testu to ok. Ogólne
podsumowanie test result: ok. oznacza, że wszystkie testy przeszły, a część
1 passed; 0 failed sumuje liczbę testów, które przeszły lub nie powiodły się.
Można oznaczyć test jako zignorowany, aby nie był uruchamiany w konkretnej
instancji; omówimy to w sekcji „Ignorowanie testów, chyba że są
specjalnie żądane” później w tym rozdziale. Ponieważ
tego tutaj nie zrobiliśmy, podsumowanie pokazuje 0 ignored. Możemy również
przekazać argument do polecenia cargo test, aby uruchomić tylko te testy,
których nazwa pasuje do ciągu znaków; nazywa się to filtrowaniem,
i omówimy to w sekcji „Uruchamianie podzbioru testów według
nazwy”. Tutaj nie filtrowaliśmy uruchamianych testów,
więc na końcu podsumowania wyświetla się 0 filtered out.
Statystyka 0 measured dotyczy testów wydajnościowych, które mierzą
wydajność. Testy wydajnościowe, w chwili pisania tego tekstu, są dostępne tylko
w nightly Rust. Więcej informacji znajdziesz w dokumentacji testów
wydajnościowych.
Następna część danych wyjściowych testu, zaczynająca się od Doc-tests adder,
dotyczy wyników wszelkich testów dokumentacyjnych. Nie mamy jeszcze żadnych
testów dokumentacyjnych, ale Rust może kompilować wszelkie przykłady kodu,
które pojawiają się w naszej dokumentacji API. Ta funkcja pomaga utrzymać
dokumentację i kod w synchronizacji! Omówimy, jak pisać testy dokumentacyjne w
sekcji „Komentarze dokumentacyjne jako testy”
Rozdziału 14. Na razie zignorujemy dane wyjściowe Doc-tests.
Zacznijmy dostosowywać test do naszych własnych potrzeb. Najpierw zmień nazwę
funkcji it_works na inną, taką jak exploration, w ten sposób:
Nazwa pliku: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Następnie ponownie uruchom cargo test. Wynik pokazuje teraz exploration
zamiast it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Teraz dodamy kolejny test, ale tym razem stworzymy test, który zawiedzie! Testy
zawodzą, gdy coś w funkcji testowej panikuje. Każdy test jest uruchamiany w
nowym wątku, a gdy główny wątek widzi, że wątek testowy umarł, test jest
oznaczany jako nieudany. W Rozdziale 9 rozmawialiśmy o tym, że najprostszym
sposobem na panikę jest wywołanie makra panic!. Wprowadź nowy test jako
funkcję o nazwie another, tak aby Twój plik src/lib.rs wyglądał jak Listing
11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}panic!Uruchom testy ponownie za pomocą cargo test. Wynik powinien wyglądać jak
Listing 11-4, który pokazuje, że nasz test exploration przeszedł, a another
zakończył się niepowodzeniem.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Zamiast ok, linia test tests::another pokazuje FAILED. Pojawiają się
dwie nowe sekcje między indywidualnymi wynikami a podsumowaniem: Pierwsza
wyświetla szczegółowy powód każdego niepowodzenia testu. W tym przypadku
dostajemy szczegóły, że tests::another zawiódł, ponieważ spanikował z
wiadomością Make this test fail w linii 17 w pliku src/lib.rs. Następna
sekcja zawiera tylko nazwy wszystkich nieudanych testów, co jest przydatne,
gdy jest dużo testów i dużo szczegółowych danych wyjściowych nieudanych
testów. Możemy użyć nazwy nieudanego testu, aby uruchomić tylko ten test,
aby łatwiej go debugować; więcej na temat sposobów uruchamiania testów
opowiemy w sekcji „Kontrolowanie sposobu uruchamiania
testów”.
Na koniec wyświetla się linia podsumowująca: Ogólnie, nasz wynik testów to
FAILED. Jeden test przeszedł, a jeden zawiódł.
Teraz, gdy widziałeś, jak wyglądają wyniki testów w różnych scenariuszach,
przyjrzyjmy się innym makrom niż panic!, które są przydatne w testach.
Sprawdzanie wyników za pomocą makra assert!
Makro assert!, dostarczane przez standardową bibliotekę, jest przydatne,
gdy chcesz upewnić się, że jakiś warunek w teście ocenia się jako true.
Podajemy makru assert! argument, który ocenia się do wartości boolowskiej.
Jeśli wartość jest true, nic się nie dzieje i test przechodzi. Jeśli wartość
jest false, makro assert! wywołuje panic!, aby spowodować niepowodzenie
testu. Użycie makra assert! pomaga nam sprawdzić, czy nasz kod działa w
sposób, w jaki zamierzamy.
W Rozdziale 5, Listing 5-15, użyliśmy struktury Rectangle i metody
can_hold, które są powtórzone tutaj w Listingu 11-5. Umieśćmy ten kod w
pliku src/lib.rs, a następnie napiszmy dla niego kilka testów za pomocą
makra assert!.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Rectangle i jej metoda can_hold z Rozdziału 5Metoda can_hold zwraca wartość boolowską, co oznacza, że jest idealnym
przypadkiem użycia dla makra assert!. W Listingu 11-6 piszemy test, który
wykorzystuje metodę can_hold, tworząc instancję Rectangle o szerokości 8
i wysokości 7 i twierdząc, że może ona pomieścić inną instancję Rectangle
o szerokości 5 i wysokości 1.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}can_hold, który sprawdza, czy większy prostokąt może rzeczywiście pomieścić mniejszy prostokątZwróć uwagę na linię use super::*; w module tests. Moduł tests to
zwykły moduł, który podlega zwykłym zasadom widoczności, które omówiliśmy w
Rozdziale 7 w sekcji „Ścieżki do odwoływania się do elementu w drzewie
modułów”.
Ponieważ moduł tests jest modułem wewnętrznym, musimy wprowadzić kod poddawany
testom z modułu zewnętrznego do zakresu modułu wewnętrznego. Używamy tutaj
globa, więc wszystko, co zdefiniujemy w module zewnętrznym, jest dostępne dla
tego modułu tests.
Nazwaliśmy nasz test larger_can_hold_smaller i utworzyliśmy dwie
instancje Rectangle, których potrzebujemy. Następnie wywołaliśmy makro
assert! i przekazaliśmy mu wynik wywołania larger.can_hold(&smaller).
To wyrażenie powinno zwrócić true, więc nasz test powinien przejść.
Sprawdźmy!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Przechodzi! Dodajmy kolejny test, tym razem sprawdzający, czy mniejszy prostokąt nie może pomieścić większego prostokąta:
Nazwa pliku: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Ponieważ poprawny wynik funkcji can_hold w tym przypadku to false, musimy
zanegować ten wynik, zanim przekażemy go do makra assert!. W rezultacie nasz
test przejdzie, jeśli can_hold zwróci false:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Dwa testy, które przeszły! Zobaczmy teraz, co się stanie z wynikami naszych
testów, gdy wprowadzimy błąd do naszego kodu. Zmienimy implementację metody
can_hold, zastępując znak „większe niż” (>) znakiem „mniejsze niż” (<),
gdy porównuje szerokości:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Uruchomienie testów teraz daje następujące wyniki:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nasze testy wykryły błąd! Ponieważ larger.width wynosi 8, a smaller.width
wynosi 5, porównanie szerokości w can_hold zwraca teraz false: 8 nie jest
mniejsze niż 5.
Testowanie równości za pomocą makr assert_eq! i assert_ne!
Powszechnym sposobem weryfikacji funkcjonalności jest testowanie równości między
wynikiem kodu poddanego testom a wartością, którą kod powinien zwrócić. Można
to zrobić, używając makra assert! i przekazując mu wyrażenie używające
operatora ==. Jest to jednak tak powszechny test, że standardowa biblioteka
dostarcza parę makr — assert_eq! i assert_ne! — aby wygodniej
wykonać ten test. Makra te porównują dwa argumenty pod kątem równości lub
nierówności. Wyświetlają również dwie wartości, jeśli asercja zawiedzie, co
ułatwia zrozumienie, dlaczego test zawiódł; z kolei makro assert!
wskazuje tylko, że otrzymało wartość false dla wyrażenia ==, nie
wyświetlając wartości, które doprowadziły do wartości false.
W Listingu 11-7 piszemy funkcję o nazwie add_two, która dodaje 2 do swego
parametru, a następnie testujemy tę funkcję za pomocą makra assert_eq!.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}add_two za pomocą makra assert_eq!Sprawdźmy, czy przechodzi!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Tworzymy zmienną o nazwie result, która przechowuje wynik wywołania
add_two(2). Następnie przekazujemy result i 4 jako argumenty do makra
assert_eq!. Linia wyjściowa dla tego testu to test tests::it_adds_two ... ok,
a tekst ok wskazuje, że nasz test przeszedł!
Wprowadźmy błąd do naszego kodu, aby zobaczyć, jak wygląda assert_eq!, gdy
zawodzi. Zmień implementację funkcji add_two, aby zamiast tego dodawała 3:
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Uruchom testy ponownie:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nasz test wykrył błąd! Test tests::it_adds_two nie powiódł się, a komunikat
informuje nas, że asercja, która zawiodła, to left == right oraz jakie są
wartości left i right. Ten komunikat pomaga nam rozpocząć debugowanie:
argument left, gdzie mieliśmy wynik wywołania add_two(2), wynosił 5, ale
argument right wynosił 4. Można sobie wyobrazić, że byłoby to szczególnie
pomocne, gdybyśmy mieli wiele testów.
Zauważ, że w niektórych językach i frameworkach testowych parametry funkcji
asercji równości nazywane są expected i actual, a kolejność, w jakiej
określamy argumenty, ma znaczenie. Jednak w Rust nazywają się left i
right, a kolejność, w jakiej określamy wartość, której oczekujemy, i
wartość, którą produkuje kod, nie ma znaczenia. Moglibyśmy napisać asercję
w tym teście jako assert_eq!(4, result), co spowodowałoby ten sam komunikat
o błędzie, który wyświetla assertion `left == right` failed.
Makro assert_ne! przejdzie, jeśli dwie podane mu wartości nie są sobie równe,
a zawiedzie, jeśli są równe. To makro jest najbardziej przydatne w przypadkach,
gdy nie jesteśmy pewni, jaka będzie wartość, ale wiemy, jaka wartość
zdecydowanie nie powinna być. Na przykład, jeśli testujemy funkcję, która ma
gwarantować zmianę jej danych wejściowych w jakiś sposób, ale sposób zmiany
danych wejściowych zależy od dnia tygodnia, w którym uruchamiamy nasze testy,
najlepiej byłoby sprawdzić, czy wynik funkcji nie jest równy danym
wejściowym.
Pod powierzchnią, makra assert_eq! i assert_ne! używają odpowiednio
operatorów == i !=. Kiedy asercje zawiodą, te makra wypisują swoje
argumenty za pomocą formatowania debuggowania, co oznacza, że porównywane
wartości muszą implementować cechy PartialEq i Debug. Wszystkie typy
prymitywne i większość typów standardowej biblioteki implementują te cechy.
Dla struktur i wyliczeń, które sam definiujesz, będziesz musiał zaimplementować
PartialEq, aby sprawdzić równość tych typów. Będziesz również musiał
zaimplementować Debug, aby wyświetlić wartości, gdy asercja zawiedzie.
Ponieważ obie cechy są cechami, które można wyprowadzić, jak wspomniano w
Listingu 5-12 w Rozdziale 5, jest to zazwyczaj tak proste, jak dodanie
anotacji #[derive(PartialEq, Debug)] do definicji struktury lub wyliczenia.
Więcej szczegółów na temat tych i innych cech, które można wyprowadzić,
znajdziesz w Dodatku C, „Cechy, które można
wyprowadzić”.
Dodawanie niestandardowych komunikatów o błędach
Możesz również dodać niestandardowy komunikat do wydrukowania wraz z
komunikatem o błędzie jako opcjonalne argumenty do makr assert!, assert_eq!
i assert_ne!. Wszelkie argumenty określone po wymaganych argumentach są
przekazywane do makra format! (omówionego w „Łączenie za pomocą + lub
format!” w Rozdziale 8), więc możesz
przekazać ciąg formatujący, który zawiera znaczniki {} i wartości, które mają
być umieszczone w tych znacznikach. Niestandardowe komunikaty są przydatne do
dokumentowania, co oznacza asercja; gdy test zawiedzie, będziesz miał lepsze
pojęcie o tym, na czym polega problem z kodem.
Na przykład, powiedzmy, że mamy funkcję, która wita ludzi po imieniu, i chcemy przetestować, czy imię, które przekazujemy do funkcji, pojawia się w danych wyjściowych:
Nazwa pliku: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Wymagania dla tego programu nie zostały jeszcze uzgodnione, a my jesteśmy
raczej pewni, że tekst „Hello” na początku pozdrowienia zmieni się. Postanowiliśmy,
że nie chcemy aktualizować testu, gdy wymagania się zmienią, więc zamiast
sprawdzać dokładną równość z wartością zwróconą przez funkcję greeting,
będziemy tylko sprawdzać, czy wynik zawiera tekst parametru wejściowego.
Teraz wprowadźmy błąd do tego kodu, zmieniając greeting tak, aby wykluczało
name, aby zobaczyć, jak wygląda domyślne niepowodzenie testu:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Uruchomienie tego testu daje następujące wyniki:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Ten wynik wskazuje tylko, że asercja nie powiodła się i w której linii się
znajduje. Bardziej użyteczny komunikat o błędzie wyświetliłby wartość z funkcji
greeting. Dodajmy niestandardowy komunikat o błędzie składający się z ciągu
formatującego z znacznikiem miejsca wypełnionym rzeczywistą wartością, którą
otrzymaliśmy z funkcji greeting:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}Teraz, gdy uruchomimy test, otrzymamy bardziej informacyjny komunikat o błędzie:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Możemy zobaczyć rzeczywistą wartość, którą otrzymaliśmy w wynikach testu, co pomogłoby nam debugować, co się stało, zamiast tego, czego się spodziewaliśmy.
Sprawdzanie paniki za pomocą should_panic
Oprócz sprawdzania wartości zwracanych, ważne jest sprawdzenie, czy nasz kod
obsługuje warunki błędów zgodnie z oczekiwaniami. Na przykład, rozważ typ
Guess, który utworzyliśmy w Rozdziale 9, Listing 9-13. Inny kod, który
używa Guess, zależy od gwarancji, że instancje Guess będą zawierać tylko
wartości od 1 do 100. Możemy napisać test, który zapewni, że próba utworzenia
instancji Guess z wartością spoza tego zakresu spowoduje panikę.
Robimy to, dodając atrybut should_panic do naszej funkcji testowej. Test
przechodzi, jeśli kod wewnątrz funkcji panikuje; test kończy się niepowodzeniem,
jeśli kod wewnątrz funkcji nie panikuje.
Listing 11-8 przedstawia test, który sprawdza, czy warunki błędu funkcji
Guess::new występują, gdy tego oczekujemy.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}panic!Umieszczamy atrybut #[should_panic] po atrybucie #[test] i przed funkcją
testową, której dotyczy. Spójrzmy na wynik, gdy ten test przejdzie:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Wygląda dobrze! Teraz wprowadźmy błąd do naszego kodu, usuwając warunek, że
funkcja new spanikuje, jeśli wartość jest większa niż 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Kiedy uruchomimy test w Listingu 11-8, zakończy się on niepowodzeniem:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
W tym przypadku nie otrzymujemy zbyt pomocnego komunikatu, ale patrząc na
funkcję testową, widzimy, że jest ona opatrzona adnotacją
#[should_panic]. Otrzymany błąd oznacza, że kod w funkcji testowej nie
spowodował paniki.
Testy wykorzystujące should_panic mogą być niedokładne. Test should_panic
przeszedłby nawet wtedy, gdyby test panikował z innego powodu niż ten, którego
się spodziewaliśmy. Aby testy should_panic były bardziej precyzyjne,
możemy dodać opcjonalny parametr expected do atrybutu should_panic. Test
framework zapewni, że komunikat o błędzie będzie zawierał podany tekst. Na
przykład, rozważ zmodyfikowany kod dla Guess w Listingu 11-9, gdzie funkcja
new panikuje z różnymi komunikatami w zależności od tego, czy wartość jest
za mała, czy za duża.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}panic! z komunikatem paniki zawierającym określony podciągTen test przejdzie, ponieważ wartość, którą umieściliśmy w parametrze
expected atrybutu should_panic, jest podciągiem komunikatu, z którym
funkcja Guess::new panikuje. Mogliśmy określić cały oczekiwany komunikat
paniki, który w tym przypadku brzmiałby Guess value must be less than or equal to 100, got 200. To, co zdecydujesz się określić, zależy od tego, jak
wiele z komunikatu paniki jest unikalne lub dynamiczne i jak precyzyjny chcesz,
aby był Twój test. W tym przypadku podciąg komunikatu paniki jest wystarczający,
aby upewnić się, że kod w funkcji testowej wykonuje przypadek
else if value > 100.
Aby zobaczyć, co się stanie, gdy test should_panic z komunikatem expected
zawiedzie, ponownie wprowadźmy błąd do naszego kodu, zamieniając ciała bloków
if value < 1 i else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Tym razem, gdy uruchomimy test should_panic, zakończy się on niepowodzeniem:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "Guess value must be greater than or equal to 1, got 200."
expected substring: "less than or equal to 100"
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Komunikat o błędzie wskazuje, że ten test rzeczywiście panikował, jak się
spodziewaliśmy, ale komunikat paniki nie zawierał oczekiwanego ciągu znaków
less than or equal to 100. Komunikat paniki, który otrzymaliśmy w tym
przypadku, brzmiał Guess value must be greater than or equal to 1, got 200.
Teraz możemy zacząć szukać naszego błędu!
Używanie Result<T, E> w testach
Wszystkie nasze dotychczasowe testy panikują, gdy zawiodą. Możemy również
pisać testy, które używają Result<T, E>! Oto test z Listingu 11-1,
przepisany tak, aby używał Result<T, E> i zwracał Err zamiast panikować:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}Funkcja it_works ma teraz typ zwracany Result<(), String>. W ciele
funkcji, zamiast wywoływać makro assert_eq!, zwracamy Ok(()), gdy test
przejdzie, i Err z String w środku, gdy test zawiedzie.
Pisanie testów w taki sposób, aby zwracały Result<T, E>, pozwala na
używanie operatora znaku zapytania w ciele testów, co może być wygodnym
sposobem pisania testów, które powinny zakończyć się niepowodzeniem, jeśli
jakakolwiek operacja w ich obrębie zwróci wariant Err.
Nie możesz używać adnotacji #[should_panic] w testach, które używają
Result<T, E>. Aby potwierdzić, że operacja zwraca wariant Err, nie używaj
operatora znaku zapytania na wartości Result<T, E>. Zamiast tego użyj
assert!(value.is_err()).
Teraz, gdy znasz kilka sposobów pisania testów, przyjrzyjmy się, co dzieje się,
gdy uruchamiamy nasze testy i zbadajmy różne opcje, których możemy użyć z
cargo test.
Kontrolowanie sposobu uruchamiania testów
Kontrolowanie sposobu uruchamiania testów
Tak jak cargo run kompiluje Twój kod, a następnie uruchamia wynikowy plik binarny, tak cargo test kompiluje Twój kod w trybie testowym i uruchamia wynikowy plik binarny testów. Domyślne zachowanie pliku binarnego wyprodukowanego przez cargo test to uruchamianie wszystkich testów równolegle i przechwytywanie danych wyjściowych generowanych podczas przebiegów testów, co zapobiega wyświetlaniu danych wyjściowych i ułatwia czytanie danych wyjściowych związanych z wynikami testów. Możesz jednak określić opcje wiersza poleceń, aby zmienić to domyślne zachowanie.
Niektóre opcje wiersza poleceń trafiają do cargo test, a niektóre do wynikowego pliku binarnego testów. Aby rozdzielić te dwa typy argumentów, należy wymienić argumenty, które trafiają do cargo test, po których następuje separator --, a następnie te, które trafiają do pliku binarnego testów. Uruchomienie cargo test --help wyświetla opcje, których można użyć z cargo test, a uruchomienie cargo test -- --help wyświetla opcje, których można użyć po separatorze. Opcje te są również udokumentowane w sekcji „Testy” w The rustc Book.
Uruchamianie testów równolegle lub sekwencyjnie
Kiedy uruchamiasz wiele testów, domyślnie działają one równolegle, używając wątków, co oznacza, że kończą się szybciej i otrzymujesz informację zwrotną wcześniej. Ponieważ testy działają jednocześnie, musisz upewnić się, że Twoje testy nie zależą od siebie nawzajem ani od żadnego współdzielonego stanu, w tym współdzielonego środowiska, takiego jak bieżący katalog roboczy lub zmienne środowiskowe.
Na przykład, powiedzmy, że każdy z twoich testów uruchamia pewien kod, który tworzy plik na dysku o nazwie test-output.txt i zapisuje do niego pewne dane. Następnie, każdy test odczytuje dane z tego pliku i twierdzi, że plik zawiera określoną wartość, która jest różna w każdym teście. Ponieważ testy działają jednocześnie, jeden test może nadpisać plik w czasie między zapisem a odczytem pliku przez inny test. Drugi test zakończy się niepowodzeniem, nie dlatego, że kod jest niepoprawny, ale dlatego, że testy wzajemnie się zakłócały podczas działania równoległego. Jednym z rozwiązań jest upewnienie się, że każdy test zapisuje do innego pliku; innym rozwiązaniem jest uruchamianie testów jeden po drugim.
Jeśli nie chcesz uruchamiać testów równolegle lub jeśli chcesz mieć bardziej precyzyjną kontrolę nad liczbą używanych wątków, możesz przekazać flagę --test-threads oraz liczbę wątków, których chcesz użyć, do binarnego pliku testowego. Spójrz na następujący przykład:
$ cargo test -- --test-threads=1
Ustawiamy liczbę wątków testowych na 1, informując program, aby nie używał żadnego paralelizmu. Uruchamianie testów na jednym wątku zajmie więcej czasu niż uruchamianie ich równolegle, ale testy nie będą ze sobą kolidować, jeśli współdzielą stan.
Wyświetlanie wyjścia funkcji
Domyślnie, jeśli test przechodzi, biblioteka testowa Rust przechwytuje wszystko, co jest wypisywane na standardowe wyjście. Na przykład, jeśli wywołamy println! w teście, a test przejdzie, nie zobaczymy wyjścia println! w terminalu; zobaczymy tylko wiersz wskazujący, że test przeszedł. Jeśli test zakończy się niepowodzeniem, zobaczymy wszystko, co zostało wypisane na standardowe wyjście, wraz z resztą komunikatu o błędzie.
Jako przykład, Listing 11-10 zawiera prostą funkcję, która wypisuje wartość swojego parametru i zwraca 10, a także test, który przechodzi, i test, który kończy się niepowodzeniem.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}Kiedy uruchomimy te testy za pomocą cargo test, zobaczymy następujące dane wyjściowe:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Zauważ, że w tym wyjściu nigdzie nie widzimy I got the value 4, które jest wypisywane, gdy test, który przechodzi, jest uruchamiany. To wyjście zostało przechwycone. Wyjście z testu, który zakończył się niepowodzeniem, I got the value 8, pojawia się w sekcji podsumowania testów, która również pokazuje przyczynę niepowodzenia testu.
Jeśli chcemy zobaczyć wypisane wartości również dla przechodzących testów, możemy nakazać Rustowi wyświetlanie danych wyjściowych udanych testów za pomocą --show-output:
$ cargo test -- --show-output
Kiedy ponownie uruchomimy testy z Listingu 11-10 z flagą --show-output, zobaczymy następujące dane wyjściowe:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Uruchamianie podzbioru testów po nazwie
Uruchamianie pełnego zestawu testów może czasem zająć dużo czasu. Jeśli pracujesz nad kodem w określonym obszarze, możesz chcieć uruchomić tylko testy dotyczące tego kodu. Możesz wybrać, które testy uruchomić, przekazując cargo test nazwę lub nazwy testów, które chcesz uruchomić, jako argument.
Aby zademonstrować, jak uruchomić podzbiór testów, najpierw utworzymy trzy testy dla naszej funkcji add_two, jak pokazano w Listingu 11-11, i wybierzemy, które z nich uruchomić.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}Jeśli uruchomimy testy bez przekazywania żadnych argumentów, jak widzieliśmy wcześniej, wszystkie testy zostaną uruchomione równolegle:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Uruchamianie pojedynczych testów
Możemy przekazać nazwę dowolnej funkcji testowej do cargo test, aby uruchomić tylko ten test:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Uruchomiono tylko test o nazwie one_hundred; pozostałe dwa testy nie pasowały do tej nazwy. Wyniki testów informują nas, że było więcej testów, które nie zostały uruchomione, wyświetlając na końcu 2 filtered out.
W ten sposób nie można określać nazw wielu testów; użyta zostanie tylko pierwsza wartość podana cargo test. Ale istnieje sposób na uruchamianie wielu testów.
Filtrowanie w celu uruchomienia wielu testów
Możemy określić część nazwy testu, a każdy test, którego nazwa pasuje do tej wartości, zostanie uruchomiony. Na przykład, ponieważ nazwy dwóch naszych testów zawierają add, możemy uruchomić te dwa, uruchamiając cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
To polecenie uruchomiło wszystkie testy zawierające add w nazwie i odfiltrowało test o nazwie one_hundred. Zwróć również uwagę, że moduł, w którym pojawia się test, staje się częścią nazwy testu, więc możemy uruchomić wszystkie testy w module, filtrując po nazwie modułu.
Ignorowanie testów, chyba że są wyraźnie żądane
Czasami kilka konkretnych testów może być bardzo czasochłonnych w wykonaniu, więc możesz chcieć je wykluczyć podczas większości uruchomień cargo test. Zamiast wymieniać jako argumenty wszystkie testy, które chcesz uruchomić, możesz zamiast tego opatrzyć czasochłonne testy atrybutem ignore, aby je wykluczyć, jak pokazano tutaj:
Nazwa pliku: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}Po #[test] dodajemy wiersz #[ignore] do testu, który chcemy wykluczyć. Teraz, gdy uruchomimy nasze testy, it_works zostanie uruchomione, ale expensive_test nie:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Funkcja expensive_test jest wymieniona jako ignored. Jeśli chcemy uruchomić tylko ignorowane testy, możemy użyć cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Kontrolując, które testy są uruchamiane, możesz mieć pewność, że wyniki cargo test zostaną zwrócone szybko. Kiedy nadejdzie moment, w którym sensowne jest sprawdzenie wyników testów ignored i masz czas, aby poczekać na wyniki, możesz zamiast tego uruchomić cargo test -- --ignored. Jeśli chcesz uruchomić wszystkie testy, niezależnie od tego, czy są ignorowane, czy nie, możesz uruchomić cargo test -- --include-ignored.
Organizacja testów
Organizacja testów
Jak wspomniano na początku rozdziału, testowanie jest złożoną dyscypliną, a różni ludzie używają różnej terminologii i organizacji. Społeczność Rust rozważa testy w kategoriach dwóch głównych kategorii: testów jednostkowych i testów integracyjnych. Testy jednostkowe są małe i bardziej skoncentrowane, testują jeden moduł w izolacji, i mogą testować interfejsy prywatne. Testy integracyjne są całkowicie zewnętrzne w stosunku do Twojej biblioteki i używają Twojego kodu w taki sam sposób, jak każdy inny kod zewnętrzny, używając tylko publicznego interfejsu i potencjalnie testując wiele modułów na test.
Pisanie obu rodzajów testów jest ważne, aby upewnić się, że części twojej biblioteki działają tak, jak tego oczekujesz, zarówno oddzielnie, jak i razem.
Testy jednostkowe
Celem testów jednostkowych jest przetestowanie każdej jednostki kodu w izolacji od reszty kodu, aby szybko zlokalizować, gdzie kod działa, a gdzie nie, zgodnie z oczekiwaniami. Testy jednostkowe umieszcza się w katalogu src w każdym pliku z kodem, który testują. Konwencją jest tworzenie w każdym pliku modułu o nazwie tests, który zawiera funkcje testowe i oznaczanie modułu atrybutem cfg(test).
Moduł tests i #[cfg(test)]
Adnotacja #[cfg(test)] na module tests informuje Rust, aby kompilował i uruchamiał kod testowy tylko wtedy, gdy uruchamiasz cargo test, a nie gdy uruchamiasz cargo build. To oszczędza czas kompilacji, gdy chcesz tylko zbudować bibliotekę, i oszczędza miejsce w wynikowym skompilowanym artefakcie, ponieważ testy nie są włączone. Zobaczysz, że ponieważ testy integracyjne znajdują się w innym katalogu, nie potrzebują adnotacji #[cfg(test)]. Jednakże, ponieważ testy jednostkowe znajdują się w tych samych plikach co kod, będziesz używał #[cfg(test)] do określenia, że nie powinny być one uwzględniane w skompilowanym wyniku.
Pamiętaj, że kiedy generowaliśmy nowy projekt adder w pierwszej sekcji tego rozdziału, Cargo wygenerował dla nas ten kod:
Nazwa pliku: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Na automatycznie wygenerowanym module tests atrybut cfg oznacza konfigurację i informuje Rust, że następny element powinien być uwzględniony tylko przy określonej opcji konfiguracji. W tym przypadku opcją konfiguracji jest test, która jest dostarczana przez Rust do kompilowania i uruchamiania testów. Używając atrybutu cfg, Cargo kompiluje nasz kod testowy tylko wtedy, gdy aktywnie uruchamiamy testy za pomocą cargo test. Dotyczy to wszelkich funkcji pomocniczych, które mogą znajdować się w tym module, oprócz funkcji oznaczonych #[test].
Testy funkcji prywatnych
Istnieje debata w środowisku testowym na temat tego, czy funkcje prywatne powinny być testowane bezpośrednio, a inne języki utrudniają lub uniemożliwiają testowanie funkcji prywatnych. Niezależnie od tego, której ideologii testowania przestrzegasz, zasady prywatności Rust pozwalają testować funkcje prywatne. Rozważ kod w Listingu 11-12 z prywatną funkcją internal_adder.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}Zauważ, że funkcja internal_adder nie jest oznaczona jako pub. Testy to po prostu kod Rust, a moduł tests to tylko kolejny moduł. Jak omówiliśmy w sekcji „Ścieżki do odwoływania się do elementu w drzewie modułów”, elementy w podmodułach mogą używać elementów w swoich modułach nadrzędnych. W tym teście wprowadzamy wszystkie elementy należące do rodzica modułu tests do zasięgu za pomocą use super::*, a następnie test może wywołać internal_adder. Jeśli nie uważasz, że funkcje prywatne powinny być testowane, w Rust nie ma niczego, co by Cię do tego zmuszało.
Testy integracyjne
W Rust testy integracyjne są całkowicie zewnętrzne w stosunku do twojej biblioteki. Używają one twojej biblioteki w taki sam sposób, jak każdy inny kod, co oznacza, że mogą wywoływać tylko funkcje, które są częścią publicznego API twojej biblioteki. Ich celem jest sprawdzenie, czy wiele części twojej biblioteki działa poprawnie razem. Jednostki kodu, które działają poprawnie samodzielnie, mogą mieć problemy po zintegrowaniu, dlatego pokrycie testowe zintegrowanego kodu jest również ważne. Aby utworzyć testy integracyjne, najpierw potrzebujesz katalogu tests.
Katalog tests
Tworzymy katalog tests na najwyższym poziomie naszego katalogu projektu, obok src. Cargo wie, że powinien szukać plików testów integracyjnych w tym katalogu. Możemy następnie tworzyć dowolną liczbę plików testowych, a Cargo skompiluje każdy z tych plików jako oddzielną skrzynkę.
Utwórzmy test integracyjny. Z kodem z Listingu 11-12, który nadal znajduje się w pliku src/lib.rs, utwórz katalog tests i stwórz nowy plik o nazwie tests/integration_test.rs. Struktura katalogów powinna wyglądać następująco:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Wprowadź kod z Listingu 11-13 do pliku tests/integration_test.rs.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}Każdy plik w katalogu tests jest oddzielną skrzynką, więc musimy wprowadzić naszą bibliotekę do zasięgu każdej skrzynki testowej. Z tego powodu na początku kodu dodajemy use adder::add_two;, czego nie potrzebowaliśmy w testach jednostkowych.
Nie musimy adnotować żadnego kodu w tests/integration_test.rs atrybutem #[cfg(test)]. Cargo traktuje katalog tests w specjalny sposób i kompiluje pliki w tym katalogu tylko wtedy, gdy uruchamiamy cargo test. Uruchom cargo test teraz:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Trzy sekcje wyników obejmują testy jednostkowe, testy integracyjne i testy dokumentacji. Zauważ, że jeśli jakikolwiek test w sekcji zakończy się niepowodzeniem, następne sekcje nie zostaną uruchomione. Na przykład, jeśli test jednostkowy zakończy się niepowodzeniem, nie będzie żadnych danych wyjściowych dla testów integracyjnych i dokumentacji, ponieważ te testy zostaną uruchomione tylko wtedy, gdy wszystkie testy jednostkowe przejdą.
Pierwsza sekcja dla testów jednostkowych jest taka sama, jak widzieliśmy wcześniej: jeden wiersz dla każdego testu jednostkowego (jeden o nazwie internal, który dodaliśmy w Listingu 11-12), a następnie wiersz podsumowania dla testów jednostkowych.
Sekcja testów integracyjnych zaczyna się od wiersza Running tests/integration_test.rs. Następnie, dla każdej funkcji testowej w tym teście integracyjnym znajduje się wiersz i wiersz podsumowania wyników testu integracyjnego tuż przed sekcją Doc-tests adder.
Każdy plik testów integracyjnych ma swoją własną sekcję, więc jeśli dodamy więcej plików do katalogu tests, będzie więcej sekcji testów integracyjnych.
Nadal możemy uruchomić konkretną funkcję testową integracji, określając nazwę funkcji testowej jako argument dla cargo test. Aby uruchomić wszystkie testy w konkretnym pliku testowym integracji, użyj argumentu --test cargo test, po którym następuje nazwa pliku:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
To polecenie uruchamia tylko testy z pliku tests/integration_test.rs.
Podmoduły w testach integracyjnych
W miarę dodawania kolejnych testów integracyjnych, możesz chcieć utworzyć więcej plików w katalogu tests, aby pomóc w ich organizacji; na przykład, możesz grupować funkcje testowe według testowanej przez nie funkcjonalności. Jak wspomniano wcześniej, każdy plik w katalogu tests jest kompilowany jako oddzielna skrzynka, co jest przydatne do tworzenia oddzielnych zasięgów, aby dokładniej naśladować sposób, w jaki użytkownicy końcowi będą używać Twojej skrzynki. Oznacza to jednak, że pliki w katalogu tests nie mają tego samego zachowania, co pliki w src, o czym dowiedziałeś się w Rozdziale 7, dotyczącym sposobu dzielenia kodu na moduły i pliki.
Różne zachowanie plików z katalogu tests jest najbardziej zauważalne, gdy masz zestaw funkcji pomocniczych do użycia w wielu plikach testów integracyjnych i próbujesz postępować zgodnie z instrukcjami w sekcji „Dzielenie modułów na różne pliki” w Rozdziale 7, aby wyodrębnić je do wspólnego modułu. Na przykład, jeśli utworzymy tests/common.rs i umieścimy w nim funkcję o nazwie setup, możemy dodać do setup kod, który chcemy wywołać z wielu funkcji testowych w wielu plikach testowych:
Nazwa pliku: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}Kiedy ponownie uruchomimy testy, zobaczymy nową sekcję w wynikach testów dla pliku common.rs, mimo że ten plik nie zawiera żadnych funkcji testowych ani nie wywołaliśmy funkcji setup z żadnego miejsca:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Pojawienie się common w wynikach testów z wyświetlonym running 0 tests nie było tym, czego chcieliśmy. Chcieliśmy tylko udostępnić kod innym plikom testów integracyjnych. Aby uniknąć pojawiania się common w wynikach testów, zamiast tworzenia tests/common.rs, utworzymy tests/common/mod.rs. Katalog projektu wygląda teraz tak:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
Jest to starsza konwencja nazewnictwa, którą Rust również rozumie i o której wspomnieliśmy w sekcji „Alternatywne ścieżki plików” w Rozdziale 7. Nazwanie pliku w ten sposób informuje Rust, aby nie traktował modułu common jako pliku testów integracyjnych. Kiedy przeniesiemy kod funkcji setup do tests/common/mod.rs i usuniemy plik tests/common.rs, sekcja w wynikach testów przestanie się pojawiać. Pliki w podkatalogach katalogu tests nie są kompilowane jako oddzielne skrzynki ani nie mają sekcji w wynikach testów.
Po utworzeniu tests/common/mod.rs możemy go używać z dowolnego pliku testów integracyjnych jako modułu. Oto przykład wywołania funkcji setup z testu it_adds_two w tests/integration_test.rs:
Nazwa pliku: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}Zauważ, że deklaracja mod common; jest taka sama jak deklaracja modułu, którą zademonstrowaliśmy w Listingu 7-21. Następnie w funkcji testowej możemy wywołać funkcję common::setup().
Testy integracyjne dla binarnych skrzynek
Jeśli nasz projekt jest binarną skrzynką, która zawiera tylko plik src/main.rs i nie ma pliku src/lib.rs, nie możemy tworzyć testów integracyjnych w katalogu tests i wprowadzać funkcji zdefiniowanych w pliku src/main.rs do zasięgu za pomocą instrukcji use. Tylko skrzynki biblioteczne udostępniają funkcje, których mogą używać inne skrzynki; skrzynki binarne są przeznaczone do samodzielnego uruchamiania.
Jest to jeden z powodów, dla których projekty Rust, które udostępniają plik binarny, mają prosty plik src/main.rs, który wywołuje logikę znajdującą się w pliku src/lib.rs. Korzystając z tej struktury, testy integracyjne mogą testować skrzynkę biblioteczną za pomocą use, aby udostępnić ważną funkcjonalność. Jeśli ważna funkcjonalność działa, mała ilość kodu w pliku src/main.rs również będzie działać, a ta mała ilość kodu nie musi być testowana.
Podsumowanie
Funkcje testowe Rust zapewniają sposób na określenie, jak kod powinien działać, aby zapewnić, że będzie on nadal działał zgodnie z oczekiwaniami, nawet po wprowadzeniu zmian. Testy jednostkowe sprawdzają różne części biblioteki oddzielnie i mogą testować prywatne szczegóły implementacji. Testy integracyjne sprawdzają, czy wiele części biblioteki działa poprawnie razem, i używają publicznego API biblioteki do testowania kodu w taki sam sposób, w jaki będzie go używał kod zewnętrzny. Mimo że system typów i zasady własności Rust pomagają zapobiegać niektórym rodzajom błędów, testy są nadal ważne, aby zmniejszyć liczbę błędów logicznych związanych z oczekiwanym zachowaniem kodu.
Połączmy wiedzę zdobytą w tym i poprzednich rozdziałach, aby popracować nad projektem!
Projekt I/O: Budowa programu wiersza poleceń
Ten rozdział to podsumowanie wielu umiejętności, których nauczyłeś się do tej pory, oraz eksploracja kilku dodatkowych funkcji biblioteki standardowej. Zbudujemy narzędzie wiersza poleceń, które będzie współpracować z plikowym i wierszowym wejściem/wyjściem, aby przećwiczyć niektóre pojęcia Rust, które masz już opanowane.
Szybkość, bezpieczeństwo, pojedynczy plik binarny i wsparcie międzyplatformowe Rust sprawiają, że jest to idealny język do tworzenia narzędzi wiersza poleceń. Dlatego w naszym projekcie stworzymy własną wersję klasycznego narzędzia wyszukiwania wiersza poleceń grep (globally search a regular expression and print). W najprostszym przypadku grep wyszukuje w określonym pliku określony ciąg znaków. Aby to zrobić, grep przyjmuje jako argumenty ścieżkę do pliku i ciąg znaków. Następnie odczytuje plik, znajduje w nim wiersze zawierające argument ciągu znaków i wypisuje te wiersze.
Po drodze pokażemy, jak sprawić, by nasze narzędzie wiersza poleceń korzystało z funkcji terminala, których używa wiele innych narzędzi wiersza poleceń. Odczytamy wartość zmiennej środowiskowej, aby umożliwić użytkownikowi skonfigurowanie zachowania naszego narzędzia. Będziemy również wypisywać komunikaty o błędach do standardowego strumienia błędów konsoli (stderr) zamiast standardowego wyjścia (stdout), aby na przykład użytkownik mógł przekierować udane dane wyjściowe do pliku, nadal widząc komunikaty o błędach na ekranie.
Jeden z członków społeczności Rust, Andrew Gallant, stworzył już w pełni funkcjonalną, bardzo szybką wersję grep, nazwaną ripgrep. W porównaniu, nasza wersja będzie raczej prosta, ale ten rozdział da ci podstawową wiedzę, której potrzebujesz, aby zrozumieć rzeczywisty projekt, taki jak ripgrep.
Nasz projekt grep połączy wiele pojęć, których nauczyłeś się do tej pory:
- Organizowanie kodu (Rozdział 7)
- Używanie wektorów i ciągów znaków (Rozdział 8)
- Obsługa błędów (Rozdział 9)
- Używanie cech i czasów życia tam, gdzie jest to stosowne (Rozdział 10)
- Pisanie testów (Rozdział 11)
Ponadto pokrótce przedstawimy domknięcia, iteratory i obiekty cech, które Rozdział 13 i Rozdział 18 omówią szczegółowo.
Akceptowanie argumentów wiersza poleceń
Akceptowanie argumentów wiersza poleceń
Utwórzmy nowy projekt, jak zawsze, za pomocą cargo new. Nasz projekt nazwiemy minigrep, aby odróżnić go od narzędzia grep, które możesz już mieć w swoim systemie:
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Pierwszym zadaniem jest sprawienie, aby minigrep akceptował dwa argumenty wiersza poleceń: ścieżkę do pliku i ciąg znaków do wyszukania. Oznacza to, że chcemy móc uruchamiać nasz program za pomocą cargo run, dwóch myślników wskazujących, że następujące argumenty są przeznaczone dla naszego programu, a nie dla cargo, ciągu znaków do wyszukania i ścieżki do pliku, w którym ma się odbywać wyszukiwanie, w następujący sposób:
$ cargo run -- searchstring example-filename.txt
Obecnie program wygenerowany przez cargo new nie może przetwarzać podanych mu argumentów. Istniejące biblioteki na crates.io mogą pomóc w pisaniu programu, który akceptuje argumenty wiersza poleceń, ale ponieważ dopiero uczysz się tej koncepcji, zaimplementujmy tę funkcjonalność samodzielnie.
Odczytywanie wartości argumentów
Aby minigrep mógł odczytywać wartości argumentów wiersza poleceń, które do niego przekazujemy, będziemy potrzebować funkcji std::env::args udostępnionej w standardowej bibliotece Rust. Funkcja ta zwraca iterator argumentów wiersza poleceń przekazanych do minigrep. Wyczerpująco omówimy iteratory w Rozdziale 13. Na razie musisz znać tylko dwa szczegóły dotyczące iteratorów: iteratory produkują serię wartości, a metodę collect możemy wywołać na iteratorze, aby zamienić go w kolekcję, taką jak wektor, która zawiera wszystkie elementy produkowane przez iterator.
Kod z Listingu 12-1 pozwala programowi minigrep odczytać wszelkie argumenty wiersza poleceń, które do niego przekazano, a następnie zebrać wartości w wektor.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
dbg!(args);
}Najpierw wprowadzamy moduł std::env do zasięgu za pomocą instrukcji use, abyśmy mogli używać jego funkcji args. Zauważ, że funkcja std::env::args jest zagnieżdżona na dwóch poziomach modułów. Jak omówiliśmy w Rozdziale 7, w przypadkach, gdy pożądana funkcja jest zagnieżdżona w więcej niż jednym module, zdecydowaliśmy się wprowadzić moduł nadrzędny do zasięgu, a nie funkcję. Dzięki temu możemy łatwo używać innych funkcji z std::env. Jest to również mniej dwuznaczne niż dodawanie use std::env::args, a następnie wywoływanie funkcji tylko za pomocą args, ponieważ args można by łatwo pomylić z funkcją zdefiniowaną w bieżącym module.
W pierwszym wierszu main wywołujemy env::args i natychmiast używamy collect, aby zamienić iterator w wektor zawierający wszystkie wartości wyprodukowane przez iterator. Możemy użyć funkcji collect do tworzenia wielu rodzajów kolekcji, więc jawnie adnotujemy typ args, aby określić, że chcemy wektora ciągów znaków. Chociaż w Rust bardzo rzadko trzeba adnotować typy, collect jest jedną z funkcji, którą często trzeba adnotować, ponieważ Rust nie jest w stanie wywnioskować, jakiego rodzaju kolekcję chcemy.
Na koniec wypisujemy wektor za pomocą makra debugowania. Spróbujmy uruchomić kod najpierw bez argumentów, a następnie z dwoma argumentami:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Zauważ, że pierwszą wartością w wektorze jest "target/debug/minigrep", co jest nazwą naszego pliku binarnego. Odpowiada to zachowaniu listy argumentów w C, pozwalając programom używać nazwy, za pomocą której zostały wywołane, w swoim wykonaniu. Często wygodnie jest mieć dostęp do nazwy programu w przypadku, gdy chcesz ją wypisać w komunikatach lub zmienić zachowanie programu na podstawie aliasu wiersza poleceń, który został użyty do wywołania programu. Ale dla celów tego rozdziału zignorujemy to i zapiszemy tylko dwa argumenty, których potrzebujemy.
Zapisywanie wartości argumentów w zmiennych
Program jest obecnie w stanie uzyskać dostęp do wartości określonych jako argumenty wiersza poleceń. Teraz musimy zapisać wartości tych dwóch argumentów w zmiennych, abyśmy mogli używać ich w pozostałej części programu. Robimy to w Listingu 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}Jak widzieliśmy, wypisując wektor, nazwa programu zajmuje pierwszą wartość w wektorze pod args[0], więc zaczynamy argumenty od indeksu 1. Pierwszym argumentem, który przyjmuje minigrep, jest ciąg znaków, którego szukamy, więc umieszczamy referencję do pierwszego argumentu w zmiennej query. Drugim argumentem będzie ścieżka do pliku, więc umieszczamy referencję do drugiego argumentu w zmiennej file_path.
Tymczasowo wypisujemy wartości tych zmiennych, aby udowodnić, że kod działa zgodnie z naszym zamierzeniem. Uruchommy ten program ponownie z argumentami test i sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Świetnie, program działa! Potrzebne nam wartości argumentów są zapisywane w odpowiednich zmiennych. Później dodamy obsługę błędów, aby poradzić sobie z pewnymi potencjalnie błędnymi sytuacjami, takimi jak brak argumentów podanych przez użytkownika; na razie zignorujemy tę sytuację i zajmiemy się dodaniem możliwości odczytu plików.
Odczytywanie pliku
Odczytywanie pliku
Teraz dodamy funkcjonalność do odczytywania pliku określonego w argumencie file_path. Najpierw potrzebujemy przykładowego pliku do przetestowania: użyjemy pliku z niewielką ilością tekstu na wielu liniach z kilkoma powtórzonymi słowami. Listing 12-3 zawiera wiersz Emily Dickinson, który będzie dobrze działał! Utwórz plik o nazwie poem.txt w katalogu głównym projektu i wprowadź wiersz „I’m Nobody! Who are you?”
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Gdy tekst jest już na miejscu, edytuj src/main.rs i dodaj kod do odczytywania pliku, jak pokazano w Listingu 12-4.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}Najpierw wprowadzamy do zasięgu odpowiednią część biblioteki standardowej za pomocą instrukcji use: Potrzebujemy std::fs do obsługi plików.
W main nowa instrukcja fs::read_to_string przyjmuje file_path, otwiera ten plik i zwraca wartość typu std::io::Result<String>, która zawiera zawartość pliku.
Następnie ponownie dodajemy tymczasową instrukcję println!, która wypisuje wartość contents po odczytaniu pliku, abyśmy mogli sprawdzić, czy program działa do tej pory.
Uruchommy ten kod z dowolnym ciągiem znaków jako pierwszym argumentem wiersza poleceń (ponieważ nie zaimplementowaliśmy jeszcze części wyszukiwania) i plikiem poem.txt jako drugim argumentem:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Świetnie! Kod odczytał, a następnie wypisał zawartość pliku. Ale kod ma kilka wad. W tej chwili funkcja main pełni wiele ról: parsuje argumenty i odczytuje pliki. W miarę rozrostu programu, liczba oddzielnych zadań obsługiwanych przez funkcję main będzie wzrastać. W miarę zwiększania odpowiedzialności funkcji, staje się ona trudniejsza do zrozumienia, trudniejsza do testowania i trudniejsza do zmiany bez uszkodzenia jednej z jej części. Najlepiej jest rozdzielić funkcjonalność tak, aby każda funkcja była odpowiedzialna tylko za jedno zadanie.
Ten problem wiąże się również z drugim problemem: chociaż query i file_path są zmiennymi konfiguracyjnymi naszego programu, zmienne takie jak contents są używane do wykonywania logiki programu. Im dłuższy staje się main, tym więcej zmiennych będziemy musieli wprowadzić do zasięgu; im więcej zmiennych mamy w zasięgu, tym trudniej będzie śledzić cel każdej z nich. Najlepiej jest zgrupować zmienne konfiguracyjne w jedną strukturę, aby ich cel był jasny.
Trzeci problem polega na tym, że użyliśmy expect do wypisania komunikatu o błędzie, gdy odczyt pliku się nie powiedzie, ale komunikat o błędzie wypisuje tylko Should have been able to read the file. Odczyt pliku może zakończyć się niepowodzeniem na wiele sposobów: na przykład, plik może brakować, lub możemy nie mieć uprawnień do jego otwarcia. W tej chwili, niezależnie od sytuacji, wypisywalibyśmy ten sam komunikat o błędzie dla wszystkiego, co nie dałoby użytkownikowi żadnych informacji!
Po czwarte, używamy expect do obsługi błędu, a jeśli użytkownik uruchomi nasz program bez określenia wystarczającej liczby argumentów, otrzyma błąd index out of bounds z Rust, który nie wyjaśnia jasno problemu. Najlepiej byłoby, gdyby cały kod obsługi błędów znajdował się w jednym miejscu, tak aby przyszli konserwatorzy mieli tylko jedno miejsce do konsultowania kodu, jeśli logika obsługi błędów wymagała zmiany. Posiadanie całego kodu obsługi błędów w jednym miejscu zapewni również, że będziemy wypisywać komunikaty, które będą zrozumiałe dla naszych użytkowników końcowych.
Zajmiemy się tymi czterema problemami, refaktoryzując nasz projekt.
Refaktoryzacja w celu poprawy modułowości i obsługi błędów
Refaktoryzacja w celu poprawy modułowości i obsługi błędów
Aby ulepszyć nasz program, naprawimy cztery problemy związane ze strukturą
programu i sposobem obsługi potencjalnych błędów. Po pierwsze, nasza funkcja
main wykonuje teraz dwa zadania: parsuje argumenty i odczytuje pliki. W
miarę rozwoju programu liczba oddzielnych zadań, które obsługuje funkcja
main, będzie rosła. Gdy funkcja zyskuje nowe obowiązki, staje się trudniejsza
do zrozumienia, trudniejsza do testowania i trudniejsza do zmiany bez
uszkodzenia jednej z jej części. Najlepiej jest oddzielić funkcjonalność,
tak aby każda funkcja była odpowiedzialna za jedno zadanie.
Ten problem wiąże się również z drugim problemem: chociaż query i
file_path są zmiennymi konfiguracyjnymi naszego programu, zmienne takie jak
contents są używane do wykonywania logiki programu. Im dłuższy staje się
main, tym więcej zmiennych będziemy musieli wprowadzić do zakresu; im więcej
zmiennych mamy w zakresie, tym trudniej będzie śledzić cel każdej z nich.
Najlepiej jest pogrupować zmienne konfiguracyjne w jedną strukturę, aby ich cel
był jasny.
Trzeci problem polega na tym, że użyliśmy expect do wyświetlenia
komunikatu o błędzie, gdy odczyt pliku nie powiódł się, ale komunikat o
błędzie po prostu wyświetla Should have been able to read the file. Odczyt
pliku może zakończyć się niepowodzeniem na wiele sposobów: na przykład plik
może brakować lub możemy nie mieć uprawnień do jego otwarcia. Obecnie,
niezależnie od sytuacji, wyświetlalibyśmy ten sam komunikat o błędzie dla
wszystkiego, co nie dostarczyłoby użytkownikowi żadnych informacji!
Po czwarte, używamy expect do obsługi błędu, a jeśli użytkownik uruchomi nasz
program bez podania wystarczającej liczby argumentów, otrzyma błąd index out of bounds z Rusta, który nie wyjaśnia jasno problemu. Byłoby najlepiej,
gdyby cały kod obsługi błędów znajdował się w jednym miejscu, tak aby przyszli
utrzymujący mieli tylko jedno miejsce do konsultowania kodu, jeśli logika
obsługi błędów wymagałaby zmiany. Posiadanie całego kodu obsługi błędów w
jednym miejscu zapewni również, że wyświetlamy komunikaty, które będą
zrozumiałe dla naszych użytkowników końcowych.
Rozwiążemy te cztery problemy, refaktoryzując nasz projekt.
Rozdzielanie odpowiedzialności w projektach binarnych
Problem organizacyjny polegający na przypisywaniu funkcji main
odpowiedzialności za wiele zadań jest powszechny w wielu projektach
binarnych. W rezultacie wielu programistów Rust uważa za przydatne
rozdzielenie różnych aspektów programu binarnego, gdy funkcja main staje
się zbyt duża. Proces ten obejmuje następujące kroki:
- Podziel program na pliki main.rs i lib.rs i przenieś logikę programu do lib.rs.
- Dopóki logika parsowania wiersza poleceń jest mała, może pozostać w
funkcji
main. - Kiedy logika parsowania wiersza poleceń zaczyna się komplikować, wyodrębnij
ją z funkcji
maindo innych funkcji lub typów.
Obowiązki, które pozostają w funkcji main po tym procesie, powinny być
ograniczone do następujących:
- Wywołanie logiki parsowania wiersza poleceń z wartościami argumentów
- Ustawienie wszelkich innych konfiguracji
- Wywołanie funkcji
runw lib.rs - Obsługa błędu, jeśli
runzwróci błąd
Ten wzorzec polega na rozdzieleniu odpowiedzialności: main.rs zajmuje się
uruchamianiem programu, a lib.rs obsługuje całą logikę bieżącego zadania.
Ponieważ nie można bezpośrednio testować funkcji main, ta struktura pozwala
testować całą logikę programu, przenosząc ją poza funkcję main. Kod,
który pozostaje w funkcji main, będzie wystarczająco mały, aby zweryfikować
jego poprawność poprzez odczytanie. Przeróbmy nasz program, postępując
zgodnie z tym procesem.
Wyodrębnianie parsera argumentów
Wyodrębnimy funkcjonalność parsowania argumentów do funkcji, którą wywoła main.
Listing 12-5 pokazuje nowy początek funkcji main, która wywołuje nową funkcję
parse_config, którą zdefiniujemy w src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}parse_config z mainNadal zbieramy argumenty wiersza poleceń do wektora, ale zamiast przypisywać
wartość argumentu pod indeksem 1 do zmiennej query i wartość argumentu pod
indeksem 2 do zmiennej file_path w funkcji main, przekazujemy cały wektor
do funkcji parse_config. Funkcja parse_config zawiera następnie logikę,
która określa, który argument trafia do której zmiennej i przekazuje wartości
z powrotem do main. Nadal tworzymy zmienne query i file_path w main,
ale main nie jest już odpowiedzialny za określanie, jak argumenty wiersza
poleceń i zmienne odpowiadają sobie.
Ta przeróbka może wydawać się przesadna dla naszego małego programu, ale refaktoryzujemy ją małymi, przyrostowymi krokami. Po dokonaniu tej zmiany, uruchom program ponownie, aby sprawdzić, czy parsowanie argumentów nadal działa. Dobrze jest często sprawdzać postępy, aby pomóc zidentyfikować przyczynę problemów, gdy się pojawią.
Grupowanie wartości konfiguracyjnych
Możemy podjąć kolejny mały krok, aby jeszcze bardziej ulepszyć funkcję
parse_config. W tej chwili zwracamy krotkę, ale natychmiast rozbijamy tę
krotkę ponownie na pojedyncze części. Jest to znak, że być może nie mamy
jeszcze odpowiedniej abstrakcji.
Inny wskaźnik, który pokazuje, że jest miejsce na ulepszenia, to część config
w parse_config, co implikuje, że dwie zwracane wartości są powiązane i obie
są częścią jednej wartości konfiguracyjnej. Obecnie nie przekazujemy tego
znaczenia w strukturze danych inaczej niż poprzez grupowanie dwóch wartości w
krotkę; zamiast tego umieścimy dwie wartości w jednej strukturze i nadamy
każdemu z pól struktury znaczącą nazwę. Zrobienie tego ułatwi przyszłym
utrzymującym ten kod zrozumienie, jak różne wartości są ze sobą powiązane i
jaki jest ich cel.
Listing 12-6 pokazuje ulepszenia funkcji parse_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}parse_config w celu zwrócenia instancji struktury ConfigDodaliśmy strukturę o nazwie Config z polami query i file_path. Sygnatura
parse_config wskazuje teraz, że zwraca wartość Config. W ciele parse_config,
gdzie wcześniej zwracaliśmy wycinki stringów, które odwoływały się do wartości
String w args, teraz definiujemy Config tak, aby zawierał własne wartości
String. Zmienna args w main jest właścicielem wartości argumentów i tylko
pozwala funkcji parse_config je pożyczyć, co oznacza, że naruszylibyśmy zasady
pożyczania Rusta, gdyby Config próbowało przejąć własność wartości w args.
Istnieje wiele sposobów zarządzania danymi String; najłatwiejsza, choć
nieco nieefektywna, droga to wywołanie metody clone na wartościach. Spowoduje
to pełną kopię danych dla instancji Config, co zajmuje więcej czasu i pamięci
niż przechowywanie referencji do danych ciągu znaków. Jednak klonowanie danych
również sprawia, że nasz kod jest bardzo prosty, ponieważ nie musimy
zarządzać czasami życia referencji; w tych okolicznościach, rezygnacja z
nieco wydajności na rzecz prostoty jest opłacalnym kompromisem.
Kompromisy związane z używaniem clone
Wielu programistów Rusta ma tendencję do unikania używania clone do
naprawiania problemów z własnością ze względu na jego koszt wykonawczy.
W Rozdziale 13 dowiesz się, jak używać bardziej
efektywnych metod w tego typu sytuacjach. Ale na razie w porządku jest
kopiowanie kilku ciągów znaków, aby kontynuować postęp, ponieważ te kopie
zrobisz tylko raz, a ścieżka pliku i ciąg zapytania są bardzo małe. Lepiej
mieć działający program, który jest nieco nieefektywny, niż próbować
hiperoptymalizować kod za pierwszym razem. W miarę zdobywania doświadczenia
z Rustem, łatwiej będzie zacząć od najbardziej efektywnego rozwiązania, ale na
razie, używanie clone jest całkowicie akceptowalne.
Zaktualizowaliśmy main tak, aby umieszczał instancję Config zwróconą przez
parse_config w zmiennej o nazwie config, i zaktualizowaliśmy kod, który
wcześniej używał oddzielnych zmiennych query i file_path, tak aby teraz
używał pól struktury Config.
Teraz nasz kod jaśniej przekazuje, że query i file_path są ze sobą
powiązane i że ich celem jest konfigurowanie działania programu. Każdy kod,
który używa tych wartości, wie, że znajdzie je w instancji config w polach
nazwanych zgodnie z ich przeznaczeniem.
Tworzenie konstruktora dla Config
Do tej pory wyodrębniliśmy logikę odpowiedzialną za parsowanie argumentów
wiersza poleceń z main i umieściliśmy ją w funkcji parse_config. Dzięki
temu zauważyliśmy, że wartości query i file_path były ze sobą powiązane,
i ten związek powinien być przekazany w naszym kodzie. Następnie dodaliśmy
strukturę Config, aby nazwać powiązane przeznaczenie query i file_path
oraz móc zwracać nazwy wartości jako nazwy pól struktury z funkcji
parse_config.
Skoro teraz celem funkcji parse_config jest stworzenie instancji Config,
możemy zmienić parse_config z prostej funkcji na funkcję o nazwie new,
która jest skojarzona ze strukturą Config. Ta zmiana sprawi, że kod będzie
bardziej idiomatyczny. Możemy tworzyć instancje typów w standardowej bibliotece,
takich jak String, wywołując String::new. Podobnie, zmieniając
parse_config na funkcję new skojarzoną z Config, będziemy mogli tworzyć
instancje Config, wywołując Config::new. Listing 12-7 pokazuje zmiany, które
musimy wprowadzić.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}parse_config na Config::newZaktualizowaliśmy main, gdzie wywoływaliśmy parse_config, aby zamiast tego
wywoływać Config::new. Zmieniliśmy nazwę parse_config na new i przenieśliśmy
ją do bloku impl, co wiąże funkcję new z Config. Spróbuj ponownie
skompilować ten kod, aby upewnić się, że działa.
Naprawa obsługi błędów
Teraz zajmiemy się naprawą obsługi błędów. Przypomnijmy, że próba uzyskania
dostępu do wartości w wektorze args pod indeksem 1 lub 2 spowoduje panikę
programu, jeśli wektor zawiera mniej niż trzy elementy. Spróbuj uruchomić
program bez żadnych argumentów; będzie to wyglądało tak:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Linia index out of bounds: the len is 1 but the index is 1 to komunikat o
błędzie przeznaczony dla programistów. Nie pomoże on naszym użytkownikom
końcowym zrozumieć, co powinni zrobić zamiast tego. Naprawmy to teraz.
Ulepszanie komunikatu o błędzie
W Listingu 12-8 dodajemy w funkcji new sprawdzenie, czy wycinek jest
wystarczająco długi, zanim uzyska dostęp do indeksu 1 i 2. Jeśli wycinek nie
jest wystarczająco długi, program panikuje i wyświetla lepszy komunikat o błędzie.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Ten kod jest podobny do funkcji Guess::new, którą napisaliśmy w Listingu
9-13, gdzie wywołaliśmy panic!, gdy
argument value był poza zakresem prawidłowych wartości. Zamiast sprawdzać
zakres wartości tutaj, sprawdzamy, czy długość args wynosi co najmniej 3,
a reszta funkcji może działać, zakładając, że ten warunek został spełniony.
Jeśli args ma mniej niż trzy elementy, ten warunek będzie true i wywołamy
makro panic!, aby natychmiast zakończyć program.
Z tymi dodatkowymi kilkoma liniami kodu w new, uruchommy program ponownie bez
żadnych argumentów, aby zobaczyć, jak teraz wygląda błąd:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ten wynik jest lepszy: mamy teraz rozsądny komunikat o błędzie. Mamy jednak
także zbędne informacje, których nie chcemy przekazywać naszym użytkownikom.
Być może technika, której użyliśmy w Listingu 9-13, nie jest tutaj najlepsza:
wywołanie panic! jest bardziej odpowiednie dla problemu programistycznego niż
problemu z użyciem, jak omówiono w Rozdziale
9. Zamiast tego, użyjemy innej
techniki, o której dowiedziałeś się w Rozdziale 9 – zwracania
Result, który wskazuje na sukces lub błąd.
Zwracanie Result zamiast wywoływania panic!
Zamiast tego możemy zwrócić wartość Result, która będzie zawierała instancję
Config w przypadku sukcesu i będzie opisywać problem w przypadku błędu.
Zmienimy również nazwę funkcji z new na build, ponieważ wielu
programistów oczekuje, że funkcje new nigdy nie zawiodą. Kiedy Config::build
komunikuje się z main, możemy użyć typu Result, aby zasygnalizować,
że wystąpił problem. Następnie możemy zmienić main, aby przekształcić
wariant Err w bardziej praktyczny błąd dla naszych użytkowników, bez
otaczającego tekstu o thread 'main' i RUST_BACKTRACE, które powoduje
wywołanie panic!.
Listing 12-9 pokazuje zmiany, które musimy wprowadzić w wartości zwracanej
funkcji, którą teraz nazywamy Config::build, oraz w ciele funkcji
potrzebnym do zwrócenia Result. Zauważ, że to się nie skompiluje, dopóki nie
zaktualizujemy również main, co zrobimy w następnym listingu.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Result z Config::buildNasza funkcja build zwraca Result z instancją Config w przypadku
pomyślności i literałem ciągu znaków w przypadku błędu. Nasze wartości błędów
będą zawsze literałami ciągu znaków, które mają czas życia 'static.
Dokonaliśmy dwóch zmian w ciele funkcji: zamiast wywoływać panic! gdy
użytkownik nie przekaże wystarczającej liczby argumentów, teraz zwracamy
wartość Err, a wartość zwracaną Config opakowaliśmy w Ok. Te zmiany
sprawiają, że funkcja jest zgodna z nowym podpisem typu.
Zwracanie wartości Err z Config::build pozwala funkcji main obsłużyć
wartość Result zwróconą z funkcji build i czysto zakończyć proces w
przypadku błędu.
Wywoływanie Config::build i obsługa błędów
Aby obsłużyć przypadek błędu i wyświetlić komunikat zrozumiały dla użytkownika,
musimy zaktualizować main w celu obsługi Result zwracanego przez
Config::build, jak pokazano w Listingu 12-10. Przejmiemy również
odpowiedzialność za zakończenie narzędzia wiersza poleceń z niezerowym kodem
błędu zamiast panic! i zaimplementujemy to ręcznie. Niezerowy status
wyjścia jest konwencją sygnalizującą procesowi, który wywołał nasz program, że
program zakończył działanie ze stanem błędu.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Config zawiedzieW tym listingu użyliśmy metody, której jeszcze szczegółowo nie omówiliśmy:
unwrap_or_else, która jest zdefiniowana w Result<T, E> przez standardową
bibliotekę. Użycie unwrap_or_else pozwala nam zdefiniować niestandardową,
nie-panic! obsługę błędów. Jeśli Result jest wartością Ok, zachowanie
tej metody jest podobne do unwrap: zwraca wewnętrzną wartość, którą opakowuje
Ok. Jednak jeśli wartość jest wartością Err, ta metoda wywołuje kod w
zamknięciu, które jest anonimową funkcją, którą definiujemy i przekazujemy jako
argument do unwrap_or_else. Zamknięcia omówimy bardziej szczegółowo w
Rozdziale 13. Na razie wystarczy wiedzieć, że
unwrap_or_else przekaże wewnętrzną wartość Err, która w tym przypadku jest
statycznym ciągiem znaków "not enough arguments", który dodaliśmy w Listingu
12-9, do naszego zamknięcia w argumencie err, który pojawia się między
pionowymi kreskami. Kod w zamknięciu może następnie użyć wartości err, gdy
będzie działał.
Dodaliśmy nową linię use, aby wprowadzić process ze standardowej biblioteki
do zakresu. Kod w zamknięciu, który zostanie uruchomiony w przypadku błędu,
składa się tylko z dwóch linii: wyświetlamy err, a następnie wywołujemy
process::exit. Funkcja process::exit natychmiast zatrzyma program i zwróci
liczbę, która została przekazana jako kod statusu wyjścia. Jest to podobne do
obsługi opartej na panic!, której użyliśmy w Listingu 12-8, ale nie
otrzymujemy już wszystkich dodatkowych danych wyjściowych. Spróbujmy:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Świetnie! Ten wynik jest znacznie bardziej przyjazny dla naszych użytkowników.
Wyodrębnianie logiki z funkcji main
Teraz, gdy zakończyliśmy refaktoryzację parsowania konfiguracji, zajmijmy się
logiką programu. Jak stwierdziliśmy w sekcji „Rozdzielanie odpowiedzialności w
projektach binarnych”, wyodrębnimy funkcję o nazwie run, która będzie zawierała całą
logikę znajdującą się obecnie w funkcji main, niezwiązaną z konfigurowaniem
ani obsługą błędów. Po zakończeniu funkcja main będzie zwięzła i łatwa do
weryfikacji poprzez inspekcję, a my będziemy mogli pisać testy dla całej
pPozostałej logiki.
Listing 12-11 pokazuje niewielką, przyrostową poprawę w wyodrębnianiu funkcji
run.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run zawierającej resztę logiki programuFunkcja run zawiera teraz całą pozostałą logikę z main, poczynając od
樑odczytu pliku. Funkcja run przyjmuje instancję Config jako argument.
Zwracanie błędów z funkcji run
Po oddzieleniu pozostałej logiki programu do funkcji run, możemy poprawić
obsługę błędów, tak jak to zrobiliśmy z Config::build w Listingu 12-9.
Zamiast pozwalać programowi na panikę poprzez wywołanie expect, funkcja
run będzie zwracać Result<T, E>, gdy coś pójdzie nie tak. Pozwoli to nam
dalej skonsolidować logikę obsługi błędów w main w sposób przyjazny dla
użytkownika. Listing 12-12 pokazuje zmiany, które musimy wprowadzić w sygnaturze
i ciele run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run na zwracającą ResultWprowadziliśmy tu trzy istotne zmiany. Po pierwsze, zmieniliśmy typ zwracany
funkcji run na Result<(), Box<dyn Error>>. Ta funkcja wcześniej zwracała
typ jednostkowy (), i zachowujemy to jako wartość zwracaną w przypadku Ok.
Jako typ błędu użyliśmy obiektu cechy Box<dyn Error> (i wprowadziliśmy
std::error::Error do zakresu za pomocą instrukcji use na górze). Obiekty
cech omówimy w Rozdziale 18. Na razie wystarczy wiedzieć,
że Box<dyn Error> oznacza, że funkcja zwróci typ, który implementuje cechę
Error, ale nie musimy określać, jaki konkretny typ będzie miała wartość
zwracana. Daje nam to elastyczność w zwracaniu wartości błędów, które mogą być
różnych typów w różnych przypadkach błędów. Słowo kluczowe dyn to skrót od
dynamiczny.
Po drugie, usunęliśmy wywołanie expect na rzecz operatora ?, o czym
mówiliśmy w Rozdziale 9. Zamiast panikować
w przypadku błędu, ? zwróci wartość błędu z bieżącej funkcji, aby wywołujący
mógł ją obsłużyć.
Po trzecie, funkcja run zwraca teraz wartość Ok w przypadku sukcesu.
Zadeklarowaliśmy typ sukcesu funkcji run jako () w sygnaturze, co oznacza,
że musimy opakować wartość typu jednostkowego w wartość Ok. Ta składnia
Ok(()) może na początku wydawać się nieco dziwna. Ale użycie () w ten sposób
jest idiomatycznym sposobem wskazania, że wywołujemy run tylko dla jego
efektów ubocznych; nie zwraca on wartości, której potrzebujemy.
Kiedy uruchomisz ten kod, skompiluje się, ale wyświetli ostrzeżenie:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust informuje nas, że nasz kod zignorował wartość Result i że wartość
Result może wskazywać na wystąpienie błędu. Ale nie sprawdzamy, czy wystąpił
błąd, a kompilator przypomina nam, że prawdopodobnie zamierzaliśmy umieścić
tutaj jakiś kod do obsługi błędów! Naprawmy ten problem teraz.
Obsługa błędów zwracanych przez run w main
Sprawdzimy błędy i obsłużymy je za pomocą techniki podobnej do tej, której
użyliśmy z Config::build w Listingu 12-10, ale z niewielką różnicą:
Nazwa pliku: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Używamy if let zamiast unwrap_or_else, aby sprawdzić, czy run zwraca
wartość Err, i aby wywołać process::exit(1), jeśli tak. Funkcja run nie
zwraca wartości, którą chcemy unwrap w taki sam sposób, w jaki
Config::build zwraca instancję Config. Ponieważ run zwraca () w
przypadku sukcesu, zależy nam tylko na wykryciu błędu, więc nie potrzebujemy
unwrap_or_else, aby zwrócić rozpakowaną wartość, która byłaby tylko ().
Ciała funkcji if let i unwrap_or_else są w obu przypadkach takie same:
wyświetlamy błąd i wychodzimy.
Podział kodu na bibliotekę typu “crate”
Nasz projekt minigrep wygląda do tej pory dobrze! Teraz podzielimy plik
src/main.rs i umieścimy część kodu w pliku src/lib.rs. W ten sposób możemy
testować kod i mieć plik src/main.rs z mniejszą odpowiedzialnością.
Zdefiniujmy kod odpowiedzialny za wyszukiwanie tekstu w src/lib.rs zamiast w
src/main.rs, co pozwoli nam (lub każdemu innemu, kto używa naszej biblioteki
minigrep) wywołać funkcję wyszukiwania z większej liczby kontekstów niż nasz
plik binarny minigrep.
Najpierw zdefiniujmy sygnaturę funkcji search w src/lib.rs, jak pokazano w
Listingu 12-13, z ciałem, które wywołuje makro unimplemented!. Wyjaśnimy
sygnaturę bardziej szczegółowo, gdy wypełnimy implementację.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}search w src/lib.rsUżyliśmy słowa kluczowego pub w definicji funkcji, aby oznaczyć search jako
część publicznego API naszego pakietu bibliotecznego. Mamy teraz pakiet
biblioteczny, którego możemy używać z naszego pakietu binarnego i który możemy
testować!
Teraz musimy wprowadzić kod zdefiniowany w src/lib.rs do zakresu pakietu binarnego w src/main.rs i wywołać go, jak pokazano w Listingu 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}search z biblioteki minigrep w src/main.rsDodajemy linię use minigrep::search, aby wprowadzić funkcję search z
pakietu bibliotecznego do zakresu pakietu binarnego. Następnie, w funkcji run,
zamiast wypisywać zawartość pliku, wywołujemy funkcję search i przekazujemy
wartość config.query oraz contents jako argumenty. Następnie run użyje
pętli for do wypisania każdej linii zwróconej przez search, która
dopasowała zapytanie. To również dobry moment na usunięcie wywołań
println! w funkcji main, które wyświetlały zapytanie i ścieżkę pliku, tak
aby nasz program wyświetlał tylko wyniki wyszukiwania (jeśli nie wystąpiły
błędy).
Zauważ, że funkcja wyszukiwania będzie zbierać wszystkie wyniki do zwracanego wektora, zanim rozpocznie się jakiekolwiek drukowanie. Ta implementacja może być powolna w wyświetlaniu wyników podczas wyszukiwania w dużych plikach, ponieważ wyniki nie są drukowane w miarę ich znajdowania; omówimy możliwy sposób rozwiązania tego problemu za pomocą iteratorów w Rozdziale 13.
Uff! To była ciężka praca, ale przygotowaliśmy się na przyszłość. Teraz o wiele łatwiej jest obsługiwać błędy, a kod uczyniliśmy bardziej modułowym. Prawie cała nasza praca będzie wykonywana w src/lib.rs od teraz.
Wykorzystajmy tę nowo odkrytą modułowość, robiąc coś, co byłoby trudne ze starym kodem, ale jest łatwe z nowym: napiszemy kilka testów!
Dodawanie funkcjonalności z wykorzystaniem programowania sterowanego testami
Dodawanie funkcjonalności z wykorzystaniem programowania sterowanego testami
Teraz, gdy logika wyszukiwania znajduje się w pliku src/lib.rs oddzielnie od funkcji main, znacznie łatwiej jest pisać testy dla podstawowej funkcjonalności naszego kodu. Możemy wywoływać funkcje bezpośrednio z różnymi argumentami i sprawdzać wartości zwracane bez konieczności wywoływania naszego pliku binarnego z wiersza poleceń.
W tej sekcji dodamy logikę wyszukiwania do programu minigrep przy użyciu procesu programowania sterowanego testami (TDD) zgodnie z następującymi krokami:
- Napisz test, który zawodzi, i uruchom go, aby upewnić się, że zawodzi z oczekiwanej przyczyny.
- Napisz lub zmodyfikuj wystarczająco dużo kodu, aby nowy test przeszedł.
- Zrefaktoruj kod, który właśnie dodałeś lub zmieniłeś, i upewnij się, że testy nadal przechodzą.
- Powtórz od kroku 1!
Chociaż jest to tylko jeden z wielu sposobów pisania oprogramowania, TDD może pomóc w kierowaniu projektem kodu. Pisanie testu przed napisaniem kodu, który sprawia, że test przechodzi, pomaga utrzymać wysokie pokrycie testami przez cały proces.
Będziemy testować implementację funkcjonalności, która faktycznie będzie wyszukiwać ciąg zapytania w zawartości pliku i generować listę pasujących wierszy. Tę funkcjonalność dodamy w funkcji nazwanej search.
Pisanie nieudanego testu
W pliku src/lib.rs dodamy moduł tests z funkcją testową, tak jak to zrobiliśmy w Rozdziale 11. Funkcja testowa określa zachowanie, jakie chcemy, aby funkcja search miała: Będzie przyjmować zapytanie i tekst do przeszukania, i będzie zwracać tylko te wiersze z tekstu, które zawierają zapytanie. Listing 12-15 pokazuje ten test.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Ten test wyszukuje ciąg "duct". Tekst, który przeszukujemy, ma trzy wiersze, z których tylko jeden zawiera "duct" (zauważ, że ukośnik wsteczny po otwierającym cudzysłowie podwójnym informuje Rusta, aby nie umieszczał znaku nowej linii na początku zawartości tego literału ciągu znaków). Twierdzimy, że wartość zwrócona przez funkcję search zawiera tylko oczekiwany wiersz.
Jeśli uruchomimy ten test, obecnie się nie powiedzie, ponieważ makro unimplemented! panikuje z komunikatem „not implemented”. Zgodnie z zasadami TDD, zrobimy mały krok, dodając wystarczająco dużo kodu, aby test nie panikował podczas wywoływania funkcji, definiując funkcję search tak, aby zawsze zwracała pusty wektor, jak pokazano w Listing 12-16. Następnie test powinien się skompilować i zakończyć niepowodzeniem, ponieważ pusty wektor nie pasuje do wektora zawierającego wiersz "safe, fast, productive.".
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Teraz omówmy, dlaczego musimy zdefiniować jawną żywotność 'a w sygnaturze search i użyć tej żywotności z argumentem contents i wartością zwracaną. Przypomnij sobie z Rozdziału 10, że parametry żywotności określają, która żywotność argumentu jest połączona z żywotnością wartości zwracanej. W tym przypadku wskazujemy, że zwrócony wektor powinien zawierać wycinki ciągów znaków, które odwołują się do wycinków argumentu contents (a nie argumentu query).
Innymi słowy, mówimy Rustowi, że dane zwrócone przez funkcję search będą żyły tak długo, jak dane przekazane do funkcji search w argumencie contents. To jest ważne! Dane, do których odwołuje się wycinek, muszą być ważne, aby referencja była ważna; jeśli kompilator założy, że tworzymy wycinki ciągów znaków z query zamiast z contents, to jego sprawdzanie bezpieczeństwa będzie nieprawidłowe.
Jeśli zapomnimy o adnotacjach żywotności i spróbujemy skompilować tę funkcję, otrzymamy następujący błąd:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust nie może wiedzieć, który z dwóch parametrów jest nam potrzebny do wyjścia, więc musimy mu to jawnie powiedzieć. Zauważ, że tekst pomocy sugeruje określenie tego samego parametru czasu życia dla wszystkich parametrów i typu wyjściowego, co jest nieprawidłowe! Ponieważ contents jest parametrem, który zawiera cały nasz tekst i chcemy zwrócić pasujące fragmenty tego tekstu, wiemy, że contents jest jedynym parametrem, który powinien być połączony z wartością zwracaną za pomocą składni czasu życia.
Inne języki programowania nie wymagają łączenia argumentów z wartościami zwracanymi w sygnaturze, ale ta praktyka z czasem stanie się łatwiejsza. Możesz porównać ten przykład z przykładami w sekcji „Walidowanie referencji za pomocą żywotności” w Rozdziale 10.
Pisanie kodu, aby test przeszedł
Obecnie nasz test zawodzi, ponieważ zawsze zwracamy pusty wektor. Aby to naprawić i zaimplementować search, nasz program musi wykonać następujące kroki:
- Iteruj przez każdy wiersz zawartości.
- Sprawdź, czy wiersz zawiera nasz ciąg zapytania.
- Jeśli tak, dodaj go do listy wartości, które zwracamy.
- Jeśli nie, nie rób nic.
- Zwróć listę pasujących wyników.
Przejdźmy przez każdy krok, zaczynając od iteracji przez wiersze.
Iterowanie przez wiersze za pomocą metody lines
Rust ma przydatną metodę do obsługi iteracji po ciągach znaków wiersz po wierszu, wygodnie nazwaną lines, która działa tak, jak pokazano w Listing 12-17. Zauważ, że to jeszcze się nie skompiluje.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Metoda lines zwraca iterator. Dogłębnie omówimy iteratory w Rozdziale 13. Ale przypomnij sobie, że widziałeś ten sposób używania iteratora w Listing 3-5, gdzie używaliśmy pętli for z iteratorem, aby wykonać kod na każdym elemencie w kolekcji.
Wyszukiwanie zapytania w każdym wierszu
Następnie sprawdzimy, czy bieżący wiersz zawiera nasz ciąg zapytania. Na szczęście ciągi znaków mają przydatną metodę o nazwie contains, która to dla nas robi! Dodaj wywołanie metody contains w funkcji search, jak pokazano w Listing 12-18. Zauważ, że to nadal się nie skompiluje.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}W tej chwili budujemy funkcjonalność. Aby kod się skompilował, musimy zwrócić wartość z ciała, zgodnie z tym, co wskazaliśmy w sygnaturze funkcji.
Przechowywanie pasujących wierszy
Aby zakończyć tę funkcję, potrzebujemy sposobu na przechowywanie pasujących wierszy, które chcemy zwrócić. W tym celu możemy stworzyć modyfikowalny wektor przed pętlą for i wywołać metodę push, aby zapisać line w wektorze. Po pętli for zwracamy wektor, jak pokazano w Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Teraz funkcja search powinna zwracać tylko wiersze zawierające query, a nasz test powinien przejść. Uruchommy test:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Nasz test przeszedł, więc wiemy, że działa!
W tym momencie moglibyśmy rozważyć możliwości refaktoryzacji implementacji funkcji wyszukiwania, jednocześnie utrzymując testy przechodzące, aby zachować tę samą funkcjonalność. Kod w funkcji wyszukiwania nie jest zbyt zły, ale nie wykorzystuje niektórych przydatnych funkcji iteratorów. Wrócimy do tego przykładu w Rozdziale 13, gdzie szczegółowo omówimy iteratory i przyjrzymy się, jak go ulepszyć.
Teraz cały program powinien działać! Wypróbujmy go najpierw ze słowem, które powinno zwrócić dokładnie jeden wiersz z wiersza Emily Dickinson: frog.
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Świetnie! Teraz spróbujmy słowa, które będzie pasować do wielu wierszy, na przykład body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
I na koniec, upewnijmy się, że nie otrzymujemy żadnych wierszy, gdy szukamy słowa, którego nie ma w wierszu, na przykład monomorfization:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Doskonale! Zbudowaliśmy naszą mini wersję klasycznego narzędzia i wiele nauczyliśmy się o tym, jak strukturyzować aplikacje. Nauczyliśmy się również trochę o wejściu i wyjściu plikowym, żywotności, testowaniu i parsowaniu wiersza poleceń.
Aby zakończyć ten projekt, krótko zademonstrujemy, jak pracować ze zmiennymi środowiskowymi i jak drukować do standardowego strumienia błędów, co jest przydatne podczas pisania programów wiersza poleceń.
Praca ze zmiennymi środowiskowymi
Praca ze zmiennymi środowiskowymi
Udoskonalimy plik binarny minigrep, dodając dodatkową funkcję: opcję wyszukiwania bez uwzględniania wielkości liter, którą użytkownik może włączyć za pomocą zmiennej środowiskowej. Moglibyśmy uczynić tę funkcję opcją wiersza poleceń i wymagać od użytkowników wprowadzania jej za każdym razem, gdy chcą ją zastosować, ale zamiast tego, tworząc zmienną środowiskową, pozwalamy naszym użytkownikom ustawić zmienną środowiskową raz i mieć wszystkie ich wyszukiwania bez uwzględniania wielkości liter w tej sesji terminala.
Pisanie nieudanego testu dla wyszukiwania bez uwzględniania wielkości liter
Najpierw dodajemy nową funkcję search_case_insensitive do biblioteki minigrep, która zostanie wywołana, gdy zmienna środowiskowa będzie miała wartość. Będziemy kontynuować proces TDD, więc pierwszym krokiem ponownie jest napisanie nieudanego testu. Dodamy nowy test dla nowej funkcji search_case_insensitive i zmienimy nazwę naszego starego testu z one_result na case_sensitive, aby wyjaśnić różnice między dwoma testami, jak pokazano w Listing 12-20.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Zauważ, że zmodyfikowaliśmy również contents starego testu. Dodaliśmy nowy wiersz z tekstem "Duct tape." z wielką literą D, który nie powinien pasować do zapytania "duct" podczas wyszukiwania z uwzględnieniem wielkości liter. Zmiana starego testu w ten sposób pomaga upewnić się, że nie uszkodzimy przypadkowo funkcjonalności wyszukiwania z uwzględnieniem wielkości liter, którą już zaimplementowaliśmy. Ten test powinien teraz przejść i powinien nadal przechodzić podczas pracy nad wyszukiwaniem bez uwzględniania wielkości liter.
Nowy test dla wyszukiwania bez uwzględniania wielkości liter (case-insensitive) używa "rUsT" jako zapytania. W funkcji search_case_insensitive, którą zaraz dodamy, zapytanie "rUsT" powinno pasować do wiersza zawierającego "Rust:" z wielką literą R oraz do wiersza "Trust me." mimo że oba mają inną wielkość liter niż zapytanie. To jest nasz test, który zakończy się niepowodzeniem, ponieważ nie zdefiniowaliśmy jeszcze funkcji search_case_insensitive. Możesz dodać szkieletową implementację, która zawsze zwraca pusty wektor, podobnie jak zrobiliśmy to dla funkcji search w Listing 12-16, aby zobaczyć, jak test się kompiluje i kończy niepowodzeniem.
Implementowanie funkcji search_case_insensitive
Funkcja search_case_insensitive, pokazana w Listing 12-21, będzie prawie taka sama jak funkcja search. Jedyną różnicą jest to, że zmienimy query i każdy line na małe litery, tak aby niezależnie od wielkości liter w argumentach wejściowych, miały one tę samą wielkość liter, gdy sprawdzamy, czy wiersz zawiera zapytanie.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Najpierw zmieniamy ciąg znaków query na małe litery i przechowujemy go w nowej zmiennej o tej samej nazwie, zasłaniając oryginalny query. Wywołanie to_lowercase na zapytaniu jest konieczne, aby niezależnie od tego, czy zapytanie użytkownika to "rust", "RUST", "Rust", czy "rUsT", traktować zapytanie tak, jakby było "rust" i ignorować wielkość liter. Chociaż to_lowercase poradzi sobie z podstawowym Unicode, nie będzie w 100 procentach dokładne. Gdybyśmy pisali prawdziwą aplikację, chcielibyśmy włożyć w to więcej pracy, ale ta sekcja dotyczy zmiennych środowiskowych, a nie Unicode, więc na tym poprzestaniemy.
Zauważ, że query jest teraz String, a nie wycinkiem ciągu znaków, ponieważ wywołanie to_lowercase tworzy nowe dane, zamiast odwoływać się do istniejących. Na przykład, jeśli zapytanie to "rUsT": ten wycinek ciągu znaków nie zawiera małych liter u ani t, których moglibyśmy użyć, więc musimy zaalokować nowy String zawierający "rust". Kiedy teraz przekazujemy query jako argument do metody contains, musimy dodać ampersand, ponieważ sygnatura contains jest zdefiniowana tak, aby przyjmowała wycinek ciągu znaków.
Następnie dodajemy wywołanie to_lowercase na każdym line, aby zmienić wszystkie znaki na małe litery. Teraz, gdy przekonwertowaliśmy line i query na małe litery, znajdziemy dopasowania niezależnie od wielkości liter w zapytaniu.
Sprawdźmy, czy ta implementacja przechodzi testy:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Świetnie! Testy przeszły. Teraz wywołajmy nową funkcję search_case_insensitive z funkcji run. Najpierw dodamy opcję konfiguracji do struktury Config, aby przełączać się między wyszukiwaniem z uwzględnianiem wielkości liter a wyszukiwaniem bez uwzględniania wielkości liter. Dodanie tego pola spowoduje błędy kompilacji, ponieważ nigdzie jeszcze nie inicjalizujemy tego pola:
Nazwa pliku: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Dodaliśmy pole ignore_case, które przechowuje wartość typu boolean. Następnie funkcja run musi sprawdzić wartość pola ignore_case i na tej podstawie zdecydować, czy wywołać funkcję search, czy funkcję search_case_insensitive, jak pokazano w Listing 12-22. To jeszcze się nie skompiluje.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Na koniec musimy sprawdzić zmienną środowiskową. Funkcje do pracy ze zmiennymi środowiskowymi znajdują się w module env w standardowej bibliotece, który jest już w zakresie na początku pliku src/main.rs. Użyjemy funkcji var z modułu env, aby sprawdzić, czy jakakolwiek wartość została ustawiona dla zmiennej środowiskowej o nazwie IGNORE_CASE, jak pokazano w Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Tutaj tworzymy nową zmienną ignore_case. Aby ustawić jej wartość, wywołujemy funkcję env::var i przekazujemy jej nazwę zmiennej środowiskowej IGNORE_CASE. Funkcja env::var zwraca Result, który będzie wariantem Ok zawierającym wartość zmiennej środowiskowej, jeśli zmienna środowiskowa jest ustawiona na jakąkolwiek wartość. Zwróci wariant Err, jeśli zmienna środowiskowa nie jest ustawiona.
Używamy metody is_ok na Result, aby sprawdzić, czy zmienna środowiskowa jest ustawiona, co oznacza, że program powinien przeprowadzić wyszukiwanie bez uwzględniania wielkości liter. Jeśli zmienna środowiskowa IGNORE_CASE nie jest ustawiona na nic, is_ok zwróci false, a program przeprowadzi wyszukiwanie z uwzględnieniem wielkości liter. Nie obchodzi nas wartość zmiennej środowiskowej, tylko to, czy jest ustawiona, czy nie, więc sprawdzamy is_ok zamiast używać unwrap, expect lub innych metod, które widzieliśmy na Result.
Przekazujemy wartość zmiennej ignore_case do instancji Config, aby funkcja run mogła odczytać tę wartość i zdecydować, czy wywołać search_case_insensitive, czy search, jak zaimplementowaliśmy w Listing 12-22.
Wypróbujmy to! Najpierw uruchomimy nasz program bez ustawionej zmiennej środowiskowej i z zapytaniem to, które powinno pasować do każdego wiersza zawierającego słowo to pisanego małymi literami:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Wygląda na to, że to nadal działa! Teraz uruchommy program z IGNORE_CASE ustawionym na 1, ale z tym samym zapytaniem to:
$ IGNORE_CASE=1 cargo run -- to poem.txt
Jeśli używasz PowerShell, musisz ustawić zmienną środowiskową i uruchomić program jako osobne polecenia:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Spowoduje to, że IGNORE_CASE będzie obowiązywać przez resztę sesji powłoki. Można go usunąć za pomocą polecenia Remove-Item:
PS> Remove-Item Env:IGNORE_CASE
Ppowinniśmy otrzymać wiersze, które zawierają to z ewentualnymi dużymi literami:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Doskonale, dostaliśmy też linie zawierające To! Nasz program minigrep może teraz przeprowadzać wyszukiwanie bez uwzględniania wielkości liter, sterowane zmienną środowiskową. Teraz wiesz, jak zarządzać opcjami ustawionymi za pomocą argumentów wiersza poleceń lub zmiennych środowiskowych.
Niektóre programy pozwalają na użycie argumentów i zmiennych środowiskowych dla tej samej konfiguracji. W takich przypadkach programy decydują, które z nich mają pierwszeństwo. W ramach samodzielnego ćwiczenia spróbuj kontrolować czułość na wielkość liter za pomocą argumentu wiersza poleceń lub zmiennej środowiskowej. Zdecyduj, czy argument wiersza poleceń, czy zmienna środowiskowa powinna mieć pierwszeństwo, jeśli program jest uruchamiany z jednym ustawionym na uwzględnianie wielkości liter, a drugim na ignorowanie wielkości liter.
Moduł std::env zawiera wiele innych przydatnych funkcji do obsługi zmiennych środowiskowych: zajrzyj do jego dokumentacji, aby zobaczyć, co jest dostępne.
Przekierowywanie błędów do standardowego strumienia błędów
Przekierowywanie błędów do standardowego strumienia błędów
W tej chwili wszystkie nasze dane wyjściowe zapisujemy do terminala za pomocą makra println!. W większości terminali istnieją dwa rodzaje danych wyjściowych: standardowe wyjście (stdout) dla ogólnych informacji i standardowy błąd (stderr) dla komunikatów o błędach. To rozróżnienie umożliwia użytkownikom skierowanie pomyślnych danych wyjściowych programu do pliku, ale nadal wyświetlanie komunikatów o błędach na ekranie.
Makro println! jest w stanie drukować tylko na standardowe wyjście, więc musimy użyć czegoś innego do drukowania na standardowy błąd.
Sprawdzanie, gdzie są zapisywane błędy
Najpierw zaobserwujmy, jak zawartość drukowana przez minigrep jest obecnie zapisywana na standardowe wyjście, w tym wszelkie komunikaty o błędach, które chcielibyśmy zamiast tego zapisać na standardowy strumień błędów. Zrobimy to, przekierowując standardowy strumień wyjściowy do pliku, celowo powodując błąd. Nie będziemy przekierowywać standardowego strumienia błędów, więc wszelka zawartość wysłana na standardowy strumień błędów będzie nadal wyświetlana na ekranie.
Oczekuje się, że programy wiersza poleceń wysyłają komunikaty o błędach do standardowego strumienia błędów, abyśmy mogli nadal widzieć komunikaty o błędach na ekranie, nawet jeśli przekierujemy standardowy strumień wyjściowy do pliku. Nasz program nie zachowuje się obecnie poprawnie: zaraz zobaczymy, że zapisuje komunikaty o błędach do pliku!
Aby zademonstrować to zachowanie, uruchomimy program z > i ścieżką pliku output.txt, do której chcemy przekierować standardowy strumień wyjściowy. Nie będziemy przekazywać żadnych argumentów, co powinno spowodować błąd:
$ cargo run > output.txt
Składnia > informuje powłokę, aby zapisała zawartość standardowego wyjścia do output.txt zamiast na ekran. Nie zobaczyliśmy komunikatu o błędzie, którego się spodziewaliśmy, na ekranie, więc musi on trafić do pliku. Oto co zawiera output.txt:
Problem parsing arguments: not enough arguments
Tak, nasz komunikat o błędzie jest drukowany na standardowe wyjście. Dużo bardziej użyteczne jest drukowanie takich komunikatów o błędach na standardowy strumień błędów, tak aby do pliku trafiały tylko dane z pomyślnego uruchomienia. Zmienimy to.
Drukowanie błędów na standardowy strumień błędów
Użyjemy kodu z Listing 12-24, aby zmienić sposób drukowania komunikatów o błędach. Dzięki refaktoryzacji, którą przeprowadziliśmy wcześniej w tym rozdziale, cały kod drukujący komunikaty o błędach znajduje się w jednej funkcji, main. Standardowa biblioteka dostarcza makro eprintln!, które drukuje na standardowy strumień błędów, więc zmieńmy dwa miejsca, w których wywoływaliśmy println! do drukowania błędów, aby zamiast tego użyć eprintln!.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Uruchommy teraz program ponownie w ten sam sposób, bez żadnych argumentów i przekierowując standardowe wyjście za pomocą >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Teraz widzimy błąd na ekranie, a plik output.txt jest pusty, co jest zachowaniem, którego oczekujemy od programów wiersza poleceń.
Uruchommy program ponownie z argumentami, które nie powodują błędu, ale nadal przekierowują standardowe wyjście do pliku, w następujący sposób:
$ cargo run -- to poem.txt > output.txt
Nie zobaczymy żadnych danych wyjściowych w terminalu, a plik output.txt będzie zawierał nasze wyniki:
Nazwa pliku: output.txt
Are you nobody, too?
How dreary to be somebody!
To pokazuje, że teraz używamy standardowego wyjścia dla pomyślnych wyników i standardowego strumienia błędów dla komunikatów o błędach, stosownie do potrzeb.
Podsumowanie
Ten rozdział podsumował niektóre z głównych pojęć, które poznałeś do tej pory, i omówił, jak wykonywać typowe operacje wejścia/wyjścia w Rust. Korzystając z argumentów wiersza poleceń, plików, zmiennych środowiskowych i makra eprintln! do drukowania błędów, jesteś teraz przygotowany do pisania aplikacji wiersza poleceń. W połączeniu z koncepcjami z poprzednich rozdziałów, Twój kod będzie dobrze zorganizowany, skutecznie przechowywał dane w odpowiednich strukturach danych, ładnie obsługiwał błędy i będzie dobrze przetestowany.
Następnie zbadamy niektóre funkcje Rusta, które zostały zainspirowane językami funkcyjnymi: domknięcia i iteratory.
Funkcjonalne cechy języka: Iteratory i domknięcia
Projekt Rusta czerpie inspirację z wielu istniejących języków i technik, a jednym z istotnych wpływów jest programowanie funkcyjne. Programowanie w stylu funkcyjnym często obejmuje używanie funkcji jako wartości, przekazywanie ich w argumentach, zwracanie ich z innych funkcji, przypisywanie ich do zmiennych do późniejszego wykonania i tak dalej.
W tym rozdziale nie będziemy debatować nad tym, czym jest lub nie jest programowanie funkcyjne, ale zamiast tego omówimy niektóre cechy Rusta, które są podobne do cech w wielu językach często określanych jako funkcyjne.
Bardziej szczegółowo omówimy:
- Domknięcia, konstrukcje podobne do funkcji, które można przechowywać w zmiennej
- Iteratory, sposób przetwarzania serii elementów
- Jak używać domknięć i iteratorów do ulepszenia projektu I/O z Rozdziału 12
- Wydajność domknięć i iteratorów (spoiler: są szybsze, niż mogłoby się wydawać!)
Omówiliśmy już inne cechy Rusta, takie jak dopasowywanie wzorców i wyliczenia, które również są inspirowane stylem funkcyjnym. Ponieważ opanowanie domknięć i iteratorów jest ważną częścią pisania szybkiego, idiomatycznego kodu w Rust, poświęcimy im cały ten rozdział.
Domknięcia
Domknięcia
Domknięcia w Rust to anonimowe funkcje, które można zapisać w zmiennej lub przekazać jako argumenty do innych funkcji. Można utworzyć domknięcie w jednym miejscu, a następnie wywołać je w innym, aby je ocenić w innym kontekście. W przeciwieństwie do funkcji, domknięcia mogą przechwytywać wartości ze środowiska, w którym są zdefiniowane. Zdemonstrujemy, jak te cechy domknięć pozwalają na ponowne użycie kodu i dostosowanie zachowania.
Przechwytywanie środowiska
Najpierw zbadamy, jak możemy używać domknięć do przechwytywania wartości ze środowiska, w którym są zdefiniowane, do późniejszego użycia. Oto scenariusz: Co jakiś czas nasza firma produkująca koszulki rozdaje ekskluzywną koszulkę z limitowanej edycji osobie z naszej listy mailingowej w ramach promocji. Osoby z listy mailingowej mogą opcjonalnie dodać swój ulubiony kolor do swojego profilu. Jeśli osoba wybrana do darmowej koszulki ma ustawiony ulubiony kolor, otrzymuje koszulkę w tym kolorze. Jeśli osoba nie określiła ulubionego koloru, otrzymuje koszulkę w kolorze, którego firma ma obecnie najwięcej.
Istnieje wiele sposobów na zaimplementowanie tego. W tym przykładzie użyjemy wyliczenia ShirtColor, które ma warianty Red i Blue (dla uproszczenia ograniczamy liczbę dostępnych kolorów). Reprezentujemy stan magazynowy firmy za pomocą struktury Inventory, która ma pole shirts zawierające Vec<ShirtColor> reprezentujące kolory koszulek aktualnie w magazynie. Metoda giveaway zdefiniowana dla Inventory pobiera opcjonalne preferencje koloru koszulki zwycięzcy darmowej koszulki i zwraca kolor koszulki, którą osoba otrzyma. Ta konfiguracja jest pokazana w Listing 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"Użytkownik z preferencją {:?} dostaje {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"Użytkownik z preferencją {:?} dostaje {:?}",
user_pref2, giveaway2
);
}store zdefiniowany w main ma dwie niebieskie i jedną czerwoną koszulkę do rozdania w ramach tej limitowanej promocji. Wywołujemy metodę giveaway dla użytkownika preferującego czerwoną koszulkę i dla użytkownika bez żadnych preferencji.
Ponownie, ten kod mógłby być zaimplementowany na wiele sposobów, a tutaj, aby skupić się na domknięciach, trzymaliśmy się pojęć, które już znasz, z wyjątkiem ciała metody giveaway, która używa domknięcia. W metodzie giveaway otrzymujemy preferencję użytkownika jako parametr typu Option<ShirtColor> i wywołujemy metodę unwrap_or_else na user_preference. Metoda unwrap_or_else w Option<T> jest zdefiniowana przez standardową bibliotekę. Przyjmuje jeden argument: domknięcie bez żadnych argumentów, które zwraca wartość T (tego samego typu co przechowywany w wariancie Some Option<T>, w tym przypadku ShirtColor). Jeśli Option<T> jest wariantem Some, unwrap_or_else zwraca wartość z Some. Jeśli Option<T> jest wariantem None, unwrap_or_else wywołuje domknięcie i zwraca wartość zwróconą przez domknięcie.
Określamy wyrażenie domknięcia || self.most_stocked() jako argument dla unwrap_or_else. Jest to domknięcie, które samo nie przyjmuje parametrów (gdyby domknięcie miało parametry, pojawiłyby się one między dwoma pionowymi kreskami). Ciało domknięcia wywołuje self.most_stocked(). Definiujemy tutaj domknięcie, a implementacja unwrap_or_else oceni domknięcie później, jeśli wynik będzie potrzebny.
Uruchomienie tego kodu wyświetli następujące informacje:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
Użytkownik z preferencją Some(Red) dostaje Red
Użytkownik z preferencją None dostaje Blue
Jednym interesującym aspektem jest to, że przekazaliśmy domknięcie, które wywołuje self.most_stocked() na bieżącej instancji Inventory. Standardowa biblioteka nie musiała wiedzieć nic o typach Inventory ani ShirtColor, które zdefiniowaliśmy, ani o logice, której chcemy użyć w tym scenariuszu. Domknięcie przechwytuje niezmienną referencję do instancji self Inventory i przekazuje ją z określonym przez nas kodem do metody unwrap_or_else. Funkcje natomiast nie są w stanie przechwytywać swojego środowiska w ten sposób.
Wywnioskowanie i adnotowanie typów domknięć
Istnieje więcej różnic między funkcjami a domknięciami. Domknięcia zazwyczaj nie wymagają adnotowania typów parametrów ani wartości zwracanej, tak jak funkcje fn. Adnotacje typów są wymagane w funkcjach, ponieważ typy są częścią jawnego interfejsu udostępnianego użytkownikom. Sztywne definiowanie tego interfejsu jest ważne dla zapewnienia, że wszyscy zgadzają się co do tego, jakich typów wartości funkcja używa i zwraca. Domknięcia natomiast nie są używane w takim udostępnionym interfejsie: są przechowywane w zmiennych i używane bez nazywania ich i udostępniania użytkownikom naszej biblioteki.
Domknięcia są zazwyczaj krótkie i istotne tylko w wąskim kontekście, a nie w dowolnym scenariuszu. W tych ograniczonych kontekstach kompilator może wywnioskować typy parametrów i typ zwracany, podobnie jak jest w stanie wywnioskować typy większości zmiennych (istnieją rzadkie przypadki, w których kompilator również potrzebuje adnotacji typów domknięć).
Podobnie jak w przypadku zmiennych, możemy dodać adnotacje typów, jeśli chcemy zwiększyć jawność i klarowność kosztem większej szczegółowości, niż jest to ściśle konieczne. Adnotowanie typów dla domknięcia wyglądałoby jak definicja pokazana w Listing 13-2. W tym przykładzie definiujemy domknięcie i przechowujemy je w zmiennej, zamiast definiować domknięcie w miejscu, w którym przekazujemy je jako argument, jak to zrobiliśmy w Listing 13-1.
use std::thread;
use std::time::Duration;
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num: u32| -> u32 {
println!("obliczanie powoli...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Dziś, zrób {} pompek!", expensive_closure(intensity));
println!("Następnie, zrób {} brzuszków!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Zrób sobie dziś przerwę! Pamiętaj o nawodnieniu!");
} else {
println!(
"Dziś, biegnij przez {} minut!",
expensive_closure(intensity)
);
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}Po dodaniu adnotacji typów składnia domknięć wygląda bardziej podobnie do składni funkcji. Tutaj definiujemy funkcję, która dodaje 1 do swojego parametru, i domknięcie, które ma takie samo zachowanie, dla porównania. Dodaliśmy kilka spacji, aby wyrównać odpowiednie części. Pokazuje to, jak składnia domknięcia jest podobna do składni funkcji, z wyjątkiem użycia pionowych kresek i ilości składni, która jest opcjonalna:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;Pierwsza linia pokazuje definicję funkcji, a druga definicję domknięcia z pełnymi adnotacjami. W trzeciej linii usuwamy adnotacje typów z definicji domknięcia. W czwartej linii usuwamy nawiasy klamrowe, które są opcjonalne, ponieważ ciało domknięcia ma tylko jedno wyrażenie. Wszystkie te definicje są poprawne i będą dawać to samo zachowanie po ich wywołaniu. Linie add_one_v3 i add_one_v4 wymagają oceny domknięć, aby mogły się skompilować, ponieważ typy zostaną wywnioskowane z ich użycia. Jest to podobne do let v = Vec::new();, które wymaga albo adnotacji typów, albo wartości jakiegoś typu do wstawienia do Vec, aby Rust mógł wywnioskować typ.
Dla definicji domknięć kompilator wywnioskuje jeden konkretny typ dla każdego z ich parametrów i dla ich wartości zwracanej. Na przykład, Listing 13-3 pokazuje definicję krótkiego domknięcia, które po prostu zwraca wartość, którą otrzymuje jako parametr. To domknięcie nie jest zbyt użyteczne, z wyjątkiem celów tego przykładu. Zauważ, że nie dodaliśmy żadnych adnotacji typów do definicji. Ponieważ nie ma adnotacji typów, możemy wywołać domknięcie z dowolnym typem, co zrobiliśmy tutaj z String za pierwszym razem. Jeśli następnie spróbujemy wywołać example_closure z liczbą całkowitą, otrzymamy błąd.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Kompilator daje nam następujący błąd:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
Za pierwszym razem, gdy wywołujemy example_closure z wartością String, kompilator wywnioskowuje typ x i typ zwracany domknięcia jako String. Te typy są następnie zablokowane w domknięciu w example_closure, i otrzymujemy błąd typu, gdy następnym razem próbujemy użyć innego typu z tym samym domknięciem.
Przechwytywanie referencji lub przenoszenie własności
Domknięcia mogą przechwytywać wartości ze swojego środowiska na trzy sposoby, które bezpośrednio odpowiadają trzem sposobom, w jakie funkcja może przyjąć parametr: pożyczanie niezmienne, pożyczanie zmienne i przejmowanie własności. Domknięcie zdecyduje, którego z nich użyć, w zależności od tego, co ciało funkcji robi z przechwyconymi wartościami.
W Listing 13-4 definiujemy domknięcie, które przechwytuje niezmienną referencję do wektora o nazwie list, ponieważ potrzebuje jedynie niezmiennej referencji, aby wydrukować wartość.
fn main() {
let list = vec![1, 2, 3];
println!("Przed zdefiniowaniem domknięcia: {list:?}");
let only_borrows = || println!("Z domknięcia: {list:?}");
println!("Przed wywołaniem domknięcia: {list:?}");
only_borrows();
println!("Po wywołaniu domknięcia: {list:?}");
}Ten przykład ilustruje również, że zmienna może być związana z definicją domknięcia, a później możemy wywołać domknięcie, używając nazwy zmiennej i nawiasów, tak jakby nazwa zmiennej była nazwą funkcji.
Ponieważ możemy mieć jednocześnie wiele niezmiennych referencji do list, list jest nadal dostępny z kodu przed definicją domknięcia, po definicji domknięcia, ale przed wywołaniem domknięcia, i po wywołaniu domknięcia. Ten kod kompiluje się, uruchamia i drukuje:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Przed zdefiniowaniem domknięcia: [1, 2, 3]
Przed wywołaniem domknięcia: [1, 2, 3]
Z domknięcia: [1, 2, 3]
Po wywołaniu domknięcia: [1, 2, 3]
Następnie, w Listing 13-5, zmieniamy ciało domknięcia tak, aby dodawało element do wektora list. Domknięcie teraz przechwytuje zmienną referencję.
fn main() {
let mut list = vec![1, 2, 3];
println!("Przed zdefiniowaniem domknięcia: {list:?}");
let mut borrows_mutably = || list.push(7);
borrows_mutably();
println!("Po wywołaniu domknięcia: {list:?}");
}Ten kod kompiluje się, uruchamia i drukuje:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Przed zdefiniowaniem domknięcia: [1, 2, 3]
Po wywołaniu domknięcia: [1, 2, 3, 7]
Zauważ, że nie ma już println! między definicją a wywołaniem domknięcia borrows_mutably: Kiedy borrows_mutably jest zdefiniowane, przechwytuje zmienną referencję do list. Nie używamy domknięcia ponownie po jego wywołaniu, więc zmienna pożyczka się kończy. Między definicją domknięcia a wywołaniem domknięcia, niezmienna pożyczka do wydrukowania nie jest dozwolona, ponieważ żadne inne pożyczki nie są dozwolone, gdy istnieje zmienna pożyczka. Spróbuj dodać tam println!, aby zobaczyć, jaki komunikat o błędzie otrzymasz!
Jeśli chcesz wymusić na domknięciu przejęcie własności wartości, których używa w środowisku, mimo że ciało domknięcia nie potrzebuje ściśle własności, możesz użyć słowa kluczowego move przed listą parametrów.
Ta technika jest najbardziej użyteczna, gdy przekazujemy domknięcie do nowego wątku, aby przenieść dane, tak aby nowy wątek był ich właścicielem. Szczegółowo omówimy wątki i dlaczego warto ich używać w Rozdziale 16, kiedy będziemy mówić o współbieżności, ale na razie przyjrzyjmy się krótko tworzeniu nowego wątku za pomocą domknięcia, które wymaga słowa kluczowego move. Listing 13-6 pokazuje Listing 13-4 zmodyfikowany tak, aby drukował wektor w nowym wątku, a nie w wątku głównym.
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Przed zdefiniowaniem domknięcia: {list:?}");
thread::spawn(move || println!("Z wątku: {list:?}"))
.join()
.unwrap();
}Tworzymy nowy wątek, przekazując mu domknięcie do uruchomienia jako argument. Ciało domknięcia wypisuje listę. W Listing 13-4 domknięcie przechwytywało list tylko za pomocą niezmiennej referencji, ponieważ to jest minimalny dostęp do list potrzebny do jego wydrukowania. W tym przykładzie, mimo że ciało domknięcia nadal potrzebuje tylko niezmiennej referencji, musimy określić, że list powinno zostać przeniesione do domknięcia, umieszczając słowo kluczowe move na początku definicji domknięcia. Gdyby wątek główny wykonywał więcej operacji przed wywołaniem join na nowym wątku, nowy wątek mógłby zakończyć się przed zakończeniem reszty wątku głównego, lub wątek główny mógłby zakończyć się pierwszy. Gdyby wątek główny zachował własność list, ale zakończył się przed nowym wątkiem i upuścił list, niezmienna referencja w wątku byłaby nieważna. Dlatego kompilator wymaga przeniesienia list do domknięcia przekazanego nowemu wątkowi, aby referencja była ważna. Spróbuj usunąć słowo kluczowe move lub użyć list w wątku głównym po zdefiniowaniu domknięcia, aby zobaczyć, jakie błędy kompilatora otrzymasz!
Przenoszenie przechwyconych wartości poza domknięcia
Gdy domknięcie przechwyci referencję lub własność wartości ze środowiska, w którym jest zdefiniowane (wpływając tym samym na to, co, jeśli w ogóle, jest przenoszone do domknięcia), kod w ciele domknięcia określa, co dzieje się z referencjami lub wartościami, gdy domknięcie jest później oceniane (wpływając tym samym na to, co, jeśli w ogóle, jest przenoszone z domknięcia).
Ciało domknięcia może wykonać dowolne z następujących czynności: przenieść przechwyconą wartość poza domknięcie, zmutować przechwyconą wartość, ani nie przenieść, ani nie zmutować wartości, lub w ogóle nic nie przechwycić ze środowiska.
Sposób, w jaki domknięcie przechwytuje i obsługuje wartości ze środowiska, wpływa na to, które cechy domknięcie implementuje, a cechy to sposób, w jaki funkcje i struktury mogą określać, jakich rodzajów domknięć mogą używać. Domknięcia automatycznie zaimplementują jedną, dwie lub wszystkie trzy z tych cech Fn, w sposób addytywny, w zależności od tego, jak ciało domknięcia obsługuje wartości:
FnOncedotyczy domknięć, które można wywołać raz. Wszystkie domknięcia implementują co najmniej tę cechę, ponieważ wszystkie domknięcia można wywołać. Domknięcie, które przenosi przechwycone wartości ze swojego ciała, zaimplementuje tylkoFnOncei żadnych innych cechFn, ponieważ można je wywołać tylko raz.FnMutdotyczy domknięć, które nie przenoszą przechwyconych wartości ze swojego ciała, ale mogą mutować przechwycone wartości. Te domknięcia można wywołać więcej niż raz.Fndotyczy domknięć, które nie przenoszą przechwyconych wartości ze swojego ciała i nie mutują przechwyconych wartości, a także domknięć, które nic nie przechwytują ze swojego środowiska. Te domknięcia można wywołać więcej niż raz bez mutowania ich środowiska, co jest ważne w przypadkach takich jak wielokrotne wywoływanie domknięcia współbieżnie.
Przyjrzyjmy się definicji metody unwrap_or_else na Option<T>, której użyliśmy w Listing 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Pamiętaj, że T to typ ogólny reprezentujący typ wartości w wariancie Some Option. Ten typ T jest również typem zwracanym przez funkcję unwrap_or_else: kod, który wywołuje unwrap_or_else na Option<String>, na przykład, otrzyma String.
Następnie, zauważ, że funkcja unwrap_or_else ma dodatkowy generyczny parametr typu F. Typ F to typ parametru o nazwie f, czyli domknięcia, które dostarczamy podczas wywoływania unwrap_or_else.
Ograniczenie cechy określone dla typu generycznego F to FnOnce() -> T, co oznacza, że F musi być wywoływalne raz, nie przyjmować żadnych argumentów i zwracać T. Użycie FnOnce w ograniczeniu cechy wyraża ograniczenie, że unwrap_or_else nie wywoła f więcej niż raz. W ciele unwrap_or_else widzimy, że jeśli Option jest Some, f nie zostanie wywołane. Jeśli Option jest None, f zostanie wywołane raz. Ponieważ wszystkie domknięcia implementują FnOnce, unwrap_or_else akceptuje wszystkie trzy rodzaje domknięć i jest tak elastyczne, jak to tylko możliwe.
Uwaga: Jeśli to, co chcemy zrobić, nie wymaga przechwytywania wartości ze środowiska, możemy użyć nazwy funkcji zamiast domknięcia tam, gdzie potrzebujemy czegoś, co implementuje jedną z cech
Fn. Na przykład, na wartościOption<Vec<T>>moglibyśmy wywołaćunwrap_or_else(Vec::new), aby otrzymać nowy, pusty wektor, jeśli wartość toNone. Kompilator automatycznie implementuje dowolną z cechFn, która jest odpowiednia dla definicji funkcji.
Teraz przyjrzyjmy się metodzie sort_by_key ze standardowej biblioteki, zdefiniowanej dla wycinków, aby zobaczyć, jak różni się ona od unwrap_or_else i dlaczego sort_by_key używa FnMut zamiast FnOnce dla ograniczenia cechy. Domknięcie otrzymuje jeden argument w postaci referencji do bieżącego elementu w rozpatrywanym wycinku i zwraca wartość typu K, którą można posortować. Ta funkcja jest przydatna, gdy chcesz posortować wycinek według określonego atrybutu każdego elementu. W Listing 13-7 mamy listę instancji Rectangle i używamy sort_by_key do uporządkowania ich według atrybutu width od najmniejszego do największego.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
list.sort_by_key(|r| r.width);
println!("{list:#?}");
}Ten kod drukuje:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
Powodem, dla którego sort_by_key jest zdefiniowany tak, aby przyjmować domknięcie FnMut, jest to, że wywołuje ono domknięcie wielokrotnie: raz dla każdego elementu w wycinku. Domknięcie |r| r.width nie przechwytuje, nie mutuje ani nie przenosi niczego ze swojego środowiska, więc spełnia wymagania ograniczenia cechy.
Natomiast Listing 13-8 przedstawia przykład domknięcia, które implementuje tylko cechę FnOnce, ponieważ przenosi wartość ze środowiska. Kompilator nie pozwoli nam użyć tego domknięcia z sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}To jest wymyślny, skomplikowany sposób (który nie działa) na próbę zliczenia, ile razy sort_by_key wywołuje domknięcie podczas sortowania list. Ten kod próbuje to zrobić, wpychając value – String ze środowiska domknięcia – do wektora sort_operations. Domknięcie przechwytuje value, a następnie przenosi value poza domknięcie, przekazując własność value do wektora sort_operations. To domknięcie można wywołać raz; próba wywołania go po raz drugi nie zadziała, ponieważ value nie byłoby już w środowisku, aby ponownie wpychać je do sort_operations! Dlatego to domknięcie implementuje tylko FnOnce. Kiedy próbujemy skompilować ten kod, otrzymujemy następujący błąd, że value nie może zostać przeniesione poza domknięcie, ponieważ domknięcie musi implementować FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
Błąd wskazuje na linię w ciele domknięcia, która przenosi value poza środowisko. Aby to naprawić, musimy zmienić ciało domknięcia tak, aby nie przenosiło wartości poza środowisko. Utrzymywanie licznika w środowisku i inkrementowanie jego wartości w ciele domknięcia jest prostszym sposobem na zliczanie, ile razy domknięcie jest wywoływane. Domknięcie w Listing 13-9 działa z sort_by_key, ponieważ przechwytuje tylko zmienną referencję do licznika num_sort_operations i dlatego może być wywoływane więcej niż raz.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut num_sort_operations = 0;
list.sort_by_key(|r| {
num_sort_operations += 1;
r.width
});
println!("{list:#?}, posortowane w {num_sort_operations} operacjach");
}Cechy Fn są ważne podczas definiowania lub używania funkcji lub typów, które wykorzystują domknięcia. W następnej sekcji omówimy iteratory. Wiele metod iteratora przyjmuje argumenty domknięcia, więc pamiętaj o tych szczegółach domknięć, kontynuując!
Przetwarzanie serii elementów za pomocą iteratorów
Przetwarzanie serii elementów za pomocą iteratorów
Wzorzec iteratora pozwala na wykonywanie określonego zadania na sekwencji elementów po kolei. Iterator jest odpowiedzialny za logikę iterowania po każdym elemencie i określanie, kiedy sekwencja się zakończyła. Kiedy używasz iteratorów, nie musisz samodzielnie ponownie implementować tej logiki.
W Rust iteratory są lenistwe, co oznacza, że nie mają żadnego efektu, dopóki nie wywołasz metod, które zużywają iterator. Na przykład, kod w Listing 13-10 tworzy iterator po elementach w wektorze v1, wywołując metodę iter zdefiniowaną dla Vec<T>. Sam ten kod nie robi nic użytecznego.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}Iterator jest przechowywany w zmiennej v1_iter. Po utworzeniu iteratora możemy go używać na różne sposoby. W Listing 3-5 iterowaliśmy po tablicy za pomocą pętli for, aby wykonać jakiś kod na każdym z jej elementów. Pod spodem, to niejawnie utworzyło, a następnie zużyło iterator, ale pomijaliśmy dokładne działanie tego mechanizmu aż do teraz.
W przykładzie z Listing 13-11 oddzielamy tworzenie iteratora od używania iteratora w pętli for. Kiedy pętla for jest wywoływana z użyciem iteratora w v1_iter, każdy element iteratora jest używany w jednej iteracji pętli, która wypisuje każdą wartość.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("Otrzymano: {val}");
}
}W językach, które nie mają iteratorów dostarczanych przez ich standardowe biblioteki, prawdopodobnie napisałbyś tę samą funkcjonalność, rozpoczynając zmienną od indeksu 0, używając tej zmiennej do indeksowania wektora w celu uzyskania wartości i zwiększając wartość zmiennej w pętli, dopóki nie osiągnęłaby całkowitej liczby elementów w wektorze.
Iteratory obsługują całą tę logikę za Ciebie, zmniejszając ilość powtarzającego się kodu, który mógłbyś potencjalnie zepsuć. Iteratory dają większą elastyczność w używaniu tej samej logiki z wieloma różnymi rodzajami sekwencji, a nie tylko ze strukturami danych, do których można indeksować, takimi jak wektory. Przyjrzyjmy się, jak to robią iteratory.
Cecha Iterator i metoda next
Wszystkie iteratory implementują cechę o nazwie Iterator, która jest zdefiniowana w standardowej bibliotece. Definicja cechy wygląda następująco:
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// metody z domyślnymi implementacjami pominięte
}
}Zauważ, że ta definicja używa nowej składni: type Item i Self::Item, które definiują typ skojarzony z tą cechą. Szczegółowo omówimy typy skojarzone w Rozdziale 20. Na razie wystarczy wiedzieć, że ten kod mówi, że implementacja cechy Iterator wymaga również zdefiniowania typu Item, a ten typ Item jest używany w typie zwracanym przez metodę next. Innymi słowy, typ Item będzie typem zwracanym przez iterator.
Cecha Iterator wymaga od implementatorów zdefiniowania tylko jednej metody: metody next, która zwraca po jednym elemencie iteratora na raz, opakowanym w Some, a po zakończeniu iteracji zwraca None.
Możemy wywoływać metodę next bezpośrednio na iteratorach; Listing 13-12 pokazuje, jakie wartości są zwracane z wielokrotnych wywołań next na iteratorze utworzonym z wektora.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}Zauważ, że musieliśmy uczynić v1_iter zmiennym: wywołanie metody next na iteratorze zmienia wewnętrzny stan, którego iterator używa do śledzenia swojej pozycji w sekwencji. Innymi słowy, ten kod zużywa, czyli wykorzystuje, iterator. Każde wywołanie next pobiera element z iteratora. Nie musieliśmy uczynić v1_iter zmiennym, gdy używaliśmy pętli for, ponieważ pętla przejmowała własność v1_iter i czyniła go zmiennym za kulisami.
Zauważ również, że wartości, które otrzymujemy z wywołań next, to niezmienne referencje do wartości w wektorze. Metoda iter produkuje iterator po niezmiennych referencjach. Jeśli chcemy stworzyć iterator, który przejmuje własność v1 i zwraca posiadane wartości, możemy zamiast iter wywołać into_iter. Podobnie, jeśli chcemy iterować po zmiennych referencjach, możemy zamiast iter wywołać iter_mut.
Metody, które zużywają iterator
Cecha Iterator ma szereg różnych metod z domyślnymi implementacjami dostarczonymi przez standardową bibliotekę; o tych metodach możesz dowiedzieć się, przeglądając dokumentację API standardowej biblioteki dla cechy Iterator. Niektóre z tych metod wywołują metodę next w swojej definicji, dlatego jesteś zobowiązany do zaimplementowania metody next przy implementacji cechy Iterator.
Metody, które wywołują next, nazywane są konsumującymi adapterami, ponieważ ich wywołanie zużywa iterator. Jednym z przykładów jest metoda sum, która przejmuje własność iteratora i iteruje przez elementy, wielokrotnie wywołując next, zużywając tym samym iterator. Podczas iteracji dodaje każdy element do bieżącej sumy i zwraca sumę po zakończeniu iteracji. Listing 13-13 zawiera test ilustrujący użycie metody sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Nie możemy użyć v1_iter po wywołaniu sum, ponieważ sum przejmuje własność iteratora, na którym jest wywoływana.
Metody, które produkują inne iteratory
Adaptery iteratora to metody zdefiniowane na cesze Iterator, które nie zużywają iteratora. Zamiast tego produkują one inne iteratory, zmieniając jakiś aspekt oryginalnego iteratora.
Listing 13-14 pokazuje przykład wywołania metody adaptera iteratora map, która przyjmuje domknięcie do wywołania na każdym elemencie w trakcie iteracji. Metoda map zwraca nowy iterator, który produkuje zmodyfikowane elementy. Domknięcie tutaj tworzy nowy iterator, w którym każdy element z wektora zostanie zwiększony o 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}Jednak ten kod generuje ostrzeżenie:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Kod w Listing 13-14 nic nie robi; określone przez nas domknięcie nigdy nie jest wywoływane. Ostrzeżenie przypomina nam, dlaczego: adaptery iteratorów są leniwe, i musimy tutaj skonsumować iterator.
Aby naprawić to ostrzeżenie i skonsumować iterator, użyjemy metody collect, której użyliśmy z env::args w Listing 12-1. Ta metoda zużywa iterator i zbiera wynikowe wartości do typu danych kolekcji.
W Listing 13-15 zbieramy wyniki iteracji po iteratorze zwróconym z wywołania map do wektora. Ten wektor będzie zawierał każdy element z oryginalnego wektora, zwiększony o 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}Ponieważ map przyjmuje domknięcie, możemy określić dowolną operację, którą chcemy wykonać na każdym elemencie. Jest to doskonały przykład tego, jak domknięcia pozwalają dostosować pewne zachowanie, jednocześnie ponownie wykorzystując zachowanie iteracji, które zapewnia cecha Iterator.
Można łączyć wiele wywołań adapterów iteratora, aby wykonywać złożone działania w czytelny sposób. Ponieważ jednak wszystkie iteratory są leniwe, należy wywołać jedną z metod adaptera konsumującego, aby uzyskać wyniki z wywołań adapterów iteratora.
Domknięcia, które przechwytują swoje środowisko
Wiele adapterów iteratora przyjmuje domknięcia jako argumenty, a często domknięcia, które będziemy określać jako argumenty dla adapterów iteratora, będą domknięciami, które przechwytują ich środowisko.
W tym przykładzie użyjemy metody filter, która przyjmuje domknięcie. Domknięcie pobiera element z iteratora i zwraca bool. Jeśli domknięcie zwraca true, wartość zostanie włączona do iteracji wyprodukowanej przez filter. Jeśli domknięcie zwraca false, wartość nie zostanie włączona.
W Listing 13-16 używamy filter z domknięciem, które przechwytuje zmienną shoe_size ze swojego środowiska, aby iterować po kolekcji instancji struktury Shoe. Zwróci tylko buty o określonym rozmiarze.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}Funkcja shoes_in_size przejmuje własność wektora butów i rozmiaru buta jako parametry. Zwraca wektor zawierający tylko buty o określonym rozmiarze.
W ciele shoes_in_size wywołujemy into_iter, aby stworzyć iterator, który przejmuje własność wektora. Następnie wywołujemy filter, aby dostosować ten iterator do nowego iteratora, który zawiera tylko elementy, dla których domknięcie zwraca true.
Domknięcie przechwytuje parametr shoe_size ze środowiska i porównuje wartość z rozmiarem każdego buta, zachowując tylko buty o określonym rozmiarze. Na koniec wywołanie collect zbiera wartości zwrócone przez dostosowany iterator do wektora, który jest zwracany przez funkcję.
Test pokazuje, że po wywołaniu shoes_in_size otrzymujemy z powrotem tylko buty, które mają ten sam rozmiar, co określona przez nas wartość.
Udoskonalanie naszego projektu I/O
Udoskonalanie naszego projektu I/O
Dzięki tej nowej wiedzy o iteratorach możemy ulepszyć projekt I/O z Rozdziału 12, wykorzystując iteratory, aby uczynić kod bardziej czytelnym i zwięzłym. Przyjrzyjmy się, jak iteratory mogą ulepszyć naszą implementację funkcji Config::build i funkcji search.
Usuwanie clone za pomocą iteratora
W Listing 12-6 dodaliśmy kod, który przyjmował wycinek wartości String i tworzył instancję struktury Config poprzez indeksowanie do wycinka i klonowanie wartości, co pozwalało strukturze Config na posiadanie tych wartości. W Listing 13-17 odtworzyliśmy implementację funkcji Config::build taką, jaka była w Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Wówczas powiedzieliśmy, żeby nie martwić się nieefektywnymi wywołaniami clone, ponieważ usuniemy je w przyszłości. Cóż, ten czas nadszedł!
Potrzebowaliśmy clone tutaj, ponieważ mamy wycinek z elementami String w parametrze args, ale funkcja build nie jest właścicielem args. Aby zwrócić własność instancji Config, musieliśmy sklonować wartości z pól query i file_path Config, tak aby instancja Config mogła posiadać swoje wartości.
Dzięki naszej nowej wiedzy o iteratorach możemy zmienić funkcję build, aby przyjmowała własność iteratora jako swój argument, zamiast pożyczać wycinek. Użyjemy funkcjonalności iteratora zamiast kodu, który sprawdza długość wycinka i indeksuje do określonych miejsc. To wyjaśni, co robi funkcja Config::build, ponieważ iterator będzie miał dostęp do wartości.
Gdy Config::build przejmie własność iteratora i przestanie używać operacji indeksowania, które pożyczają, możemy przenieść wartości String z iteratora do Config zamiast wywoływać clone i tworzyć nową alokację.
Bezpośrednie używanie zwróconego iteratora
Otwórz plik src/main.rs swojego projektu I/O, który powinien wyglądać następująco:
Nazwa pliku: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Najpierw zmienimy początek funkcji main z Listing 12-24 na kod z Listing 13-18, który tym razem używa iteratora. To nie skompiluje się, dopóki nie zaktualizujemy również Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem z parsowaniem argumentów: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Błąd aplikacji: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("za mało argumentów");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Funkcja env::args zwraca iterator! Zamiast zbierać wartości iteratora do wektora, a następnie przekazywać wycinek do Config::build, teraz przekazujemy własność iteratora zwróconego przez env::args bezpośrednio do Config::build.
Następnie musimy zaktualizować definicję Config::build. Zmieńmy sygnaturę Config::build tak, aby wyglądała jak w Listing 13-19. To nadal się nie skompiluje, ponieważ musimy zaktualizować ciało funkcji.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem z parsowaniem argumentów: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Błąd aplikacji: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("za mało argumentów");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Dokumentacja standardowej biblioteki dla funkcji env::args pokazuje, że typ iteratora, który zwraca, to std::env::Args, a ten typ implementuje cechę Iterator i zwraca wartości String.
Zaktualizowaliśmy sygnaturę funkcji Config::build tak, aby parametr args miał typ generyczny z ograniczeniami cech impl Iterator<Item = String> zamiast &[String]. To użycie składni impl Trait, którą omówiliśmy w sekcji „Używanie cech jako parametrów” w Rozdziale 10, oznacza, że args może być dowolnym typem, który implementuje cechę Iterator i zwraca elementy String.
Ponieważ przejmujemy własność args i będziemy modyfikować args poprzez iterację po nim, możemy dodać słowo kluczowe mut do specyfikacji parametru args, aby uczynić go zmiennym.
Używanie metod cech Iterator
Następnie poprawimy ciało Config::build. Ponieważ args implementuje cechę Iterator, wiemy, że możemy na nim wywołać metodę next! Listing 13-20 aktualizuje kod z Listing 12-23, aby używał metody next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem z parsowaniem argumentów: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Błąd aplikacji: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Nie otrzymano ciągu zapytania"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Nie otrzymano ścieżki pliku"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Pamiętaj, że pierwsza wartość zwracana przez env::args to nazwa programu. Chcemy ją zignorować i przejść do następnej wartości, więc najpierw wywołujemy next i nic nie robimy z wartością zwracaną. Następnie wywołujemy next, aby uzyskać wartość, którą chcemy umieścić w polu query struktury Config. Jeśli next zwraca Some, używamy match, aby wyodrębnić wartość. Jeśli zwraca None, oznacza to, że nie podano wystarczającej liczby argumentów, i zwracamy Err. To samo robimy dla wartości file_path.
Upraszczanie kodu za pomocą adapterów iteratorów
Możemy również wykorzystać iteratory w funkcji search w naszym projekcie I/O, która jest tutaj odtworzona w Listing 13-21 w takiej postaci, w jakiej była w Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Możemy napisać ten kod w bardziej zwięzły sposób, używając metod adaptera iteratora. Pozwala to również uniknąć posiadania zmiennego, pośredniego wektora results. Styl programowania funkcyjnego preferuje minimalizowanie ilości zmiennego stanu, aby kod był bardziej czytelny. Usunięcie zmiennego stanu może umożliwić przyszłe ulepszenie, aby wyszukiwanie odbywało się równolegle, ponieważ nie musielibyśmy zarządzać współbieżnym dostępem do wektora results. Listing 13-22 pokazuje tę zmianę.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Pamiętaj, że celem funkcji search jest zwrócenie wszystkich wierszy w contents, które zawierają query. Podobnie jak w przykładzie filter w Listing 13-16, ten kod używa adaptera filter do zachowania tylko tych wierszy, dla których line.contains(query) zwraca true. Następnie zbieramy pasujące wiersze do innego wektora za pomocą collect. O wiele prościej! Zachęcamy do wprowadzenia tej samej zmiany, aby używać metod iteratora również w funkcji search_case_insensitive.
Dla dalszego ulepszenia, zwróć iterator z funkcji search poprzez usunięcie wywołania collect i zmianę typu zwracanego na impl Iterator<Item = &'a str>, tak aby funkcja stała się adapterem iteratora. Zauważ, że będziesz musiał również zaktualizować testy! Przeszukaj duży plik za pomocą narzędzia minigrep przed i po wprowadzeniu tej zmiany, aby zaobserwować różnicę w zachowaniu. Przed tą zmianą program nie wyświetli żadnych wyników, dopóki nie zbierze wszystkich wyników, ale po zmianie wyniki będą wyświetlane w miarę znajdowania każdej pasującej linii, ponieważ pętla for w funkcji run będzie mogła wykorzystać lenistwo iteratora.
Wybór między pętlami a iteratorami
Następne logiczne pytanie brzmi, jaki styl powinieneś wybrać w swoim kodzie i dlaczego: oryginalną implementację z Listing 13-21, czy wersję używającą iteratorów z Listing 13-22 (zakładając, że zbieramy wszystkie wyniki przed ich zwróceniem, a nie zwracamy iteratora). Większość programistów Rusta preferuje styl iteratorów. Na początku jest to trochę trudniejsze do opanowania, ale gdy już poczujesz się z różnymi adapterami iteratorów i tym, co robią, iteratory mogą być łatwiejsze do zrozumienia. Zamiast bawić się różnymi elementami pętli i budować nowe wektory, kod skupia się na ogólnym celu pętli. Abstrakcjonizuje to niektóre z typowych kodów, dzięki czemu łatwiej jest dostrzec koncepcje unikalne dla tego kodu, takie jak warunek filtrowania, który musi spełnić każdy element w iteratorze.
Ale czy te dwie implementacje są naprawdę równoważne? Intuicyjne założenie może być takie, że pętla niższego poziomu będzie szybsza. Porozmawiajmy o wydajności.
Wydajność w pętlach vs. iteratorach
Wydajność w pętlach vs. iteratorach
Aby zdecydować, czy użyć pętli, czy iteratorów, musisz wiedzieć, która implementacja jest szybsza: wersja funkcji search z jawną pętlą for czy wersja z iteratorami.
Przeprowadziliśmy benchmark, ładując całą zawartość Przygód Sherlocka Holmesa Sir Arthura Conana Doyle’a do String i szukając słowa the w zawartości. Oto wyniki benchmarku dla wersji search używającej pętli for i wersji używającej iteratorów:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Obie implementacje mają podobną wydajność! Nie będziemy tutaj wyjaśniać kodu benchmarku, ponieważ nie chodzi o udowodnienie, że obie wersje są równoważne, ale o ogólne rozeznanie, jak te dwie implementacje wypadają pod względem wydajności.
Aby uzyskać bardziej kompleksowy benchmark, powinieneś sprawdzić użycie różnych tekstów o różnych rozmiarach jako contents, różnych słów i słów o różnej długości jako query oraz wszelkiego rodzaju innych wariacji. Chodzi o to: iteratory, choć są abstrakcją wysokiego poziomu, są kompilowane do mniej więcej tego samego kodu, co gdybyś sam napisał kod niższego poziomu. Iteratory to jedna z abstrakcji zerokosztowych Rusta, co oznacza, że użycie abstrakcji nie narzuca żadnego dodatkowego narzutu czasowego. Jest to analogiczne do tego, jak Bjarne Stroustrup, oryginalny projektant i implementator C++, definiuje zerowy narzut w swoim przemówieniu inauguracyjnym ETAPS z 2012 roku „Foundations of C++”:
Ogólnie rzecz biorąc, implementacje C++ przestrzegają zasady zerowego narzutu: Czego nie używasz, za to nie płacisz. A dalej: Czego używasz, nie mógłbyś napisać ręcznie lepiej.
W wielu przypadkach kod Rusta używający iteratorów kompiluje się do tego samego assemblera, co kod napisany ręcznie. Stosowane są optymalizacje, takie jak rozwinięcie pętli i eliminacja sprawdzania zakresów przy dostępie do tablic, co sprawia, że wynikowy kod jest niezwykle wydajny. Teraz, gdy to wiesz, możesz bez obaw używać iteratorów i domknięć! Sprawiają, że kod wydaje się być na wyższym poziomie, ale nie narzucają kary za wydajność w czasie działania.
Podsumowanie
Domknięcia i iteratory to cechy Rusta inspirowane ideami programowania funkcyjnego. Przyczyniają się one do zdolności Rusta do wyraźnego wyrażania idei wysokiego poziomu z niskopoziomową wydajnością. Implementacje domknięć i iteratorów są takie, że wydajność w czasie działania nie jest naruszana. Jest to część celu Rusta, jakim jest dążenie do zapewnienia abstrakcji zerokosztowych.
Teraz, gdy ulepszyliśmy ekspresywność naszego projektu I/O, przyjrzyjmy się kilku innym funkcjom cargo, które pomogą nam udostępnić projekt światu.
Więcej o Cargo i Crates.io
Do tej pory używaliśmy tylko najbardziej podstawowych funkcji Cargo do budowania, uruchamiania i testowania naszego kodu, ale potrafi ono znacznie więcej. W tym rozdziale omówimy niektóre z jego innych, bardziej zaawansowanych funkcji, aby pokazać, jak:
- Dostosować kompilację za pomocą profili wydania.
- Publikować biblioteki na crates.io.
- Organizować duże projekty za pomocą obszarów roboczych.
- Instalować pliki binarne z crates.io.
- Rozszerzać Cargo za pomocą niestandardowych poleceń.
Cargo potrafi jeszcze więcej niż funkcjonalność, którą omówimy w tym rozdziale, więc aby uzyskać pełne wyjaśnienie wszystkich jego funkcji, zobacz jego dokumentację.
Dostosowywanie kompilacji za pomocą profili wydania
Dostosowywanie kompilacji za pomocą profili wydania
W Rust profile wydania to predefiniowane, dostosowywalne profile z różnymi konfiguracjami, które pozwalają programistom na większą kontrolę nad różnymi opcjami kompilacji kodu. Każdy profil jest konfigurowany niezależnie od innych.
Cargo ma dwa główne profile: profil dev, którego Cargo używa podczas uruchamiania cargo build, oraz profil release, którego Cargo używa podczas uruchamiania cargo build --release. Profil dev jest zdefiniowany z dobrymi wartościami domyślnymi do tworzenia oprogramowania, a profil release ma dobre wartości domyślne dla kompilacji wydania.
Te nazwy profili mogą być znane z danych wyjściowych Twoich kompilacji:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
dev i release to różne profile używane przez kompilator.
Cargo ma domyślne ustawienia dla każdego z profili, które są stosowane, gdy nie dodałeś jawnie żadnych sekcji [profile.*] do pliku Cargo.toml projektu. Dodając sekcje [profile.*] dla dowolnego profilu, który chcesz dostosować, nadpisujesz dowolny podzbiór domyślnych ustawień. Na przykład, oto domyślne wartości ustawienia opt-level dla profili dev i release:
Nazwa pliku: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Ustawienie opt-level kontroluje liczbę optymalizacji, które Rust zastosuje do Twojego kodu, w zakresie od 0 do 3. Zastosowanie większej liczby optymalizacji wydłuża czas kompilacji, więc jeśli jesteś w fazie rozwoju i często kompilujesz swój kod, będziesz chciał mniej optymalizacji, aby kompilować szybciej, nawet jeśli wynikowy kod będzie działał wolniej. Domyślny opt-level dla dev wynosi zatem 0. Kiedy jesteś gotowy do wydania swojego kodu, najlepiej poświęcić więcej czasu na kompilację. Skompilujesz w trybie wydania tylko raz, ale będziesz uruchamiać skompilowany program wiele razy, więc tryb wydania wymienia dłuższy czas kompilacji na szybszy kod. Dlatego domyślny opt-level dla profilu release wynosi 3.
Możesz nadpisać domyślne ustawienie, dodając dla niego inną wartość w Cargo.toml. Na przykład, jeśli chcemy użyć poziomu optymalizacji 1 w profilu deweloperskim, możemy dodać te dwie linie do pliku Cargo.toml naszego projektu:
Nazwa pliku: Cargo.toml
[profile.dev]
opt-level = 1
Ten kod nadpisuje domyślne ustawienie 0. Teraz, gdy uruchomimy cargo build, Cargo użyje domyślnych ustawień dla profilu dev plus nasze dostosowanie opt-level. Ponieważ ustawiliśmy opt-level na 1, Cargo zastosuje więcej optymalizacji niż domyślnie, ale nie tak wiele, jak w kompilacji wydania.
Aby uzyskać pełną listę opcji konfiguracji i wartości domyślnych dla każdego profilu, zobacz dokumentację Cargo.
Publikowanie pakietu na Crates.io
Publikowanie pakietu na Crates.io
Korzystaliśmy już z pakietów z crates.io jako zależności w naszych projektach, ale możesz również udostępniać swój kod innym osobom, publikując własne pakiety. Rejestr pakietów crates.io dystrybuuje kod źródłowy Twoich pakietów, więc hostuje głównie kod open source.
Rust i Cargo posiadają funkcje, które ułatwiają innym osobom odnalezienie i użycie opublikowanego pakietu. Następnie omówimy niektóre z tych funkcji, a potem wyjaśnimy, jak opublikować pakiet.
Tworzenie użytecznych komentarzy dokumentacji
Dokładne udokumentowanie Twoich pakietów pomoże innym użytkownikom zrozumieć, jak i kiedy ich używać, dlatego warto poświęcić czas na napisanie dokumentacji. W Rozdziale 3 omówiliśmy, jak komentować kod w Rust za pomocą dwóch ukośników, //. Rust ma również szczególny rodzaj komentarza do dokumentacji, znany wygodnie jako komentarz dokumentacji, który wygeneruje dokumentację HTML. HTML wyświetla zawartość komentarzy dokumentacji dla publicznych elementów API przeznaczonych dla programistów zainteresowanych sposobem użycia Twojego pakietu, w przeciwieństwie do sposobu implementacji Twojego pakietu.
Komentarze dokumentacji używają trzech ukośników, ///, zamiast dwóch i obsługują notację Markdown do formatowania tekstu. Umieść komentarze dokumentacji tuż przed elementem, który dokumentują. Listing 14-1 pokazuje komentarze dokumentacji dla funkcji add_one w pakiecie o nazwie my_crate.
/// Dodaje jeden do podanej liczby.
///
/// # Przykłady
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Tutaj podajemy opis tego, co robi funkcja add_one, rozpoczynamy sekcję z nagłówkiem Przykłady, a następnie podajemy kod, który demonstruje, jak używać funkcji add_one. Możemy wygenerować dokumentację HTML z tego komentarza dokumentacji, uruchamiając cargo doc. To polecenie uruchamia narzędzie rustdoc dystrybuowane z Rustem i umieszcza wygenerowaną dokumentację HTML w katalogu target/doc.
Dla wygody, uruchomienie cargo doc --open zbuduje HTML dla dokumentacji twojego bieżącego pakietu (a także dokumentację dla wszystkich zależności twojego pakietu) i otworzy wynik w przeglądarce internetowej. Przejdź do funkcji add_one i zobaczysz, jak tekst z komentarzy dokumentacji jest renderowany, jak pokazano na Rysunku 14-1.
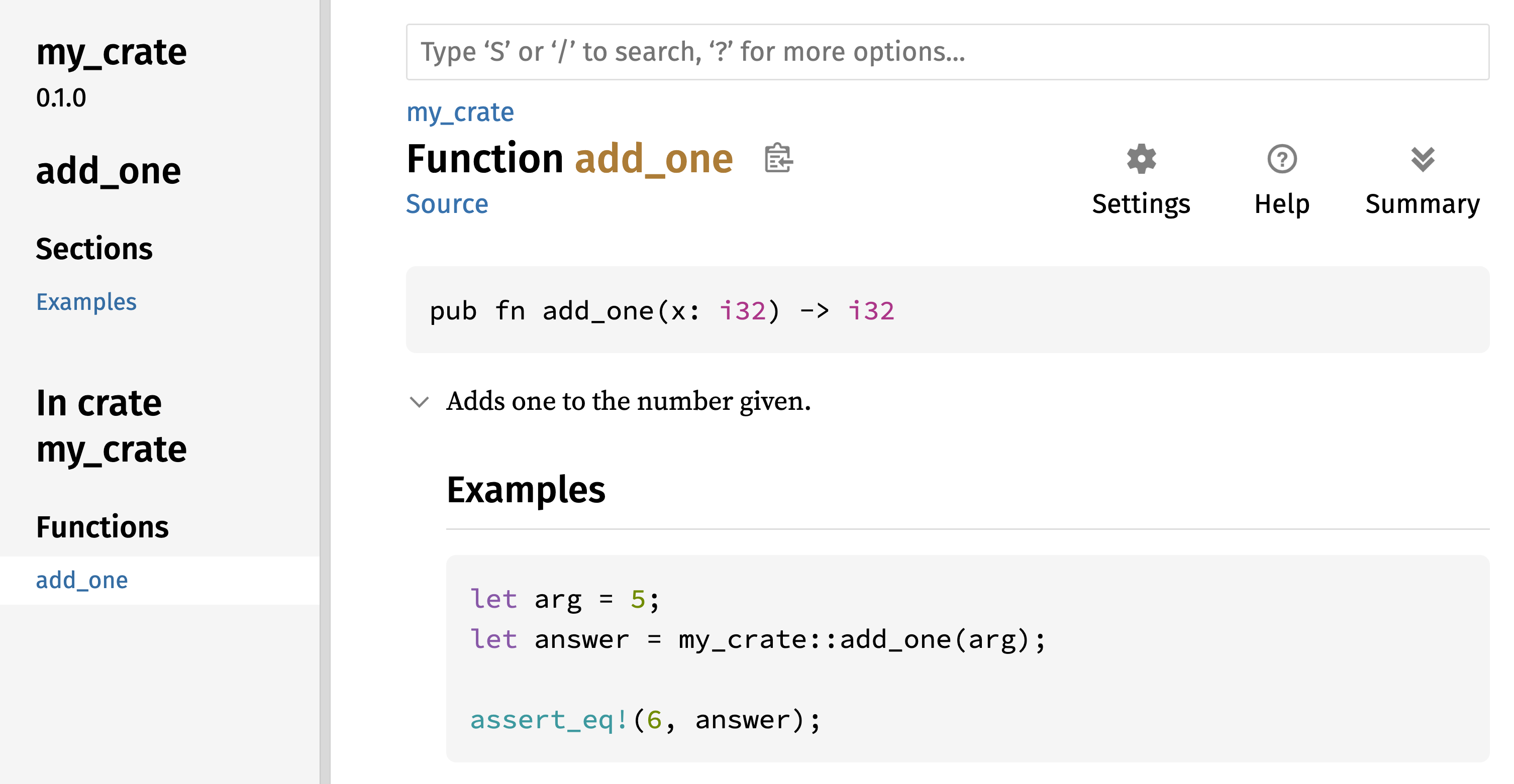
Rysunek 14-1: Dokumentacja HTML dla funkcji add_one
Często używane sekcje
Użyliśmy nagłówka Markdown # Przykłady w Listing 14-1, aby stworzyć sekcję w HTML z tytułem „Przykłady”. Oto inne sekcje, które autorzy pakietów często używają w swojej dokumentacji:
- Panics: Są to scenariusze, w których dokumentowana funkcja może wywołać panikę. Osoby wywołujące funkcję, które nie chcą, aby ich programy panikowały, powinny upewnić się, że nie wywołują funkcji w tych sytuacjach.
- Errors: Jeśli funkcja zwraca
Result, opisanie rodzajów błędów, które mogą wystąpić, i warunków, które mogą spowodować zwrócenie tych błędów, może być pomocne dla osób wywołujących, aby mogły napisać kod do obsługi różnych rodzajów błędów na różne sposoby. - Safety: Jeśli wywołanie funkcji jest
unsafe(niebezpieczne) (omawiamy niebezpieczeństwo w Rozdziale 20), powinna istnieć sekcja wyjaśniająca, dlaczego funkcja jest niebezpieczna i omawiająca niezmienniki, których funkcja oczekuje od osób wywołujących.
Większość komentarzy dokumentacyjnych nie potrzebuje wszystkich tych sekcji, ale jest to dobra lista kontrolna, która przypomina o aspektach Twojego kodu, którymi użytkownicy będą zainteresowani.
Komentarze dokumentacji jako testy
Dodawanie bloków kodu przykładu w komentarzach dokumentacji może pomóc zademonstrować, jak używać Twojej biblioteki i ma dodatkowy bonus: uruchomienie cargo test uruchomi przykłady kodu z Twojej dokumentacji jako testy! Nic nie jest lepsze niż dokumentacja z przykładami. Ale nic nie jest gorsze niż przykłady, które nie działają, ponieważ kod zmienił się od czasu napisania dokumentacji. Jeśli uruchomimy cargo test z dokumentacją dla funkcji add_one z Listing 14-1, zobaczymy sekcję w wynikach testów, która wygląda tak:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (linia 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Teraz, jeśli zmienimy funkcję lub przykład tak, że assert_eq! w przykładzie wywoła panikę, i ponownie uruchomimy cargo test, zobaczymy, że testy dokumentacji wykryją, że przykład i kod są niezsynchronizowane!
Komentarze do zawartych elementów
Styl komentarza dokumentacji //! dodaje dokumentację do elementu, który zawiera komentarze, a nie do elementów następujących po komentarzach. Zazwyczaj używamy tych komentarzy dokumentacji wewnątrz pliku głównego pakietu (src/lib.rs zgodnie z konwencją) lub wewnątrz modułu, aby udokumentować pakiet lub moduł jako całość.
Na przykład, aby dodać dokumentację opisującą cel pakietu my_crate, który zawiera funkcję add_one, dodajemy komentarze dokumentacji, które zaczynają się od //! na początku pliku src/lib.rs, jak pokazano w Listing 14-2.
//! # Mój Pakiet
//!
//! `my_crate` to zbiór narzędzi ułatwiających wykonywanie pewnych
//! obliczeń.
/// Dodaje jeden do podanej liczby.
// --snip--
///
/// # Przykłady
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Zauważ, że po ostatniej linii zaczynającej się od //! nie ma żadnego kodu. Ponieważ rozpoczęliśmy komentarze od //! zamiast ///, dokumentujemy element, który zawiera ten komentarz, a nie element, który następuje po tym komentarzu. W tym przypadku elementem jest plik src/lib.rs, który jest korzeniem pakietu. Te komentarze opisują cały pakiet.
Kiedy uruchomimy cargo doc --open, te komentarze zostaną wyświetlone na stronie głównej dokumentacji my_crate powyżej listy publicznych elementów w pakiecie, jak pokazano na Rysunku 14-2.
Komentarze dokumentacyjne wewnątrz elementów są szczególnie przydatne do opisywania pakietów i modułów. Używaj ich do wyjaśniania ogólnego celu kontenera, aby pomóc użytkownikom zrozumieć organizację pakietu.
Rysunek 14-2: Wyrenderowana dokumentacja dla my_crate, zawierająca komentarz opisujący cały pakiet
Eksportowanie wygodnego publicznego API
Struktura publicznego API jest kluczową kwestią podczas publikowania pakietu. Osoby korzystające z twojego pakietu są mniej zaznajomione z jego strukturą niż ty i mogą mieć trudności ze znalezieniem elementów, których chcą użyć, jeśli twój pakiet ma dużą hierarchię modułów.
W Rozdziale 7 omówiliśmy, jak uczynić elementy publicznymi za pomocą słowa kluczowego pub oraz jak wprowadzić elementy do zakresu za pomocą słowa kluczowego use. Jednak struktura, która ma sens dla Ciebie podczas tworzenia pakietu, może nie być zbyt wygodna dla Twoich użytkowników. Możesz chcieć zorganizować swoje struktury w hierarchii zawierającej wiele poziomów, ale wtedy osoby, które chcą użyć typu zdefiniowanego głęboko w hierarchii, mogą mieć trudności z odkryciem, że taki typ istnieje. Mogą również być zirytowane koniecznością wpisywania use my_crate::some_module::another_module::UsefulType; zamiast use my_crate::UsefulType;.
Dobrą wiadomością jest to, że jeśli struktura nie jest wygodna do użycia z innej biblioteki, nie musisz zmieniać swojej wewnętrznej organizacji: zamiast tego możesz ponownie eksportować elementy, aby stworzyć publiczną strukturę, która różni się od Twojej prywatnej struktury, używając pub use. Ponowne eksportowanie pobiera publiczny element w jednym miejscu i udostępnia go publicznie w innym miejscu, tak jakby był zdefiniowany w tym innym miejscu.
Na przykład, powiedzmy, że stworzyliśmy bibliotekę o nazwie art do modelowania pojęć artystycznych. W tej bibliotece znajdują się dwa moduły: moduł kinds zawierający dwa wyliczenia o nazwach PrimaryColor i SecondaryColor oraz moduł utils zawierający funkcję o nazwie mix, jak pokazano w Listing 14-3.
//! # Sztuka
//!
//! Biblioteka do modelowania koncepcji artystycznych.
pub mod kinds {
/// Kolory podstawowe według modelu kolorów RYB.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// Kolory wtórne według modelu kolorów RYB.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Łączy dwa kolory podstawowe w równych proporcjach, aby stworzyć
/// kolor wtórny.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}Rysunek 14-3 pokazuje, jak wyglądałaby strona główna dokumentacji dla tego pakietu wygenerowana przez cargo doc.
Rysunek 14-3: Strona główna dokumentacji dla art, która zawiera listę modułów kinds i utils
Zauważ, że typy PrimaryColor i SecondaryColor nie są wymienione na stronie głównej, podobnie jak funkcja mix. Musimy kliknąć kinds i utils, aby je zobaczyć.
Inny pakiet, który zależy od tej biblioteki, potrzebowałby instrukcji use, które wprowadzają elementy z art do zakresu, określając strukturę modułu, która jest aktualnie zdefiniowana. Listing 14-4 pokazuje przykład pakietu, który używa elementów PrimaryColor i mix z pakietu art.
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Autor kodu w Listing 14-4, który używa pakietu art, musiał dowiedzieć się, że PrimaryColor znajduje się w module kinds, a mix w module utils. Struktura modułów pakietu art jest bardziej istotna dla programistów pracujących nad pakietem art niż dla tych, którzy go używają. Wewnętrzna struktura nie zawiera żadnych użytecznych informacji dla kogoś próbującego zrozumieć, jak używać pakietu art, ale raczej powoduje zamieszanie, ponieważ programiści, którzy go używają, muszą dowiedzieć się, gdzie szukać i muszą określać nazwy modułów w instrukcjach use.
Aby usunąć wewnętrzną organizację z publicznego API, możemy zmodyfikować kod pakietu art w Listing 14-3, aby dodać instrukcje pub use do ponownego eksportu elementów na najwyższym poziomie, jak pokazano w Listing 14-5.
//! # Sztuka
//!
//! Biblioteka do modelowania koncepcji artystycznych.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// Kolory podstawowe według modelu kolorów RYB.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// Kolory wtórne według modelu kolorów RYB.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Łączy dwa kolory podstawowe w równych proporcjach, aby stworzyć
/// kolor wtórny.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}Dokumentacja API wygenerowana przez cargo doc dla tego pakietu będzie teraz listować i linkować ponowne eksporty na stronie głównej, jak pokazano na Rysunku 14-4, ułatwiając znalezienie typów PrimaryColor i SecondaryColor oraz funkcji mix.
Rysunek 14-4: Strona główna dokumentacji dla art, która zawiera listę ponownych eksportów
Użytkownicy pakietu art nadal mogą przeglądać i używać wewnętrznej struktury z Listing 14-3, jak zademonstrowano w Listing 14-4, lub mogą używać bardziej wygodnej struktury z Listing 14-5, jak pokazano w Listing 14-6.
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}W przypadkach, gdy istnieje wiele zagnieżdżonych modułów, ponowne eksportowanie typów na najwyższym poziomie za pomocą pub use może znacznie wpłynąć na doświadczenie osób korzystających z pakietu. Innym częstym zastosowaniem pub use jest ponowne eksportowanie definicji zależności w bieżącym pakiecie, aby definicje tego pakietu stały się częścią publicznego API Twojego pakietu.
Tworzenie użytecznej struktury publicznego API to bardziej sztuka niż nauka, a Ty możesz iterować, aby znaleźć API, które najlepiej pasuje do Twoich użytkowników. Wybór pub use daje Ci elastyczność w wewnętrznej strukturze pakietu i oddziela tę wewnętrzną strukturę od tego, co prezentujesz użytkownikom. Przyjrzyj się kodowi niektórych zainstalowanych pakietów, aby sprawdzić, czy ich wewnętrzna struktura różni się od ich publicznego API.
Konfigurowanie konta Crates.io
Zanim będziesz mógł publikować jakiekolwiek pakiety, musisz utworzyć konto na crates.io i uzyskać token API. Aby to zrobić, odwiedź stronę główną crates.io i zaloguj się za pomocą konta GitHub. (Konto GitHub jest obecnie wymagane, ale witryna może w przyszłości obsługiwać inne sposoby tworzenia konta.) Po zalogowaniu odwiedź ustawienia swojego konta pod adresem https://crates.io/me/ i pobierz swój klucz API. Następnie uruchom polecenie cargo login i wklej swój klucz API po wyświetleniu monitu, w następujący sposób:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
To polecenie poinformuje Cargo o Twoim tokenie API i zapisze go lokalnie w ~/.cargo/credentials.toml. Zauważ, że ten token jest tajny: nie udostępniaj go nikomu. Jeśli z jakiegoś powodu go udostępnisz, powinieneś go unieważnić i wygenerować nowy token na crates.io.
Dodawanie metadanych do nowego pakietu
Powiedzmy, że masz pakiet, który chcesz opublikować. Przed publikacją musisz dodać kilka metadanych w sekcji [package] pliku Cargo.toml pakietu.
Twój pakiet będzie potrzebował unikalnej nazwy. Podczas pracy nad pakietem lokalnie, możesz nazwać pakiet jak chcesz. Jednak nazwy pakietów na crates.io są przydzielane na zasadzie „kto pierwszy, ten lepszy”. Gdy nazwa pakietu zostanie zajęta, nikt inny nie może opublikować pakietu o tej nazwie. Przed próbą publikacji pakietu, wyszukaj nazwę, której chcesz użyć. Jeśli nazwa została użyta, będziesz musiał znaleźć inną nazwę i edytować pole name w pliku Cargo.toml w sekcji [package], aby użyć nowej nazwy do publikacji, w następujący sposób:
Nazwa pliku: Cargo.toml
[package]
name = "guessing_game"
Nawet jeśli wybrałeś unikalną nazwę, kiedy uruchomisz cargo publish, aby opublikować pakiet w tym momencie, otrzymasz ostrzeżenie, a następnie błąd:
$ cargo publish
Aktualizowanie indeksu crates.io
warning: manifest nie ma opisu, licencji, pliku licencyjnego, dokumentacji, strony głównej lub repozytorium.
Zobacz https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata aby uzyskać więcej informacji.
--snip--
error: nie udało się opublikować w rejestrze pod adresem https://crates.io
Spowodowane przez:
zdalny serwer odpowiedział błędem (status 400 Bad Request): brakujące lub puste pola metadanych: description, license. Zobacz https://doc.rust-lang.org/cargo/reference/manifest.html, aby uzyskać więcej informacji na temat konfiguracji tych pól
Prowadzi to do błędu, ponieważ brakuje Ci pewnych kluczowych informacji: opis i licencja są wymagane, aby ludzie wiedzieli, co robi Twój pakiet i na jakich warunkach mogą go używać. W Cargo.toml dodaj opis składający się z jednego lub dwóch zdań, ponieważ będzie on wyświetlany wraz z Twoim pakietem w wynikach wyszukiwania. Dla pola license musisz podać wartość identyfikatora licencji. Software Package Data Exchange (SPDX) Fundacji Linuksa wymienia identyfikatory, których możesz użyć dla tej wartości. Na przykład, aby określić, że licencjonowałeś swój pakiet za pomocą licencji MIT, dodaj identyfikator MIT:
Nazwa pliku: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Jeśli chcesz użyć licencji, która nie pojawia się w SPDX, musisz umieścić tekst tej licencji w pliku, dołączyć ten plik do swojego projektu, a następnie użyć license-file, aby określić nazwę tego pliku zamiast używania klucza license.
Porady dotyczące wyboru odpowiedniej licencji dla Twojego projektu wykraczają poza zakres tej książki. Wiele osób w społeczności Rusta licencjonuje swoje projekty w ten sam sposób co Rust, używając podwójnej licencji MIT OR Apache-2.0. Ta praktyka pokazuje, że możesz również określić wiele identyfikatorów licencji oddzielonych OR, aby mieć wiele licencji dla swojego projektu.
Po dodaniu unikalnej nazwy, wersji, opisu i licencji, plik Cargo.toml dla projektu gotowego do publikacji może wyglądać następująco:
Nazwa pliku: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "Ciekawa gra, w której zgadujesz liczbę wybraną przez komputer."
license = "MIT OR Apache-2.0"
[dependencies]
Dokumentacja Cargo opisuje inne metadane, które można określić, aby inni mogli łatwiej odkryć i używać Twojego pakietu.
Publikowanie na Crates.io
Teraz, gdy utworzyłeś konto, zapisałeś swój token API, wybrałeś nazwę dla swojego pakietu i określiłeś wymagane metadane, jesteś gotowy do publikacji! Publikowanie pakietu przesyła konkretną wersję do crates.io, aby inni mogli z niej korzystać.
Bądź ostrożny, ponieważ publikacja jest trwała. Wersja nigdy nie może zostać nadpisana, a kod nie może zostać usunięty, z wyjątkiem pewnych okoliczności. Jednym z głównych celów Crates.io jest pełnienie funkcji stałego archiwum kodu, tak aby kompilacje wszystkich projektów, które zależą od pakietów z crates.io, nadal działały. Dopuszczenie usuwania wersji uniemożliwiłoby osiągnięcie tego celu. Nie ma jednak limitu liczby wersji pakietów, które możesz opublikować.
Uruchom ponownie polecenie cargo publish. Powinno się teraz udać:
$ cargo publish
Aktualizowanie indeksu crates.io
Pakowanie guessing_game v0.1.0 (file:///projects/guessing_game)
Spakowano 6 plików, 1.2KiB (895.0B skompresowanych)
Weryfikowanie guessing_game v0.1.0 (file:///projects/guessing_game)
Kompilowanie guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Zakończono `dev` profil [unoptimized + debuginfo] cel(e) w 0.19s
Przesyłanie guessing_game v0.1.0 (file:///projects/guessing_game)
Przesłano guessing_game v0.1.0 do rejestru `crates-io`
note: oczekiwanie na dostępność `guessing_game v0.1.0` w rejestrze
`crates-io`. Możesz nacisnąć ctrl-c, aby pominąć oczekiwanie; pakiet powinien być dostępny wkrótce.
Opublikowano guessing_game v0.1.0 w rejestrze `crates-io`
Gratulacje! Udostępniłeś swój kod społeczności Rusta, a każdy może łatwo dodać Twój pakiet jako zależność swojego projektu.
Publikowanie nowej wersji istniejącego pakietu
Kiedy wprowadzisz zmiany w swoim pakiecie i będziesz gotowy do wydania nowej wersji, zmieniasz wartość version określoną w pliku Cargo.toml i publikujesz ponownie. Użyj zasad Semantycznego Wersjonowania, aby zdecydować, jaki jest odpowiedni numer następnej wersji, w oparciu o rodzaj wprowadzonych zmian. Następnie uruchom cargo publish, aby przesłać nową wersję.
Wycofywanie wersji z Crates.io
Chociaż nie możesz usuwać poprzednich wersji pakietu, możesz uniemożliwić przyszłym projektom dodawanie ich jako nowych zależności. Jest to przydatne, gdy wersja pakietu jest zepsuta z jakiegoś powodu. W takich sytuacjach Cargo obsługuje wycofanie wersji pakietu.
Wycofanie wersji zapobiega zależnościom nowych projektów od tej wersji, jednocześnie umożliwiając wszystkim istniejącym projektom, które są od niej zależne, dalsze działanie. Zasadniczo, wycofanie oznacza, że wszystkie projekty z plikiem Cargo.lock nie zostaną zepsute, a żadne przyszłe pliki Cargo.lock nie będą używać wycofanej wersji.
Aby wycofać wersję pakietu, w katalogu pakietu, który wcześniej opublikowałeś, uruchom cargo yank i określ, którą wersję chcesz wycofać. Na przykład, jeśli opublikowaliśmy pakiet o nazwie guessing_game w wersji 1.0.1 i chcemy go wycofać, uruchomimy następujące polecenie w katalogu projektu guessing_game:
$ cargo yank --vers 1.0.1
Aktualizowanie indeksu crates.io
Wycofuję guessing_game@1.0.1
Dodając --undo do polecenia, możesz również cofnąć wycofanie i ponownie zezwolić projektom na zależność od danej wersji:
$ cargo yank --vers 1.0.1 --undo
Aktualizowanie indeksu crates.io
Przywracam guessing_game@1.0.1
Wycofanie nie usuwa żadnego kodu. Nie może na przykład usunąć przypadkowo przesłanych sekretów. Jeśli tak się stanie, musisz natychmiast zresetować te sekrety.
Obszary robocze Cargo
Obszary robocze Cargo
W Rozdziale 12 zbudowaliśmy pakiet, który zawierał binarny crate i biblioteczny crate. W miarę rozwoju projektu może się okazać, że biblioteczny crate staje się coraz większy i chcesz podzielić swój pakiet na wiele bibliotecznych crate’ów. Cargo oferuje funkcję o nazwie workspaces (obszary robocze), która może pomóc w zarządzaniu wieloma powiązanymi pakietami, które są rozwijane równocześnie.
Tworzenie obszaru roboczego
Obszar roboczy to zestaw pakietów, które współdzielą ten sam plik Cargo.lock i katalog wyjściowy. Stwórzmy projekt z wykorzystaniem obszaru roboczego — użyjemy trywialnego kodu, abyśmy mogli skupić się na strukturze obszaru roboczego. Istnieje wiele sposobów na strukturę obszaru roboczego, więc pokażemy tylko jeden powszechny. Będziemy mieć obszar roboczy zawierający binarny pakiet i dwie biblioteki. Binarny pakiet, który zapewni główną funkcjonalność, będzie zależał od dwóch bibliotek. Jedna biblioteka zapewni funkcję add_one, a druga biblioteka funkcję add_two. Te trzy pakiety będą częścią tego samego obszaru roboczego. Zaczniemy od utworzenia nowego katalogu dla obszaru roboczego:
$ mkdir add
$ cd add
Następnie, w katalogu add, tworzymy plik Cargo.toml, który skonfiguruje cały obszar roboczy. Ten plik nie będzie miał sekcji [package]. Zamiast tego, zacznie się od sekcji [workspace], która pozwoli nam dodawać członków do obszaru roboczego. Zwracamy również uwagę na użycie najnowszej i najlepszej wersji algorytmu resolvera Cargo w naszym obszarze roboczym, ustawiając wartość resolver na "3":
Nazwa pliku: Cargo.toml
[workspace]
resolver = "3"
Następnie utworzymy binarny pakiet adder poprzez uruchomienie cargo new w katalogu add:
$ cargo new adder
Utworzono pakiet binarny (aplikacja) `adder`
Dodawanie `adder` jako członka obszaru roboczego pod `file:///projects/add`
Uruchomienie cargo new wewnątrz obszaru roboczego automatycznie dodaje nowo utworzony pakiet do klucza members w definicji [workspace] w pliku Cargo.toml obszaru roboczego, w następujący sposób:
[workspace]
resolver = "3"
members = ["adder"]
W tym momencie możemy zbudować obszar roboczy, uruchamiając cargo build. Pliki w katalogu add powinny wyglądać następująco:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Obszar roboczy posiada jeden katalog target na najwyższym poziomie, do którego zostaną umieszczone skompilowane artefakty; pakiet adder nie ma własnego katalogu target. Nawet gdybyśmy uruchomili cargo build z wnętrza katalogu adder, skompilowane artefakty nadal znalazłyby się w add/target, a nie add/adder/target. Cargo strukturyzuje katalog target w obszarze roboczym w ten sposób, ponieważ pakiety w obszarze roboczym mają od siebie zależeć. Gdyby każdy pakiet miał własny katalog target, każdy pakiet musiałby rekompilować każdy z pozostałych pakietów w obszarze roboczym, aby umieścić artefakty w swoim własnym katalogu target. Dzięki współdzieleniu jednego katalogu target pakiety mogą uniknąć niepotrzebnej ponownej kompilacji.
Tworzenie drugiego pakietu w obszarze roboczym
Następnie stwórzmy kolejny pakiet członkowski w obszarze roboczym i nazwijmy go add_one. Wygeneruj nowy pakiet biblioteczny o nazwie add_one:
$ cargo new add_one --lib
Utworzono bibliotekę `add_one`
Dodawanie `add_one` jako członka obszaru roboczego pod `file:///projects/add`
Plik Cargo.toml na najwyższym poziomie będzie teraz zawierał ścieżkę add_one na liście members:
Nazwa pliku: Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
Twój katalog add powinien teraz zawierać następujące katalogi i pliki:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
W pliku add_one/src/lib.rs dodajmy funkcję add_one:
Nazwa pliku: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}Teraz pakiet adder z naszym plikiem binarnym może zależeć od pakietu add_one, który zawiera naszą bibliotekę. Najpierw będziemy musieli dodać zależność ścieżkową do add_one do pliku adder/Cargo.toml.
Nazwa pliku: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo nie zakłada, że pakiety w obszarze roboczym będą od siebie zależeć, więc musimy jawnie określić relacje zależności.
Następnie, użyjmy funkcji add_one (z pakietu add_one) w pakiecie adder. Otwórz plik adder/src/main.rs i zmień funkcję main, aby wywoływała funkcję add_one, jak w Listing 14-7.
fn main() {
let num = 10;
println!("Witaj, świecie! {num} plus jeden to {}!", add_one::add_one(num));
}Zbudujmy obszar roboczy, uruchamiając cargo build w katalogu add na najwyższym poziomie!
$ cargo build
Kompilowanie add_one v0.1.0 (file:///projects/add/add_one)
Kompilowanie adder v0.1.0 (file:///projects/add/adder)
Zakończono `dev` profil [unoptimized + debuginfo] cel(e) w 0.22s
Aby uruchomić binarny pakiet z katalogu add, możemy określić, który pakiet w obszarze roboczym chcemy uruchomić, używając argumentu -p i nazwy pakietu z cargo run:
$ cargo run -p adder
Zakończono `dev` profil [unoptimized + debuginfo] cel(e) w 0.00s
Uruchamianie `target/debug/adder`
Witaj, świecie! 10 plus jeden to 11!
To uruchamia kod z adder/src/main.rs, który zależy od pakietu add_one.
Zależność od zewnętrznego pakietu
Zauważ, że obszar roboczy ma tylko jeden plik Cargo.lock na najwyższym poziomie, zamiast mieć plik Cargo.lock w katalogu każdego pakietu. To zapewnia, że wszystkie pakiety używają tej samej wersji wszystkich zależności. Jeśli dodamy pakiet rand do plików adder/Cargo.toml i add_one/Cargo.toml, Cargo rozwiąże oba do jednej wersji rand i zapisze to w jednym pliku Cargo.lock. Sprawienie, by wszystkie pakiety w obszarze roboczym używały tych samych zależności, oznacza, że pakiety zawsze będą ze sobą kompatybilne. Dodajmy pakiet rand do sekcji [dependencies] w pliku add_one/Cargo.toml, abyśmy mogli używać pakietu rand w pakiecie add_one:
Nazwa pliku: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
Możemy teraz dodać use rand; do pliku add_one/src/lib.rs, a zbudowanie całego obszaru roboczego przez uruchomienie cargo build w katalogu add spowoduje zaimportowanie i skompilowanie pakietu rand. Otrzymamy jedno ostrzeżenie, ponieważ nie odwołujemy się do rand, które wprowadziliśmy do zakresu:
$ cargo build
Aktualizowanie indeksu crates.io
Pobrano rand v0.8.5
--snip--
Kompilowanie rand v0.8.5
Kompilowanie add_one v0.1.0 (file:///projects/add/add_one)
warning: nieużywany import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` domyślnie włączone
warning: `add_one` (lib) wygenerował 1 ostrzeżenie (uruchom `cargo fix --lib -p add_one`, aby zastosować 1 sugestię)
Kompilowanie adder v0.1.0 (file:///projects/add/adder)
Zakończono `dev` profil [unoptimized + debuginfo] cel(e) w 0.95s
Plik Cargo.lock na najwyższym poziomie zawiera teraz informacje o zależności add_one od rand. Jednakże, mimo że rand jest używane gdzieś w obszarze roboczym, nie możemy go używać w innych pakietach w obszarze roboczym, chyba że dodamy rand również do ich plików Cargo.toml. Na przykład, jeśli dodamy use rand; do pliku adder/src/main.rs dla pakietu adder, otrzymamy błąd:
$ cargo build
--snip--
Kompilowanie adder v0.1.0 (file:///projects/add/adder)
error[E0432]: nierozwiązany import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ brak zewnętrznego pakietu `rand`
Aby to naprawić, edytuj plik Cargo.toml pakietu adder i wskaż, że rand jest również jego zależnością. Budowanie pakietu adder doda rand do listy zależności dla adder w Cargo.lock, ale nie zostaną pobrane żadne dodatkowe kopie rand. Cargo zapewni, że każdy pakiet w obszarze roboczym używający pakietu rand będzie używał tej samej wersji, o ile określą kompatybilne wersje rand, oszczędzając nam miejsce i zapewniając, że pakiety w obszarze roboczym będą ze sobą kompatybilne.
Jeśli pakiety w obszarze roboczym określają niekompatybilne wersje tej samej zależności, Cargo rozwiąże każdą z nich, ale nadal będzie starało się rozwiązać jak najmniej wersji.
Dodawanie testu do obszaru roboczego
Dla kolejnego ulepszenia, dodajmy test funkcji add_one::add_one w pakiecie add_one:
Nazwa pliku: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Teraz uruchom cargo test w katalogu add najwyższego poziomu. Uruchomienie cargo test w tak skonstruowanym obszarze roboczym uruchomi testy dla wszystkich pakietów w obszarze roboczym:
$ cargo test
Kompilowanie add_one v0.1.0 (file:///projects/add/add_one)
Kompilowanie adder v0.1.0 (file:///projects/add/adder)
Zakończono `test` profil [unoptimized + debuginfo] cel(e) w 0.20s
Uruchamianie unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Uruchamianie unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Pierwsza sekcja wyjścia pokazuje, że test it_works w pakiecie add_one przeszedł. Następna sekcja pokazuje, że w pakiecie adder nie znaleziono żadnych testów, a następnie ostatnia sekcja pokazuje, że w pakiecie add_one nie znaleziono żadnych testów dokumentacji.
Możemy również uruchomić testy dla jednego konkretnego pakietu w obszarze roboczym z katalogu najwyższego poziomu, używając flagi -p i określając nazwę pakietu, który chcemy przetestować:
$ cargo test -p add_one
Zakończono `test` profil [unoptimized + debuginfo] cel(e) w 0.00s
Uruchamianie unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
To wyjście pokazuje, że cargo test uruchomił tylko testy dla pakietu add_one i nie uruchomił testów pakietu adder.
Jeśli opublikujesz pakiety w obszarze roboczym na crates.io, każdy pakiet w obszarze roboczym będzie musiał zostać opublikowany osobno. Podobnie jak cargo test, możemy opublikować konkretny pakiet w naszym obszarze roboczym, używając flagi -p i określając nazwę pakietu, który chcemy opublikować.
Dodatkowo, spróbuj dodać pakiet add_two do tego obszaru roboczego w podobny sposób jak pakiet add_one!
W miarę wzrostu projektu rozważ użycie obszaru roboczego: pozwala on na pracę z mniejszymi, łatwiejszymi do zrozumienia komponentami niż jedna duża bryła kodu. Ponadto, utrzymywanie pakietów w obszarze roboczym może ułatwić koordynację między pakietami, jeśli często są zmieniane w tym samym czasie.
Instalowanie binariów za pomocą cargo install
Instalowanie binariów za pomocą cargo install
Polecenie cargo install pozwala instalować i używać lokalnie binarne pakiety. Nie ma ono na celu zastąpienia pakietów systemowych; ma być wygodnym sposobem dla programistów Rust na instalowanie narzędzi, które inni udostępnili na crates.io. Zauważ, że możesz instalować tylko pakiety, które mają binarne cele. Cel binarny to uruchamialny program, który jest tworzony, jeśli pakiet ma plik src/main.rs lub inny plik określony jako binarny, w przeciwieństwie do celu bibliotecznego, który nie jest uruchamialny sam w sobie, ale nadaje się do włączenia do innych programów. Zazwyczaj pakiety mają w pliku README informacje o tym, czy dany pakiet jest biblioteką, ma cel binarny, czy jedno i drugie.
Wszystkie pliki binarne zainstalowane za pomocą cargo install są przechowywane w folderze bin katalogu instalacyjnego. Jeśli zainstalowałeś Rust za pomocą rustup.rs i nie masz żadnych niestandardowych konfiguracji, ten katalog będzie $HOME/.cargo/bin. Upewnij się, że ten katalog znajduje się w Twojej zmiennej $PATH, aby móc uruchamiać programy zainstalowane za pomocą cargo install.
Na przykład, w Rozdziale 12 wspomnieliśmy, że istnieje implementacja narzędzia grep w Rust o nazwie ripgrep do przeszukiwania plików. Aby zainstalować ripgrep, możemy uruchomić następujące polecenie:
$ cargo install ripgrep
Aktualizowanie indeksu crates.io
Pobrano ripgrep v14.1.1
Pobrano 1 pakiet (213.6 KB) w 0.40s
Instalowanie ripgrep v14.1.1
--snip--
Kompilowanie grep v0.3.2
Zakończono `release` profil [optimized + debuginfo] cel(e) w 6.73s
Instalowanie ~/.cargo/bin/rg
Zainstalowano pakiet `ripgrep v14.1.1` (wykonywalny `rg`)
Druga od końca linia wyjścia pokazuje lokalizację i nazwę zainstalowanego pliku binarnego, którym w przypadku ripgrep jest rg. Dopóki katalog instalacyjny znajduje się w Twoim $PATH, jak wspomniano wcześniej, możesz uruchomić rg --help i zacząć używać szybszego, bardziej „rusty” narzędzia do przeszukiwania plików!
Rozszerzanie Cargo o niestandardowe polecenia
Rozszerzanie Cargo o niestandardowe polecenia
Cargo zostało zaprojektowane tak, aby można było je rozszerzać o nowe podpolecenia bez konieczności modyfikowania. Jeśli plik binarny w Twojej $PATH ma nazwę cargo-coś, możesz uruchomić go tak, jakby był podpoleceniem Cargo, uruchamiając cargo coś. Niestandardowe polecenia tego typu są również wyświetlane po uruchomieniu cargo --list. Możliwość użycia cargo install do instalowania rozszerzeń, a następnie uruchamiania ich tak samo jak wbudowanych narzędzi Cargo, jest bardzo wygodną zaletą projektu Cargo!
Podsumowanie
Udostępnianie kodu za pomocą Cargo i crates.io jest częścią tego, co sprawia, że ekosystem Rusta jest użyteczny do wielu różnych zadań. Standardowa biblioteka Rusta jest mała i stabilna, ale pakiety są łatwe do udostępniania, używania i ulepszania w innym tempie niż język. Nie krępuj się udostępniać kodu, który jest dla Ciebie użyteczny, na crates.io; prawdopodobnie będzie on użyteczny również dla kogoś innego!
Inteligentne wskaźniki
Wskaźnik to ogólne pojęcie dla zmiennej, która zawiera adres w pamięci. Ten adres odwołuje się do, czyli „wskazuje na”, inne dane. Najczęstszym rodzajem wskaźnika w Rust jest referencja, o której uczyłeś się w Rozdziale 4. Referencje są wskazywane symbolem & i pożyczają wartość, na którą wskazują. Nie mają żadnych specjalnych możliwości poza odwoływaniem się do danych i nie mają żadnych narzutów.
Inteligentne wskaźniki natomiast to struktury danych, które zachowują się jak wskaźnik, ale mają również dodatkowe metadane i możliwości. Koncepcja inteligentnych wskaźników nie jest unikalna dla Rusta: inteligentne wskaźniki powstały w C++ i istnieją również w innych językach. Rust posiada różnorodne inteligentne wskaźniki zdefiniowane w standardowej bibliotece, które zapewniają funkcjonalność wykraczającą poza tę zapewnianą przez referencje. Aby zbadać ogólne pojęcie, przyjrzymy się kilku różnym przykładom inteligentnych wskaźników, w tym typowi inteligentnego wskaźnika z licznikiem referencji. Ten wskaźnik umożliwia posiadanie wielu właścicieli danych poprzez śledzenie liczby właścicieli i, gdy nie ma już właścicieli, oczyszczanie danych.
W Rust, z jego koncepcją własności i pożyczania, istnieje dodatkowa różnica między referencjami a inteligentnymi wskaźnikami: podczas gdy referencje tylko pożyczają dane, w wielu przypadkach inteligentne wskaźniki posiadają dane, na które wskazują.
Inteligentne wskaźniki są zazwyczaj implementowane za pomocą struktur. W przeciwieństwie do zwykłej struktury, inteligentne wskaźniki implementują cechy Deref i Drop. Cecha Deref pozwala instancji struktury inteligentnego wskaźnika zachowywać się jak referencja, dzięki czemu można pisać kod, który działa zarówno z referencjami, jak i inteligentnymi wskaźnikami. Cecha Drop pozwala dostosować kod, który jest uruchamiany, gdy instancja inteligentnego wskaźnika wychodzi poza zakres. W tym rozdziale omówimy obie te cechy i zademonstrujemy, dlaczego są one ważne dla inteligentnych wskaźników.
Biorąc pod uwagę, że wzorzec inteligentnego wskaźnika jest ogólnym wzorcem projektowym często używanym w Rust, ten rozdział nie obejmie każdego istniejącego inteligentnego wskaźnika. Wiele bibliotek ma własne inteligentne wskaźniki, a nawet możesz napisać własny. Omówimy najbardziej popularne inteligentne wskaźniki w standardowej bibliotece:
Box<T>, do alokowania wartości na stercieRc<T>, typ zliczający referencje, który umożliwia wielokrotne posiadanieRef<T>iRefMut<T>, dostępne przezRefCell<T>, typ, który wymusza zasady pożyczania w czasie działania zamiast w czasie kompilacji
Ponadto omówimy wzorzec wewnętrznej zmienności, w którym niezmienny typ udostępnia API do mutowania wartości wewnętrznej. Omówimy również cykle referencji: jak mogą prowadzić do wycieków pamięci i jak im zapobiegać.
Zaczynajmy!
Użycie Box<T> do wskazywania na dane na stercie
Użycie Box<T> do wskazywania na dane na stercie
Najprostszym inteligentnym wskaźnikiem jest pudełko, którego typ zapisuje się
jako Box<T>. Pudełka pozwalają przechowywać dane na stercie zamiast na
stosie. To, co pozostaje na stosie, to wskaźnik do danych na stercie.
Odwołaj się do Rozdziału 4, aby zapoznać się z różnicą między stosem a stertą.
Pudełka nie mają narzutu wydajnościowego, poza przechowywaniem danych na stercie zamiast na stosie. Ale nie mają też wielu dodatkowych możliwości. Będziesz ich używać najczęściej w następujących sytuacjach:
- Kiedy masz typ, którego rozmiar nie może być znany w czasie kompilacji, i chcesz użyć wartości tego typu w kontekście, który wymaga dokładnego rozmiaru
- Kiedy masz dużą ilość danych i chcesz przenieść własność, ale upewnić się, że dane nie zostaną skopiowane, gdy to zrobisz
- Kiedy chcesz być właścicielem wartości, a zależy ci tylko na tym, aby była to typ, który implementuje określoną cechę, zamiast być konkretnym typem
Pokażemy pierwszą sytuację w sekcji „Włączanie typów rekurencyjnych za pomocą pudełek”. W drugim przypadku przeniesienie własności dużej ilości danych może zająć dużo czasu, ponieważ dane są kopiowane na stosie. Aby poprawić wydajność w tej sytuacji, możemy przechowywać dużą ilość danych na stercie w pudełku. Wtedy tylko mała ilość danych wskaźnika jest kopiowana na stosie, podczas gdy dane, do których wskazuje, pozostają w jednym miejscu na stercie. Trzeci przypadek jest znany jako obiekt cechy, a sekcja „Używanie obiektów cech do abstrakcji nad wspólnym zachowaniem” w Rozdziale 18 jest poświęcona temu tematowi. Więc to, czego się tutaj nauczysz, zastosujesz p ponownie w tej sekcji!
Przechowywanie danych na stercie
Zanim omówimy przypadek użycia Box<T> do przechowywania na stercie,
powiemy o składni i sposobie interakcji z wartościami przechowywanymi w Box<T>.
Listing 15-1 pokazuje, jak użyć pudełka do przechowywania wartości i32 na
stercie.
fn main() {
let b = Box::new(5);
println!("b = {b}");
}i32 na stercie za pomocą pudełkaDefiniujemy zmienną b z wartością Box, która wskazuje na wartość 5,
alokowaną na stercie. Ten program wyświetli b = 5; w tym przypadku możemy
dostęp do danych w pudełku podobnie jak wtedy, gdyby te dane znajdowały się na
stercie. Podobnie jak każda posiadana wartość, gdy pudełko wyjdzie poza
zakres, tak jak b na końcu main, zostanie zdealokowane. Dealokacja
odbywa się zarówno dla pudełka (przechowywanego na stosie), jak i dla danych,
do których wskazuje (przechowywanych na stercie).
Umieszczenie pojedynczej wartości na stercie nie jest zbyt użyteczne, więc
rzadko będziesz używać pudełek w ten sposób. Posiadanie wartości, takich jak
pojedyncze i32 na stosie, gdzie są domyślnie przechowywane, jest bardziej
odpowiednie w większości sytuacji. Spójrzmy na przypadek, w którym pudełka
pozwalają nam definiować typy, których nie moglibyśmy zdefiniować, gdybyśmy
nie mieli pudełek.
Włączanie typów rekurencyjnych za pomocą pudełek
Wartość typu rekurencyjnego może zawierać inną wartość tego samego typu jako swoją część. Typy rekurencyjne stanowią problem, ponieważ Rust musi wiedzieć w czasie kompilacji, ile miejsca zajmuje dany typ. Jednak zagnieżdżanie wartości typów rekurencyjnych mogłoby teoretycznie trwać w nieskończoność, więc Rust nie może wiedzieć, ile miejsca potrzebuje wartość. Ponieważ pudełka mają znany rozmiar, możemy włączyć typy rekurencyjne, wstawiając pudełko do definicji typu rekurencyjnego.
Jako przykład typu rekurencyjnego, przeanalizujmy listę cons. Jest to typ danych powszechnie spotykany w językach programowania funkcyjnego. Typ listy cons, który zdefiniujemy, jest prosty, z wyjątkiem rekurencji; dlatego koncepcje w przykładzie, z którym będziemy pracować, będą przydatne zawsze, gdy znajdziesz się w bardziej złożonych sytuacjach związanych z typami rekurencyjnymi.
Zrozumienie listy cons
Lista cons to struktura danych pochodząca z języka programowania Lisp i jego
dialektów, składająca się z zagnieżdżonych par, i jest lispońską wersją listy
składającej się z połączonych elementów. Jej nazwa pochodzi od funkcji cons
(skrót od construct function) w Lispie, która konstruuje nową parę z dwóch
swoich argumentów. Wywołując cons na parze składającej się z wartości i innej
pary, możemy konstruować listy cons składające się z rekurencyjnych par.
Na przykład, oto pseudokodowa reprezentacja listy cons zawierającej listę 1, 2, 3,
gdzie każda para jest w nawiasach:
(1, (2, (3, Nil)))
Każdy element listy cons zawiera dwa elementy: wartość bieżącego elementu i
następnego elementu. Ostatni element listy zawiera tylko wartość zwaną Nil
bez następnego elementu. Lista cons jest tworzona przez rekurencyjne
wywoływanie funkcji cons. Kanoniczna nazwa oznaczająca przypadek bazowy
rekurencji to Nil. Zauważ, że to nie to samo, co koncepcja „null” lub „nil”
omówiona w Rozdziale 6, która oznacza nieprawidłową lub brakującą wartość.
Lista cons nie jest powszechnie używaną strukturą danych w Rust. W większości
przypadków, gdy masz listę elementów w Rust, Vec<T> jest lepszym wyborem. Inne,
bardziej złożone rekurencyjne typy danych są użyteczne w różnych sytuacjach,
ale zaczynając od listy cons w tym rozdziale, możemy zbadać, jak pudełka
pPozwalają nam definiować rekurencyjny typ danych bez zbytniego rozpraszania.
Listing 15-2 zawiera definicję wyliczenia dla listy cons. Zauważ, że ten kod
jeszcze się nie skompiluje, ponieważ typ List nie ma znanego rozmiaru, co
pokażemy.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}i32Uwaga: Implementujemy listę cons, która przechowuje tylko wartości i32 dla
celów tego przykładu. Moglibyśmy zaimplementować ją za pomocą generyków, jak
omówiliśmy w Rozdziale 10, aby zdefiniować typ listy cons, który mógłby
przechowywać wartości dowolnego typu.
Użycie typu List do przechowywania listy 1, 2, 3 wyglądałoby jak kod
w Listingu 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}List do przechowywania listy 1, 2, 3Pierwsza wartość Cons przechowuje 1 i inną wartość List. Ta wartość
List to inna wartość Cons, która przechowuje 2 i inną wartość List.
Ta wartość List to jeszcze jedna wartość Cons, która przechowuje 3
i wartość List, która jest w końcu Nil, nierrekurencyjnym wariantem,
który sygnalizuje koniec listy.
Jeśli spróbujemy skompilować kod z Listingu 15-3, otrzymamy błąd pokazany w Listingu 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
Błąd pokazuje, że ten typ „ma nieskończony rozmiar”. Powodem jest to, że
zdefiniowaliśmy List z wariantem, który jest rekurencyjny: przechowuje inną
wartość siebie bezpośrednio. W rezultacie Rust nie potrafi określić, ile miejsca
potrzebuje do przechowywania wartości List. Rozłóżmy na czynniki pierwsze,
dlaczego otrzymujemy ten błąd. Najpierw przyjrzymy się, jak Rust decyduje, ile
miejsca potrzebuje do przechowywania wartości typu nierrekurencyjnego.
Obliczanie rozmiaru typu nierrekurencyjnego
Przypomnijmy wyliczenie Message, które zdefiniowaliśmy w Listingu 6-2,
kiedy omawialiśmy definicje wyliczeń w Rozdziale 6:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Aby określić, ile miejsca należy przeznaczyć na wartość Message, Rust
przechodzi przez każdy z wariantów, aby sprawdzić, który wariant potrzebuje
najwięcej miejsca. Rust widzi, że Message::Quit nie potrzebuje miejsca,
Message::Move potrzebuje wystarczająco dużo miejsca na przechowanie dwóch
wartości i32 i tak dalej. Ponieważ używany będzie tylko jeden wariant,
najwięcej miejsca, jakie będzie potrzebować wartość Message, to miejsce
potrzebne na przechowanie największego z jej wariantów.
Porównaj to z tym, co dzieje się, gdy Rust próbuje określić, ile miejsca
potrzebuje rekurencyjny typ, taki jak wyliczenie List w Listingu 15-2.
Kompilator zaczyna od wariantu Cons, który przechowuje wartość typu i32
i wartość typu List. Dlatego Cons potrzebuje tyle miejsca, ile wynosi
rozmiar i32 plus rozmiar List. Aby dowiedzieć się, ile pamięci potrzebuje
typ List, kompilator patrzy na warianty, zaczynając od wariantu Cons.
Wariant Cons przechowuje wartość typu i32 i wartość typu List, i ten
proces trwa w nieskończoność, jak pokazano na Rysunku 15-1.

Rysunek 15-1: Nieskończona lista List składająca się z nieskończonych wariantów Cons
Uzyskiwanie rekurencyjnego typu o znanym rozmiarze
Ponieważ Rust nie jest w stanie określić, ile miejsca należy przydzielić dla rekurencyjnie zdefiniowanych typów, kompilator zwraca błąd z tą pomocną sugestią:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
W tej sugestii pośrednictwo oznacza, że zamiast bezpośrednio przechowywać wartość, powinniśmy zmienić strukturę danych, aby przechowywać wartość pośrednio, przechowując zamiast tego wskaźnik do wartości.
Ponieważ Box<T> jest wskaźnikiem, Rust zawsze wie, ile miejsca potrzebuje
Box<T>: rozmiar wskaźnika nie zmienia się w zależności od ilości danych, na
które wskazuje. Oznacza to, że możemy umieścić Box<T> w wariancie Cons
zamiast bezpośrednio innej wartości List. Box<T> będzie wskazywać na
kolejną wartość List, która będzie znajdować się na stercie, a nie wewnątrz
wariantu Cons. Koncepcyjnie, nadal mamy listę, utworzoną z list
przechowujących inne listy, ale ta implementacja jest teraz bardziej podobna
do umieszczania elementów obok siebie, a nie wewnątrz siebie.
Możemy zmienić definicję wyliczenia List w Listingu 15-2 i użycie List w
Listingu 15-3 na kod w Listingu 15-5, który się skompiluje.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}List, która używa Box<T>, aby mieć znany rozmiarWariant Cons potrzebuje rozmiaru i32 plus miejsca na przechowywanie danych
wskaznika pudełka. Wariant Nil nie przechowuje żadnych wartości, więc
potrzebuje mniej miejsca na stosie niż wariant Cons. Wiemy teraz, że każda
wartość List zajmie rozmiar i32 plus rozmiar danych wskaźnika pudełka.
Używając pudełka, przerwaliśmy nieskończony, rekurencyjny łańcuch, więc
kompilator może określić rozmiar potrzebny do przechowywania wartości List.
Rysunek 15-2 pokazuje, jak wygląda teraz wariant Cons.

Rysunek 15-2: List, która nie ma nieskończonego rozmiaru, ponieważ Cons zawiera Box
Pudełka zapewniają jedynie pośrednictwo i alokację na stercie; nie mają żadnych innych specjalnych możliwości, takich jak te, które zobaczymy w przypadku innych typów inteligentnych wskaźników. Nie mają również narzutu wydajnościowego, który wiąże się z tymi specjalnymi możliwościami, więc mogą być przydatne w przypadkach, takich jak lista cons, gdzie pośrednictwo jest jedyną potrzebną nam funkcją. Więcej przypadków użycia pudełek omówimy w Rozdziale 18.
Typ Box<T> jest inteligentnym wskaźnikiem, ponieważ implementuje cechę
Deref, która pozwala traktować wartości Box<T> jak referencje. Kiedy
wartość Box<T> wychodzi poza zakres, dane na stercie, na które wskazuje
pudełko, również są czyszczone ze względu na implementację cechy Drop. Te
dwie cechy będą jeszcze ważniejsze dla funkcjonalności zapewnianej przez inne
typy inteligentnych wskaźników, które omówimy w pozostałej części tego
rozdziału. Przeanalizujmy te dwie cechy bardziej szczegółowo.
Traktowanie inteligentnych wskaźników jak zwykłych referencji
Traktowanie inteligentnych wskaźników jak zwykłych referencji
Implementacja cechy Deref pozwala dostosować zachowanie operatora dereferencji * (nie mylić z operatorem mnożenia ani glob). Implementując Deref w taki sposób, że inteligentny wskaźnik może być traktowany jak zwykła referencja, możesz pisać kod, który działa na referencjach i używać tego kodu również z inteligentnymi wskaźnikami.
Najpierw przyjrzyjmy się, jak operator dereferencji działa ze zwykłymi referencjami. Następnie spróbujemy zdefiniować niestandardowy typ, który zachowuje się jak Box<T> i zobaczymy, dlaczego operator dereferencji nie działa jak referencja na naszym nowo zdefiniowanym typie. Zbadamy, jak implementacja cechy Deref umożliwia inteligentnym wskaźnikom działanie w sposób podobny do referencji. Następnie przyjrzymy się funkcji Rust deref coercion i temu, jak pozwala nam ona pracować zarówno z referencjami, jak i inteligentnymi wskaźnikami.
Podążanie za referencją do wartości za pomocą operatora dereferencji
Zwykła referencja jest typem wskaźnika, a jeden ze sposobów myślenia o wskaźniku to strzałka do wartości przechowywanej gdzie indziej. W Listing 15-6 tworzymy referencję do wartości i32, a następnie używamy operatora dereferencji, aby podążyć za referencją do wartości.
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}Zmienna x przechowuje wartość i32 równą 5. Ustawiamy y na referencję do x. Możemy potwierdzić, że x jest równe 5. Jednak jeśli chcemy sprawdzić wartość w y, musimy użyć *y, aby podążyć za referencją do wartości, na którą wskazuje (stąd dereferencja), tak aby kompilator mógł porównać rzeczywistą wartość. Po dereferencji y mamy dostęp do wartości całkowitej, na którą wskazuje y, którą możemy porównać z 5.
Gdybyśmy spróbowali napisać assert_eq!(5, y); zamiast tego, otrzymalibyśmy następujący błąd kompilacji:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: nie można porównać `{integer}` z `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ brak implementacji dla `{integer} == &{integer}`
|
= help: cecha `PartialEq<&{integer}>` nie jest zaimplementowana dla `{integer}`
= note: ten błąd pochodzi z makra `assert_eq` (w kompilacjach Nightly, uruchom z -Z macro-backtrace, aby uzyskać więcej informacji)
For more information about this error, try `rustc --explain E0277`.
error: nie udało się skompilować `deref-example` (bin "deref-example") z powodu 1 poprzedniego błędu
Porównywanie liczby i referencji do liczby jest niedozwolone, ponieważ są to różne typy. Musimy użyć operatora dereferencji, aby podążyć za referencją do wartości, na którą wskazuje.
Używanie Box<T> jak referencji
Możemy przepisać kod z Listing 15-6, aby używał Box<T> zamiast referencji; operator dereferencji użyty na Box<T> w Listing 15-7 działa tak samo, jak operator dereferencji użyty na referencji w Listing 15-6.
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Główna różnica między Listing 15-7 a Listing 15-6 polega na tym, że tutaj ustawiamy y jako instancję pudełka wskazującego na skopiowaną wartość x, a nie referencję wskazującą na wartość x. W ostatniej asercji możemy użyć operatora dereferencji, aby podążyć za wskaźnikiem pudełka w ten sam sposób, w jaki robiliśmy to, gdy y była referencją. Następnie zbadamy, co jest specjalnego w Box<T>, co pozwala nam używać operatora dereferencji, definiując nasz własny typ pudełka.
Definiowanie naszego własnego inteligentnego wskaźnika
Zbudujmy typ opakowujący podobny do typu Box<T> dostarczanego przez standardową bibliotekę, aby doświadczyć, jak typy inteligentnych wskaźników domyślnie zachowują się inaczej niż referencje. Następnie przyjrzymy się, jak dodać możliwość użycia operatora dereferencji.
Uwaga: Istnieje jedna duża różnica między typem
MyBox<T>, który zaraz zbudujemy, a prawdziwymBox<T>: nasza wersja nie będzie przechowywać swoich danych na stercie. W tym przykładzie skupiamy się naDeref, więc to, gdzie dane są faktycznie przechowywane, jest mniej ważne niż zachowanie podobne do wskaźnika.
Typ Box<T> jest ostatecznie zdefiniowany jako struktura tuplowa z jednym elementem, więc Listing 15-8 definiuje typ MyBox<T> w ten sam sposób. Zdefiniujemy również funkcję new pasującą do funkcji new zdefiniowanej w Box<T>.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {}Definiujemy strukturę o nazwie MyBox i deklarujemy parametr generyczny T, ponieważ chcemy, aby nasz typ przechowywał wartości dowolnego typu. Typ MyBox jest strukturą tuplową z jednym elementem typu T. Funkcja MyBox::new przyjmuje jeden parametr typu T i zwraca instancję MyBox, która przechowuje przekazaną wartość.
Spróbujmy dodać funkcję main z Listing 15-7 do Listing 15-8 i zmienić ją tak, aby używała zdefiniowanego przez nas typu MyBox<T> zamiast Box<T>. Kod w Listing 15-9 nie skompiluje się, ponieważ Rust nie wie, jak dereferencyjnie traktować MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Oto wynikowy błąd kompilacji:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ nie można dereferencyjnie traktować
For more information about this error, try `rustc --explain E0614`.
error: nie udało się skompilować `deref-example` (bin "deref-example") z powodu 1 poprzedniego błędu
Nasz typ MyBox<T> nie może zostać dereferencjonowany, ponieważ nie zaimplementowaliśmy tej możliwości dla naszego typu. Aby umożliwić dereferencjonowanie za pomocą operatora *, implementujemy cechę Deref.
Implementacja cechy Deref
Jak omówiono w sekcji „Implementacja cechy dla typu” w Rozdziale 10, aby zaimplementować cechę, musimy dostarczyć implementacje dla wymaganych metod cechy. Cecha Deref, dostarczana przez standardową bibliotekę, wymaga od nas zaimplementowania jednej metody o nazwie deref, która pożycza self i zwraca referencję do wewnętrznych danych. Listing 15-10 zawiera implementację Deref do dodania do definicji MyBox<T>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Składnia type Target = T; definiuje typ skojarzony dla cechy Deref. Typy skojarzone to nieco inny sposób deklarowania parametru generycznego, ale na razie nie musisz się nimi martwić; omówimy je bardziej szczegółowo w Rozdziale 20.
Wypełniamy ciało metody deref za pomocą &self.0, tak aby deref zwracało referencję do wartości, do której chcemy uzyskać dostęp za pomocą operatora *; przypomnij sobie z sekcji „Tworzenie różnych typów za pomocą struktur tuplowych” w Rozdziale 5, że .0 uzyskuje dostęp do pierwszej wartości w strukturze tuplowej. Funkcja main w Listing 15-9, która wywołuje * na wartości MyBox<T>, teraz się kompiluje, a asercje przechodzą!
Bez cechy Deref kompilator może dereferencyjnie traktować tylko referencje &. Metoda deref daje kompilatorowi możliwość wzięcia wartości dowolnego typu, który implementuje Deref, i wywołania metody deref, aby uzyskać referencję, którą wie, jak dereferencyjnie traktować.
Kiedy wpisaliśmy *y w Listing 15-9, za kulisami Rust faktycznie uruchomił ten kod:
*(y.deref())Rust zastępuje operator * wywołaniem metody deref, a następnie prostym dereferencjonowaniem, tak abyśmy nie musieli zastanawiać się, czy potrzebujemy wywoływać metodę deref, czy nie. Ta funkcja Rusta pozwala nam pisać kod, który działa identycznie, niezależnie od tego, czy mamy zwykłą referencję, czy typ implementujący Deref.
Powód, dla którego metoda deref zwraca referencję do wartości, a zwykła dereferencja poza nawiasami w *(y.deref()) jest nadal konieczna, ma związek z systemem własności. Gdyby metoda deref zwracała wartość bezpośrednio zamiast referencji do wartości, wartość zostałaby przeniesiona z self. Nie chcemy przejmować własności wewnętrznej wartości w MyBox<T> w tym przypadku ani w większości przypadków, gdy używamy operatora dereferencji.
Zauważ, że operator * jest zastępowany wywołaniem metody deref, a następnie wywołaniem operatora * tylko raz, za każdym razem, gdy używamy * w naszym kodzie. Ponieważ podstawianie operatora * nie rekursuje w nieskończoność, otrzymujemy dane typu i32, co pasuje do 5 w assert_eq! w Listing 15-9.
Używanie koercji Deref w funkcjach i metodach
Koercja Deref konwertuje referencję do typu, który implementuje cechę Deref, na referencję do innego typu. Na przykład, koercja Deref może przekonwertować &String na &str, ponieważ String implementuje cechę Deref w taki sposób, że zwraca &str. Koercja Deref jest udogodnieniem, które Rust wykonuje na argumentach funkcji i metod, i działa tylko na typach, które implementują cechę Deref. Dzieje się to automatycznie, gdy przekazujemy referencję do wartości konkretnego typu jako argument do funkcji lub metody, która nie pasuje do typu parametru w definicji funkcji lub metody. Sekwencja wywołań metody deref konwertuje dostarczony przez nas typ na typ, którego potrzebuje parametr.
Koercja Deref została dodana do Rusta, aby programiści piszący wywołania funkcji i metod nie musieli dodawać tak wielu jawnych referencji i dereferencji za pomocą & i *. Funkcja koercji Deref pozwala nam również pisać więcej kodu, który może działać zarówno z referencjami, jak i inteligentnymi wskaźnikami.
Aby zobaczyć koercję Deref w działaniu, użyjmy typu MyBox<T>, który zdefiniowaliśmy w Listing 15-8, a także implementacji Deref, którą dodaliśmy w Listing 15-10. Listing 15-11 pokazuje definicję funkcji, która ma parametr wycinka ciągu znaków.
fn hello(name: &str) {
println!("Witaj, {name}!");
}
fn main() {}Możemy wywołać funkcję hello z wycinkiem ciągu znaków jako argumentem, na przykład hello("Rust");. Koercja Deref umożliwia wywołanie hello z referencją do wartości typu MyBox<String>, jak pokazano w Listing 15-12.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Witaj, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}Tutaj wywołujemy funkcję hello z argumentem &m, który jest referencją do wartości MyBox<String>. Ponieważ zaimplementowaliśmy cechę Deref dla MyBox<T> w Listing 15-10, Rust może przekształcić &MyBox<String> w &String poprzez wywołanie deref. Standardowa biblioteka dostarcza implementację Deref dla String, która zwraca wycinek ciągu znaków, i jest to w dokumentacji API dla Deref. Rust ponownie wywołuje deref, aby przekształcić &String w &str, co pasuje do definicji funkcji hello.
Gdyby Rust nie implementował koercji dereferencyjnej, musielibyśmy napisać kod z Listing 15-13 zamiast kodu z Listing 15-12, aby wywołać hello z wartością typu &MyBox<String>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Witaj, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}(*m) dereferencuje MyBox<String> do String. Następnie & i [..] pobierają wycinek ciągu znaków z String, który jest równy całemu ciągowi, aby pasował do sygnatury hello. Ten kod bez koercji dereferencyjnych jest trudniejszy do odczytania, napisania i zrozumienia ze wszystkimi zaangażowanymi symbolami. Koercja Deref pozwala Rustowi automatycznie obsługiwać te konwersje.
Kiedy cecha Deref jest zdefiniowana dla zaangażowanych typów, Rust przeanalizuje typy i użyje Deref::deref tyle razy, ile to konieczne, aby uzyskać referencję pasującą do typu parametru. Liczba razy, jaką należy wstawić Deref::deref, jest rozwiązywana w czasie kompilacji, więc nie ma kary za wydajność w czasie działania za korzystanie z koercji Deref!
Obsługa koercji Deref ze zmiennymi referencjami
Podobnie jak używasz cechy Deref do nadpisywania operatora * na niezmiennych referencjach, możesz użyć cechy DerefMut do nadpisywania operatora * na zmiennych referencjach.
Rust wykonuje koercję dereferencyjną, gdy znajdzie typy i implementacje cech w trzech przypadkach:
- Z
&Tdo&U, gdyT: Deref<Target=U> - Z
&mut Tdo&mut U, gdyT: DerefMut<Target=U> - Z
&mut Tdo&U, gdyT: Deref<Target=U>
Pierwsze dwa przypadki są takie same, z wyjątkiem tego, że drugi implementuje zmienność. Pierwszy przypadek mówi, że jeśli masz &T i T implementuje Deref do pewnego typu U, możesz w sposób przezroczysty uzyskać &U. Drugi przypadek mówi, że ta sama koercja dereferencyjna ma miejsce dla zmiennych referencji.
Trzeci przypadek jest bardziej podstępny: Rust również przekształci zmienną referencję w niezmienną. Ale odwrotna operacja nie jest możliwa: niezmienne referencje nigdy nie zostaną przekształcone w zmienne referencje. Ze względu na zasady pożyczania, jeśli masz zmienną referencję, ta zmienna referencja musi być jedyną referencją do tych danych (w przeciwnym razie program nie skompilowałby się). Konwersja jednej zmiennej referencji na jedną niezmienną referencję nigdy nie naruszy zasad pożyczania. Konwersja niezmiennej referencji na zmienną referencję wymagałaby, aby początkowa niezmienna referencja była jedyną niezmienną referencją do tych danych, ale zasady pożyczania tego nie gwarantują. Dlatego Rust nie może przyjąć założenia, że konwersja niezmiennej referencji na zmienną referencję jest możliwa.
Uruchamianie kodu podczas czyszczenia za pomocą cechy `Drop`
Uruchamianie kodu podczas czyszczenia za pomocą cechy Drop
Druga cecha ważna dla wzorca wskaźnika sprytnego to Drop, która pozwala na
dostosowanie tego, co dzieje się, gdy wartość ma wyjść poza zakres. Możesz
dostarczyć implementację cechy Drop dla dowolnego typu, a ten kod może
zostać użyty do zwolnienia zasobów, takich jak pliki lub połączenia sieciowe.
Wprowadzamy Drop w kontekście wskaźników sprytnych, ponieważ funkcjonalność
cechy Drop jest prawie zawsze używana podczas implementacji wskaźnika
sprytnego. Na przykład, gdy Box<T> zostanie usunięty (dropped), zwolni
przestrzeń na stercie, na którą wskazuje Box.
W niektórych językach, dla niektórych typów, programista musi wywołać kod, aby zwolnić pamięć lub zasoby za każdym razem, gdy skończy używać instancji tych typów. Przykładami są uchwyty plików, gniazda sieciowe i blokady. Jeśli programista zapomni, system może zostać przeciążony i ulec awarii. W Rust można określić, że dany fragment kodu ma być uruchamiany za każdym razem, gdy wartość wyjdzie poza zakres, a kompilator wstawi ten kod automatycznie. W rezultacie nie musisz martwić się o umieszczanie kodu czyszczącego wszędzie w programie, gdzie instancja określonego typu zostaje zakończona – nadal nie będziesz miał wycieków zasobów!
Kod do uruchomienia, gdy wartość wyjdzie poza zakres, określasz, implementując
cechę Drop. Cecha Drop wymaga zaimplementowania jednej metody o nazwie
drop, która przyjmuje mutowalną referencję do self. Aby zobaczyć, kiedy Rust
wywołuje drop, zaimplementujmy na razie drop z instrukcjami println!.
Listing 15-14 przedstawia strukturę CustomSmartPointer, której jedyną
dostosowaną funkcjonalnością jest to, że wypisze Dropping CustomSmartPointer!,
gdy instancja wyjdzie poza zakres, aby pokazać, kiedy Rust uruchamia metodę
drop.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created");
}Cecha Drop jest uwzględniona w preambule, więc nie musimy jej importować.
Implementujemy cechę Drop dla CustomSmartPointer i dostarczamy implementację
metody drop, która wywołuje println!. Treść metody drop to miejsce, w
którym umieściłbyś dowolną logikę, którą chciałbyś uruchomić, gdy instancja
twojego typu wyjdzie poza zakres. Wypisujemy tutaj tekst, aby wizualnie
zademonstrować, kiedy Rust wywoła drop.
W main tworzymy dwie instancje CustomSmartPointer, a następnie wypisujemy
CustomSmartPointers created. Pod koniec main, nasze instancje
CustomSmartPointer wyjdą poza zakres, a Rust wywoła kod, który umieściliśmy
w metodzie drop, wypisując naszą końcową wiadomość. Zauważ, że nie musieliśmy
jawnie wywoływać metody drop.
Po uruchomieniu tego programu zobaczymy następujący wynik:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust automatycznie wywołał drop dla nas, gdy nasze instancje wyszły poza
zakres, uruchamiając określony przez nas kod. Zmienne są usuwane w odwrotnej
kolejności ich tworzenia, więc d zostało usunięte przed c. Celem tego
przykładu jest zapewnienie wizualnego przewodnika po działaniu metody drop;
zazwyczaj określiłbyś kod czyszczący, który twój typ musi uruchomić, a nie
komunikat do wypisania.
Niestety, wyłączenie automatycznej funkcjonalności drop nie jest proste.
Wyłączanie drop zazwyczaj nie jest konieczne; cały sens cechy Drop polega
na tym, że jest obsługiwana automatycznie. Czasami jednak możesz chcieć
posprzątać wartość wcześniej. Jednym z przykładów jest użycie wskaźników
sprytnych zarządzających blokadami: Możesz chcieć wymusić wywołanie metody
drop, która zwalnia blokadę, tak aby inny kod w tym samym zakresie mógł
nabyć blokadę. Rust nie pozwala na ręczne wywołanie metody drop cechy Drop;
zamiast tego musisz wywołać funkcję std::mem::drop dostarczoną przez
bibliotekę standardową, jeśli chcesz wymusić usunięcie wartości przed końcem
jej zakresu.
Próba ręcznego wywołania metody drop cechy Drop poprzez modyfikację funkcji
main z Listingu 15-14 nie zadziała, jak pokazano w Listingu 15-15.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}Kiedy spróbujemy skompilować ten kod, otrzymamy taki błąd:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Ten komunikat o błędzie informuje, że nie wolno nam jawnie wywoływać drop.
Komunikat o błędzie używa terminu destruktor, który jest ogólnym terminem
programistycznym dla funkcji, która oczyszcza instancję. Destruktor jest
analogiczny do konstruktora, który tworzy instancję. Funkcja drop w Rust
jest jednym szczególnym destruktorem.
Rust nie pozwala nam jawnie wywoływać drop, ponieważ Rust nadal
automatycznie wywoływałby drop na wartości na końcu main. Spowodowałoby to
błąd podwójnego zwolnienia pamięci, ponieważ Rust próbowałby dwukrotnie
posprzątać tę samą wartość.
Nie możemy wyłączyć automatycznego wstawiania drop, gdy wartość wyjdzie poza
zakres, i nie możemy jawnie wywołać metody drop. Więc, jeśli potrzebujemy
wymusić wczesne posprzątanie wartości, używamy funkcji std::mem::drop.
Funkcja std::mem::drop różni się od metody drop w cechy Drop. Wywołujemy
ją, przekazując jako argument wartość, którą chcemy wymusić usunięcie.
Funkcja znajduje się w preambule, więc możemy zmodyfikować main w Listingu
15-15, aby wywołać funkcję drop, jak pokazano w Listingu 15-16.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
drop(c);
println!("CustomSmartPointer dropped before the end of main");
}Uruchomienie tego kodu wypisze następujące:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
Tekst Dropping CustomSmartPointer with data `some data`! jest wypisany
pomiędzy tekstami CustomSmartPointer created i CustomSmartPointer dropped before the end of main, pokazując, że kod metody drop jest wywoływany w celu
usunięcia c w tym punkcie.
Kod określony w implementacji cechy Drop można wykorzystać na wiele sposobów,
aby czyszczenie było wygodne i bezpieczne: na przykład można go użyć do
stworzenia własnego alokatora pamięci! Dzięki cechy Drop i systemowi własności
Rust nie musisz pamiętać o czyszczeniu, ponieważ Rust robi to automatycznie.
Nie musisz też martwić się problemami wynikającymi z przypadkowego czyszczenia
wartości nadal używanych: System własności, który zapewnia, że referencje są
zawsze prawidłowe, gwarantuje również, że drop zostanie wywołany tylko raz,
gdy wartość nie jest już używana.
Teraz, gdy przeanalizowaliśmy Box<T> i niektóre cechy wskaźników sprytnych,
przyjrzyjmy się kilku innym wskaźnikom sprytnym zdefiniowanym w bibliotece
standardowej.
`Rc<T>`, wskaźnik sprytny zliczający referencje
Rc<T>, wskaźnik sprytny zliczający referencje
W większości przypadków własność jest jasna: dokładnie wiesz, która zmienna posiada daną wartość. Istnieją jednak sytuacje, gdy pojedyncza wartość może mieć wielu właścicieli. Na przykład, w strukturach danych grafowych, wiele krawędzi może wskazywać na ten sam węzeł, a ten węzeł jest koncepcyjnie własnością wszystkich krawędzi, które na niego wskazują. Węzeł nie powinien być usuwany, chyba że nie ma żadnych krawędzi wskazujących na niego, a zatem nie ma właścicieli.
Musisz jawnie włączyć wielokrotną własność, używając typu Rust Rc<T>, co
jest skrótem od reference counting (zliczanie referencji). Typ Rc<T>
śledzi liczbę referencji do wartości, aby określić, czy wartość jest nadal
używana. Jeśli do wartości istnieje zero referencji, wartość może zostać
usunięta bez unieważniania żadnych referencji.
Wyobraź sobie Rc<T> jako telewizor w pokoju rodzinnym. Kiedy jedna osoba
wchodzi, żeby oglądać telewizor, włącza go. Inni mogą wejść do pokoju i oglądać
telewizor. Kiedy ostatnia osoba opuszcza pokój, wyłącza telewizor, ponieważ
nie jest już używany. Gdyby ktoś wyłączył telewizor, podczas gdy inni nadal
go oglądają, pozostali widzowie wywołaliby zamieszanie!
Typu Rc<T> używamy, gdy chcemy alokować dane na stercie, aby wiele części
naszego programu mogło je odczytywać, a nie możemy w czasie kompilacji
określić, która część zakończy używanie danych jako ostatnia. Gdybyśmy
wiedzieli, która część zakończy używanie jako ostatnia, moglibyśmy po prostu
uczynić tę część właścicielem danych, a normalne zasady własności egzekwowane
w czasie kompilacji weszłyby w życie.
Zauważ, że Rc<T> jest przeznaczony wyłącznie do użytku w scenariuszach
jednowątkowych. Kiedy będziemy omawiać współbieżność w Rozdziale 16,
pokażemy, jak realizować zliczanie referencji w programach
wielowątkowych.
Udostępnianie danych
Wróćmy do naszego przykładu listy konsensusowej z Listingu 15-5. Przypomnijmy,
że zdefiniowaliśmy ją za pomocą Box<T>. Tym razem stworzymy dwie listy, które
obie współdzielą własność trzeciej listy. Koncepcyjnie wygląda to podobnie do
Rysunku 15-3.

Rysunek 15-3: Dwie listy, b i c, współdzielące własność
trzeciej listy, a
Stworzymy listę a, która będzie zawierać 5, a następnie 10. Następnie,
stworzymy dwie kolejne listy: b, która zaczyna się od 3, i c, która
zaczyna się od 4. Obie listy b i c będą kontynuowane do pierwszej listy a
zawierającej 5 i 10. Innymi słowy, obie listy będą współdzielić pierwszą
listę zawierającą 5 i 10.
Próba zaimplementowania tego scenariusza przy użyciu naszej definicji List z
Box<T> nie zadziała, jak pokazano w Listingu 15-17.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Kiedy skompilujemy ten kod, otrzymamy taki błąd:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Warianty Cons posiadają przechowywane dane, więc kiedy tworzymy listę b, a
zostaje przeniesione do b, a b staje się właścicielem a. Następnie, gdy
próbujemy ponownie użyć a podczas tworzenia c, nie jest to dozwolone,
ponieważ a zostało przeniesione.
Moglibyśmy zmienić definicję Cons, aby przechowywała referencje, ale wtedy
musielibyśmy określić parametry czasu życia. Określając parametry czasu życia,
określilibyśmy, że każdy element na liście będzie istniał co najmniej tak długo
jak cała lista. Tak jest w przypadku elementów i list w Listingu 15-17, ale
nie w każdym scenariuszu.
Zamiast tego zmienimy naszą definicję List, aby używać Rc<T> zamiast
Box<T>, jak pokazano w Listingu 15-18. Każdy wariant Cons będzie teraz
przechowywał wartość i Rc<T> wskazujący na List. Kiedy tworzymy b,
zamiast przejmować własność a, sklonujemy Rc<List>, które a przechowuje,
powiąkszając tym samym liczbę referencji z jednej do dwóch i pozwalając a i b
współdzielić własność danych w tym Rc<List>. Sklonujemy również a podczas
tworzenia c, zwiększając liczbę referencji z dwóch do trzech. Za każdym
razem, gdy wywołamy Rc::clone, liczba referencji do danych w Rc<List>
wzrośnie, a dane nie zostaną usunięte, chyba że będzie do nich zero referencji.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}Musimy dodać instrukcję use, aby wprowadzić Rc<T> do zakresu, ponieważ nie
znajduje się on w preambule. W funkcji main tworzymy listę zawierającą 5 i
10 i przechowujemy ją w nowym Rc<List> w zmiennej a. Następnie, gdy
tworzymy b i c, wywołujemy funkcję Rc::clone i przekazujemy referencję
do Rc<List> w a jako argument.
Moglibyśmy wywołać a.clone() zamiast Rc::clone(&a), ale konwencją Rust jest
używanie Rc::clone w tym przypadku. Implementacja Rc::clone nie tworzy
głębokiej kopii wszystkich danych, jak robią to implementacje clone większości
typów. Wywołanie Rc::clone tylko zwiększa licznik referencji, co nie
zabiera wiele czasu. Głębokie kopie danych mogą zajmować dużo czasu. Używając
Rc::clone do zliczania referencji, możemy wizualnie rozróżnić klony
tworzące głębokie kopie od klonów, które zwiększają licznik referencji. Szukając
problemów z wydajnością w kodzie, musimy brać pod uwagę tylko klony tworzące
głębokie kopie i możemy ignorować wywołania Rc::clone.
Klonowanie w celu zwiększenia licznika referencji
Zmieńmy nasz działający przykład z Listingu 15-18, abyśmy mogli zobaczyć,
jak zmieniają się liczniki referencji, gdy tworzymy i usuwamy referencje do
Rc<List> w a.
W Listingu 15-19 zmienimy main tak, aby zawierał wewnętrzny zakres wokół
listy c; wtedy będziemy mogli zobaczyć, jak zmienia się licznik referencji,
gdy c wyjdzie poza zakres.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
// --snip--
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}W każdym punkcie programu, w którym zmienia się licznik referencji, wypisujemy
wartość licznika referencji, którą uzyskujemy wywołując funkcję
Rc::strong_count. Funkcja ta nazywa się strong_count (silne zliczanie)
zamiast count (zliczanie), ponieważ typ Rc<T> ma również weak_count
(słabe zliczanie); do czego służy weak_count zobaczymy w sekcji „Zapobieganie
cyklom referencji za pomocą Weak<T>”.
Ten kod wypisuje następujące:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Widzimy, że Rc<List> w a ma początkowy licznik referencji równy 1; następnie,
za każdym razem, gdy wywołujemy clone, licznik zwiększa się o 1. Gdy c
wyjdzie poza zakres, licznik zmniejsza się o 1. Nie musimy wywoływać funkcji
w celu zmniejszenia licznika referencji, tak jak musimy wywołać Rc::clone
w celu zwiększenia licznika referencji: Implementacja cechy Drop automatycznie
zmniejsza licznik referencji, gdy wartość Rc<T> wyjdzie poza zakres.
Czego nie widzimy w tym przykładzie, to to, że gdy b, a następnie a wyjdą
poza zakres na końcu main, licznik wynosi 0, a Rc<List> zostaje całkowicie
wyczyszczone. Użycie Rc<T> pozwala jednej wartości mieć wielu właścicieli, a
licznik zapewnia, że wartość pozostaje ważna tak długo, jak długo istnieje
którykolwiek z właścicieli.
Poprzez niemutowalne referencje, Rc<T> pozwala na współdzielenie danych
pomiędzy wieloma częściami programu wyłącznie do odczytu. Gdyby Rc<T>
pozwalało na posiadanie również wielu mutowalnych referencji, mogłoby to
naruszyć jedną z zasad pożyczania omówionych w Rozdziale 4: Wiele mutowalnych
pożyczeń do tego samego miejsca może prowadzić do wyścigów danych i
niekonsekwencji. Ale możliwość modyfikacji danych jest bardzo przydatna! W
następnej sekcji omówimy wzorzec mutowalności wewnętrznej i typ RefCell<T>,
którego można używać w połączeniu z Rc<T> do pracy z tym ograniczeniem
iemutowalności.
`RefCell<T>` i wzorzec mutowalności wewnętrznej
RefCell<T> i wzorzec mutowalności wewnętrznej
Mutowalność wewnętrzna to wzorzec projektowy w Rust, który pozwala na
modyfikowanie danych nawet wtedy, gdy istnieją do nich niemutowalne referencje;
zazwyczaj takie działanie jest zabronione przez zasady pożyczania. Aby
modyfikować dane, wzorzec ten używa kodu unsafe wewnątrz struktury danych,
aby naginać zwykłe zasady Rust dotyczące mutowalności i pożyczania. Kod
niebezpieczny wskazuje kompilatorowi, że ręcznie sprawdzamy zasady, zamiast
polegać na tym, że kompilator sprawdzi je za nas; o kodzie niebezpiecznym
będziemy rozmawiać szerzej w Rozdziale 20.
Typy używające wzorca mutowalności wewnętrznej możemy stosować tylko wtedy,
gdy jesteśmy pewni, że zasady pożyczania będą przestrzegane w czasie
wykonania, mimo że kompilator nie może tego zagwarantować. Kod unsafe jest
wtedy opakowany w bezpieczne API, a typ zewnętrzny nadal pozostaje
iemutowalny.
Przyjrzyjmy się tej koncepcji, badając typ RefCell<T>, który stosuje wzorzec
mutowalności wewnętrznej.
Egzekwowanie zasad pożyczania w czasie wykonania
W przeciwieństwie do Rc<T>, typ RefCell<T> reprezentuje pojedynczą własność
danych, które przechowuje. Co zatem odróżnia RefCell<T> od typu takiego jak
Box<T>? Przypomnij sobie zasady pożyczania, których nauczyłeś się w Rozdziale 4:
- W dowolnym momencie możesz mieć albo jedną mutowalną referencję, albo dowolną liczbę niemutowalnych referencji (ale nie obie naraz).
- Referencje muszą być zawsze prawidłowe.
W przypadku referencji i Box<T>, niezmienniki zasad pożyczania są
egzekwowane w czasie kompilacji. W przypadku RefCell<T> te niezmienniki są
egzekwowane w czasie wykonania. W przypadku referencji, jeśli naruszysz te
zasady, otrzymasz błąd kompilacji. W przypadku RefCell<T>, jeśli naruszysz
te zasady, Twój program zostanie przerwany (panic) i zakończy działanie.
Zaletami sprawdzania zasad pożyczania w czasie kompilacji są to, że błędy zostaną wykryte wcześniej w procesie rozwoju, a także brak wpływu na wydajność w czasie wykonania, ponieważ cała analiza jest zakończona wcześniej. Z tych powodów sprawdzanie zasad pożyczania w czasie kompilacji jest najlepszym wyborem w większości przypadków, dlatego jest to domyślne zachowanie Rust.
Zaletą sprawdzania zasad pożyczania w czasie wykonania jest to, że pozwala to na pewne scenariusze bezpieczne pod względem pamięci, które zostałyby zabronione przez sprawdzenia w czasie kompilacji. Analiza statyczna, taka jak kompilator Rust, jest z natury konserwatywna. Niektóre właściwości kodu są niemożliwe do wykrycia poprzez analizę kodu: Najsłynniejszym przykładem jest Problem Zatrzymania, który wykracza poza zakres tej książki, ale jest ciekawym tematem do zbadania.
Ponieważ niektóre analizy są niemożliwe, jeśli kompilator Rust nie może być
pewien, że kod jest zgodny z zasadami własności, może odrzucić poprawny
program; w ten sposób jest konserwatywny. Gdyby Rust akceptował niepoprawny
program, użytkownicy nie mogliby ufać gwarancjom, jakie daje Rust. Jednak
jeśli Rust odrzuci poprawny program, programista będzie miał niedogodności,
ale nic katastrofalnego nie może się wydarzyć. Typ RefCell<T> jest użyteczny,
gdy jesteś pewien, że Twój kod jest zgodny z zasadami pożyczania, ale
kompilator nie jest w stanie tego zrozumieć i zagwarantować.
Podobnie jak Rc<T>, RefCell<T> jest przeznaczony wyłącznie do użytku w
scenariuszach jednowątkowych i spowoduje błąd kompilacji, jeśli spróbujesz go
użyć w kontekście wielowątkowym. O tym, jak uzyskać funkcjonalność RefCell<T>
w programie wielowątkowym, będziemy rozmawiać w Rozdziale 16.
Oto podsumowanie powodów, dla których warto wybrać Box<T>, Rc<T> lub
RefCell<T>:
Rc<T>umożliwia wielu właścicieli tych samych danych;Box<T>iRefCell<T>mają pojedynczych właścicieli.Box<T>pozwala na niemutowalne lub mutowalne pożyczenia sprawdzane w czasie kompilacji;Rc<T>pozwala tylko na niemutowalne pożyczenia sprawdzane w czasie kompilacji;RefCell<T>pozwala na niemutowalne lub mutowalne pożyczenia sprawdzane w czasie wykonania.- Ponieważ
RefCell<T>pozwala na mutowalne pożyczenia sprawdzane w czasie wykonania, możesz modyfikować wartość wewnątrzRefCell<T>, nawet gdyRefCell<T>jest niemutowalny.
Modyfikacja wartości wewnątrz niemutowalnej wartości to wzorzec mutowalności wewnętrznej. Przyjrzyjmy się sytuacji, w której mutowalność wewnętrzna jest przydatna i zbadajmy, jak jest to możliwe.
Użycie mutowalności wewnętrznej
Konsekwencją zasad pożyczania jest to, że gdy masz niemutowalną wartość, nie możesz jej mutowalnie pożyczyć. Na przykład, ten kod się nie skompiluje:
fn main() {
let x = 5;
let y = &mut x;
}Gdybyś spróbował skompilować ten kod, otrzymałbyś następujący błąd:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Istnieją jednak sytuacje, w których byłoby przydatne, aby wartość mogła
modyfikować się w swoich metodach, ale wydawała się niemutowalna dla innego
kodu. Kod poza metodami wartości nie mógłby modyfikować wartości. Użycie
RefCell<T> jest jednym ze sposobów na uzyskanie zdolności do mutowalności
wewnętrznej, ale RefCell<T> nie omija całkowicie zasad pożyczania: Sprawdzanie
pożyczania w kompilatorze pozwala na tę mutowalność wewnętrzną, a zasady
pożyczania są sprawdzane w czasie wykonania. Jeśli naruszysz zasady,
otrzymasz panic! zamiast błędu kompilacji.
Przejdźmy przez praktyczny przykład, w którym możemy użyć RefCell<T> do
modyfikacji niemutowalnej wartości i zobaczyć, dlaczego jest to przydatne.
Testowanie z obiektami mockowymi
Czasami podczas testowania programista używa jednego typu zamiast innego, aby obserwować określone zachowanie i upewnić się, że jest ono poprawnie zaimplementowane. Ten zastępczy typ nazywa się dublerem testowym. Pomyśl o nim w sensie dublera kaskaderskiego w filmie, gdzie osoba wchodzi i zastępuje aktora, aby wykonać szczególnie trudną scenę. Dublery testowe zastępują inne typy, gdy przeprowadzamy testy. Obiekty mockowe to specyficzne typy dublerów testowych, które rejestrują, co dzieje się podczas testu, aby można było stwierdzić, że podjęto prawidłowe działania.
Rust nie ma obiektów w tym samym sensie, co inne języki, i Rust nie ma funkcji obiektów mockowych wbudowanych w bibliotekę standardową, jak to robią niektóre inne języki. Możesz jednak z pewnością stworzyć strukturę, która będzie służyć tym samym celom, co obiekt mockowy.
Oto scenariusz, który przetestujemy: stworzymy bibliotekę, która śledzi wartość w stosunku do wartości maksymalnej i wysyła wiadomości w zależności od tego, jak blisko wartości maksymalnej jest obecna wartość. Ta biblioteka mogłaby być używana na przykład do śledzenia limitu użytkownika na liczbę wywołań API, które są dozwolone.
Nasza biblioteka będzie zapewniać jedynie funkcjonalność śledzenia, jak blisko
wartości maksymalnej jest wartość i jakie wiadomości powinny być wysyłane w
danych momentach. Aplikacje korzystające z naszej biblioteki będą musiały
dostarczyć mechanizm wysyłania wiadomości: Aplikacja może pokazać wiadomość
użytkownikowi bezpośrednio, wysłać e-mail, wysłać wiadomość tekstową lub zrobić
cokolwiek innego. Biblioteka nie musi znać tych szczegółów. Potrzebuje tylko
czegoś, co implementuje cechę, którą dostarczymy, nazwaną Messenger. Listing
15-20 pokazuje kod biblioteki.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Jedną ważną częścią tego kodu jest to, że cecha Messenger ma jedną metodę
o nazwie send, która przyjmuje niemutowalną referencję do self i tekst
wiadomości. Ta cecha jest interfejsem, który nasz obiekt mockowy musi
implementować, aby mock mógł być używany w ten sam sposób, co prawdziwy obiekt.
Druga ważna część to to, że chcemy przetestować zachowanie metody set_value
w LimitTracker. Możemy zmienić to, co przekazujemy jako parametr value,
ale set_value nie zwraca niczego, na czym moglibyśmy oprzeć asercje. Chcemy
być w stanie powiedzieć, że jeśli utworzymy LimitTracker z czymś, co
implementuje cechę Messenger i określoną wartością dla max, to messenger
otrzymuje polecenie wysłania odpowiednich wiadomości, gdy przekazujemy
różne liczby dla value.
Potrzebujemy obiektu mockowego, który zamiast wysyłać e-mail lub wiadomość
tekstową po wywołaniu send, będzie jedynie śledził wiadomości, które mu
kazano wysłać. Możemy utworzyć nową instancję obiektu mockowego, stworzyć
LimitTracker używający obiektu mockowego, wywołać metodę set_value w
LimitTracker, a następnie sprawdzić, czy obiekt mockowy zawiera wiadomości,
których oczekujemy. Listing 15-21 pokazuje próbę zaimplementowania obiektu
mockowego, który ma to robić, ale sprawdzający pożyczki na to nie zezwala.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}Ten kod testowy definiuje strukturę MockMessenger, która ma pole
sent_messages z wektorem wartości String, aby śledzić wiadomości, które ma
wysyłać. Definiujemy również skojarzoną funkcję new, aby ułatwić tworzenie
nowych wartości MockMessenger, które zaczynają się od pustej listy wiadomości.
Następnie implementujemy cechę Messenger dla MockMessenger, aby móc
przekazać MockMessenger do LimitTracker. W definicji metody send
pobieramy wiadomość przekazaną jako parametr i przechowujemy ją na liście
sent_messages MockMessenger.
W teście sprawdzamy, co dzieje się, gdy LimitTracker otrzymuje polecenie
ustawienia value na wartość większą niż 75 procent wartości max. Najpierw
tworzymy nowy MockMessenger, który rozpocznie się od pustej listy wiadomości.
Następnie tworzymy nowy LimitTracker i przekazujemy mu referencję do nowego
obiektu MockMessenger oraz wartość max równą 100. Wywołujemy metodę
set_value w LimitTracker z wartością 80, co stanowi ponad 75 procent z
100. Następnie twierdzimy, że lista wiadomości śledzonych przez
MockMessenger powinna teraz zawierać jedną wiadomość.
Jest jednak jeden problem z tym testem, jak pokazano tutaj:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Nie możemy modyfikować MockMessenger, aby śledził wiadomości, ponieważ
metoda send przyjmuje niemutowalną referencję do self. Nie możemy również
skorzystać z sugestii komunikatu o błędzie, aby użyć &mut self zarówno w
metodzie impl, jak i w definicji cechy. Nie chcemy zmieniać cechy Messenger
wyłącznie dla celów testowania. Zamiast tego musimy znaleźć sposób, aby nasz
kod testowy działał poprawnie z naszym istniejącym projektem.
To sytuacja, w której mutowalność wewnętrzna może pomóc! Będziemy
przechowywać sent_messages wewnątrz RefCell<T>, a następnie metoda send
będzie mogła modyfikować sent_messages w celu przechowywania widzianych przez
nas wiadomości. Listing 15-22 pokazuje, jak to wygląda.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Pole sent_messages jest teraz typu RefCell<Vec<String>> zamiast
Vec<String>. W funkcji new tworzymy nową instancję RefCell<Vec<String>>
wokół pustego wektora.
Dla implementacji metody send pierwszy parametr nadal jest niemutowalnym
pożyczeniem self, co odpowiada definicji cechy. Wywołujemy borrow_mut na
RefCell<Vec<String>> w self.sent_messages, aby uzyskać mutowalną referencję
do wartości wewnątrz RefCell<Vec<String>>, która jest wektorem. Następnie
możemy wywołać push na mutowalnej referencji do wektora, aby śledzić wiadomości
wysłane podczas testu.
Ostatnia zmiana, jaką musimy wprowadzić, dotyczy asercji: aby sprawdzić, ile
elementów jest w wewnętrznym wektorze, wywołujemy borrow na
RefCell<Vec<String>>, aby uzyskać niemutowalną referencję do wektora.
Teraz, gdy widziałeś, jak używać RefCell<T>, zagłębmy się w to, jak to działa!
Śledzenie pożyczeń w czasie wykonania
Podczas tworzenia niemutowalnych i mutowalnych referencji używamy odpowiednio
składni & i &mut. W przypadku RefCell<T> używamy metod borrow i
borrow_mut, które są częścią bezpiecznego API należącego do RefCell<T>. Metoda
borrow zwraca typ wskaźnika sprytnego Ref<T>, a borrow_mut zwraca typ
wskaźnika sprytnego RefMut<T>. Oba typy implementują Deref, więc możemy je
traktować jak zwykłe referencje.
RefCell<T> śledzi, ile wskaźników sprytnych Ref<T> i RefMut<T> jest
aktywnie używanych. Za każdym razem, gdy wywołujemy borrow, RefCell<T>
zwiększa licznik aktywnych niemutowalnych pożyczeń. Gdy wartość Ref<T> wyjdzie
poza zakres, licznik niemutowalnych pożyczeń zmniejsza się o 1. Podobnie jak
zasady pożyczania w czasie kompilacji, RefCell<T> pozwala nam na wiele
niemutowalnych pożyczeń lub jedno mutowalne pożyczenie w dowolnym momencie.
Jeśli spróbujemy naruszyć te zasady, zamiast otrzymania błędu kompilacji, jak
miałoby to miejsce w przypadku referencji, implementacja RefCell<T> spowoduje
panikę w czasie wykonania. Listing 15-23 pokazuje modyfikację implementacji
send z Listingu 15-22. Celowo próbujemy stworzyć dwa mutowalne pożyczenia
aktywne w tym samym zakresie, aby zilustrować, że RefCell<T> zapobiega temu
w czasie wykonania.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Tworzymy zmienną one_borrow dla wskaźnika sprytnego RefMut<T> zwróconego
przez borrow_mut. Następnie tworzymy kolejne mutowalne pożyczenie w ten sam
sposób w zmiennej two_borrow. Tworzy to dwie mutowalne referencje w tym samym
zakresie, co jest niedozwolone. Kiedy uruchomimy testy dla naszej biblioteki,
kod z Listingu 15-23 skompiluje się bez błędów, ale test się nie powiedzie:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Zauważ, że kod spowodował panikę z komunikatem already borrowed: BorrowMutError. W ten sposób RefCell<T> obsługuje naruszenia zasad
pożyczania w czasie wykonania.
Decyzja o wychwytywaniu błędów pożyczania w czasie wykonania, a nie w czasie
kompilacji, jak to zrobiliśmy tutaj, oznacza, że potencjalnie możesz
znajdować błędy w swoim kodzie później w procesie rozwoju: być może dopiero po
wdrożeniu kodu do produkcji. Ponadto, Twój kod poniesie niewielką karę
wydajnościową w czasie wykonania w wyniku śledzenia pożyczeń w czasie
wykonania, a nie w czasie kompilacji. Jednakże, użycie RefCell<T> umożliwia
napisanie obiektu mockowego, który może modyfikować się, aby śledzić
wiadomości, które widział, podczas gdy używasz go w kontekście, w którym
dozwolone są tylko niemutowalne wartości. Możesz używać RefCell<T> pomimo
jego kompromisów, aby uzyskać większą funkcjonalność niż zapewniają zwykłe
referencje.
Zezwalanie na wielu właścicieli mutowalnych danych
Częstym sposobem użycia RefCell<T> jest połączenie go z Rc<T>. Przypomnijmy,
że Rc<T> pozwala na posiadanie wielu właścicieli danych, ale daje dostęp do
tych danych tylko w trybie niemutowalnym. Jeśli masz Rc<T>, który zawiera
RefCell<T>, możesz uzyskać wartość, która może mieć wielu właścicieli i którą
możesz modyfikować!
Na przykład, przypomnij sobie przykład listy konsensusowej z Listingu 15-18,
w którym użyliśmy Rc<T>, aby umożliwić wielu listom współdzielenie własności
innej listy. Ponieważ Rc<T> przechowuje tylko niemutowalne wartości, nie możemy
zmienić żadnej z wartości na liście po ich utworzeniu. Dodajmy RefCell<T>,
aby móc zmieniać wartości na listach. Listing 15-24 pokazuje, że używając
RefCell<T> w definicji Cons, możemy modyfikować wartość przechowywaną we
wszystkich listach.
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {a:?}");
println!("b after = {b:?}");
println!("c after = {c:?}");
}Tworzymy wartość, która jest instancją Rc<RefCell<i32>> i przechowujemy ją
w zmiennej o nazwie value, abyśmy mogli uzyskać do niej bezpośredni dostęp
później. Następnie tworzymy List w a z wariantem Cons, który przechowuje
value. Musimy sklonować value, aby zarówno a, jak i value posiadały
własność wewnętrznej wartości 5, zamiast przenosić własność z value do a
lub aby a pożyczało z value.
Opakowujemy listę a w Rc<T>, aby po utworzeniu list b i c obie mogły
odnosić się do a, co zrobiliśmy w Listingu 15-18.
Po utworzeniu list w a, b i c, chcemy dodać 10 do wartości w value. Robimy
to, wywołując borrow_mut na value, co wykorzystuje funkcję automatycznego
rozpożyczania, którą omówiliśmy w „Gdzie jest operator ->?”
w Rozdziale 5, aby rozpożyczyć Rc<T> do wewnętrznej wartości RefCell<T>. Metoda
borrow_mut zwraca wskaźnik sprytny RefMut<T>, a my używamy na nim operatora
rozpożyczania i zmieniamy wewnętrzną wartość.
Kiedy wypiszemy a, b i c, widzimy, że wszystkie mają zmodyfikowaną
wartość 15 zamiast 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Ta technika jest całkiem sprytna! Używając RefCell<T>, mamy zewnętrznie
niemutowalną wartość List. Ale możemy użyć metod RefCell<T>, które zapewniają
dostęp do jego wewnętrznej mutowalności, dzięki czemu możemy modyfikować nasze
dane, gdy tego potrzebujemy. Sprawdzenia zasad pożyczania w czasie wykonania
chronią nas przed wyścigami danych, a czasami warto poświęcić trochę szybkości
dla tej elastyczności w naszych strukturach danych. Zauważ, że RefCell<T>
nie działa w kodzie wielowątkowym! Mutex<T> to wersja RefCell<T> bezpieczna
wielowątkowo, a o Mutex<T> będziemy rozmawiać w Rozdziale 16.
Cykle referencji mogą prowadzić do wycieków pamięci
Cykle referencji mogą prowadzić do wycieków pamięci
Gwarancje bezpieczeństwa pamięci w Rust sprawiają, że trudno, ale nie jest
niemożliwe, przypadkowe tworzenie pamięci, która nigdy nie jest zwalniana (znane
jako wyciek pamięci). Całkowite zapobieganie wyciekom pamięci nie jest jedną
z gwarancji Rust, co oznacza, że wycieki pamięci są bezpieczne w Rust. Możemy
zobaczyć, że Rust dopuszcza wycieki pamięci, używając Rc<T> i RefCell<T>:
Możliwe jest tworzenie referencji, w których elementy odwołują się do siebie
w cyklu. Tworzy to wycieki pamięci, ponieważ licznik referencji każdego
elementu w cyklu nigdy nie osiągnie 0, a wartości nigdy nie zostaną usunięte.
Tworzenie cyklu referencji
Przyjrzyjmy się, jak może powstać cykl referencji i jak mu zapobiec, zaczynając
od definicji enum List i metody tail w Listingu 15-25.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {}Używamy kolejnej wariacji definicji List z Listingu 15-5. Drugi element
wariantu Cons to teraz RefCell<Rc<List>>, co oznacza, że zamiast możliwości
modyfikacji wartości i32, jak to robiliśmy w Listingu 15-24, chcemy
modyfikować wartość List, na którą wskazuje wariant Cons. Dodajemy również
metodę tail, aby ułatwić nam dostęp do drugiego elementu, jeśli mamy wariant
Cons.
W Listingu 15-26 dodajemy funkcję main, która używa definicji z Listingu
15-25. Ten kod tworzy listę w a i listę w b, która wskazuje na listę w a.
Następnie modyfikuje listę w a, aby wskazywała na b, tworząc cykl
referencji. Po drodze znajdują się instrukcje println!, aby pokazać, jakie
są liczniki referencji w różnych punktach tego procesu.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack.
// println!("a next item = {:?}", a.tail());
}Tworzymy instancję Rc<List> przechowującą wartość List w zmiennej a z
początkową listą 5, Nil. Następnie tworzymy instancję Rc<List> przechowującą
inna wartość List w zmiennej b, która zawiera wartość 10 i wskazuje na
listę w a.
Modyfikujemy a tak, aby wskazywała na b zamiast Nil, tworząc cykl.
Robimy to, używając metody tail do uzyskania referencji do
RefCell<Rc<List>> w a, którą umieszczamy w zmiennej link. Następnie
używamy metody borrow_mut w RefCell<Rc<List>>, aby zmienić wewnętrzną
wartość z Rc<List>, która przechowuje wartość Nil, na Rc<List> w b.
Po uruchomieniu tego kodu, z pominięciem ostatniego println! na razie,
otrzymamy następujący wynik:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Licznik referencji instancji Rc<List> zarówno w a, jak i b wynosi 2 po
zmianie listy w a na wskazującą na b. Na końcu main Rust usuwa zmienną
b, co zmniejsza licznik referencji instancji Rc<List> z b z 2 do 1.
Pamięć, którą Rc<List> ma na stercie, nie zostanie w tym momencie usunięta,
ponieważ jej licznik referencji wynosi 1, a nie 0. Następnie Rust usuwa a, co
zmniejsza licznik referencji instancji Rc<List> z a również z 2 do 1.
Pamięć tej instancji również nie może zostać usunięta, ponieważ inna instancja
Rc<List> nadal się do niej odwołuje. Pamięć alokowana na listę pozostanie
niezebrana na zawsze. Aby zwizualizować ten cykl referencji, stworzyliśmy
diagram na Rysunku 15-4.

Rysunek 15-4: Cykl referencji list a i b
wskazujących na siebie nawzajem
Jeśli odkomentujesz ostatnią instrukcję println! i uruchomisz program, Rust
spróbuje wypisać ten cykl, w którym a wskazuje na b, b na a i tak dalej,
aż do przepełnienia stosu.
W porównaniu do rzeczywistego programu, konsekwencje tworzenia cyklu referencji w tym przykładzie nie są bardzo poważne: zaraz po utworzeniu cyklu referencji program się kończy. Jednakże, jeśli bardziej złożony program alokowałby dużo pamięci w cyklu i utrzymywał ją przez długi czas, program zużywałby więcej pamięci niż potrzebował i mógłby przeciążyć system, powodując wyczerpanie dostępnej pamięci.
Tworzenie cykli referencji nie jest łatwe, ale też nie niemożliwe. Jeśli masz
wartości RefCell<T>, które zawierają wartości Rc<T> lub podobne zagnieżdżone
połączenia typów z mutowalnością wewnętrzną i zliczaniem referencji, musisz
zapewnić, że nie tworzysz cykli; nie możesz polegać na Rust w ich
wykrywaniu. Tworzenie cyklu referencji byłoby błędem logicznym w twoim
programie, który powinieneś minimalizować za pomocą automatycznych testów,
przeglądów kodu i innych praktyk rozwoju oprogramowania.
Innym rozwiązaniem pozwalającym uniknąć cykli referencji jest reorganizacja
struktur danych tak, aby niektóre referencje wyrażały własność, a inne nie.
W rezultacie możesz mieć cykle składające się z relacji własności i relacji
braku własności, a tylko relacje własności wpływają na to, czy wartość może
zostać usunięta. W Listingu 15-25 zawsze chcemy, aby warianty Cons posiadały
swoją listę, więc reorganizacja struktury danych nie jest możliwa.
Przyjrzyjmy się przykładowi używającemu grafów składających się z węzłów
rodzicielskich i węzłów potomnych, aby zobaczyć, kiedy relacje braku własności
są odpowiednim sposobem na zapobieganie cyklom referencji.
Zapobieganie cyklom referencji za pomocą Weak<T>
Do tej pory wykazaliśmy, że wywołanie Rc::clone zwiększa strong_count
instancji Rc<T>, a instancja Rc<T> jest usuwana tylko, jeśli jej
strong_count wynosi 0. Możesz również utworzyć słabą referencję do wartości
w instancji Rc<T>, wywołując Rc::downgrade i przekazując referencję do
Rc<T>. Silne referencje to sposób na współdzielenie własności instancji
Rc<T>. Słabe referencje nie wyrażają relacji własności, a ich licznik nie
wpływa na to, kiedy instancja Rc<T> jest usuwana. Nie spowodują one cyklu
referencji, ponieważ każdy cykl zawierający słabe referencje zostanie przerwany,
gdy silny licznik referencji wartości w nim zaangażowanych osiągnie 0.
Kiedy wywołujesz Rc::downgrade, otrzymujesz wskaźnik sprytny typu Weak<T>.
Zamiast zwiększać strong_count w instancji Rc<T> o 1, wywołanie
Rc::downgrade zwiększa weak_count o 1. Typ Rc<T> używa weak_count do
śledzenia liczby istniejących referencji Weak<T>, podobnie jak strong_count.
Różnica polega na tym, że weak_count nie musi wynosić 0, aby instancja Rc<T>
została usunięta.
Ponieważ wartość, do której odwołuje się Weak<T>, mogła zostać usunięta, aby
coś zrobić z wartością, na którą wskazuje Weak<T>, musisz upewnić się, że
wartość nadal istnieje. Zrób to, wywołując metodę upgrade na instancji
Weak<T>, która zwróci Option<Rc<T>>. Otrzymasz wynik Some, jeśli wartość
Rc<T> nie została jeszcze usunięta, i wynik None, jeśli wartość Rc<T>
została usunięta. Ponieważ upgrade zwraca Option<Rc<T>>, Rust zapewni,
że przypadki Some i None zostaną obsłużone, i nie będzie nieprawidłowego
wskaźnika.
Jako przykład, zamiast używać listy, której elementy wiedzą tylko o następnym elemencie, stworzymy drzewo, którego elementy wiedzą o swoich elementach potocznych i swoich elementach nadrzędnych.
Tworzenie struktury danych drzewa
Na początek zbudujemy drzewo z węzłami, które wiedzą o swoich węzłach
potocznych. Stworzymy strukturę o nazwie Node, która będzie zawierała własną
wartość i32, a także referencje do swoich potomnych węzłów Node:
Nazwa pliku: src/main.rs
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Chcemy, aby Node był właścicielem swoich dzieci, i chcemy współdzielić tę
własność ze zmiennymi, abyśmy mogli bezpośrednio uzyskiwać dostęp do każdego
Node w drzewie. Aby to zrobić, definiujemy elementy Vec<T> jako wartości
typu Rc<Node>. Chcemy również modyfikować, które węzły są dziećmi innego
węzła, więc mamy RefCell<T> w children wokół Vec<Rc<Node>>.
Następnie użyjemy naszej definicji struktury i stworzymy jedną instancję
Node o nazwie leaf z wartością 3 i bez dzieci, oraz inną instancję o
nazwie branch z wartością 5 i leaf jako jedno z jej dzieci, jak pokazano
w Listingu 15-27.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Klonujemy Rc<Node> z leaf i przechowujemy go w branch, co oznacza, że
Node z leaf ma teraz dwóch właścicieli: leaf i branch. Możemy przejść
od branch do leaf poprzez branch.children, ale nie ma sposobu, aby
przejść od leaf do branch. Powodem jest to, że leaf nie ma referencji do
branch i nie wie, że są ze sobą powiązane. Chcemy, aby leaf wiedziało,
że branch jest jego rodzicem. Zrobimy to w następnym kroku.
Dodawanie referencji od dziecka do jego rodzica
Aby węzeł potomny był świadomy swojego rodzica, musimy dodać pole parent do
definicji naszej struktury Node. Problem polega na podjęciu decyzji, jaki
typ powinno mieć parent. Wiemy, że nie może zawierać Rc<T>, ponieważ
stworzyłoby to cykl referencji, w którym leaf.parent wskazywałoby na branch,
a branch.children na leaf, co spowodowałoby, że ich wartości
strong_count nigdy nie byłyby równe 0.
Rozważając relacje w inny sposób, węzeł rodzicielski powinien być właścicielem swoich dzieci: Jeśli węzeł rodzicielski zostanie usunięty, jego węzły potomne również powinny zostać usunięte. Jednak dziecko nie powinno być właścicielem swojego rodzica: Jeśli usuniemy węzeł potomny, rodzic powinien nadal istnieć. To przypadek dla słabych referencji!
Tak więc, zamiast Rc<T>, typ parent będzie używał Weak<T>, a konkretnie
RefCell<Weak<Node>>. Teraz definicja naszej struktury Node wygląda
tak:
Nazwa pliku: src/main.rs
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}Węzeł będzie mógł odwoływać się do swojego węzła rodzicielskiego, ale nie
posiada swojego rodzica. W Listingu 15-28 aktualizujemy main, aby używał tej
nowej definicji, tak aby węzeł leaf miał sposób odwoływania się do swojego
rodzica, branch.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}Tworzenie węzła leaf wygląda podobnie do Listingu 15-27, z wyjątkiem pola
parent: leaf zaczyna bez rodzica, więc tworzymy nową, pustą instancję
referencji Weak<Node>.
W tym momencie, gdy próbujemy uzyskać referencję do rodzica leaf za pomocą
metody upgrade, otrzymujemy wartość None. Widzimy to w wynikach pierwszej
instrukcji println!:
leaf parent = None
Kiedy tworzymy węzeł branch, będzie on również miał nową referencję Weak<Node>
w polu parent, ponieważ branch nie ma węzła rodzicielskiego. Nadal mamy
leaf jako jedno z dzieci branch. Gdy już mamy instancję Node w branch,
możemy zmodyfikować leaf, aby nadać mu referencję Weak<Node> do jego rodzica.
Używamy metody borrow_mut w RefCell<Weak<Node>> w polu parent węzła leaf,
a następnie używamy funkcji Rc::downgrade do stworzenia referencji Weak<Node>
do branch z Rc<Node> w branch.
Kiedy ponownie wypiszemy rodzica leaf, tym razem otrzymamy wariant Some
przechowujący branch: Teraz leaf może uzyskać dostęp do swojego rodzica!
Gdy wypiszemy leaf, unikamy również cyklu, który ostatecznie zakończył się
przepełnieniem stosu, jak to miało miejsce w Listingu 15-26; referencje
Weak<Node> są wypisywane jako (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
Brak nieskończonego wyniku wskazuje, że ten kod nie stworzył cyklu referencji.
Możemy to również stwierdzić, patrząc na wartości, które otrzymujemy po
wywołaniu Rc::strong_count i Rc::weak_count.
Wizualizacja zmian w strong_count i weak_count
Spójrzmy, jak zmieniają się wartości strong_count i weak_count instancji
Rc<Node>, tworząc nowy wewnętrzny zakres i przenosząc tworzenie branch do
tego zakresu. W ten sposób możemy zobaczyć, co dzieje się, gdy branch jest
tworzone, a następnie usuwane, gdy wyjdzie poza zakres. Modyfikacje pokazano
w Listingu 15-29.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}Po utworzeniu leaf, jego Rc<Node> ma silny licznik równy 1 i słaby licznik
równy 0. W wewnętrznym zakresie tworzymy branch i kojarzymy go z leaf, po
czym, gdy wypiszemy liczniki, Rc<Node> w branch będzie miało silny licznik
równy 1 i słaby licznik równy 1 (dla leaf.parent wskazującego na branch za
pomocą Weak<Node>). Kiedy wypiszemy liczniki w leaf, zobaczymy, że będzie
miało silny licznik równy 2, ponieważ branch ma teraz klon Rc<Node> z leaf
przechowywany w branch.children, ale nadal będzie miało słaby licznik równy
0.
Kiedy wewnętrzny zakres się kończy, branch wychodzi poza zakres, a silny
licznik Rc<Node> zmniejsza się do 0, więc jego Node zostaje usunięty.
Słaby licznik równy 1 z leaf.parent nie ma wpływu na to, czy Node jest
usuwany, więc nie mamy wycieków pamięci!
Jeśli spróbujemy uzyskać dostęp do rodzica leaf po zakończeniu zakresu,
ponownie otrzymamy None. Na końcu programu Rc<Node> w leaf ma silny
licznik równy 1 i słaby licznik równy 0, ponieważ zmienna leaf jest teraz
ponownie jedyną referencją do Rc<Node>.
Wszystkie logiki zarządzające licznikami i usuwaniem wartości są wbudowane w
Rc<T> i Weak<T> oraz ich implementacje cechy Drop. Określając, że
relacja od dziecka do rodzica powinna być referencją Weak<T> w definicji
Node, jesteś w stanie sprawić, że węzły rodzicielskie wskazują na węzły
potoczne i vice versa bez tworzenia cyklu referencji i wycieków pamięci.
Podsumowanie
Ten rozdział omówił, jak używać wskaźników sprytnych, aby uzyskać różne
gwarancje i kompromisy w porównaniu do tych, które Rust domyślnie zapewnia ze
zwykłymi referencjami. Typ Box<T> ma znany rozmiar i wskazuje na dane
alokowane na stercie. Typ Rc<T> śledzi liczbę referencji do danych na stercie,
tak aby dane mogły mieć wielu właścicieli. Typ RefCell<T> ze swoją
mutowalnością wewnętrzną daje nam typ, którego możemy używać, gdy potrzebujemy
nimutowalnego typu, ale musimy zmienić wewnętrzną wartość tego typu; egzekwuje
on również zasady pożyczania w czasie wykonania zamiast w czasie kompilacji.
Omówiono również cechy Deref i Drop, które umożliwiają wiele funkcjonalności
wskaźników sprytnych. Zbadaliśmy cykle referencji, które mogą powodować wycieki
pamięci, i jak im zapobiegać za pomocą Weak<T>.
Jeśli ten rozdział wzbudził Twoje zainteresowanie i chcesz zaimplementować własne wskaźniki sprytne, zajrzyj do „The Rustonomicon” po więcej przydatnych informacji.
Następnie będziemy rozmawiać o współbieżności w Rust. Nauczysz się nawet kilku nowych wskaźników sprytnych.
Bezpieczna współbieżność
Bezpieczne i efektywne zarządzanie programowaniem współbieżnym to kolejny z głównych celów Rust. Programowanie współbieżne, w którym różne części programu wykonują się niezależnie, oraz programowanie równoległe, w którym różne części programu wykonują się w tym samym czasie, stają się coraz ważniejsze, ponieważ coraz więcej komputerów wykorzystuje swoje wieloprocesorowe możliwości. Historycznie programowanie w tych kontekstach było trudne i podatne na błędy. Rust ma nadzieję to zmienić.
Początkowo zespół Rust uważał, że zapewnienie bezpieczeństwa pamięci i zapobieganie problemom współbieżności to dwa oddzielne wyzwania do rozwiązania różnymi metodami. Z czasem zespół odkrył, że systemy własności i typów to potężny zestaw narzędzi pomagających zarządzać zarówno bezpieczeństwem pamięci, jak i problemami współbieżności! Dzięki wykorzystaniu własności i sprawdzania typów, wiele błędów współbieżności w Rust to błędy kompilacji, a nie błędy czasu wykonania. Dlatego, zamiast zmuszać Cię do spędzania wielu godzin na próbach odtworzenia dokładnych okoliczności, w których występuje błąd współbieżności w czasie wykonania, niepoprawny kod odmówi kompilacji i wyświetli błąd wyjaśniający problem. W rezultacie możesz naprawić swój kod podczas pracy nad nim, a nie potencjalnie po jego wdrożeniu do produkcji. Nazwaliśmy ten aspekt Rust bezpieczną współbieżnością. Bezpieczna współbieżność pozwala pisać kod wolny od subtelnych błędów i łatwy do refaktoryzacji bez wprowadzania nowych błędów.
Uwaga: Dla uproszczenia będziemy odnosić się do wielu problemów jako współbieżnych, zamiast być bardziej precyzyjnym, mówiąc współbieżnych i/lub równoległych. W tym rozdziale proszę mentalnie zastępować współbieżnych i/lub równoległych za każdym razem, gdy używamy współbieżnych. W następnym rozdziale, gdzie rozróżnienie ma większe znaczenie, będziemy bardziej precyzyjni.
Wiele języków jest dogmatycznych w kwestii rozwiązań, które oferują do obsługi problemów współbieżności. Na przykład, Erlang ma elegancką funkcjonalność dla współbieżności opartej na przekazywaniu wiadomości, ale ma tylko niejasne sposoby udostępniania stanu między wątkami. Obsługiwanie tylko podzbioru możliwych rozwiązań jest rozsądną strategią dla języków wyższego poziomu, ponieważ język wyższego poziomu obiecuje korzyści z oddawania części kontroli w zamian za abstrakcje. Jednak od języków niższego poziomu oczekuje się, że zapewnią rozwiązanie o najlepszej wydajności w każdej danej sytuacji i będą miały mniej abstrakcji nad sprzętem. Dlatego Rust oferuje różnorodne narzędzia do modelowania problemów w sposób odpowiedni dla twojej sytuacji i wymagań.
Oto tematy, które omówimy w tym rozdziale:
- Jak tworzyć wątki do jednoczesnego uruchamiania wielu fragmentów kodu
- Współbieżność oparta na przekazywaniu wiadomości, gdzie kanały wysyłają wiadomości między wątkami
- Współbieżność oparta na współdzielonym stanie, gdzie wiele wątków ma dostęp do pewnej części danych
- Cechy
SynciSend, które rozszerzają gwarancje współbieżności Rust na typy zdefiniowane przez użytkownika, a także na typy dostarczane przez bibliotekę standardową
Używanie wątków do jednoczesnego uruchamiania kodu
Używanie wątków do jednoczesnego uruchamiania kodu
W większości obecnych systemów operacyjnych kod wykonywanego programu działa w procesie, a system operacyjny zarządza wieloma procesami jednocześnie. Wewnątrz programu możesz mieć również niezależne części, które działają jednocześnie. Funkcje, które uruchamiają te niezależne części, nazywane są wątkami. Na przykład, serwer webowy może mieć wiele wątków, aby mógł jednocześnie odpowiadać na więcej niż jedno żądanie.
Podzielenie obliczeń w programie na wiele wątków w celu jednoczesnego uruchamiania wielu zadań może poprawić wydajność, ale także zwiększa złożoność. Ponieważ wątki mogą działać jednocześnie, nie ma inherentnej gwarancji co do kolejności, w jakiej będą działać części kodu na różnych wątkach. Może to prowadzić do problemów, takich jak:
- Wyścigi danych, w których wątki uzyskują dostęp do danych lub zasobów w niekonsekwentnej kolejności
- Zakleszczenia, w których dwa wątki czekają na siebie nawzajem, uniemożliwiając kontynuowanie obu wątków
- Błędy, które występują tylko w określonych sytuacjach i są trudne do niezawodnego odtworzenia i naprawy
Rust próbuje złagodzić negatywne skutki używania wątków, ale programowanie w kontekście wielowątkowym nadal wymaga starannego przemyślenia i innej struktury kodu niż w programach działających w pojedynczym wątku.
Języki programowania implementują wątki na kilka różnych sposobów, a wiele systemów operacyjnych zapewnia API, które język programowania może wywoływać w celu tworzenia nowych wątków. Biblioteka standardowa Rust używa modelu implementacji wątków 1:1, w którym program używa jednego wątku systemu operacyjnego na jeden wątek językowy. Istnieją crate’y, które implementują inne modele wątkowania, które dokonują innych kompromisów w stosunku do modelu 1:1. (System asynchroniczny Rust, który zobaczymy w następnym rozdziale, zapewnia również inne podejście do współbieżności.)
Tworzenie nowego wątku za pomocą spawn
Aby utworzyć nowy wątek, wywołujemy funkcję thread::spawn i przekazujemy jej
domknięcie (o domknięciach mówiliśmy w Rozdziale 13) zawierające kod, który
chcemy uruchomić w nowym wątku. Przykład w Listingu 16-1 wypisuje tekst z
głównego wątku i inny tekst z nowego wątku.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Zauważ, że gdy główny wątek programu Rust zakończy działanie, wszystkie utworzone wątki zostają wyłączone, niezależnie od tego, czy zakończyły działanie. Wynik tego programu może być za każdym razem nieco inny, ale będzie wyglądał podobnie do następującego:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Wywołania thread::sleep zmuszają wątek do zatrzymania jego wykonania na krótki
okres, pozwalając na uruchomienie innego wątku. Wątki prawdopodobnie będą
działać naprzemiennie, ale nie jest to gwarantowane: Zależy to od tego, jak
system operacyjny planuje wątki. W tym uruchomieniu główny wątek wypisał się
jako pierwszy, mimo że instrukcja print z utworzonego wątku pojawia się
pierwsza w kodzie. I chociaż kazaliśmy utworzonemu wątkowi wypisywać, dopóki i
nie będzie równe 9, doszedł tylko do 5, zanim główny wątek się
wyłączył.
Jeśli uruchomisz ten kod i zobaczysz tylko wynik z głównego wątku, lub nie zobaczysz żadnych nakładek, spróbuj zwiększyć liczby w zakresach, aby stworzyć więcej możliwości dla systemu operacyjnego do przełączania między wątkami.
Czekanie na zakończenie wszystkich wątków
Kod z Listingu 16-1 nie tylko zatrzymuje utworzony wątek przedwcześnie w w większości przypadków z powodu zakończenia głównego wątku, ale ponieważ nie ma gwarancji co do kolejności, w jakiej wątki działają, nie możemy również zagwarantować, że utworzony wątek w ogóle się uruchomi!
Problem przedwczesnego zakończenia lub braku uruchomienia utworzonego wątku
możemy naprawić, zapisując wartość zwracaną przez thread::spawn w zmiennej.
Typem zwracanym przez thread::spawn jest JoinHandle<T>. JoinHandle<T>
jest wartością własnościową, która po wywołaniu na niej metody join będzie
czekała na zakończenie swojego wątku. Listing 16-2 pokazuje, jak użyć
JoinHandle<T> z utworzonego w Listingu 16-1 wątku i jak wywołać join, aby
upewnić się, że utworzony wątek zakończy się przed zakończeniem main.
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}Wywołanie join na uchwycie blokuje aktualnie działający wątek, uniemożliwiając
mu wykonywanie pracy lub zakończenie, dopóki wątek reprezentowany przez uchwyt
się nie zakończy. Blokowanie wątku oznacza, że wątek jest uniemożliwiony
wykonanie pracy lub wyjścia. Ponieważ umieściliśmy wywołanie join po pętli
for głównego wątku, uruchomienie Listingu 16-2 powinno wygenerować wynik
podobny do tego:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Dwa wątki nadal działają naprzemiennie, ale główny wątek czeka z powodu wywołania
handle.join() i nie kończy działania, dopóki utworzony wątek się nie
zakończy.
Ale zobaczmy, co się stanie, gdy zamiast tego przeniesiemy handle.join() przed
pętlę for w main, tak:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Główny wątek poczeka na zakończenie utworzonego wątku, a następnie uruchomi
swoją pętlę for, więc wyniki nie będą już przeplatane, jak pokazano
tutaj:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Małe detale, takie jak miejsce wywołania join, mogą wpływać na to, czy wątki
działają jednocześnie.
Używanie domknięć move z wątkami
Często będziemy używać słowa kluczowego move z domknięciami przekazywanymi do
thread::spawn, ponieważ domknięcie przejmie wtedy własność wartości, których
używa ze środowiska, przenosząc w ten sposób własność tych wartości z jednego
wątku do drugiego. W sekcji „Przechwytywanie referencji lub przenoszenie
własności” w Rozdziale 13 omówiliśmy move w kontekście
domknięć. Teraz skupimy się bardziej na interakcji między move a
thread::spawn.
Zauważ w Listingu 16-1, że domknięcie, które przekazujemy do thread::spawn,
nie przyjmuje żadnych argumentów: Nie używamy żadnych danych z głównego wątku
w kodzie utworzonego wątku. Aby użyć danych z głównego wątku w utworzonym
wątku, domknięcie utworzonego wątku musi przechwycić wartości, których
potrzebuje. Listing 16-3 pokazuje próbę utworzenia wektora w głównym wątku i
użycia go w utworzonym wątku. Jednak to jeszcze nie zadziała, jak zobaczysz za
chwilę.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Domknięcie używa v, więc przechwyci v i uczyni je częścią środowiska
domknięcia. Ponieważ thread::spawn uruchamia to domknięcie w nowym wątku,
powinniśmy mieć dostęp do v w tym nowym wątku. Ale kiedy kompilujemy ten
przykład, otrzymujemy następujący błąd:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust wnioskuje, jak przechwycić v, a ponieważ println! potrzebuje tylko
referencji do v, domknięcie próbuje pożyczyć v. Jest jednak problem: Rust
nie jest w stanie określić, jak długo będzie działać utworzony wątek, więc nie
wie, czy referencja do v zawsze będzie ważna.
Listing 16-4 przedstawia scenariusz, w którym referencja do v z większym
prawdopodobieństwem nie będzie ważna.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}Gdyby Rust pozwolił nam uruchomić ten kod, istniałaby możliwość, że utworzony
wątek zostałby natychmiast przeniesiony do tła bez uruchomienia. Utworzony
wątek ma w środku referencję do v, ale główny wątek natychmiast usuwa v
używając funkcji drop, którą omówiliśmy w Rozdziale 15. Wtedy, gdy
utworzony wątek zacznie się wykonywać, v nie jest już ważne, więc referencja
do niego również jest nieważna. Och nie!
Aby naprawić błąd kompilacji w Listingu 16-3, możemy skorzystać z porady z komunikatu o błędzie:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Dodając słowo kluczowe move przed domknięciem, zmuszamy domknięcie do
przejęcia własności wartości, których używa, zamiast pozwalać Rustowi
wnioskować, że powinno ono pożyczyć te wartości. Modyfikacja Listingu 16-3
przedstawiona w Listingu 16-5 skompiluje się i zadziała zgodnie z naszym
zamierzeniem.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Możemy być kuszeni, aby spróbować tego samego, aby naprawić kod z Listingu
16-4, gdzie główny wątek wywołał drop za pomocą domknięcia move. Jednakże,
ta poprawka nie zadziała, ponieważ to, co Listing 16-4 próbuje zrobić, jest
niedozwolone z innego powodu. Gdybyśmy dodali move do domknięcia,
przenieślibyśmy v do środowiska domknięcia i nie moglibyśmy już wywoływać na
v drop w głównym wątku. Zamiast tego otrzymalibyśmy błąd kompilacji:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Zasady własności Rust znów nas uratowały! Otrzymaliśmy błąd z kodu w Listingu
16-3, ponieważ Rust był konserwatywny i tylko pożyczał v dla wątku, co
oznaczało, że główny wątek teoretycznie mógłby unieważnić referencję
utworzonego wątku. Mówiąc Rustowi, aby przeniósł własność v do utworzonego
wątku, gwarantujemy Rustowi, że główny wątek nie będzie już używał v. Jeśli
zmienimy Listing 16-4 w ten sam sposób, naruszamy wtedy zasady własności,
gdy próbujemy użyć v w głównym wątku. Słowo kluczowe move nadpisuje
konserwatywną domyślną pożyczkę Rust; nie pozwala nam naruszać zasad
własności.
Teraz, gdy omówiliśmy, czym są wątki i metody dostarczane przez API wątków, przyjrzyjmy się kilku sytuacjom, w których możemy używać wątków.
Przesyłanie danych między wątkami za pomocą przekazywania wiadomości
Przesyłanie danych między wątkami za pomocą przekazywania wiadomości
Jednym z coraz popularniejszych podejść do zapewnienia bezpiecznej współbieżności jest przekazywanie wiadomości, gdzie wątki lub aktorzy komunikują się, wysyłając sobie wiadomości zawierające dane. Oto idea w haśle z dokumentacji języka Go: „Nie komunikuj się poprzez współdzielenie pamięci; zamiast tego współdziel pamięć poprzez komunikację.”
Aby zrealizować współbieżność opartą na przekazywaniu wiadomości, biblioteka standardowa Rust dostarcza implementację kanałów. Kanał to ogólna koncepcja programistyczna, za pomocą której dane są przesyłane z jednego wątku do drugiego.
Możesz wyobrazić sobie kanał w programowaniu jako kierunkowy kanał wodny, taki jak strumień lub rzeka. Jeśli wrzucisz coś, na przykład gumową kaczkę, do rzeki, będzie ona płynęła w dół rzeki aż do końca szlaku wodnego.
Kanał ma dwie połówki: nadajnik i odbiornik. Połówka nadajnika to miejsce w górze rzeki, gdzie wrzucasz gumową kaczkę, a połówka odbiornika to miejsce, gdzie gumowa kaczka dociera w dół rzeki. Jedna część twojego kodu wywołuje metody na nadajniku z danymi, które chcesz wysłać, a inna część sprawdza koniec odbiorczy pod kątem nadchodzących wiadomości. Kanał jest uważany za zamknięty, jeśli którakolwiek z połówek – nadajnik lub odbiornik – zostanie usunięta.
Tutaj stworzymy program, który będzie miał jeden wątek do generowania wartości i wysyłania ich przez kanał, oraz inny wątek, który będzie odbierał te wartości i wypisywał je. Będziemy przesyłać proste wartości między wątkami za pomocą kanału, aby zilustrować tę funkcję. Gdy już zapoznasz się z tą techniką, będziesz mógł używać kanałów dla dowolnych wątków, które muszą się ze sobą komunikować, np. w systemie czatu lub w systemie, gdzie wiele wątków wykonuje części obliczeń i wysyła je do jednego wątku, który agreguje wyniki.
Najpierw, w Listingu 16-6, stworzymy kanał, ale nic z nim nie zrobimy. Zauważ, że to jeszcze się nie skompiluje, ponieważ Rust nie potrafi określić, jakiego typu wartości chcemy przesyłać przez kanał.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Tworzymy nowy kanał za pomocą funkcji mpsc::channel; mpsc oznacza
multiple producer, single consumer (wielu producentów, jeden konsument). W
skrócie, sposób, w jaki biblioteka standardowa Rust implementuje kanały,
oznacza, że kanał może mieć wiele końców wysyłających, które produkują
wartości, ale tylko jeden koniec odbierający, który te wartości konsumuje.
Wyobraź sobie wiele strumieni spływających do jednej dużej rzeki: Wszystko,
co zostanie wysłane w dół któregokolwiek ze strumieni, znajdzie się w jednej
rzece na końcu. Na razie zaczniemy od jednego producenta, ale dodamy wielu
producentów, gdy ten przykład zadziała.
Funkcja mpsc::channel zwraca krotkę, której pierwszy element to koniec
wysyłający – nadajnik – a drugi element to koniec odbierający – odbiornik.
Skróty tx i rx są tradycyjnie używane w wielu dziedzinach odpowiednio dla
transmitter (nadajnik) i receiver (odbiornik), więc tak nazywamy nasze
zmienne, aby wskazać każdy koniec. Używamy instrukcji let ze wzorcem,
który dekomponuje krotki; o użyciu wzorców w instrukcjach let i
dekompozycji będziemy rozmawiać w Rozdziale 19. Na razie wiedz, że użycie
instrukcji let w ten sposób jest wygodnym podejściem do wyodrębniania
elementów krotki zwracanej przez mpsc::channel.
Przenieśmy koniec nadawczy do utworzonego wątku i niech wyśle jeden ciąg znaków, tak aby utworzony wątek komunikował się z głównym wątkiem, jak pokazano w Listingu 16-7. To jest jak wrzucenie gumowej kaczki do rzeki w górnym biegu lub wysłanie wiadomości na czacie z jednego wątku do drugiego.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
}Ponownie używamy thread::spawn do utworzenia nowego wątku, a następnie
używamy move do przeniesienia tx do domknięcia, tak aby utworzony wątek
był właścicielem tx. Utworzony wątek musi być właścicielem nadajnika, aby
móc wysyłać wiadomości przez kanał.
Nadajnik ma metodę send, która przyjmuje wartość, którą chcemy wysłać.
Metoda send zwraca typ Result<T, E>, więc jeśli odbiornik został już
usunięty i nie ma dokąd wysłać wartości, operacja wysyłania zwróci błąd.
W tym przykładzie wywołujemy unwrap, aby spowodować panikę w przypadku błędu.
Ale w prawdziwej aplikacji obsłużylibyśmy to poprawnie: Wróć do Rozdziału 9,
aby przejrzeć strategie właściwej obsługi błędów.
W Listingu 16-8 pobierzemy wartość z odbiornika w głównym wątku. To jest jak pobieranie gumowej kaczki z wody na końcu rzeki lub odbieranie wiadomości na czacie.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}Odbiornik ma dwie przydatne metody: recv i try_recv. Używamy recv,
skrótu od receive (odbierz), która zablokuje wykonanie głównego wątku i
poczeka, aż wartość zostanie wysłana przez kanał. Gdy tylko wartość zostanie
wysłana, recv zwróci ją w Result<T, E>. Gdy nadajnik zostanie zamknięty,
recv zwróci błąd, sygnalizując, że nie nadejdą już więcej wartości.
Metoda try_recv nie blokuje, ale zamiast tego natychmiast zwraca Result<T, E>: wartość Ok zawierającą wiadomość, jeśli jest dostępna, oraz wartość
Err, jeśli tym razem nie ma żadnych wiadomości. Użycie try_recv jest
przydatne, jeśli ten wątek ma inną pracę do wykonania podczas oczekiwania na
wiadomości: Moglibyśmy napisać pętlę, która co jakiś czas wywołuje try_recv,
obchodzi wiadomość, jeśli jest dostępna, a w przeciwnym razie wykonuje inną
pracę przez jakiś czas, zanim ponownie sprawdzi.
W tym przykładzie dla uproszczenia użyliśmy recv; główny wątek nie ma innej
pracy do wykonania poza czekaniem na wiadomości, więc blokowanie głównego
wątku jest odpowiednie.
Po uruchomieniu kodu z Listingu 16-8 zobaczymy wartość wypisaną z głównego wątku:
Got: hi
Idealnie!
Przenoszenie własności przez kanały
Zasady własności odgrywają kluczową rolę w przesyłaniu wiadomości, ponieważ
pomagają pisać bezpieczny, współbieżny kod. Zapobieganie błędom w programowaniu
współbieżnym to zaleta myślenia o własności w całym programie Rust. Przeprowadźmy
eksperyment, aby pokazać, jak kanały i własność współpracują, aby zapobiegać
problemom: Spróbujemy użyć wartości val w utworzonym wątku po tym, jak
wysłaliśmy ją przez kanał. Spróbuj skompilować kod z Listingu 16-9, aby
zobaczyć, dlaczego ten kod jest niedozwolony.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}Tutaj próbujemy wypisać val po tym, jak wysłaliśmy go przez kanał za pomocą
tx.send. Zezwolenie na to byłoby złym pomysłem: Gdy wartość zostanie
wysłana do innego wątku, ten wątek mógłby ją zmodyfikować lub usunąć, zanim
ponownie spróbujemy jej użyć. Potencjalnie modyfikacje innego wątku mogłyby
spowodować błędy lub nieoczekiwane rezultaty z powodu niespójnych lub
nieistniejących danych. Jednak Rust zgłasza błąd, jeśli spróbujemy
skompilować kod z Listingu 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Nasz błąd współbieżności spowodował błąd kompilacji. Funkcja send przejmuje
własność swojego parametru, a po przeniesieniu wartości odbiornik przejmuje jej
własność. To uniemożliwia nam przypadkowe ponowne użycie wartości po jej
wysłaniu; system własności sprawdza, czy wszystko jest w porządku.
Wysyłanie wielu wartości
Kod z Listingu 16-8 skompilował się i zadziałał, ale nie pokazał nam jasno, że dwa oddzielne wątki komunikowały się ze sobą przez kanał.
W Listingu 16-10 wprowadziliśmy pewne modyfikacje, które udowodnią, że kod z Listingu 16-8 działa współbieżnie: utworzony wątek będzie teraz wysyłał wiele wiadomości i pauzował na sekundę między każdą wiadomością.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}Tym razem utworzony wątek ma wektor ciągów, które chcemy wysłać do głównego
wątku. Iterujemy po nich, wysyłając każdy z osobna i pauzując między każdym,
wywołując funkcję thread::sleep z wartością Duration wynoszącą jedną sekundę.
W głównym wątku nie wywołujemy już jawnie funkcji recv: Zamiast tego
traktujemy rx jako iterator. Dla każdej otrzymanej wartości wypisujemy ją.
Gdy kanał zostanie zamknięty, iteracja się zakończy.
Podczas uruchamiania kodu z Listingu 16-10 powinieneś zobaczyć następujący wynik z jednominutową przerwą między każdą linią:
Got: hi
Got: from
Got: the
Got: thread
Ponieważ nie mamy żadnego kodu, który pauzuje lub opóźnia w pętli for w
głównym wątku, możemy stwierdzić, że główny wątek czeka na odebranie wartości
z utworzonego wątku.
Tworzenie wielu producentów
Wcześniej wspomnieliśmy, że mpsc to skrót od multiple producer, single
consumer (wiele producentów, jeden konsument). Wykorzystajmy mpsc i
rozszerzmy kod z Listingu 16-10, aby utworzyć wiele wątków, które wszystkie
wysyłają wartości do tego samego odbiornika. Możemy to zrobić, klonując
nadajnik, jak pokazano w Listingu 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}Tym razem, zanim utworzymy pierwszy wątek, wywołujemy clone na nadajniku.
Spowoduje to utworzenie nowego nadajnika, który możemy przekazać do pierwszego
utworzonego wątku. Oryginalny nadajnik przekazujemy do drugiego utworzonego
wątku. Daje nam to dwa wątki, każdy wysyłający różne wiadomości do jednego
odbiornika.
Po uruchomieniu kodu, wynik powinien wyglądać mniej więcej tak:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
Możesz zobaczyć wartości w innej kolejności, w zależności od twojego systemu.
To właśnie sprawia, że współbieżność jest interesująca, a także trudna. Jeśli
poeksperymentujesz z thread::sleep, nadając mu różne wartości w różnych
wątkach, każde uruchomienie będzie bardziej niedeterministyczne i za każdym
razem będzie generować inne dane wyjściowe.
Teraz, gdy przyjrzeliśmy się, jak działają kanały, spójrzmy na inną metodę współbieżności.
Współbieżność ze współdzielonym stanem
Współbieżność ze współdzielonym stanem
Przekazywanie wiadomości to dobry sposób na obsługę współbieżności, ale nie jedyny. Inną metodą byłoby, aby wiele wątków uzyskiwało dostęp do tych samych współdzielonych danych. Ponownie rozważmy tę część sloganu z dokumentacji języka Go: „Nie komunikuj się poprzez współdzielenie pamięci.”
Jak wyglądałaby komunikacja poprzez współdzielenie pamięci? Ponadto, dlaczego entuzjaści przekazywania wiadomości ostrzegaliby przed używaniem współdzielenia pamięci?
Pod pewnym względem kanały w każdym języku programowania są podobne do pojedynczej własności, ponieważ po przeniesieniu wartości przez kanał nie powinno się już więcej używać tej wartości. Współbieżność oparta na współdzielonej pamięci jest jak wielokrotna własność: Wiele wątków może uzyskiwać dostęp do tego samego miejsca w pamięci w tym samym czasie. Jak widziałeś w Rozdziale 15, gdzie wskaźniki sprytne umożliwiły wielokrotną własność, wielokrotna własność może zwiększyć złożoność, ponieważ ci różni właściciele wymagają zarządzania. System typów Rust i zasady własności znacznie pomagają w prawidłowym zarządzaniu. Na przykład, przyjrzyjmy się muteksom, jednej z najpopularniejszych prymitywów współbieżności dla współdzielonej pamięci.
Kontrolowanie dostępu za pomocą muteksów
Muteks to skrót od mutual exclusion (wzajemne wykluczenie), co oznacza, że muteks pozwala tylko jednemu wątkowi na dostęp do danych w danym momencie. Aby uzyskać dostęp do danych w muteksie, wątek musi najpierw zasygnalizować, że chce uzyskać dostęp, prosząc o nabycie blokady muteksu. Blokada to struktura danych, która jest częścią muteksu i śledzi, kto aktualnie ma wyłączny dostęp do danych. Dlatego muteks jest opisywany jako ochraniający dane, które przechowuje, za pomocą systemu blokowania.
Muteksy mają reputację trudnych w użyciu, ponieważ trzeba pamiętać o dwóch zasadach:
- Musisz spróbować uzyskać blokadę przed użyciem danych.
- Kiedy skończysz korzystać z danych chronionych przez muteks, musisz zwolnić blokadę, aby inne wątki mogły ją uzyskać.
Na przykład, wyobraź sobie panel dyskusyjny na konferencji z tylko jednym mikrofonem. Zanim panelista będzie mógł mówić, musi zapytać lub zasygnalizować, że chce użyć mikrofonu. Kiedy dostanie mikrofon, może mówić tak długo, jak chce, a następnie przekazać mikrofon kolejnemu panelistowi, który poprosi o mówienie. Jeśli panelista zapomni oddać mikrofon, gdy skończy z niego korzystać, nikt inny nie będzie mógł mówić. Jeśli zarządzanie wspólnym mikrofonem pójdzie źle, panel nie zadziała zgodnie z planem!
Zarządzanie muteksami może być niezwykle trudne do prawidłowego wykonania, dlatego tak wiele osób jest entuzjastycznie nastawionych do kanałów. Jednak dzięki systemowi typów i zasadom własności Rust, nie można pomylić się z blokowaniem i odblokowywaniem.
API Mutex<T>
Jako przykład użycia muteksu, zacznijmy od użycia muteksu w kontekście jednowątkowym, jak pokazano w Listingu 16-12.
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut num = m.lock().unwrap();
*num = 6;
}
println!("m = {m:?}");
}Podobnie jak w przypadku wielu typów, tworzymy Mutex<T> za pomocą
skojarzonej funkcji new. Aby uzyskać dostęp do danych wewnątrz muteksu,
używamy metody lock, aby uzyskać blokadę. To wywołanie zablokuje bieżący
wątek, tak aby nie mógł on wykonywać żadnej pracy, dopóki nie nadejdzie nasza
kolej na uzyskanie blokady.
Wywołanie lock zakończyłoby się niepowodzeniem, gdyby inny wątek trzymający
blokadę wywołał panikę. W takim przypadku nikt nigdy nie mógłby uzyskać blokady,
dlatego zdecydowaliśmy się na unwrap, aby ten wątek wywołał panikę, jeśli
znajdziemy się w takiej sytuacji.
Po uzyskaniu blokady, możemy traktować zwróconą wartość, nazwaną w tym przypadku
num, jako mutowalną referencję do wewnętrznych danych. System typów
gwarantuje, że uzyskujemy blokadę przed użyciem wartości w m. Typ m to
Mutex<i32>, a nie i32, więc musimy wywołać lock, aby móc użyć wartości
i32. Nie możemy zapomnieć; system typów w przeciwnym razie nie pozwoli nam
na dostęp do wewnętrznej wartości i32.
Wywołanie lock zwraca typ nazwany MutexGuard, opakowany w LockResult,
który obsłużyliśmy wywołaniem unwrap. Typ MutexGuard implementuje Deref,
aby wskazywać na nasze wewnętrzne dane; typ ten ma również implementację Drop,
która automatycznie zwalnia blokadę, gdy MutexGuard wyjdzie poza zakres,
co dzieje się na końcu wewnętrznego zakresu. W rezultacie nie ryzykujemy
zapomnienia o zwolnieniu blokady i zablokowania muteksu przed użyciem przez
inne wątki, ponieważ zwolnienie blokady odbywa się automatycznie.
Po zwolnieniu blokady możemy wypisać wartość muteksu i zobaczyć, że udało nam
się zmienić wewnętrzną wartość i32 na 6.
Współdzielony dostęp do Mutex<T>
Teraz spróbujmy współdzielić wartość między wieloma wątkami za pomocą Mutex<T>.
Uruchomimy 10 wątków i każdy z nich zwiększy wartość licznika o 1, więc licznik
wzrośnie od 0 do 10. Przykład w Listingu 16-13 spowoduje błąd kompilacji, a my
wykorzystamy ten błąd, aby dowiedzieć się więcej o używaniu Mutex<T> i o tym,
jak Rust pomaga nam używać go poprawnie.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Tworzymy zmienną counter do przechowywania i32 wewnątrz Mutex<T>, tak jak
zrobiliśmy to w Listingu 16-12. Następnie tworzymy 10 wątków, iterując po
zakresie liczb. Używamy thread::spawn i przekazujemy wszystkim wątkom to
samo domknięcie: takie, które przenosi licznik do wątku, uzyskuje blokadę na
Mutex<T> poprzez wywołanie metody lock, a następnie dodaje 1 do wartości w
muteksie. Gdy wątek zakończy wykonywanie swojego domknięcia, num wyjdzie
poza zakres i zwolni blokadę, aby inny wątek mógł ją uzyskać.
W głównym wątku zbieramy wszystkie uchwyty join. Następnie, jak to zrobiliśmy
w Listingu 16-2, wywołujemy join na każdym uchwycie, aby upewnić się, że
wszystkie wątki się zakończyły. W tym momencie główny wątek uzyska blokadę i
wypisze wynik tego programu.
Sugerowaliśmy, że ten przykład się nie skompiluje. Teraz dowiemy się, dlaczego!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Komunikat o błędzie wskazuje, że wartość counter została przeniesiona w
poprzedniej iteracji pętli. Rust informuje nas, że nie możemy przenieść własności
blokady counter do wielu wątków. Naprawmy błąd kompilacji, używając metody
wielokrotnej własności, którą omówiliśmy w Rozdziale 15.
Wielokrotna własność z wieloma wątkami
W Rozdziale 15, nadaliśmy wartość wielu właścicielom, używając wskaźnika
sprytnego Rc<T> do stworzenia wartości zliczanej referencjami. Zróbmy to samo
tutaj i zobaczmy, co się stanie. Opakujemy Mutex<T> w Rc<T> w Listingu 16-14
i sklonujemy Rc<T> przed przeniesieniem własności do wątku.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Ponownie kompilujemy i otrzymujemy… inne błędy! Kompilator wiele nas uczy:
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Wow, ten komunikat o błędzie jest bardzo rozwlekły! Oto najważniejsza część, na
której należy się skupić: `Rc<Mutex<i32>>` cannot be sent between threads safely. Kompilator podaje nam również przyczynę: the trait `Send` is not implemented for `Rc<Mutex<i32>>`. O Send będziemy rozmawiać w następnej
sekcji: Jest to jedna z cech, która zapewnia, że typy, których używamy z
wątkami, są przeznaczone do użytku w sytuacjach współbieżnych.
Niestety, Rc<T> nie jest bezpieczny do współdzielenia między wątkami. Kiedy
Rc<T> zarządza licznikiem referencji, dodaje do licznika dla każdego wywołania
clone i odejmuje od licznika, gdy każdy klon zostanie usunięty. Ale nie używa
żadnych prymitywów współbieżności, aby upewnić się, że zmiany w liczniku nie
mogą być przerwane przez inny wątek. Może to prowadzić do błędnych liczników
— subtelnych błędów, które z kolei mogą prowadzić do wycieków pamięci lub
przedwczesnego usunięcia wartości. Potrzebujemy typu, który jest dokładnie
taki jak Rc<T>, ale który dokonuje zmian w liczniku referencji w sposób
bardzo bezpieczny dla wątków.
Atomowe zliczanie referencji za pomocą Arc<T>
Na szczęście Arc<T> jest typem podobnym do Rc<T>, który jest bezpieczny
w użyciu w sytuacjach współbieżnych. Litera a oznacza atomic, co oznacza,
że jest to typ atomowo zliczający referencje. Atomy to dodatkowy rodzaj
prymitywu współbieżności, którego nie będziemy szczegółowo omawiać: Więcej
szczegółów można znaleźć w dokumentacji biblioteki standardowej dla
std::sync::atomic. W tym momencie wystarczy wiedzieć,
że atomy działają jak typy prymitywne, ale są bezpieczne do współdzielenia
między wątkami.
Możesz się wtedy zastanawiać, dlaczego wszystkie typy prymitywne nie są
atomowe i dlaczego typy biblioteki standardowej nie są domyślnie
zimplementowane do używania Arc<T>. Powodem jest to, że bezpieczeństwo
wątkowe wiąże się z karą wydajnościową, którą chcesz ponieść tylko wtedy, gdy
rzeczywiście tego potrzebujesz. Jeśli wykonujesz operacje na wartościach
jednowątkowo, twój kod może działać szybciej, jeśli nie musi egzekwować
gwarancji zapewnianych przez atomy.
Wróćmy do naszego przykładu: Arc<T> i Rc<T> mają to samo API, więc
naprawiamy nasz program, zmieniając linię use, wywołanie new i wywołanie
clone. Kod w Listingu 16-15 ostatecznie skompiluje się i uruchomi.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Ten kod wypisze następujące:
Result: 10
Udało się! Policzyliśmy od 0 do 10, co może nie wydawać się zbyt imponujące,
ale wiele nas nauczyło o Mutex<T> i bezpieczeństwie wątkowym. Możesz również
wykorzystać strukturę tego programu do bardziej skomplikowanych operacji niż
samo zwiększanie licznika. Używając tej strategii, możesz podzielić obliczenia
na niezależne części, rozdzielić te części między wątki, a następnie użyć
Mutex<T>, aby każdy wątek aktualizował ostateczny wynik swoją częścią.
Zauważ, że jeśli wykonujesz proste operacje numeryczne, istnieją typy
prostsze niż Mutex<T> udostępniane przez moduł
std::sync::atomic biblioteki standardowej. Typy te
zapewniają bezpieczny, współbieżny, atomowy dostęp do typów prymitywnych.
Wybraliśmy użycie Mutex<T> z typem prymitywnym w tym przykładzie, abyśmy mogli
skupić się na tym, jak działa Mutex<T>.
Porównanie RefCell<T>/Rc<T> i Mutex<T>/Arc<T>
Być może zauważyłeś, że counter jest niemutowalny, ale mogliśmy uzyskać do
wartości w nim mutowalną referencję; oznacza to, że Mutex<T> zapewnia
mutowalność wewnętrzną, podobnie jak rodzina Cell. W ten sam sposób, w jaki
wykorzystaliśmy RefCell<T> w Rozdziale 15, aby umożliwić nam mutowanie
zawartości wewnątrz Rc<T>, używamy Mutex<T> do mutowania zawartości wewnątrz
Arc<T>.
Kolejny szczegół do odnotowania to to, że Rust nie jest w stanie ochronić Cię
przed wszystkimi rodzajami błędów logicznych, gdy używasz Mutex<T>. Przypomnij
sobie z Rozdziału 15, że użycie Rc<T> wiązało się z ryzykiem tworzenia cykli
referencji, gdzie dwie wartości Rc<T> odwołują się do siebie nawzajem,
powodując wycieki pamięci. Podobnie, Mutex<T> wiąże się z ryzykiem tworzenia
zakleszczeń. Dzieje się to, gdy operacja musi zablokować dwa zasoby, a dwa
wątki uzyskały po jednej blokadzie, powodując, że czekają na siebie nawzajem w
nieskończoność. Jeśli interesują Cię zakleszczenia, spróbuj stworzyć program
w Rust, który ma zakleszczenie; następnie zbadaj strategie łagodzenia
zakleszczeń dla muteksów w dowolnym języku i spróbuj je zaimplementować w Rust.
Dokumentacja API biblioteki standardowej dla Mutex<T> i MutexGuard oferuje
przydatne informacje.
Ukończymy ten rozdział, mówiąc o cechach Send i Sync oraz o tym, jak możemy
ich używać z niestandardowymi typami.
Rozszerzalna współbieżność dzięki cechom `Send` i `Sync`
Rozszerzalna współbieżność dzięki cechom Send i Sync
Co ciekawe, prawie każda funkcja współbieżności, o której do tej pory mówiliśmy w tym rozdziale, była częścią biblioteki standardowej, a nie języka. Twoje opcje obsługi współbieżności nie ograniczają się do języka ani biblioteki standardowej; możesz pisać własne funkcje współbieżności lub korzystać z tych napisanych przez innych.
Jednakże, wśród kluczowych koncepcji współbieżności, które są osadzone w języku,
a nie w bibliotece standardowej, znajdują się cechy znacznika std::marker
Send i Sync.
Przenoszenie własności między wątkami
Cecha znacznikowa Send wskazuje, że własność wartości typu implementującego
Send może być przenoszona między wątkami. Prawie każdy typ Rust
implementuje Send, ale istnieją pewne wyjątki, w tym Rc<T>: Nie może on
implementować Send, ponieważ gdybyś sklonował wartość Rc<T> i próbował
przenieść własność klonu do innego wątku, oba wątki mogłyby jednocześnie
zaktualizować licznik referencji. Z tego powodu Rc<T> jest zaimplementowany
do użytku w sytuacjach jednowątkowych, gdzie nie chcesz ponosić kary
wydajnościowej związanej z bezpieczeństwem wątków.
Dlatego system typów Rust i ograniczenia cech zapewniają, że nigdy nie możesz
przypadkowo wysłać wartości Rc<T> między wątkami w sposób niebezpieczny.
Kiedy próbowaliśmy to zrobić w Listingu 16-14, otrzymaliśmy błąd the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Kiedy zmieniliśmy na Arc<T>,
który implementuje Send, kod się skompilował.
Każdy typ składający się wyłącznie z typów Send jest automatycznie
oznaczany jako Send. Prawie wszystkie typy prymitywne są Send, poza
surowymi wskaźnikami, o których będziemy rozmawiać w Rozdziale 20.
Dostęp z wielu wątków
Cecha znacznikowa Sync wskazuje, że bezpieczne jest odwoływanie się do typu
implementującego Sync z wielu wątków. Innymi słowy, każdy typ T
implementuje Sync, jeśli &T (niemutowalna referencja do T) implementuje
Send, co oznacza, że referencja może być bezpiecznie wysłana do innego wątku.
Podobnie jak Send, wszystkie typy prymitywne implementują Sync, a typy
składające się wyłącznie z typów implementujących Sync również implementują
Sync.
Wskaźnik sprytny Rc<T> również nie implementuje Sync z tych samych powodów,
dla których nie implementuje Send. Typ RefCell<T> (o którym mówiliśmy w
Rozdziale 15) i rodzina powiązanych typów Cell<T> nie implementują Sync.
Implementacja sprawdzania pożyczeń, którą RefCell<T> wykonuje w czasie
wykonania, nie jest bezpieczna wątkowo. Wskaźnik sprytny Mutex<T> implementuje
Sync i może być używany do współdzielenia dostępu z wieloma wątkami, jak
widziałeś w sekcji „Współdzielony dostęp do Mutex<T>”.
Ręczna implementacja Send i Sync jest niebezpieczna
Ponieważ typy składające się wyłącznie z innych typów, które implementują
cechy Send i Sync, automatycznie implementują również Send i Sync, nie
musimy implementować tych cech ręcznie. Jako cechy znacznikowe, nie mają one
nawet żadnych metod do zaimplementowania. Są po prostu przydatne do
egzekwowania niezmienników związanych ze współbieżnością.
Ręczna implementacja tych cech wiąże się z użyciem niebezpiecznego kodu Rust.
O używaniu niebezpiecznego kodu Rust będziemy rozmawiać w Rozdziale 20;
na razie ważną informacją jest to, że budowanie nowych typów współbieżnych nie
składających się z części Send i Sync wymaga starannego przemyślenia w
c celu utrzymania gwarancji bezpieczeństwa. „The Rustonomicon”
zawiera więcej informacji na temat tych gwarancji i sposobów ich
podtrzymywania.
Podsumowanie
To nie jest ostatni raz, kiedy spotkasz się ze współbieżnością w tej książce: następny rozdział skupia się na programowaniu asynchronicznym, a projekt w Rozdziale 21 wykorzysta koncepcje z tego rozdziału w bardziej realistycznej sytuacji niż omówione tutaj mniejsze przykłady.
Jak wspomniano wcześniej, ponieważ niewiele z tego, jak Rust obsługuje współbieżność, jest częścią języka, wiele rozwiązań współbieżności jest implementowanych jako crate’y. Ewoluują one szybciej niż biblioteka standardowa, więc pamiętaj, aby szukać w Internecie aktualnych, najnowocześniejszych crate’ów do użycia w sytuacjach wielowątkowych.
Biblioteka standardowa Rust zapewnia kanały do przekazywania wiadomości oraz
typy wskaźników sprytnych, takie jak Mutex<T> i Arc<T>, które są bezpieczne
w użyciu w kontekstach współbieżnych. System typów i sprawdzający pożyczki
zapewniają, że kod używający tych rozwiązań nie doprowadzi do wyścigów danych
oraz do nieważnych referencji. Gdy kod się skompiluje, możesz być pewien, że
będzie działał na wielu wątkach bez trudnych do znalezienia błędów, typowych
dla innych języków. Programowanie współbieżne nie jest już pojęciem, którego
należy się obawiać: idź i spraw, aby twoje programy były współbieżne,
bez strachu!
Podstawy programowania asynchronicznego: Async, Await, Futures i Streams
Wiele operacji, o które prosimy komputer, może zająć trochę czasu. Dobrze by było, gdybyśmy mogli robić coś innego, czekając na zakończenie tych długotrwałych procesów. Nowoczesne komputery oferują dwie techniki pracy nad więcej niż jedną operacją jednocześnie: równoległość i współbieżność. Logika naszych programów jest jednak pisana w sposób głównie liniowy. Chcielibyśmy móc określać operacje, które program powinien wykonać, oraz punkty, w których funkcja mogłaby się zatrzymać, a jakaś inna część programu mogłaby działać zamiast niej, bez konieczności wcześniejszego precyzowania dokładnej kolejności i sposobu, w jaki każdy fragment kodu powinien działać. Programowanie asynchroniczne to abstrakcja, która pozwala nam wyrażać kod w terminach potencjalnych punktów pauzy i ostatecznych wyników, która zajmuje się szczegółami koordynacji za nas.
Ten rozdział opiera się na użyciu wątków do równoległości i współbieżności z
Rozdziału 16, wprowadzając alternatywne podejście do pisania kodu: futures i
streams Rust oraz składnię async i await, które pozwalają nam wyrazić, jak
operacje mogą być asynchroniczne, oraz crate’y zewnętrzne, które
implementują środowiska uruchomieniowe asynchroniczne: kod, który zarządza i
koordynuje wykonywanie operacji asynchronicznych.
Rozważmy przykład. Powiedzmy, że eksportujesz wideo, które stworzyłeś z rodzinnej uroczystości – operacja, która może trwać od kilku minut do kilku godzin. Eksport wideo wykorzysta tyle mocy CPU i GPU, ile tylko może. Gdybyś miał tylko jeden rdzeń CPU, a system operacyjny nie wstrzymywałby tego eksportu do momentu jego zakończenia – to znaczy, gdyby wykonywał eksport synchronicznie – nie mógłbyś robić niczego innego na swoim komputerze, podczas gdy to zadanie byłoby uruchomione. Byłoby to dość frustrujące doświadczenie. Na szczęście system operacyjny twojego komputera może, i robi to, niewidocznie przerywać eksport wystarczająco często, abyś mógł jednocześnie wykonywać inną pracę.
Teraz powiedzmy, że pobierasz wideo udostępnione przez kogoś innego, co również może trochę potrwać, ale nie zajmuje tyle czasu procesora. W tym przypadku procesor musi czekać na dane z sieci. Chociaż możesz zacząć odczytywać dane, gdy zaczną napływać, może minąć trochę czasu, zanim wszystkie się pojawią. Nawet gdy wszystkie dane są już dostępne, jeśli wideo jest dość duże, załadowanie całości może zająć co najmniej sekundę lub dwie. Może to nie brzmieć jak wiele, ale to bardzo długo dla nowoczesnego procesora, który potrafi wykonywać miliardy operacji na sekundę. Ponownie, system operacyjny niewidocznie przerwie Twój program, aby umożliwić procesorowi wykonywanie innej pracy, podczas gdy czeka na zakończenie wywołania sieciowego.
Eksport wideo jest przykładem operacji CPU-bound (ograniczonej przez CPU) lub compute-bound (ograniczonej przez obliczenia). Jest ograniczony przez potencjalną szybkość przetwarzania danych przez komputer w obrębie CPU lub GPU oraz przez to, ile z tej szybkości może poświęcić na operację. Pobieranie wideo jest przykładem operacji I/O-bound (ograniczonej przez wejście/wyjście), ponieważ jest ograniczone szybkością wejścia i wyjścia komputera; może działać tylko tak szybko, jak dane mogą być przesyłane przez sieć.
W obu tych przykładach niewidoczne przerwania systemu operacyjnego zapewniają pewną formę współbieżności. Współbieżność ta ma jednak miejsce tylko na poziomie całego programu: system operacyjny przerywa jeden program, aby inne programy mogły wykonywać swoją pracę. W wielu przypadkach, ponieważ rozumiemy nasze programy na znacznie bardziej szczegółowym poziomie niż system operacyjny, możemy dostrzec możliwości współbieżności, których system operacyjny nie jest w stanie zobaczyć.
Na przykład, jeśli budujemy narzędzie do zarządzania pobieraniem plików, powinniśmy móc napisać nasz program tak, aby rozpoczęcie jednego pobierania nie blokowało interfejsu użytkownika, a użytkownicy mogli rozpocząć wiele pobierań jednocześnie. Wiele API systemów operacyjnych do interakcji z siecią jest jednak blokujących; to znaczy, blokują one postęp programu, dopóki przetwarzane dane nie będą całkowicie gotowe.
Uwaga: Tak działa większość wywołań funkcji, jeśli się nad tym zastanowisz. Jednak termin blokujący jest zazwyczaj zarezerwowany dla wywołań funkcji, które współdziałają z plikami, siecią lub innymi zasobami na komputerze, ponieważ to właśnie w tych przypadkach indywidualny program skorzystałby na tym, aby operacja była nie-blokująca.
Moglibyśmy uniknąć blokowania naszego głównego wątku, tworząc dedykowany wątek do pobierania każdego pliku. Jednak narzut zasobów systemowych wykorzystywanych przez te wątki w końcu stałby się problemem. Byłoby lepiej, gdyby wywołanie w ogóle nie blokowało, a zamiast tego moglibyśmy zdefiniować wiele zadań, które chcielibyśmy, aby nasz program wykonał, i pozwolić środowisku uruchomieniowemu wybrać najlepszą kolejność i sposób ich wykonania.
Właśnie to zapewnia nam abstrakcja async (skrót od asynchronous) w Rust. W tym rozdziale dowiesz się wszystkiego o async, omawiając następujące tematy:
- Jak używać składni
asynciawaitRust oraz wykonywać funkcje asynchroniczne w środowisku uruchomieniowym - Jak używać modelu async do rozwiązywania niektórych z tych samych problemów, które rozważaliśmy w Rozdziale 16
- Jak wielowątkowość i async zapewniają uzupełniające się rozwiązania, które można łączyć w wielu przypadkach
Zanim jednak zobaczymy, jak async działa w praktyce, musimy zrobić krótki objazd, aby omówić różnice między równoległością a współbieżnością.
Równoległość i współbieżność
Do tej pory traktowaliśmy równoległość i współbieżność jako w większości wymienne. Teraz musimy je precyzyjniej rozróżnić, ponieważ różnice pojawią się, gdy zaczniemy pracować.
Rozważmy różne sposoby, w jakie zespół mógłby podzielić pracę nad projektem o programowaniu. Można by przydzielić jednemu członkowi wiele zadań, każdemu członkowi jedno zadanie, lub zastosować połączenie obu podejść.
Kiedy jednostka pracuje nad kilkoma różnymi zadaniami, zanim którekolwiek z nich zostanie ukończone, jest to współbieżność. Jeden ze sposobów implementacji współbieżności jest podobny do posiadania dwóch różnych projektów pobranych na komputerze, a kiedy się znudzisz lub utkniesz na jednym projekcie, przełączasz się na drugi. Jesteś tylko jedną osobą, więc nie możesz poczynić postępów w obu zadaniach dokładnie w tym samym czasie, ale możesz wielozadaniowo, robiąc postępy w jednym zadaniu naraz, przełączając się między nimi (patrz Rysunek 17-1).

Kiedy zespół dzieli grupę zadań, tak że każdy członek bierze jedno zadanie i pracuje nad nim samodzielnie, jest to równoległość. Każda osoba w zespole może robić postępy dokładnie w tym samym czasie (patrz Rysunek 17-2).

W obu tych przepływach pracy, możesz musieć koordynować działania między różnymi zadaniami. Może myślałeś, że zadanie przydzielone jednej osobie było całkowicie niezależne od pracy innych, ale w rzeczywistości wymaga ono od innej osoby w zespole najpierw zakończenia swojego zadania. Część pracy mogła być wykonana równolegle, ale część z nich była w rzeczywistości sekwencyjna: mogła dziać się tylko w serii, jedno zadanie po drugim, jak na Rysunku 17-3.

Podobnie, możesz zdać sobie sprawę, że jedno z twoich zadań zależy od innego z twoich zadań. Wtedy twoja współbieżna praca również stała się szeregowa.
Równoległość i współbieżność mogą się również ze sobą krzyżować. Jeśli dowiesz się, że kolega utknął, dopóki nie skończysz jednego ze swoich zadań, prawdopodobnie skupisz wszystkie swoje wysiłki na tym zadaniu, aby „odblokować” swojego kolegę. Ty i twój współpracownik nie jesteście już w stanie pracować równolegle, a także nie jesteście już w stanie pracować współbieżnie nad własnymi zadaniami.
Ta sama podstawowa dynamika wchodzi w grę w oprogramowaniu i sprzęcie. Na maszynie z pojedynczym rdzeniem CPU, CPU może wykonywać tylko jedną operację na raz, ale nadal może działać współbieżnie. Używając narzędzi takich jak wątki, procesy i async, komputer może wstrzymać jedną aktywność i przełączyć się na inne, zanim ostatecznie powróci do tej pierwszej aktywności. Na maszynie z wieloma rdzeniami CPU, może również wykonywać pracę równolegle. Jeden rdzeń może wykonywać jedno zadanie, podczas gdy inny rdzeń wykonuje zupełnie niepowiązane zadanie, a te operacje faktycznie dzieją się w tym samym czasie.
Uruchamianie kodu async w Rust zazwyczaj odbywa się współbieżnie. W zależności od sprzętu, systemu operacyjnego i używanego środowiska asynchronicznego (więcej o środowiskach asynchronicznych wkrótce), ta współbieżność może również wykorzystywać równoległość pod maską.
Teraz zagłębmy się w to, jak faktycznie działa programowanie asynchroniczne w Rust.
Futures i składnia `async`
Futures i składnia async
Kluczowymi elementami programowania asynchronicznego w Rust są futures oraz
słowa kluczowe async i await Rust.
Future to wartość, która może nie być gotowa teraz, ale stanie się gotowa w
pewnym momencie w przyszłości. (Ta sama koncepcja pojawia się w wielu językach,
czasami pod innymi nazwami, takimi jak task lub promise.) Rust zapewnia
cechę Future jako element konstrukcyjny, dzięki czemu różne operacje
asynchroniczne mogą być implementowane z różnymi strukturami danych, ale z
jednolitym interfejsem. W Rust futures to typy, które implementują cechę
Future. Każda przyszłość przechowuje własne informacje o postępie, który
został osiągnięty, i co oznacza „gotowy”.
Możesz zastosować słowo kluczowe async do bloków i funkcji, aby określić,
że mogą być one przerywane i wznawiane. Wewnątrz bloku async lub funkcji async,
możesz użyć słowa kluczowego await, aby oczekiwać na przyszłość (czyli
poczekać, aż stanie się gotowa). Każdy punkt, w którym oczekujesz na przyszłość
w bloku async lub funkcji async, jest potencjalnym miejscem, w którym ten blok
lub funkcja może się zatrzymać i wznowić. Proces sprawdzania z przyszłością, czy
jej wartość jest już dostępna, nazywa się polling (odpytywaniem).
Niektóre inne języki, takie jak C# i JavaScript, również używają słów
kluczowych async i await do programowania asynchronicznego. Jeśli znasz te
języki, możesz zauważyć pewne znaczące różnice w sposobie obsługi składni przez
Rust. Ma to dobry powód, jak zobaczymy!
Pisząc kod async w Rust, używamy słów kluczowych async i await przez większość
czasu. Rust kompiluje je do równoważnego kodu używającego cechy Future,
podobnie jak kompiluje pętle for do równoważnego kodu używającego cechy
Iterator. Ponieważ Rust zapewnia cechę Future, możesz ją również
zaimplementować dla własnych typów danych, gdy tego potrzebujesz. Wiele funkcji,
które zobaczymy w tym rozdziale, zwraca typy z własnymi implementacjami
Future. Wróćmy do definicji cechy na końcu rozdziału i zagłębmy się w to, jak
działa, ale to wystarczy, abyśmy mogli kontynuować.
Wszystko to może wydawać się nieco abstrakcyjne, więc napiszmy nasz pierwszy program asynchroniczny: mały scraper internetowy. Przekażemy dwa adresy URL z wiersza poleceń, pobierzemy je oba współbieżnie i zwrócimy wynik tego, który zakończy się jako pierwszy. Ten przykład będzie zawierał sporo nowej składni, ale nie martw się – wyjaśnimy wszystko, co musisz wiedzieć, w trakcie.
Nasz pierwszy program asynchroniczny
Aby skupić się w tym rozdziale na nauce async, a nie na żonglowaniu częściami
ekosystemu, stworzyliśmy crate trpl (trpl to skrót od „The Rust Programming
Language”). Reeksportuje on wszystkie typy, cechy i funkcje, których będziesz
potrzebować, głównie z crate’ów futures i
tokio. Crate futures jest oficjalnym miejscem
eksperymentów Rust dla kodu async i to właśnie tam pierwotnie zaprojektowano
cechę Future. Tokio jest obecnie najczęściej używanym środowiskiem
asynchronicznym w Rust, zwłaszcza w aplikacjach internetowych. Istnieją inne
dobre środowiska uruchomieniowe, które mogą być bardziej odpowiednie dla Twoich
potrzeb. Używamy crate’a tokio pod maską dla trpl, ponieważ jest dobrze
przetestowany i szeroko stosowany.
W niektórych przypadkach trpl również zmienia nazwy lub opakowuje oryginalne
API, abyś skupił się na szczegółach istotnych dla tego rozdziału. Jeśli chcesz
zrozumieć, co robi ten crate, zachęcamy do zapoznania się z jego kodem
źródłowym. Będziesz mógł zobaczyć, z którego crate’a pochodzi
każdy reeksport, a my zostawiliśmy obszerne komentarze wyjaśniające, co robi
crate.
Stwórzmy nowy projekt binarny o nazwie hello-async i dodajmy crate trpl
jako zależność:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Teraz możemy użyć różnych elementów dostarczonych przez trpl do napisania
naszego pierwszego programu asynchronicznego. Zbudujemy małe narzędzie
wiersza poleceń, które pobierze dwie strony internetowe, wyciągnie z każdej z
nich element <title> i wypisze tytuł tej strony, która zakończy cały proces
pierwsza.
Definiowanie funkcji page_title
Zacznijmy od napisania funkcji, która przyjmuje jeden URL strony jako parametr,
wykonuje do niego żądanie i zwraca tekst elementu <title> (patrz Listing 17-1).
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Najpierw definiujemy funkcję o nazwie page_title i oznaczamy ją słowem
kluczowym async. Następnie używamy funkcji trpl::get, aby pobrać dowolny
przekazany URL i dodajemy słowo kluczowe await, aby oczekiwać na
odpowiedź. Aby uzyskać tekst response, wywołujemy jego metodę text i
ponownie oczekujemy na nią za pomocą słowa kluczowego await. Oba te kroki
są asynchroniczne. Dla funkcji get musimy poczekać, aż serwer odeśle
pierwszą część swojej odpowiedzi, która będzie zawierała nagłówki HTTP,
ciasteczka itd. i może być dostarczana osobno od treści odpowiedzi. Zwłaszcza
jeśli treść jest bardzo duża, jej dotarcie może zająć trochę czasu. Ponieważ
musimy poczekać na całość odpowiedzi, metoda text również jest asynchroniczna.
Musimy jawnie oczekiwać na obie te futures, ponieważ futures w Rust są
leniwymi: nie robią nic, dopóki nie poprosisz ich o to słowem kluczowym
await. (W rzeczywistości Rust wyświetli ostrzeżenie kompilatora, jeśli nie
użyjesz future.) To może przypominać dyskusję o iteratorach w sekcji
„Przetwarzanie sekwencji elementów za pomocą iteratorów” w Rozdziale 13. Iteratory nic nie robią, dopóki nie wywołasz ich
metody next – bezpośrednio lub za pomocą pętli for lub metod takich jak
map, które używają next pod maską. Podobnie, futures nic nie robią, dopóki
nie poprosisz ich o to jawnie. Ta leniwość pozwala Rustowi uniknąć
uruchamiania kodu async, dopóki nie jest on faktycznie potrzebny.
Uwaga: Różni się to od zachowania, które widzieliśmy podczas używania
thread::spawnw sekcji „Tworzenie nowego wątku za pomocą spawn” w Rozdziale 16, gdzie domknięcie, które przekazaliśmy do innego wątku, zaczęło działać natychmiast. Różni się to również od podejścia wielu innych języków do async. Ale jest to ważne, aby Rust mógł zapewnić swoje gwarancje wydajności, tak jak w przypadku iteratorów.
Gdy mamy response_text, możemy ją przetworzyć na instancję typu Html za
pomocą Html::parse. Zamiast surowego ciągu znaków, mamy teraz typ danych,
którego możemy użyć do pracy z HTML-em jako bogatszą strukturą danych. W
szczególności, możemy użyć metody select_first do znalezienia pierwszej
instancji danego selektora CSS. Przekazując ciąg "title", otrzymamy pierwszy
element <title> w dokumencie, jeśli taki istnieje. Ponieważ może nie być
żadnego pasującego elementu, select_first zwraca Option<ElementRef>.
Na koniec używamy metody Option::map, która pozwala nam pracować z elementem
w Option, jeśli jest obecny, i nic nie robić, jeśli go nie ma. (Moglibyśmy
też użyć tutaj wyrażenia match, ale map jest bardziej idiomatyczne.) W treści
funkcji, którą przekazujemy do map, wywołujemy inner_html na title, aby
pobrać jego zawartość, która jest String. Po wszystkim mamy
Option<String>.
Zauważ, że słowo kluczowe await w Rust znajduje się po wyrażeniu, na które
oczekujesz, a nie przed nim. To znaczy, jest to słowo kluczowe postfixowe.
Może się to różnić od tego, do czego jesteś przyzwyczajony, jeśli używałeś
async w innych językach, ale w Rust sprawia, że łańcuchy metod są znacznie
przyjemniejsze w pracy. W rezultacie, mogliśmy zmienić ciało page_title, aby
połączyć wywołania funkcji trpl::get i text za pomocą await między nimi,
jak pokazano w Listingu 17-2.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}I w ten sposób pomyślnie napisaliśmy naszą pierwszą funkcję asynchroniczną!
Zanim dodamy kod w main, aby ją wywołać, porozmawiajmy trochę więcej o tym,
co napisaliśmy i co to oznacza.
Kiedy Rust widzi blok oznaczony słowem kluczowym async, kompiluje go do
unikalnego, anonimowego typu danych, który implementuje cechę Future. Kiedy
Rust widzi funkcję oznaczoną async, kompiluje ją do funkcji nieasync,
której ciało jest blokiem async. Typ zwracany przez funkcję async jest typem
anonimowego typu danych, który kompilator tworzy dla tego bloku async.
W związku z tym, pisanie async fn jest równoważne pisaniu funkcji,
która zwraca future typu zwracanego. Dla kompilatora, definicja funkcji,
taka jak async fn page_title w Listingu 17-1, jest z grubsza równoważna
funkcji nieasync zdefiniowanej w ten sposób:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn page_title(url: &str) -> impl Future<Output = Option<String>> {
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
}Przejdźmy przez każdą część przekształconej wersji:
- Używa składni
impl Trait, którą omówiliśmy w Rozdziale 10 w sekcji „Cechy jako parametry”. - Zwrócona wartość implementuje cechę
Futureze skojarzonym typemOutput. Zauważ, że typOutputtoOption<String>, czyli ten sam typ, co oryginalny typ zwracany przez wersjęasync fnpage_title. - Cały kod wywołany w treści oryginalnej funkcji jest opakowany w blok
async move. Pamiętaj, że bloki są wyrażeniami. Cały ten blok jest wyrażeniem zwracanym z funkcji. - Ten blok async produkuje wartość typu
Option<String>, jak właśnie opisano. Ta wartość odpowiada typowiOutputw typie zwracanym. Jest to tak samo jak inne bloki, które widziałeś. - Nowe ciało funkcji to blok
async moveze względu na sposób użycia parametruurl. (Oasynckontraasync movebędziemy rozmawiać znacznie więcej później w rozdziale.)
Teraz możemy wywołać page_title w main.
Wykonanie funkcji async w środowisku uruchomieniowym
Aby zacząć, pobierzemy tytuł dla pojedynczej strony, pokazany w Listingu 17-3. Niestety, ten kod jeszcze się nie skompiluje.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Postępujemy zgodnie z tym samym wzorcem, którego użyliśmy do pobierania
argumentów wiersza poleceń w sekcji „Akceptowanie argumentów wiersza
poleceń” w Rozdziale 12. Następnie przekazujemy
argument URL do page_title i czekamy na wynik. Ponieważ wartość
produkowana przez future jest Option<String>, używamy wyrażenia match, aby
wypisać różne komunikaty w zależności od tego, czy strona miała element
<title>.
Jedynym miejscem, w którym możemy użyć słowa kluczowego await, są funkcje
lub bloki async, a Rust nie pozwoli nam oznaczyć specjalnej funkcji main jako
async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
Powodem, dla którego main nie może być oznaczona jako async, jest to, że
kod asynchroniczny potrzebuje środowiska uruchomieniowego (runtime): crate’a
Rust, który zarządza szczegółami wykonywania kodu asynchronicznego. Funkcja
main programu może zainicjalizować środowisko uruchomieniowe, ale sama nie
jest środowiskiem uruchomieniowym. (Więcej o tym, dlaczego tak jest, dowiemy
się za chwilę.) Każdy program Rust, który wykonuje kod asynchroniczny, ma
przynajmniej jedno miejsce, w którym konfiguruje środowisko uruchomieniowe,
które wykonuje futures.
Większość języków obsługujących async dostarcza środowisko uruchomieniowe, ale Rust tego nie robi. Zamiast tego dostępnych jest wiele różnych środowisk uruchomieniowych async, z których każde dokonuje różnych kompromisów, odpowiednich dla docelowego przypadku użycia. Na przykład, wydajny serwer webowy z wieloma rdzeniami CPU i dużą ilością pamięci RAM ma bardzo różne potrzeby niż mikrokontroler z pojedynczym rdzeniem, małą ilością pamięci RAM i brakiem możliwości alokacji na stercie. Crates, które dostarczają te środowiska uruchomieniowe, często dostarczają również asynchroniczne wersje typowych funkcji, takich jak wejście/wyjście plików lub sieci.
Tutaj i przez resztę tego rozdziału będziemy używać funkcji block_on z crate’a
trpl, która przyjmuje przyszłość jako argument i blokuje bieżący wątek,
dopóki ta przyszłość nie zostanie ukończona. Pod maską, wywołanie block_on
konfiguruje środowisko uruchomieniowe za pomocą crate’a tokio, które jest
używane do uruchamiania przekazanej przyszłości (zachowanie trpl::block_on
jest podobne do funkcji block_on innych crate’ów środowiskowych).
Gdy przyszłość zostanie ukończona, block_on zwraca wartość, którą przyszłość
wyprodukowała.
Moglibyśmy przekazać przyszłość zwróconą przez page_title bezpośrednio do
block_on i, po jej zakończeniu, dopasować wynikowy Option<String>, jak to
próbowaliśmy zrobić w Listingu 17-3. Jednak w większości przykładów w rozdziale
(i w większości kodu async w prawdziwym świecie) będziemy wykonywać więcej niż
jedno wywołanie funkcji async, więc zamiast tego przekażemy blok async i
jawnie poczekamy na wynik wywołania page_title, jak w Listingu 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Po uruchomieniu tego kodu otrzymujemy zachowanie, którego początkowo się spodziewaliśmy:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Uff – w końcu mamy działający kod async! Ale zanim dodamy kod do wyścigów dwóch witryn ze sobą, poświęćmy chwilę, aby powrócić do tego, jak działają futures.
Każdy punkt oczekiwania – to znaczy każde miejsce, w którym kod używa słowa
kluczowego await – reprezentuje miejsce, w którym kontrola zostaje
przekazana z powrotem do środowiska uruchomieniowego. Aby to zadziałało, Rust
musi śledzić stan zaangażowany w blok async, tak aby środowisko uruchomieniowe
mogło rozpocząć inną pracę, a następnie powrócić, gdy będzie gotowe, aby
ponownie spróbować posunąć pierwszą pracę. Jest to niewidoczna maszyna stanów,
tak jakbyś napisał enum w ten sposób, aby zapisać bieżący stan w każdym punkcie
oczekiwania:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
}Ręczne pisanie kodu do przechodzenia między poszczególnymi stanami byłoby udręką i podatne na błędy, zwłaszcza gdy trzeba później dodać więcej funkcjonalności i stanów do kodu. Na szczęście kompilator Rust automatycznie tworzy i zarządza strukturami danych maszyny stanów dla kodu async. Normalne zasady pożyczania i własności dotyczące struktur danych nadal obowiązują, a co najważniejsze, kompilator zajmuje się również ich sprawdzaniem i dostarcza przydatne komunikaty o błędach. Kilka z nich omówimy później w tym rozdziale.
Ostatecznie, coś musi wykonać tę maszynę stanów, a tym czymś jest środowisko uruchomieniowe. (Dlatego możesz natknąć się na wzmianki o executorach, szukając informacji o środowiskach uruchomieniowych: executor to część środowiska uruchomieniowego odpowiedzialna za wykonywanie kodu async.)
Teraz widzisz, dlaczego kompilator powstrzymał nas przed uczynieniem main
samego w sobie funkcją asynchroniczną w Listingu 17-3. Gdyby main było
funkcją asynchroniczną, coś innego musiałoby zarządzać maszyną stanów dla
dowolnej przyszłości, którą main zwróciło, ale main jest punktem
początkowym programu! Zamiast tego wywołaliśmy funkcję trpl::block_on w
main, aby skonfigurować środowisko uruchomieniowe i uruchomić przyszłość
zwracaną przez blok async, dopóki nie zostanie ona ukończona.
Uwaga: Niektóre środowiska uruchomieniowe zapewniają makra, dzięki czemu możesz pisać funkcję
mainasync. Te makra przepisująasync fn main() { ... }na zwykłą funkcjęfn main, która robi to samo, co zrobiliśmy ręcznie w Listingu 17-4: wywołuje funkcję, która uruchamia przyszłość do końca w sposób, w jaki to robitrpl::block_on.
Teraz połączmy te elementy i zobaczmy, jak możemy pisać kod współbieżny.
Wyścig dwóch adresów URL ze sobą współbieżnie
W Listingu 17-5 wywołujemy page_title z dwoma różnymi adresami URL
przekazanymi z wiersza poleceń i ścigamy je, wybierając tę future, która
zakończy się jako pierwsza.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}Zaczynamy od wywołania page_title dla każdego z adresów URL podanych przez
użytkownika. Wynikowe futures zapisujemy jako title_fut_1 i title_fut_2.
Pamiętaj, że te futures jeszcze nic nie robią, ponieważ są leniwe i jeszcze
na nie nie czekaliśmy. Następnie przekazujemy futures do trpl::select, który
zwraca wartość wskazującą, która z przekazanych do niego futures zakończyła
działanie jako pierwsza.
Uwaga: Pod maską,
trpl::selectjest zbudowany na bardziej ogólnej funkcjiselectzdefiniowanej w crate’ciefutures. Funkcjaselectz crate’afuturespotrafi wiele rzeczy, których funkcjatrpl::selectnie potrafi, ale ma też pewne dodatkowe złożoności, które na razie możemy pominąć.
Każda przyszłość może legalnie „wygrać”, więc zwracanie Result nie ma sensu.
Zamiast tego, trpl::select zwraca typ, którego wcześniej nie widzieliśmy,
trpl::Either. Typ Either jest nieco podobny do Result w tym, że ma dwa
przypadki. Jednak w przeciwieństwie do Result, w Either nie ma pojęcia
czynnika sukcesu ani porażki. Zamiast tego, używa Left i Right, aby wskazać
„jedno lub drugie”:
#![allow(unused)]
fn main() {
enum Either<A, B> {
Left(A),
Right(B),
}
}Funkcja select zwraca Left z wynikiem tej future, jeśli pierwszy argument
wygra, i Right z wynikiem future drugiego argumentu, jeśli ta wygra.
Odpowiada to kolejności, w jakiej argumenty pojawiają się podczas wywoływania
funkcji: pierwszy argument jest na lewo od drugiego argumentu.
Aktualizujemy również page_title, aby zwracała ten sam URL, który został
przekazany. W ten sposób, jeśli strona, która zwróci się jako pierwsza, nie ma
<title>, którą możemy rozwiązać, nadal możemy wypisać sensowny komunikat.
Po uzyskaniu tych informacji, kończymy aktualizację naszego wyjścia println!,
aby wskazać zarówno to, który URL zakończył się jako pierwszy, jak i jaki,
jeśli w ogóle, jest <title> dla strony internetowej pod tym URL-em.
Zbudowałeś teraz mały, działający scraper internetowy! Wybierz kilka adresów URL
i uruchom narzędzie wiersza poleceń. Możesz odkryć, że niektóre witryny są
konsekwentnie szybsze od innych, podczas gdy w innych przypadkach szybsza
witryna zmienia się z uruchomienia na uruchomienie. Co ważniejsze, nauczyłeś
się podstaw pracy z futures, więc teraz możemy zagłębić się w to, co możemy
zrobić z async.
Stosowanie współbieżności z `async`
Stosowanie współbieżności z async
W tej sekcji zastosujemy async do niektórych z tych samych wyzwań współbieżności, które rozwiązaliśmy za pomocą wątków w Rozdziale 16. Ponieważ wiele kluczowych idei zostało tam już omówionych, w tej sekcji skupimy się na różnicach między wątkami a futures.
W wielu przypadkach API do pracy z współbieżnością przy użyciu async są bardzo podobne do tych do pracy z wątkami. W innych przypadkach są one zupełnie różne. Nawet gdy API wyglądają podobnie między wątkami a async, często mają różne zachowania — i prawie zawsze mają różne charakterystyki wydajności.
Tworzenie nowego zadania za pomocą spawn_task
Pierwszą operacją, którą zajęliśmy się w sekcji „Tworzenie nowego wątku za
pomocą spawn” w Rozdziale 16, było zliczanie
na dwóch oddzielnych wątkach. Zróbmy to samo, używając async. Crate trpl
dostarcza funkcję spawn_task, która wygląda bardzo podobnie do API
thread::spawn, oraz funkcję sleep, która jest asynchroniczną wersją API
thread::sleep. Możemy ich użyć razem do zaimplementowania przykładu
zliczania, jak pokazano w Listingu 17-6.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}Jako punkt wyjścia, konfigurujemy naszą funkcję main z trpl::block_on,
tak aby nasza funkcja najwyższego poziomu mogła być asynchroniczna.
Uwaga: Od tego momentu w rozdziale, każdy przykład będzie zawierał ten sam kod opakowujący z
trpl::block_onwmain, więc często będziemy go pomijać, tak jak to robimy zmain. Pamiętaj, aby uwzględnić go w swoim kodzie!
Następnie piszemy dwie pętle w tym bloku, każda zawierająca wywołanie
trpl::sleep, które czeka pół sekundy (500 milisekund) przed wysłaniem
kolejnej wiadomości. Jedną pętlę umieszczamy w ciele trpl::spawn_task, a drugą
w pętli for najwyższego poziomu. Dodajemy również await po wywołaniach
sleep.
Ten kod zachowuje się podobnie do implementacji opartej na wątkach – w tym także to, że możesz zobaczyć wiadomości pojawiające się w innej kolejności w własnym terminalu, gdy go uruchomisz:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
Ta wersja zatrzymuje się, gdy tylko zakończy się pętla for w ciele głównego
bloku async, ponieważ zadanie uruchomione przez spawn_task zostaje
wyłączone, gdy funkcja main się kończy. Jeśli chcesz, aby działało do końca
zadania, będziesz musiał użyć uchwytu join do oczekiwania na zakończenie
pierwszego zadania. W przypadku wątków, użyliśmy metody join do „blokowania”,
dopóki wątek nie zakończył działania. W Listingu 17-7 możemy użyć await do
zrobienia tego samego, ponieważ sam uchwyt zadania jest future. Jego typ
Output to Result, więc również go rozpakowujemy po oczekiwaniu na niego.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
handle.await.unwrap();
});
}Ta zaktualizowana wersja działa, dopóki obie pętle się nie zakończą:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Jak dotąd, wydaje się, że async i wątki dają nam podobne wyniki, tylko z
inną składnią: używając await zamiast wywoływania join na uchwycie join,
oraz oczekując na wywołania sleep.
Większą różnicą jest to, że nie musieliśmy tworzyć kolejnego wątku systemu
operacyjnego, aby to zrobić. W rzeczywistości, nie musimy nawet tworzyć tutaj
żadnego zadania. Ponieważ bloki async kompilują się do anonimowych futures,
możemy umieścić każdą pętlę w bloku async i pozwolić środowisku uruchomieniowemu
uruchomić je obie do końca za pomocą funkcji trpl::join.
W sekcji „Czekanie na zakończenie wszystkich wątków” w Rozdziale 16 pokazaliśmy, jak używać metody join na typie
JoinHandle zwracanym po wywołaniu std::thread::spawn. Funkcja trpl::join
jest podobna, ale dla futures. Kiedy podasz jej dwie futures, produkuje jedną
nową future, której wynikiem jest krotka zawierająca wyniki każdej future,
którą przekazałeś, gdy obie zakończą działanie. Tak więc, w Listingu 17-8
używamy trpl::join, aby poczekać na zakończenie zarówno fut1, jak i fut2.
Nie oczekujemy na fut1 i fut2, ale zamiast tego na nową future
produkowaną przez trpl::join. Ignorujemy wynik, ponieważ jest to tylko krotka
zawierająca dwie wartości jednostkowe.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}Po uruchomieniu widzimy, że obie futures działają do końca:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Teraz zobaczysz dokładnie tę samą kolejność za każdym razem, co jest bardzo
różne od tego, co widzieliśmy w przypadku wątków i trpl::spawn_task w Listingu
17-7. Dzieje się tak, ponieważ funkcja trpl::join jest sprawiedliwa,
oznacza to, że sprawdza każdą future tak samo często, naprzemiennie między nimi,
i nigdy nie pozwala jednej wyprzedzić drugiej, jeśli ta druga jest gotowa.
W przypadku wątków, system operacyjny decyduje, który wątek sprawdzić i jak
długo pozwolić mu działać. W przypadku async Rust, środowisko uruchomieniowe
decyduje, które zadanie sprawdzić. (W praktyce, szczegóły stają się
skomplikowane, ponieważ środowisko uruchomieniowe async może wykorzystywać
wątki systemu operacyjnego pod maską jako część sposobu zarządzania
współbieżnością, więc zagwarantowanie sprawiedliwości może być bardziej
pracochłonne dla środowiska uruchomieniowego – ale nadal jest to możliwe!)
Środowiska uruchomieniowe nie muszą gwarantować sprawiedliwości dla żadnej
danej operacji i często oferują różne API, aby umożliwić wybór, czy chcesz
sprawiedliwości, czy nie.
Wypróbuj niektóre z tych wariacji oczekiwania na futures i zobacz, co robią:
- Usuń blok async wokół jednej lub obu pętli.
- Oczekuj na każdy blok async natychmiast po jego zdefiniowaniu.
- Opakuj tylko pierwszą pętlę w blok async i oczekuj na wynikową future po ciele drugiej pętli.
Dodatkowym wyzwaniem jest sprawdzenie, czy potrafisz przewidzieć, jaki będzie wynik w każdym przypadku przed uruchomieniem kodu!
Przesyłanie danych między dwoma zadaniami za pomocą przekazywania wiadomości
Współdzielenie danych między futures również będzie znajome: ponownie użyjemy przekazywania wiadomości, ale tym razem z asynchronicznymi wersjami typów i funkcji. Obierzemy nieco inną ścieżkę niż w sekcji „Przesyłanie danych między wątkami za pomocą przekazywania wiadomości” w Rozdziale 16, aby zilustrować niektóre kluczowe różnice między współbieżnością opartą na wątkach a współbieżnością opartą na futures. W Listingu 17-9 zaczniemy od pojedynczego bloku async – nie uruchamiając oddzielnego zadania, tak jak uruchomiliśmy oddzielny wątek.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let val = String::from("hi");
tx.send(val).unwrap();
let received = rx.recv().await.unwrap();
println!("received '{received}'");
});
}Tutaj używamy trpl::channel, asynchronicznej wersji API kanału typu
wiele-producentów, jeden-konsument, którego użyliśmy z wątkami w Rozdziale 16.
Asynchroniczna wersja API różni się tylko nieco od wersji opartej na wątkach:
używa mutowalnego, a nie niemutowalnego odbiornika rx, a jego metoda recv
produkuje future, na którą musimy czekać, zamiast bezpośrednio produkować
wartość. Teraz możemy wysyłać wiadomości z nadawcy do odbiornika. Zauważ, że
nie musimy uruchamiać oddzielnego wątku ani nawet zadania; wystarczy, że
będziemy czekać na wywołanie rx.recv.
Synchroniczna metoda Receiver::recv w std::mpsc::channel blokuje do czasu
otrzymania wiadomości. Metoda trpl::Receiver::recv tego nie robi, ponieważ
jest asynchroniczna. Zamiast blokować, przekazuje kontrolę z powrotem do
środowiska uruchomieniowego, dopóki nie zostanie odebrana wiadomość lub strona
wysyłająca kanału nie zostanie zamknięta. Natomiast nie czekamy na wywołanie
send, ponieważ nie blokuje. Nie musi, ponieważ kanał, do którego wysyłamy,
jest nieograniczony.
Uwaga: Ponieważ cały ten kod async działa w bloku async w wywołaniu
trpl::block_on, wszystko w nim może uniknąć blokowania. Jednak kod poza im blokiem będzie blokował, dopóki funkcjablock_onnie zwróci wartości. Na tym polega cała idea funkcjitrpl::block_on: pozwala wybrać, gdzie zablokować na jakimś zestawie kodu async, a tym samym, gdzie przejść między kodem synchronicznym a asynchronicznym.
Zauważ dwie rzeczy dotyczące tego przykładu. Po pierwsze, wiadomość dotrze natychmiast. Po drugie, choć używamy tutaj przyszłości, nie ma jeszcze współbieżności. Wszystko w listingu dzieje się sekwencyjnie, tak jakby nie było żadnych futures.
Zajmijmy się pierwszą częścią, wysyłając serię wiadomości i pauzując między nimi, jak pokazano w Listingu 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}Oprócz wysyłania wiadomości, musimy je odbierać. W tym przypadku, ponieważ
wiemy, ile wiadomości nadejdzie, moglibyśmy to zrobić ręcznie, wywołując
rx.recv().await cztery razy. Jednak w prawdziwym świecie zazwyczaj będziemy
czekać na nieznaną liczbę wiadomości, więc musimy czekać, aż ustalimy, że
nie ma już więcej wiadomości.
W Listingu 16-10 użyliśmy pętli for do przetwarzania wszystkich elementów
otrzymanych z kanału synchronicznego. Rust nie ma jeszcze sposobu na użycie
pętli for z asynchronicznie produkowanym strumieniem elementów, więc musimy
użyć pętli, której wcześniej nie widzieliśmy: warunkowej pętli while let.
Jest to wersja pętli konstrukcji if let, którą widzieliśmy w sekcji „Zwięzła
kontrola przepływu z if let i let...else” w
Rozdziale 6. Pętla będzie wykonywać się tak długo, jak długo określony wzorzec
będzie pasował do wartości.
Wywołanie rx.recv produkuje future, na którą czekamy. Środowisko uruchomieniowe
wstrzyma future, dopóki nie będzie gotowa. Gdy tylko nadejdzie wiadomość,
future rozstrzygnie się na Some(message) tyle razy, ile wiadomości nadejdzie.
Gdy kanał zostanie zamknięty, niezależnie od tego, czy jakiekolwiek wiadomości
nadeszły, future zamiast tego rozstrzygnie się na None, aby wskazać, że nie
ma już więcej wartości i w związku z tym powinniśmy przestać odpytywać – to
znaczy, przestać oczekiwać.
Pętla while let łączy to wszystko w całość. Jeśli wynik wywołania
rx.recv().await to Some(message), uzyskujemy dostęp do wiadomości i możemy
jej używać w ciele pętli, tak jak w przypadku if let. Jeśli wynik to None,
pętla się kończy. Za każdym razem, gdy pętla się kończy, ponownie trafia na
punkt oczekiwania, więc środowisko uruchomieniowe ponownie ją wstrzymuje,
dopóki nie nadejdzie kolejna wiadomość.
Kod teraz pomyślnie wysyła i odbiera wszystkie wiadomości. Niestety, nadal istnieją dwa problemy. Po pierwsze, wiadomości nie docierają w odstępach półsekundowych. Docierają wszystkie naraz, 2 sekundy (2000 milisekund) po uruchomieniu programu. Po drugie, ten program również nigdy się nie kończy! Zamiast tego czeka w nieskończoność na nowe wiadomości. Musisz go wyłączyć, używając ctrl-C.
Kod w jednym bloku Async wykonuje się liniowo
Zacznijmy od zbadania, dlaczego wiadomości przychodzą wszystkie naraz po pełnym
opóźnieniu, zamiast przychodzić z opóźnieniami między każdą z nich. W danym
bloku async kolejność, w jakiej słowa kluczowe await pojawiają się w kodzie,
jest również kolejnością, w jakiej są wykonywane, gdy program działa.
W Listingu 17-10 jest tylko jeden blok async, więc wszystko w nim działa
liniowo. Nadal nie ma współbieżności. Wszystkie wywołania tx.send odbywają się,
przeplatane wszystkimi wywołaniami trpl::sleep i ich powiązanymi punktami
oczekiwania. Dopiero wtedy pętla while let może przejść przez którykolwiek z
punktów oczekiwania na wywołania recv.
Aby uzyskać pożądane zachowanie, w którym opóźnienie snu następuje między
każdą wiadomością, musimy umieścić operacje tx i rx w ich własnych blokach
async, jak pokazano w Listingu 17-11. Wtedy środowisko uruchomieniowe może
wykonać każdą z nich oddzielnie, używając funkcji trpl::join, podobnie jak
w Listingu 17-8. Ponownie, czekamy na wynik wywołania trpl::join, a nie na
poszczególne futures. Gdybyśmy czekali na poszczególne futures w sekwencji,
skutkowałoby to powrotem do sekwencyjnego przepływu – dokładnie tego, czego
próbujemy nie robić.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Dzięki zaktualizowanemu kodowi z Listingu 17-11, wiadomości są drukowane w odstępach 500 milisekund, a nie wszystkie naraz po 2 sekundach.
Przenoszenie własności do bloku async
Program nadal nigdy się nie kończy z powodu sposobu, w jaki pętla while let
współdziała z trpl::join:
- Future zwrócona przez
trpl::joinkończy się dopiero, gdy obie future, które zostały do niej przekazane, zakończą swoje działanie. - Future
tx_futkończy się, gdy zakończy spanie po wysłaniu ostatniej wiadomości wvals. - Future
rx_futnie zakończy się, dopóki pętlawhile letsię nie zakończy. - Pętla
while letnie zakończy się, dopóki oczekiwanie narx.recvnie zwróciNone. - Oczekiwanie na
rx.recvzwróciNonedopiero po zamknięciu drugiego końca kanału. - Kanał zostanie zamknięty tylko, jeśli wywołamy
rx.closelub gdy strona nadawcy,tx, zostanie usunięta. - Nigdzie nie wywołujemy
rx.close, atxnie zostanie usunięte, dopóki najbardziej zewnętrzny blok async przekazany dotrpl::block_onsię nie zakończy. - Blok nie może się zakończyć, ponieważ jest zablokowany przez zakończenie
trpl::join, co cofa nas na początek tej listy.
Obecnie blok async, w którym wysyłamy wiadomości, jedynie pożycza tx,
ponieważ wysyłanie wiadomości nie wymaga własności, ale gdybyśmy mogli
przenieść tx do tego bloku async, zostałoby ono usunięte po zakończeniu
tego bloku. W sekcji „Przechwytywanie referencji lub przenoszenie
własności” w Rozdziale 13 nauczyłeś się, jak
używać słowa kluczowego move z domknięciami, a jak omówiono w sekcji
„Używanie domknięć move z wątkami” w Rozdziale
16, często musimy przenosić dane do domknięć, pracując z wątkami. Te same
podstawowe dynamiki dotyczą bloków async, więc słowo kluczowe move działa z
blokami async tak samo, jak z domknięciami.
W Listingu 17-12 zmieniamy blok używany do wysyłania wiadomości z async na
async move.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Po uruchomieniu tej wersji kodu, zamyka się ona płynnie po wysłaniu i odebraniu ostatniej wiadomości. Następnie, zobaczmy, co musiałoby się zmienić, aby wysyłać dane z więcej niż jednej future.
Łączenie wielu futures za pomocą makra join!
Ten kanał async jest również kanałem wieloproducentowym, więc możemy wywołać
clone na tx, jeśli chcemy wysyłać wiadomości z wielu futures, jak pokazano
w Listingu 17-13.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}Najpierw klonujemy tx, tworząc tx1 poza pierwszym blokiem async. Przenosimy
tx1 do tego bloku, tak jak wcześniej z tx. Następnie, później, przenosimy
oryginalne tx do nowego bloku async, gdzie wysyłamy więcej wiadomości z
nieco wolniejszym opóźnieniem. Akurat umieszczamy ten nowy blok async po bloku
async do odbierania wiadomości, ale równie dobrze mógłby być przed nim. Kluczem
jest kolejność, w jakiej futures są oczekiwane, a nie w jakiej są tworzone.
Oba bloki async do wysyłania wiadomości muszą być blokami async move,
tak aby zarówno tx, jak i tx1 zostały usunięte po zakończeniu tych bloków.
W przeciwnym razie wrócimy do tej samej nieskończonej pętli, w której zaczęliśmy.
Na koniec, przełączamy się z trpl::join na trpl::join!, aby obsłużyć
dodatkowe future: makro join! oczekuje na dowolną liczbę futures, gdzie
liczbę futures znamy w czasie kompilacji. O oczekiwaniu na kolekcję nieznanej
liczby futures będziemy rozmawiać później w tym rozdziale.
Teraz widzimy wszystkie wiadomości z obu futures wysyłających, a ponieważ futures wysyłające używają nieco innych opóźnień po wysłaniu, wiadomości są również odbierane w tych różnych odstępach czasu:
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
Możesz zobaczyć wartości w innej kolejności, w zależności od twojego systemu.
To właśnie sprawia, że współbieżność jest interesująca, a także trudna. Jeśli
poeksperymentujesz z thread::sleep, nadając mu różne wartości w różnych
wątkach, każde uruchomienie będzie bardziej niedeterministyczne i za każdym
razem będzie generować inne dane wyjściowe.
Teraz, gdy przyjrzeliśmy się, jak działają kanały, spójrzmy na inną metodę współbieżności.
Praca z dowolną liczbą futures
Przekazywanie kontroli do środowiska wykonawczego
Przypomnijmy z sekcji „Nasz pierwszy program asynchroniczny”, że w każdym punkcie await Rust daje środowisku wykonawczemu szansę na wstrzymanie zadania i przełączenie się na inne, jeśli oczekiwany future nie jest gotowy. Odwrotność jest również prawdziwa: Rust tylko wstrzymuje bloki asynchroniczne i przekazuje kontrolę środowisku wykonawczemu w punkcie await. Wszystko pomiędzy punktami await jest synchroniczne.
Oznacza to, że jeśli wykonasz dużo pracy w bloku asynchronicznym bez punktu await, ten future zablokuje postęp innych futures. Czasami usłyszysz, że jeden future zagładza inne futures. W niektórych przypadkach może to nie być duży problem. Jednak jeśli wykonujesz jakąś kosztowną konfigurację lub długotrwałą pracę, albo jeśli masz future, które będzie wykonywać pewne zadanie w nieskończoność, będziesz musiał pomyśleć o tym, kiedy i gdzie przekazać kontrolę środowisku wykonawczemu.
Zasymulujmy długotrwałą operację, aby zilustrować problem zagładzania, a następnie zbadajmy, jak go rozwiązać. Listing 17-14 wprowadza funkcję slow.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Ten kod używa std::thread::sleep zamiast trpl::sleep, więc wywołanie slow zablokuje bieżący wątek na określoną liczbę milisekund. Możemy użyć slow do reprezentowania rzeczywistych operacji, które są zarówno długotrwałe, jak i blokujące.
W Listing 17-15 używamy slow do emulacji tego rodzaju pracy związanej z CPU w parze futures.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Każdy future przekazuje kontrolę środowisku wykonawczemu dopiero po wykonaniu szeregu wolnych operacji. Jeśli uruchomisz ten kod, zobaczysz następujący wynik:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Podobnie jak w Listing 17-5, gdzie użyliśmy trpl::select do współzawodnictwa futures pobierających dwa adresy URL, select nadal kończy działanie, gdy tylko a zostanie zakończone. Nie ma jednak przeplatania między wywołaniami slow w dwóch futures. Future a wykonuje całą swoją pracę, dopóki nie zostanie oczekiwane wywołanie trpl::sleep, następnie future b wykonuje całą swoją pracę, dopóki nie zostanie oczekiwane jego własne wywołanie trpl::sleep, a na koniec future a zostaje zakończone. Aby umożliwić obu futures postęp między ich wolnymi zadaniami, potrzebujemy punktów await, abyśmy mogli przekazać kontrolę środowisku wykonawczemu. Oznacza to, że potrzebujemy czegoś, na co możemy czekać!
Już widzimy, jak tego rodzaju przekazywanie dzieje się w Listing 17-15: gdybyśmy usunęli trpl::sleep na końcu future a, zostałoby ono zakończone bez jakiegokolwiek uruchomienia future b. Spróbujmy użyć funkcji trpl::sleep jako punktu wyjścia do umożliwienia operacjom przełączania się w celu osiągania postępu, jak pokazano w Listing 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Dodaliśmy wywołania trpl::sleep z punktami await między każdym wywołaniem slow. Teraz praca obu futures jest przeplatana:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
Future a nadal działa przez chwilę, zanim przekaże kontrolę do b, ponieważ wywołuje slow przed wywołaniem trpl::sleep, ale potem futures zamieniają się miejscami za każdym razem, gdy jedna z nich osiąga punkt await. W tym przypadku zrobiliśmy to po każdym wywołaniu slow, ale mogliśmy podzielić pracę w sposób, który miałby dla nas największy sens.
Nie chcemy jednak tutaj faktycznie spać: chcemy postępować tak szybko, jak to możliwe. Po prostu musimy przekazać kontrolę środowisku wykonawczemu. Możemy to zrobić bezpośrednio, używając funkcji trpl::yield_now. W Listing 17-17 zastępujemy wszystkie te wywołania trpl::sleep wywołaniami trpl::yield_now.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}Ten kod jest zarówno jaśniejszy pod względem rzeczywistego zamiaru, jak i może być znacznie szybszy niż użycie sleep, ponieważ timery takie jak ten używany przez sleep często mają ograniczenia co do tego, jak granularne mogą być. Na przykład, wersja sleep, której używamy, zawsze będzie spać przez co najmniej milisekundę, nawet jeśli przekażemy jej Duration o długości jednej nanosekundy. Ponownie, nowoczesne komputery są szybkie: mogą zrobić wiele w ciągu jednej milisekundy!
Oznacza to, że async może być użyteczne nawet dla zadań związanych z obliczeniami, w zależności od tego, co jeszcze robi twój program, ponieważ dostarcza przydatne narzędzie do strukturyzowania relacji między różnymi częściami programu (ale kosztem narzutu maszyny stanów async). Jest to forma wielozadaniowości kooperacyjnej, gdzie każdy future ma moc decydowania, kiedy przekaże kontrolę za pośrednictwem punktów await. Każdy future ponosi zatem również odpowiedzialność za unikanie zbyt długiego blokowania. W niektórych wbudowanych systemach operacyjnych opartych na Rust jest to jedyny rodzaj wielozadaniowości!
W rzeczywistym kodzie oczywiście nie będziesz na każdej linii przeplatać wywołań funkcji z punktami await. Chociaż przekazywanie kontroli w ten sposób jest stosunkowo niedrogie, nie jest darmowe. W wielu przypadkach próba podziału zadania intensywnie obciążającego CPU może znacznie je spowolnić, więc czasami dla ogólnej wydajności lepiej jest pozwolić operacji na krótkie zablokowanie. Zawsze mierz, aby zobaczyć, gdzie są rzeczywiste wąskie gardła wydajności twojego kodu. Ważne jest jednak, aby pamiętać o podstawowej dynamice, jeśli widzisz dużo pracy wykonywanej szeregowo, a spodziewałeś się, że będzie ona wykonywana równolegle!
Budowanie własnych abstrakcji asynchronicznych
Możemy również łączyć futures, aby tworzyć nowe wzorce. Na przykład możemy zbudować funkcję timeout z już posiadanych asynchronicznych bloków konstrukcyjnych. Kiedy skończymy, wynik będzie kolejnym blokiem konstrukcyjnym, którego moglibyśmy użyć do tworzenia jeszcze bardziej asynchronicznych abstrakcji.
Listing 17-18 pokazuje, jak ten timeout powinien działać z wolnym future.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}Zaimplementujmy to! Na początek pomyślmy o API dla timeout:
- Musi to być funkcja asynchroniczna sama w sobie, abyśmy mogli na nią czekać (
await). - Jej pierwszy parametr powinien być futurem do uruchomienia. Możemy uczynić go generycznym, aby mógł działać z dowolnym futurem.
- Jej drugi parametr będzie maksymalnym czasem oczekiwania. Jeśli użyjemy
Duration, ułatwi to przekazanie dotrpl::sleep. - Powinna zwracać
Result. Jeśli future zakończy się pomyślnie,ResultbędzieOkz wartością wyprodukowaną przez future. Jeśli limit czasu upłynie wcześniej,ResultbędzieErrz czasem trwania, na który timeout czekał.
Listing 17-19 pokazuje tę deklarację.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}To spełnia nasze cele dotyczące typów. Teraz pomyślmy o zachowaniu, którego potrzebujemy: chcemy, aby future przekazane w tle konkurowało z czasem trwania. Możemy użyć trpl::sleep, aby utworzyć future timera z czasu trwania, i użyć trpl::select, aby uruchomić ten timer z futurem przekazanym przez wywołującego.
W Listing 17-20 implementujemy timeout poprzez dopasowanie do wyniku oczekiwania (await) na trpl::select.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// --snip--
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(max_time),
}
}Implementacja trpl::select nie jest sprawiedliwa: zawsze odpytuje argumenty w kolejności, w jakiej zostały przekazane (inne implementacje select losowo wybierają, który argument odpytać jako pierwszy). W ten sposób przekazujemy future_to_try do select jako pierwszy, aby miał szansę na ukończenie, nawet jeśli max_time jest bardzo krótkim czasem trwania. Jeśli future_to_try zakończy się jako pierwszy, select zwróci Left z wynikiem z future_to_try. Jeśli timer zakończy się jako pierwszy, select zwróci Right z wynikiem timera ().
Jeśli future_to_try zakończy się sukcesem i otrzymamy Left(output), zwracamy Ok(output). Jeśli zamiast tego upłynie czas timera uśpienia i otrzymamy Right(()), ignorujemy () za pomocą _ i zamiast tego zwracamy Err(max_time).
Dzięki temu mamy działającą funkcję timeout zbudowaną z dwóch innych asynchronicznych pomocników. Jeśli uruchomimy nasz kod, wydrukuje on tryb awarii po upływie limitu czasu:
Failed after 2 seconds
Ponieważ futures komponują się z innymi futures, możesz budować naprawdę potężne narzędzia, używając mniejszych asynchronicznych bloków konstrukcyjnych. Na przykład, możesz użyć tego samego podejścia do łączenia limitów czasu z ponownymi próbami, a z kolei używać ich z operacjami takimi jak wywołania sieciowe (takie jak te w Listing 17-5).
W praktyce zazwyczaj będziesz pracować bezpośrednio z async i await, a w drugiej kolejności z funkcjami takimi jak select i makrami takimi jak makro join! do kontrolowania sposobu wykonywania zewnętrznych futures.
Widzieliśmy już wiele sposobów pracy z wieloma futures jednocześnie. Następnie przyjrzymy się, jak możemy pracować z wieloma futures w sekwencji w czasie za pomocą strumieni.
Strumienie: Futures w sekwencji
Strumienie: Futures w sekwencji
Przypomnijmy, jak używaliśmy odbiornika dla naszego asynchronicznego kanału wcześniej w tym rozdziale w sekcji „Przekazywanie wiadomości”. Asynchroniczna metoda recv wytwarza sekwencję elementów w czasie. Jest to instancja znacznie bardziej ogólnego wzorca znanego jako strumień. Wiele koncepcji jest naturalnie reprezentowanych jako strumienie: elementy stają się dostępne w kolejce, fragmenty danych są pobierane przyrostowo z systemu plików, gdy pełny zestaw danych jest zbyt duży dla pamięci komputera, lub dane przychodzą przez sieć w czasie. Ponieważ strumienie są futures, możemy ich używać z dowolnym innym rodzajem future i łączyć je w interesujące sposoby. Na przykład, możemy grupować zdarzenia, aby uniknąć wywoływania zbyt wielu wywołań sieciowych, ustawiać limity czasu na sekwencje długotrwałych operacji lub ograniczać zdarzenia interfejsu użytkownika, aby uniknąć wykonywania zbędnej pracy.
Widzieliśmy sekwencję elementów w Rozdziale 13, kiedy przyglądaliśmy się cechom Iterator w sekcji „Cechy Iterator i metoda next”, ale istnieją dwie różnice między iteratorami a asynchronicznym odbiornikiem kanału. Pierwsza różnica to czas: iteratory są synchroniczne, podczas gdy odbiornik kanału jest asynchroniczny. Druga różnica to API. Pracując bezpośrednio z Iterator, wywołujemy jego synchroniczną metodę next. W przypadku strumienia trpl::Receiver w szczególności, zamiast tego wywołaliśmy asynchroniczną metodę recv. Poza tym te API są bardzo podobne, a to podobieństwo nie jest przypadkowe. Strumień jest jak asynchroniczna forma iteracji. Podczas gdy trpl::Receiver w szczególności czeka na odebranie wiadomości, ogólne API strumienia jest znacznie szersze: dostarcza następny element w taki sam sposób jak Iterator, ale asynchronicznie.
Podobieństwo między iteratorami a strumieniami w Rust oznacza, że faktycznie możemy stworzyć strumień z dowolnego iteratora. Podobnie jak w przypadku iteratora, możemy pracować ze strumieniem, wywołując jego metodę next, a następnie oczekując na wynik, jak w Listing 17-21, który jeszcze się nie skompiluje.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Zaczynamy od tablicy liczb, którą przekształcamy w iterator, a następnie wywołujemy map, aby podwoić wszystkie wartości. Następnie przekształcamy iterator w strumień za pomocą funkcji trpl::stream_from_iter. Dalej pętlujemy po elementach w strumieniu, gdy te docierają, za pomocą pętli while let.
Niestety, kiedy próbujemy uruchomić ten kod, nie kompiluje się on, lecz zgłasza brak metody next:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Jak wyjaśnia ten wynik, przyczyną błędu kompilacji jest to, że do użycia metody next potrzebujemy odpowiedniej cechy w zasięgu. Biorąc pod uwagę naszą dotychczasową dyskusję, można by rozsądnie oczekiwać, że będzie to cecha Stream, ale w rzeczywistości jest to StreamExt. Skrót od extension (rozszerzenie), Ext to powszechny wzorzec w społeczności Rust służący do rozszerzania jednej cechy inną.
Cecha Stream definiuje niskopoziomowy interfejs, który skutecznie łączy cechy Iterator i Future. StreamExt dostarcza wyższopoziomowy zestaw API ponad Stream, w tym metodę next, a także inne metody narzędziowe podobne do tych dostarczanych przez cechę Iterator. Stream i StreamExt nie są jeszcze częścią standardowej biblioteki Rust, ale większość składowych ekosystemu używa podobnych definicji.
Naprawą błędu kompilatora jest dodanie instrukcji use dla trpl::StreamExt, jak w Listing 17-22.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// --snip--
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Po połączeniu wszystkich tych elementów ten kod działa tak, jak chcemy! Co więcej, teraz, gdy mamy StreamExt w zasięgu, możemy używać wszystkich jego metod narzędziowych, tak samo jak w przypadku iteratorów.
Bliższe spojrzenie na cechy dla async
Bliższe spojrzenie na cechy dla Async
W całym rozdziale używaliśmy cech Future, Stream i StreamExt na różne sposoby. Jak dotąd unikaliśmy jednak zagłębiania się w szczegóły ich działania lub ich wzajemnego dopasowania, co w większości przypadków jest w porządku w codziennej pracy z Rust. Czasami jednak napotkasz sytuacje, w których będziesz musiał zrozumieć kilka więcej szczegółów tych cech, a także typ Pin i cechę Unpin. W tej sekcji zagłębimy się w nie na tyle, aby pomóc w takich scenariuszach, pozostawiając naprawdę dogłębne badanie innym dokumentacjom.
Cechy Future
Zacznijmy od bliższego przyjrzenia się, jak działa cecha Future. Oto jak Rust ją definiuje:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Ta definicja cechy zawiera wiele nowych typów, a także pewną składnię, której wcześniej nie widzieliśmy, więc przejdźmy przez definicję kawałek po kawałku.
Po pierwsze, typ skojarzony Output z cechy Future mówi, do czego future się rozwiązuje. Jest to analogiczne do typu skojarzonego Item z cechy Iterator. Po drugie, cecha Future ma metodę poll, która przyjmuje specjalną referencję Pin dla swojego parametru self oraz mutowalną referencję do typu Context i zwraca Poll<Self::Output>. Więcej o Pin i Context powiemy za chwilę. Na razie skupmy się na tym, co zwraca metoda, czyli na typie Poll:
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}Ten typ Poll jest podobny do Option. Ma jeden wariant, który ma wartość, Ready(T), i jeden, który nie ma, Pending. Poll oznacza jednak coś zupełnie innego niż Option! Wariant Pending wskazuje, że future nadal ma pracę do wykonania, więc wywołujący będzie musiał sprawdzić ponownie później. Wariant Ready wskazuje, że Future zakończyło swoją pracę i wartość T jest dostępna.
Uwaga: Rzadko zdarza się potrzeba bezpośredniego wywołania
poll, ale jeśli zajdzie taka potrzeba, pamiętaj, że w przypadku większości futures, wywołujący nie powinien ponownie wywoływaćpollpo tym, jak future zwróciłoReady. Wiele futures panikuje, jeśli zostanie ponownie odpytanych po staniu się gotowymi. Futures, które są bezpieczne do ponownego odpytania, będą o tym wyraźnie informować w swojej dokumentacji. Jest to podobne do zachowaniaIterator::next.
Kiedy widzisz kod, który używa await, Rust kompiluje go pod spodem do kodu, który wywołuje poll. Jeśli spojrzysz ponownie na Listing 17-4, gdzie wydrukowaliśmy tytuł strony dla pojedynczego adresu URL po jego rozwiązaniu, Rust kompiluje go do czegoś w rodzaju (choć nie dokładnie) tego:
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// But what goes here?
}
}Co powinniśmy zrobić, gdy future jest nadal w stanie Pending? Potrzebujemy jakiegoś sposobu, aby spróbować ponownie, i ponownie, i ponownie, aż future będzie w końcu gotowe. Innymi słowy, potrzebujemy pętli:
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// continue
}
}
}Jednak gdyby Rust skompilował to dokładnie na taki kod, każde await byłoby blokujące – dokładnie przeciwnie do tego, co zamierzaliśmy! Zamiast tego Rust zapewnia, że pętla może przekazać kontrolę czemuś, co może wstrzymać pracę nad tym future, aby pracować nad innymi futures, a następnie sprawdzić ten ponownie później. Jak widzieliśmy, tym czymś jest środowisko uruchomieniowe async, a ta praca związana z planowaniem i koordynacją jest jednym z jego głównych zadań.
W sekcji „Wysyłanie danych między dwoma zadaniami za pomocą przekazywania wiadomości” opisaliśmy oczekiwanie na rx.recv. Wywołanie recv zwraca future, a oczekiwanie na future odpytuje je. Zauważyliśmy, że środowisko uruchomieniowe wstrzyma future, dopóki nie będzie ono gotowe z Some(message) lub None, gdy kanał zostanie zamknięty. Dzięki naszemu głębszemu zrozumieniu cechy Future, a konkretnie Future::poll, możemy zobaczyć, jak to działa. Środowisko uruchomieniowe wie, że future nie jest gotowe, gdy zwraca Poll::Pending. Odwrotnie, środowisko uruchomieniowe wie, że future jest gotowe i kontynuuje je, gdy poll zwraca Poll::Ready(Some(message)) lub Poll::Ready(None).
Dokładne szczegóły tego, jak środowisko wykonawcze to robi, wykraczają poza zakres tej książki, ale kluczem jest zrozumienie podstawowych mechanizmów futures: środowisko wykonawcze odpytuje każdy future, za który jest odpowiedzialne, usypiając future ponownie, gdy nie jest jeszcze gotowe.
Typ Pin i cecha Unpin
W Listing 17-13 użyliśmy makra trpl::join! do oczekiwania na trzy futures. Jednak często zdarza się mieć kolekcję, taką jak wektor, zawierającą pewną liczbę futures, której nie będzie znana do czasu wykonania. Zmieńmy Listing 17-13 na kod z Listing 17-23, który umieszcza trzy futures w wektorze i wywołuje funkcję trpl::join_all zamiast tego, co jeszcze się nie skompiluje.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}Każdy future umieszczamy w Box, aby zamienić je w obiekty cech, tak jak to zrobiliśmy w sekcji „Zwracanie błędów z run” w Rozdziale 12. (Obiekty cech szczegółowo omówimy w Rozdziale 18.) Używanie obiektów cech pozwala nam traktować każdy z anonimowych futures wyprodukowanych przez te typy jako ten sam typ, ponieważ wszystkie one implementują cechę Future.
Może to być zaskakujące. Przecież żaden z bloków async niczego nie zwraca, więc każdy z nich produkuje Future<Output = ()>. Pamiętaj jednak, że Future jest cechą, a kompilator tworzy unikalny enum dla każdego bloku async, nawet jeśli mają identyczne typy wyjściowe. Tak jak nie możesz umieścić dwóch różnych, ręcznie napisanych struktur w Vec, tak samo nie możesz mieszać enumów generowanych przez kompilator.
Następnie przekazujemy kolekcję futures do funkcji trpl::join_all i czekamy na wynik. Jednak to się nie kompiluje; oto odpowiednia część komunikatów o błędach.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
Notatka w komunikacie o błędzie mówi nam, że powinniśmy użyć makra pin!, aby przypiąć wartości, co oznacza umieszczenie ich w typie Pin, który gwarantuje, że wartości nie zostaną przeniesione w pamięci. Komunikat o błędzie mówi, że przypinanie jest wymagane, ponieważ dyn Future<Output = ()> musi implementować cechę Unpin, a obecnie tego nie robi.
Funkcja trpl::join_all zwraca strukturę o nazwie JoinAll. Ta struktura jest generyczna na typie F, który jest ograniczony do implementacji cechy Future. Bezpośrednie oczekiwanie na future za pomocą await niejawnie przypina future. Dlatego nie musimy używać pin! wszędzie tam, gdzie chcemy oczekiwać na futures.
Nie oczekujemy tu jednak bezpośrednio na future. Zamiast tego konstruujemy nowe future, JoinAll, przekazując kolekcję futures do funkcji join_all. Sygnatura join_all wymaga, aby typy elementów w kolekcji implementowały cechę Future, a Box<T> implementuje Future tylko wtedy, gdy opakowywany przez niego T jest futurem, który implementuje cechę Unpin.
To dużo do przyswojenia! Aby to naprawdę zrozumieć, zagłębmy się nieco bardziej w to, jak działa cecha Future, szczególnie w kontekście przypinania. Spójrzmy jeszcze raz na definicję cechy Future:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
// Required method
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Parametr cx i jego typ Context są kluczem do tego, jak środowisko wykonawcze faktycznie wie, kiedy sprawdzić dany future, jednocześnie pozostając leniwym. Ponownie, szczegóły tego, jak to działa, wykraczają poza zakres tego rozdziału, i zazwyczaj musisz o tym myśleć tylko wtedy, gdy piszesz niestandardową implementację Future. Zamiast tego skupimy się na typie self, ponieważ jest to pierwszy raz, gdy widzieliśmy metodę, w której self ma adnotację typu. Adnotacja typu dla self działa jak adnotacje typu dla innych parametrów funkcji, ale z dwoma kluczowymi różnicami:
- Mówi Rustowi, jakiego typu musi być
self, aby metoda mogła zostać wywołana. - Nie może to być dowolny typ. Jest ograniczony do typu, na którym metoda jest zaimplementowana, referencji lub inteligentnego wskaźnika do tego typu, lub
Pinopakowującego referencję do tego typu.
Więcej na temat tej składni zobaczymy w Rozdziale 18. Na razie wystarczy wiedzieć, że jeśli chcemy odpytać future, aby sprawdzić, czy jest Pending czy Ready(Output), potrzebujemy mutowalnej referencji do typu opakowanej w Pin.
Pin to opakowanie dla typów wskaźnikopodobnych, takich jak &, &mut, Box i Rc. (Technicznie Pin działa z typami implementującymi cechy Deref lub DerefMut, ale to jest skutecznie równoważne z pracą tylko z referencjami i inteligentnymi wskaźnikami.) Pin sam w sobie nie jest wskaźnikiem i nie ma żadnego własnego zachowania, jak Rc i Arc zliczające referencje; jest to czysto narzędzie, którego kompilator może używać do wymuszania ograniczeń na użycie wskaźników.
Przypominając, że await jest implementowane w kategoriach wywołań poll, zaczyna wyjaśniać się komunikat o błędzie, który widzieliśmy wcześniej, ale był on w kategoriach Unpin, a nie Pin. Jak więc dokładnie Pin odnosi się do Unpin i dlaczego Future potrzebuje, aby self było w typie Pin, aby wywołać poll?
Przypomnijmy z wcześniejszej części tego rozdziału, że seria punktów oczekiwania w future jest kompilowana w maszynę stanów, a kompilator dba o to, aby ta maszyna stanów przestrzegała wszystkich normalnych zasad Rusta dotyczących bezpieczeństwa, w tym pożyczania i własności. Aby to działało, Rust patrzy na to, jakie dane są potrzebne między jednym punktem oczekiwania a następnym punktem oczekiwania lub końcem bloku async. Następnie tworzy odpowiedni wariant w skompilowanej maszynie stanów. Każdy wariant uzyskuje potrzebny dostęp do danych, które będą używane w tej sekcji kodu źródłowego, albo poprzez przejęcie własności tych danych, albo poprzez uzyskanie mutowalnej lub niemutowalnej referencji do nich.
Jak dotąd, wszystko dobrze: jeśli popełnimy błąd w kwestii własności lub referencji w danym bloku async, narzędzie borrow checker nas o tym poinformuje. Kiedy chcemy przenosić future odpowiadające temu blokowi – na przykład przenosząc je do Vec, aby przekazać do join_all – sprawy stają się bardziej skomplikowane.
Kiedy przenosimy future – czy to poprzez włożenie go do struktury danych w celu użycia jako iteratora z join_all, czy zwracając je z funkcji – oznacza to faktycznie przeniesienie maszyny stanów, którą Rust dla nas tworzy. I w przeciwieństwie do większości innych typów w Rust, futures, które Rust tworzy dla bloków async, mogą mieć odwołania do samych siebie w polach dowolnego wariantu, jak pokazano na uproszczonej ilustracji na Rysunku 17-4.

Jednakże, domyślnie każdy obiekt, który ma do siebie referencję, jest niebezpieczny do przenoszenia, ponieważ referencje zawsze wskazują na rzeczywisty adres pamięci tego, do czego się odnoszą (patrz Rysunek 17-5). Jeśli przeniesiesz samą strukturę danych, te wewnętrzne referencje będą wskazywać na stare miejsce. Jednak to miejsce w pamięci jest teraz nieprawidłowe. Po pierwsze, jego wartość nie zostanie zaktualizowana, gdy wprowadzisz zmiany w strukturze danych. Po drugie – co ważniejsze – komputer może teraz swobodnie ponownie wykorzystać tę pamięć do innych celów! Później możesz odczytać zupełnie niepowiązane dane.

Teoretycznie, kompilator Rust mógłby próbować aktualizować każdą referencję do obiektu, gdy jest on przenoszony, ale to mogłoby dodać wiele narzutu wydajnościowego, zwłaszcza jeśli cała sieć referencji wymaga aktualizacji. Gdybyśmy zamiast tego mogli zapewnić, że dana struktura danych nie przesuwa się w pamięci, nie musielibyśmy aktualizować żadnych referencji. Do tego właśnie służy borrow checker Rusta: w bezpiecznym kodzie zapobiega przenoszeniu jakiegokolwiek elementu, do którego istnieje aktywna referencja.
Pin opiera się na tym, aby zapewnić nam dokładnie taką gwarancję, jakiej potrzebujemy. Kiedy przypinamy wartość, opakowując wskaźnik do tej wartości w Pin, nie może się ona już przesuwać. Zatem, jeśli masz Pin<Box<SomeType>>, faktycznie przypinasz wartość SomeType, nie wskaźnik Box. Rysunek 17-6 ilustruje ten proces.

W rzeczywistości wskaźnik Box może nadal swobodnie się przemieszczać. Pamiętaj: zależy nam na tym, aby dane, do których ostatecznie się odwołujemy, pozostały na miejscu. Jeśli wskaźnik się przemieszcza, ale dane, na które wskazuje, znajdują się w tym samym miejscu, jak na Rysunku 17-7, nie ma potencjalnego problemu. (Jako niezależne ćwiczenie, spójrz na dokumentację typów oraz modułu std::pin i spróbuj ustalić, jak byś to zrobił z Pin opakowującym Box.) Kluczem jest to, że samoodwołujący się typ sam w sobie nie może się przemieszczać, ponieważ jest nadal przypięty.

Jednak większość typów jest całkowicie bezpieczna do przenoszenia, nawet jeśli znajdują się za wskaźnikiem Pin. Musimy myśleć o przypinaniu tylko wtedy, gdy elementy mają wewnętrzne referencje. Prymitywne wartości, takie jak liczby i wartości logiczne, są bezpieczne, ponieważ oczywiście nie mają żadnych wewnętrznych referencji.
Podobnie jak większość typów, z którymi normalnie pracujesz w Rust. Możesz przenosić Vec, na przykład, bez obaw. Biorąc pod uwagę to, co widzieliśmy do tej pory, jeśli masz Pin<Vec<String>>, musiałbyś robić wszystko za pomocą bezpiecznych, ale restrykcyjnych API dostarczonych przez Pin, mimo że Vec<String> jest zawsze bezpieczny do przenoszenia, jeśli nie ma do niego innych referencji. Potrzebujemy sposobu, aby powiedzieć kompilatorowi, że w takich przypadkach można przenosić elementy – i tu właśnie wchodzi Unpin.
Unpin to cecha znacznikowa, podobna do cech Send i Sync, które widzieliśmy w Rozdziale 16, i dlatego nie ma własnej funkcjonalności. Cechy znacznikowe istnieją tylko po to, aby poinformować kompilator, że bezpieczne jest użycie typu implementującego daną cechę w określonym kontekście. Unpin informuje kompilator, że dany typ nie musi przestrzegać żadnych gwarancji dotyczących tego, czy dana wartość może być bezpiecznie przeniesiona.
Podobnie jak w przypadku Send i Sync, kompilator automatycznie implementuje Unpin dla wszystkich typów, dla których może to udowodnić, że jest bezpieczne. Szczególnym przypadkiem, ponownie podobnym do Send i Sync, jest sytuacja, gdy Unpin nie jest implementowany dla typu. Oznaczenie dla tego to impl !Unpin for SomeType, gdzie SomeType to nazwa typu, który musi przestrzegać tych gwarancji, aby być bezpiecznym za każdym razem, gdy wskaźnik do tego typu jest używany w Pin.
Innymi słowy, istnieją dwie rzeczy, o których należy pamiętać w związku z relacją między Pin a Unpin. Po pierwsze, Unpin jest przypadkiem „normalnym”, a !Unpin jest przypadkiem specjalnym. Po drugie, to, czy typ implementuje Unpin czy !Unpin, ma znaczenie tylko wtedy, gdy używasz przypiętego wskaźnika do tego typu, takiego jak Pin<&mut SomeType>.
Aby to uściślić, pomyśl o String: ma długość i znaki Unicode, które ją tworzą. Możemy opakować String w Pin, jak widać na Rysunku 17-8. Jednak String automatycznie implementuje Unpin, podobnie jak większość innych typów w Rust.

W rezultacie możemy robić rzeczy, które byłyby nielegalne, gdyby String implementował zamiast tego !Unpin, takie jak zastępowanie jednego ciągu znaków innym w dokładnie tym samym miejscu w pamięci, jak na Rysunku 17-9. Nie narusza to kontraktu Pin, ponieważ String nie ma wewnętrznych odwołań, które czyniłyby jego przenoszenie niebezpiecznym. Właśnie dlatego implementuje Unpin, a nie !Unpin.

Teraz wiemy wystarczająco dużo, aby zrozumieć błędy zgłoszone dla wywołania join_all z Listing 17-23. Pierwotnie próbowaliśmy przenieść futures wyprodukowane przez bloki async do Vec<Box<dyn Future<Output = ()>>>, ale jak widzieliśmy, te futures mogą mieć wewnętrzne referencje, więc nie implementują automatycznie Unpin. Po ich przypięciu możemy przekazać wynikowy typ Pin do Vec, ufając, że bazowe dane w futures nie zostaną przeniesione. Listing 17-24 pokazuje, jak naprawić kod, wywołując makro pin! tam, gdzie zdefiniowane są wszystkie trzy futures, i dostosowując typ obiektu cechy.
extern crate trpl; // required for mdbook test
use std::pin::{Pin, pin};
// --snip--
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let rx_fut = pin!(async {
// --snip--
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
let tx_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
});
}Ten przykład kompiluje się i działa, a my moglibyśmy dodawać lub usuwać futures z wektora w czasie wykonania i łączyć je wszystkie.
Pin i Unpin są głównie ważne przy tworzeniu bibliotek niższego poziomu lub gdy budujesz samo środowisko wykonawcze, a nie w codziennym kodzie Rust. Kiedy jednak zobaczysz te cechy w komunikatach o błędach, będziesz miał lepszy pomysł, jak naprawić swój kod!
Uwaga: To połączenie
PiniUnpinumożliwia bezpieczną implementację całej klasy złożonych typów w Rust, które w przeciwnym razie okazałyby się trudne, ponieważ są samoreferencyjne. Typy wymagającePinpojawiają się najczęściej w dzisiejszym asynchronicznym Rust, ale co jakiś czas możesz je również zobaczyć w innych kontekstach.Szczegóły dotyczące działania
PiniUnpinoraz zasad, których muszą przestrzegać, są szczegółowo omówione w dokumentacji API dlastd::pin, więc jeśli jesteś zainteresowany pogłębianiem wiedzy, to świetne miejsce, aby zacząć.Jeśli chcesz zrozumieć, jak wszystko działa pod maską jeszcze bardziej szczegółowo, zobacz Rozdziały 2 i 4 z książki Asynchronous Programming in Rust async-book.
Cecha Stream
Teraz, gdy masz głębsze zrozumienie cech Future, Pin i Unpin, możemy zwrócić uwagę na cechę Stream. Jak dowiedziałeś się wcześniej w rozdziale, strumienie są podobne do asynchronicznych iteratorów. Jednak w przeciwieństwie do Iterator i Future, Stream nie ma definicji w standardowej bibliotece w momencie pisania tego tekstu, ale istnieje bardzo powszechna definicja z kraty futures używana w całym ekosystemie.
Przyjrzyjmy się definicjom cech Iterator i Future, zanim zastanowimy się, jak cecha Stream mogłaby je połączyć. Z Iterator mamy ideę sekwencji: jego metoda next dostarcza Option<Self::Item>. Z Future mamy ideę gotowości w czasie: jego metoda poll dostarcza Poll<Self::Output>. Aby reprezentować sekwencję elementów, które stają się gotowe w czasie, definiujemy cechę Stream, która łączy te funkcje:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
}Cecha Stream definiuje typ skojarzony o nazwie Item dla typu elementów wytwarzanych przez strumień. Jest to podobne do Iterator, gdzie może być zero lub wiele elementów, i w przeciwieństwie do Future, gdzie zawsze jest pojedynczy Output, nawet jeśli jest to typ jednostkowy ().
Stream definiuje również metodę do pobierania tych elementów. Nazywamy ją poll_next, aby jasno pokazać, że odpytuje w ten sam sposób, co Future::poll, i wytwarza sekwencję elementów w ten sam sposób, co Iterator::next. Jej typ zwracany łączy Poll z Option. Typ zewnętrzny to Poll, ponieważ musi być sprawdzany pod kątem gotowości, tak jak future. Typ wewnętrzny to Option, ponieważ musi sygnalizować, czy są więcej wiadomości, tak jak iterator.
Coś bardzo podobnego do tej definicji prawdopodobnie znajdzie się w standardowej bibliotece Rusta. W międzyczasie jest to część zestawu narzędzi większości środowisk wykonawczych, więc możesz na tym polegać, a wszystko, co omówimy dalej, powinno generalnie obowiązywać!
W przykładach, które widzieliśmy w sekcji „Strumienie: Futures w sekwencji”, nie użyliśmy jednak poll_next ani Stream, lecz next i StreamExt. Oczywiście mogliśmy pracować bezpośrednio w kategoriach API poll_next, ręcznie pisząc własne maszyny stanów Stream, tak samo jak mogliśmy pracować z futures bezpośrednio za pośrednictwem ich metody poll. Użycie await jest jednak znacznie przyjemniejsze, a cecha StreamExt dostarcza metodę next, dzięki czemu możemy to zrobić:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
trait StreamExt: Stream {
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// other methods...
}
}Uwaga: Rzeczywista definicja, której użyliśmy wcześniej w rozdziale, wygląda nieco inaczej, ponieważ obsługuje wersje Rust, które nie obsługiwały jeszcze używania funkcji async w cechach. W rezultacie wygląda to tak:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Ten typ
Nexttostruct, która implementujeFuturei pozwala nam nazwać czas życia referencji doselfza pomocąNext<'_, Self>, tak abyawaitmógł działać z tą metodą.
Cecha StreamExt jest również miejscem, gdzie znajdują się wszystkie interesujące metody dostępne do użytku ze strumieniami. StreamExt jest automatycznie implementowana dla każdego typu, który implementuje Stream, ale te cechy są definiowane oddzielnie, aby umożliwić społeczności iterowanie po wygodnych API bez wpływu na podstawową cechę.
W wersji StreamExt użytej w skrzynce trpl cecha ta nie tylko definiuje metodę next, ale także dostarcza domyślną implementację next, która poprawnie obsługuje szczegóły wywoływania Stream::poll_next. Oznacza to, że nawet gdy musisz napisać własny typ danych strumieniowych, tylko musisz zaimplementować Stream, a następnie każdy, kto używa twojego typu danych, może automatycznie używać StreamExt i jego metod.
To wszystko, co omówimy w kwestii niskopoziomowych szczegółów tych cech. Na zakończenie zastanówmy się, jak futures (w tym strumienie), zadania i wątki pasują do siebie!
Futures, Zadania i Wątki
Łączenie wszystkiego w całość: Futures, Zadania i Wątki
Jak widzieliśmy w Rozdziale 16, wątki stanowią jedno z podejść do współbieżności. W tym rozdziale poznaliśmy inne podejście: używanie async z futures i strumieniami. Jeśli zastanawiasz się, kiedy wybrać jedną metodę zamiast drugiej, odpowiedź brzmi: to zależy! I w wielu przypadkach wyborem nie są wątki lub async, ale raczej wątki i async.
Wiele systemów operacyjnych od dziesięcioleci dostarczało modele współbieżności oparte na wątkach, a wiele języków programowania je obsługuje. Jednak te modele mają swoje kompromisy. Na wielu systemach operacyjnych zużywają sporo pamięci na każdy wątek. Wątki są również opcją tylko wtedy, gdy system operacyjny i sprzęt je obsługują. W przeciwieństwie do popularnych komputerów stacjonarnych i mobilnych, niektóre systemy wbudowane w ogóle nie mają systemu operacyjnego, więc nie mają też wątków.
Model async zapewnia inny – i ostatecznie uzupełniający – zestaw kompromisów. W modelu async operacje współbieżne nie wymagają własnych wątków. Zamiast tego mogą działać na zadaniach, tak jak używaliśmy trpl::spawn_task do uruchomienia pracy z funkcji synchronicznej w sekcji strumieni. Zadanie jest podobne do wątku, ale zamiast być zarządzanym przez system operacyjny, jest zarządzane przez kod na poziomie biblioteki: środowisko uruchomieniowe.
Istnieje powód, dla którego API do uruchamiania wątków i uruchamiania zadań są tak podobne. Wątki działają jako granica dla zestawów operacji synchronicznych; współbieżność jest możliwa między wątkami. Zadania działają jako granica dla zestawów operacji asynchronicznych; współbieżność jest możliwa zarówno między, jak i wewnątrz zadań, ponieważ zadanie może przełączać się między futures w swoim ciele. Wreszcie, futures są najbardziej szczegółową jednostką współbieżności w Rust, a każda future może reprezentować drzewo innych futures. Środowisko uruchomieniowe – a konkretnie jego egzekutor – zarządza zadaniami, a zadania zarządzają futures. W tym względzie zadania są podobne do lekkich, zarządzanych przez środowisko uruchomieniowe wątków z dodatkowymi możliwościami wynikającymi z bycia zarządzanym przez środowisko uruchomieniowe, a nie przez system operacyjny.
Nie oznacza to, że zadania async są zawsze lepsze od wątków (lub odwrotnie). Współbieżność z wątkami jest pod pewnymi względami prostszym modelem programowania niż współbieżność z async. Może to być siła lub słabość. Wątki są nieco w stylu „odpal i zapomnij”; nie mają natywnego odpowiednika dla future, więc po prostu działają do końca, bez przerywania, chyba że przez sam system operacyjny.
Okazuje się, że wątki i zadania często bardzo dobrze współpracują, ponieważ zadania mogą (przynajmniej w niektórych środowiskach uruchomieniowych) być przenoszone między wątkami. W rzeczywistości, pod maską, środowisko uruchomieniowe, którego używaliśmy – w tym funkcje spawn_blocking i spawn_task – jest domyślnie wielowątkowe! Wiele środowisk uruchomieniowych stosuje podejście zwane work stealing (kradzieżą pracy) do transparentnego przenoszenia zadań między wątkami, w oparciu o bieżące wykorzystanie wątków, aby poprawić ogólną wydajność systemu. To podejście faktycznie wymaga wątków i zadań, a zatem i futures.
Zastanawiając się, którą metodę zastosować, rozważ te zasady:
- Jeśli praca jest bardzo równoległa (czyli CPU-bound), taka jak przetwarzanie dużej ilości danych, gdzie każda część może być przetwarzana oddzielnie, wątki są lepszym wyborem.
- Jeśli praca jest bardzo współbieżna (czyli I/O-bound), taka jak obsługa wiadomości z wielu różnych źródeł, które mogą przychodzić w różnych odstępach czasu lub z różnymi prędkościami, async jest lepszym wyborem.
AJeśli potrzebujesz zarówno równoległości, jak i współbieżności, nie musisz wybierać między wątkami a async. Możesz ich swobodnie używać razem, pozwalając każdemu odgrywać rolę, w której jest najlepszy. Na przykład, Lista 17-25 pokazuje dość powszechny przykład tego rodzaju połączenia w rzeczywistym kodzie Rust.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (tx, mut rx) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
tx.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}Zaczynamy od utworzenia kanału async, a następnie uruchamiamy wątek, który przejmuje własność strony nadawcy kanału za pomocą słowa kluczowego move. W wątku wysyłamy liczby od 1 do 10, usypiając na sekundę między każdą z nich. Na koniec uruchamiamy future utworzoną za pomocą bloku async przekazanego do trpl::block_on, tak jak robiliśmy to w całym rozdziale. W tej future oczekujemy na te wiadomości, tak jak w innych przykładach przekazywania wiadomości, które widzieliśmy.
Powracając do scenariusza, od którego zaczęliśmy rozdział, wyobraź sobie uruchamianie zestawu zadań kodowania wideo przy użyciu dedykowanego wątku (ponieważ kodowanie wideo jest obciążające dla procesora), ale powiadamianie interfejsu użytkownika o zakończeniu tych operacji za pomocą kanału async. Istnieją niezliczone przykłady tego rodzaju kombinacji w rzeczywistych przypadkach użycia.
Podsumowanie
To nie ostatni raz, kiedy spotkasz się ze współbieżnością w tej książce. Projekt w Rozdziale 21 zastosuje te koncepcje w bardziej realistycznej sytuacji niż prostsze przykłady omówione tutaj i porówna bezpośrednio rozwiązywanie problemów za pomocą wątków kontra zadań i futures.
Niezależnie od tego, które z tych podejść wybierzesz, Rust daje ci narzędzia potrzebne do pisania bezpiecznego, szybkiego, współbieżnego kodu – czy to dla serwera WWW o wysokiej przepustowości, czy dla wbudowanego systemu operacyjnego.
Następnie omówimy idiomatyczne sposoby modelowania problemów i strukturyzowania rozwiązań w miarę wzrostu programów Rust. Ponadto omówimy, jak idiomy Rust odnoszą się do tych, które możesz znać z programowania zorientowanego obiektowo.
Cechy Programowania Zorientowanego Obiektowo
Programowanie zorientowane obiektowo (OOP) to sposób modelowania programów. Obiekty jako koncepcja programistyczna zostały wprowadzone w języku programowania Simula w latach 60. Te obiekty wpłynęły na architekturę programistyczną Alana Kaya, w której obiekty przekazują sobie wiadomości. Aby opisać tę architekturę, ukuł on termin programowanie zorientowane obiektowo w 1967 roku. Wiele konkurujących definicji opisuje, czym jest OOP, i według niektórych z tych definicji Rust jest obiektowy, ale według innych nie jest. W tym rozdziale zbadamy pewne cechy, które są powszechnie uważane za obiektowe i jak te cechy przekładają się na idiomatyczny Rust. Następnie pokażemy, jak zaimplementować obiektowy wzorzec projektowy w Rust i omówimy kompromisy związane z tym w porównaniu do implementacji rozwiązania wykorzystującego niektóre mocne strony Rust.
Charakterystyka Języków Zorientowanych Obiektowo
Charakterystyka Języków Zorientowanych Obiektowo
W społeczności programistycznej nie ma zgody co do tego, jakie cechy musi posiadać język, aby był uważany za zorientowany obiektowo. Rust jest pod wpływem wielu paradygmatów programowania, w tym OOP; na przykład, zbadaliśmy cechy pochodzące z programowania funkcyjnego w Rozdziale 13. Prawdopodobnie, języki OOP dzielą pewne wspólne cechy – a mianowicie obiekty, hermetyzację i dziedziczenie. Przyjrzyjmy się, co oznacza każda z tych cech i czy Rust je obsługuje.
Obiekty Zawierają Dane i Zachowanie
Książka Wzorce projektowe: Elementy reużywalnego oprogramowania obiektowego Ericha Gammy, Richarda Helma, Ralpha Johnsona i Johna Vlissidesa (Addison-Wesley, 1994), potocznie nazywana książką Gang of Four, jest katalogiem obiektowych wzorców projektowych. Definiuje OOP w ten sposób:
Programy zorientowane obiektowo składają się z obiektów. Obiekt pakuje zarówno dane, jak i procedury, które operują na tych danych. Procedury są zazwyczaj nazywane metodami lub operacjami.
Zgodnie z tą definicją, Rust jest zorientowany obiektowo: struktury i wyliczenia posiadają dane, a bloki impl dostarczają metody dla struktur i wyliczeń. Mimo że struktur i wyliczeń z metodami nie nazywa się obiektami, zapewniają one tę samą funkcjonalność, zgodnie z definicją obiektów według Gang of Four.
Hermetyzacja Ukrywająca Szczegóły Implementacji
Innym aspektem powszechnie kojarzonym z OOP jest idea hermetyzacji, co oznacza, że szczegóły implementacji obiektu nie są dostępne dla kodu korzystającego z tego obiektu. Dlatego jedynym sposobem interakcji z obiektem jest jego publiczne API; kod używający obiektu nie powinien być w stanie bezpośrednio zmieniać wewnętrznych danych ani zachowań obiektu. Umożliwia to programiście zmianę i refaktoryzację wewnętrznych elementów obiektu bez konieczności zmiany kodu, który go używa.
Omówiliśmy, jak kontrolować hermetyzację w Rozdziale 7: Możemy użyć słowa kluczowego pub, aby zdecydować, które moduły, typy, funkcje i metody w naszym kodzie powinny być publiczne, a domyślnie wszystko inne jest prywatne. Na przykład, możemy zdefiniować strukturę AveragedCollection, która ma pole zawierające wektor wartości i32. Struktura może również mieć pole zawierające średnią wartości w wektorze, co oznacza, że średnia nie musi być obliczana na żądanie za każdym razem, gdy ktoś jej potrzebuje. Innymi słowy, AveragedCollection będzie dla nas buforować obliczoną średnią. Lista 18-1 zawiera definicję struktury AveragedCollection.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}AveragedCollection, która przechowuje listę liczb całkowitych i średnią elementów w kolekcjiStruktura jest oznaczona jako pub, aby inny kod mógł jej używać, ale pola wewnątrz struktury pozostają prywatne. Jest to ważne w tym przypadku, ponieważ chcemy zapewnić, że za każdym razem, gdy wartość jest dodawana lub usuwana z listy, średnia jest również aktualizowana. Robimy to, implementując metody add, remove i average dla struktury, jak pokazano na Liście 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}add, remove i average w AveragedCollectionPubliczne metody add, remove i average to jedyne sposoby dostępu lub modyfikacji danych w instancji AveragedCollection. Gdy element jest dodawany do list za pomocą metody add lub usuwany za pomocą metody remove, implementacje obu metod wywołują prywatną metodę update_average, która zajmuje się również aktualizacją pola average.
Pozostawiamy pola list i average prywatne, aby zewnętrzny kod nie mógł bezpośrednio dodawać ani usuwać elementów z pola list; w przeciwnym razie pole average mogłoby stać się niespójne, gdy list się zmienia. Metoda average zwraca wartość z pola average, umożliwiając zewnętrznemu kodowi odczyt average, ale nie jego modyfikację.
Ponieważ hermetyzowaliśmy szczegóły implementacji struktury AveragedCollection, możemy w przyszłości łatwo zmieniać aspekty, takie jak struktura danych. Na przykład, moglibyśmy użyć HashSet<i32> zamiast Vec<i32> dla pola list. Dopóki sygnatury publicznych metod add, remove i average pozostałyby takie same, kod używający AveragedCollection nie wymagałby zmian. Gdybyśmy uczynili list publicznym, niekoniecznie tak by było: HashSet<i32> i Vec<i32> mają różne metody dodawania i usuwania elementów, więc kod zewnętrzny prawdopodobnie musiałby się zmienić, gdyby modyfikował list bezpośrednio.
Jeśli hermetyzacja jest wymaganym aspektem, aby język był uważany za obiektowy, to Rust spełnia to wymaganie. Opcja użycia pub lub nie dla różnych części kodu umożliwia hermetyzację szczegółów implementacji.
Dziedziczenie jako System Typów i jako Udostępnianie Kodu
Dziedziczenie to mechanizm, dzięki któremu obiekt może dziedziczyć elementy z definicji innego obiektu, uzyskując w ten sposób dane i zachowanie obiektu-rodzica bez konieczności ponownego ich definiowania.
Jeśli język musi posiadać dziedziczenie, aby być obiektowym, to Rust nie jest takim językiem. Nie ma sposobu, aby zdefiniować strukturę, która dziedziczy pola i implementacje metod struktury-rodzica bez użycia makra.
Jednakże, jeśli jesteś przyzwyczajony do posiadania dziedziczenia w swoim zestawie narzędzi programistycznych, możesz użyć innych rozwiązań w Rust, w zależności od powodu, dla którego pierwotnie sięgnąłeś po dziedziczenie.
Dziedziczenie wybrałbyś z dwóch głównych powodów. Jeden to ponowne wykorzystanie kodu: możesz zaimplementować określone zachowanie dla jednego typu, a dziedziczenie umożliwia ponowne wykorzystanie tej implementacji dla innego typu. Możesz to zrobić w ograniczony sposób w kodzie Rust, używając domyślnych implementacji metod cech, co widziałeś na Liście 10-14, gdy dodaliśmy domyślną implementację metody summarize do cechy Summary. Każdy typ implementujący cechę Summary miałby dostępną metodę summarize bez dodatkowego kodu. Jest to podobne do klasy nadrzędnej posiadającej implementację metody i dziedziczącej klasy podrzędnej również posiadającej implementację metody. Możemy również nadpisać domyślną implementację metody summarize podczas implementowania cechy Summary, co jest podobne do klasy podrzędnej nadpisującej implementację metody odziedziczonej z klasy nadrzędnej.
Drugi powód użycia dziedziczenia dotyczy systemu typów: aby umożliwić użycie typu potomnego w tych samych miejscach co typ nadrzędny. Nazywa się to również polimorfizmem, co oznacza, że można podstawiać wiele obiektów jeden za drugi w czasie wykonania, jeśli dzielą one pewne cechy.
Polimorfizm
Dla wielu osób polimorfizm jest synonimem dziedziczenia. Ale w rzeczywistości jest to bardziej ogólna koncepcja, która odnosi się do kodu, który może pracować z danymi wielu typów. Dla dziedziczenia te typy są zazwyczaj podklasami.
Rust zamiast tego używa generyków do abstrakcji nad różnymi możliwymi typami i ograniczeń cech do narzucania ograniczeń na to, co te typy muszą zapewniać. Jest to czasami nazywane ograniczonym polimorfizmem parametrycznym.
Rust wybrał inny zestaw kompromisów, nie oferując dziedziczenia. Dziedziczenie często grozi współdzieleniem większej ilości kodu niż to konieczne. Podklasy nie zawsze powinny dzielić wszystkie cechy swojej klasy nadrzędnej, ale będą to robić w przypadku dziedziczenia. Może to sprawić, że projekt programu będzie mniej elastyczny. Wprowadza to również możliwość wywoływania metod w podklasach, które nie mają sensu lub powodują błędy, ponieważ metody nie mają zastosowania do podklasy. Ponadto, niektóre języki zezwalają tylko na pojedyncze dziedziczenie (co oznacza, że podklasa może dziedziczyć tylko z jednej klasy), co dodatkowo ogranicza elastyczność projektu programu.
Z tych powodów Rust przyjmuje inne podejście, używając obiektów cech zamiast dziedziczenia, aby osiągnąć polimorfizm w czasie wykonania. Przyjrzyjmy się, jak działają obiekty cech.
Używanie Obiektów Trait do Abstrakcji nad Wspólnym Zachowaniem
Używanie Obiektów Trait do Abstrakcji nad Wspólnym Zachowaniem
W Rozdziale 8 wspomnieliśmy, że jednym z ograniczeń wektorów jest to, że mogą przechowywać elementy tylko jednego typu. Stworzyliśmy obejście w Liście 8-9, gdzie zdefiniowaliśmy wyliczenie SpreadsheetCell z wariantami do przechowywania liczb całkowitych, zmiennoprzecinkowych i tekstu. Oznaczało to, że mogliśmy przechowywać różne typy danych w każdej komórce i nadal mieć wektor reprezentujący wiersz komórek. Jest to doskonale dobre rozwiązanie, gdy nasze wymienne elementy to stały zestaw typów, które znamy w momencie kompilacji kodu.
Jednak czasami chcemy, aby użytkownik naszej biblioteki mógł rozszerzyć zestaw typów, które są prawidłowe w danej sytuacji. Aby pokazać, jak to osiągnąć, stworzymy przykład narzędzia graficznego interfejsu użytkownika (GUI), które iteruje przez listę elementów, wywołując metodę draw na każdym z nich, aby narysować go na ekranie — powszechna technika w narzędziach GUI. Stworzymy bibliotekę gui, która będzie zawierać strukturę biblioteki GUI. Ta biblioteka może zawierać typy dla użytkowników, takie jak Button lub TextField. Ponadto użytkownicy gui będą chcieli tworzyć własne typy, które można rysować: na przykład jeden programista może dodać Image, a inny SelectBox.
W momencie pisania biblioteki nie możemy znać i zdefiniować wszystkich typów, które inni programiści mogą chcieć stworzyć. Wiemy jednak, że gui musi śledzić wiele wartości różnych typów i musi wywoływać metodę draw na każdej z tych wartości o różnych typach. Nie musi wiedzieć dokładnie, co się stanie, gdy wywołamy metodę draw, tylko tyle, że wartość będzie miała tę metodę dostępną do wywołania.
Aby to zrobić w języku z dziedziczeniem, moglibyśmy zdefiniować klasę o nazwie Component, która miałaby metodę draw. Inne klasy, takie jak Button, Image i SelectBox, dziedziczyłyby po Component i w ten sposób dziedziczyłyby metodę draw. Każda z nich mogłaby nadpisać metodę draw, aby zdefiniować swoje niestandardowe zachowanie, ale framework mógłby traktować wszystkie typy tak, jakby były instancjami Component i wywoływać na nich draw. Ale ponieważ Rust nie ma dziedziczenia, potrzebujemy innego sposobu na zbudowanie biblioteki gui, aby umożliwić użytkownikom tworzenie nowych typów zgodnych z biblioteką.
Definiowanie Traitu dla Wspólnego Zachowania
Aby zaimplementować zachowanie, które chcemy, aby gui miało, zdefiniujemy cechę Draw, która będzie miała jedną metodę draw. Następnie możemy zdefiniować wektor, który przyjmuje obiekt cechy. Obiekt cechy wskazuje zarówno instancję typu implementującego naszą określoną cechę, jak i tabelę używaną do wyszukiwania metod cech na tym typie w czasie wykonania. Tworzymy obiekt cechy, określając jakiś rodzaj wskaźnika, taki jak referencja lub inteligentny wskaźnik Box<T>, następnie słowo kluczowe dyn, a następnie określając odpowiednią cechę. (O powodzie, dla którego obiekty cech muszą używać wskaźnika, porozmawiamy w sekcji „Typy o dynamicznym rozmiarze i cecha Sized” w Rozdziale 20.) Możemy używać obiektów cech zamiast typu generycznego lub konkretnego. Wszędzie, gdzie używamy obiektu cechy, system typów Rust zapewni w czasie kompilacji, że każda wartość użyta w tym kontekście będzie implementować cechę obiektu cechy. W konsekwencji nie musimy znać wszystkich możliwych typów w czasie kompilacji.
Wspomnieliśmy, że w Rust powstrzymujemy się od nazywania struktur i wyliczeń „obiektami”, aby odróżnić je od obiektów z innych języków. W strukturze lub wyliczeniu dane w polach struktury i zachowanie w blokach impl są oddzielone, podczas gdy w innych językach dane i zachowanie połączone w jedną koncepcję są często nazywane obiektem. Obiekty cech różnią się od obiektów w innych językach tym, że nie możemy dodawać danych do obiektu cechy. Obiekty cech nie są tak ogólnie użyteczne jak obiekty w innych językach: ich specyficznym celem jest umożliwienie abstrakcji nad wspólnym zachowaniem.
Lista 18-3 pokazuje, jak zdefiniować cechę Draw z jedną metodą draw.
pub trait Draw {
fn draw(&self);
}DrawTa składnia powinna być znana z naszych dyskusji na temat definiowania cech w Rozdziale 10. Dalej pojawia się nowa składnia: Lista 18-4 definiuje strukturę o nazwie Screen, która zawiera wektor o nazwie components. Ten wektor jest typu Box<dyn Draw>, czyli obiektu cechy; jest to zastępstwo dla dowolnego typu wewnątrz Box, który implementuje cechę Draw.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Screen z polem components zawierającym wektor obiektów cech, które implementują cechę DrawW strukturze Screen zdefiniujemy metodę run, która wywoła metodę draw na każdym z jej components, jak pokazano na Liście 18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}run w Screen, która wywołuje metodę draw na każdym komponencieDziała to inaczej niż definiowanie struktury, która używa generycznego parametru typu z ograniczeniami cech. Generyczny parametr typu może być podstawiony tylko jednym konkretnym typem na raz, podczas gdy obiekty cech pozwalają na wypełnienie obiektu cechy wieloma konkretnymi typami w czasie wykonania. Na przykład, moglibyśmy zdefiniować strukturę Screen używając generycznego typu i ograniczenia cech, jak na Liście 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Screen i jej metody run za pomocą generyków i ograniczeń cechTo ogranicza nas do instancji Screen, która ma listę komponentów wszystkich typu Button lub wszystkich typu TextField. Jeśli zawsze będziesz mieć tylko jednorodne kolekcje, użycie generyków i ograniczeń cech jest preferowane, ponieważ definicje zostaną zmonomorfizowane w czasie kompilacji, aby używać konkretnych typów.
Z drugiej strony, w metodzie używającej obiektów cech, jedna instancja Screen może przechowywać Vec<T>, który zawiera Box<Button> oraz Box<TextField>. Przyjrzyjmy się, jak to działa, a następnie omówimy implikacje dla wydajności w czasie wykonania.
Implementowanie Traitu
Teraz dodamy kilka typów, które implementują cechę Draw. Zapewnimy typ Button. Ponownie, faktyczne zaimplementowanie biblioteki GUI wykracza poza zakres tej książki, więc metoda draw nie będzie miała żadnej użytecznej implementacji w swoim ciele. Aby wyobrazić sobie, jak mogłaby wyglądać implementacja, struktura Button mogłaby mieć pola width, height i label, jak pokazano na Liście 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Button, która implementuje cechę DrawPola width, height i label w Button będą się różnić od pól w innych komponentach; na przykład, typ TextField mógłby mieć te same pola plus pole placeholder. Każdy z typów, które chcemy narysować na ekranie, będzie implementował cechę Draw, ale użyje innego kodu w metodzie draw, aby zdefiniować, jak narysować dany typ, jak to ma miejsce w Button (bez faktycznego kodu GUI, jak wspomniano). Typ Button, na przykład, mógłby mieć dodatkowy blok impl zawierający metody związane z tym, co dzieje się, gdy użytkownik kliknie przycisk. Tego rodzaju metody nie będą miały zastosowania do typów takich jak TextField.
Jeśli ktoś używający naszej biblioteki zdecyduje się zaimplementować strukturę SelectBox, która ma pola width, height i options, zaimplementuje również cechę Draw dla typu SelectBox, jak pokazano na Liście 18-8.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}gui i implementujący cechę Draw na strukturze SelectBoxUżytkownik naszej biblioteki może teraz napisać swoją funkcję main, aby utworzyć instancję Screen. Do instancji Screen mogą dodać SelectBox i Button, umieszczając każdy w Box<T>, aby stał się obiektem cechy. Następnie mogą wywołać metodę run na instancji Screen, która wywoła draw na każdym z komponentów. Lista 18-9 pokazuje tę implementację.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Kiedy pisaliśmy bibliotekę, nie wiedzieliśmy, że ktoś może dodać typ SelectBox, ale nasza implementacja Screen była w stanie operować na nowym typie i go rysować, ponieważ SelectBox implementuje cechę Draw, co oznacza, że implementuje metodę draw.
Ta koncepcja — zajmowanie się tylko wiadomościami, na które wartość odpowiada, a nie konkretnym typem wartości — jest podobna do koncepcji duck typing w językach z dynamicznym typowaniem: jeśli chodzi jak kaczka i kwacze jak kaczka, to musi być kaczka! W implementacji run na Screen na Liście 18-5, run nie musi wiedzieć, jaki jest konkretny typ każdego komponentu. Nie sprawdza, czy komponent jest instancją Button czy SelectBox, po prostu wywołuje metodę draw na komponencie. Poprzez określenie Box<dyn Draw> jako typu wartości w wektorze components, zdefiniowaliśmy, że Screen potrzebuje wartości, na których możemy wywołać metodę draw.
Zaletą używania obiektów cech i systemu typów Rust do pisania kodu podobnego do kodu używającego duck typingu jest to, że nigdy nie musimy sprawdzać, czy wartość implementuje konkretną metodę w czasie wykonania, ani martwić się o błędy, jeśli wartość nie implementuje metody, ale mimo to ją wywołujemy. Rust nie skompiluje naszego kodu, jeśli wartości nie implementują cech, których potrzebują obiekty cech.
Na przykład, Lista 18-10 pokazuje, co się dzieje, gdy próbujemy stworzyć Screen ze String jako komponentem.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}Otrzymamy ten błąd, ponieważ String nie implementuje cechy Draw:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
Ten błąd informuje nas, że albo przekazujemy coś do Screen, czego nie zamierzaliśmy przekazać i dlatego powinniśmy przekazać inny typ, albo powinniśmy zaimplementować Draw na String, aby Screen był w stanie wywołać na nim draw.
Wykonywanie Dynamicznego Wysyłania
Przypomnijmy sobie dyskusję w sekcji „Wydajność kodu używającego generyków” w Rozdziale 10 na temat procesu monomorfizacji wykonywanego przez kompilator dla generyków: kompilator generuje niegeneryczne implementacje funkcji i metod dla każdego konkretnego typu, który używamy w miejsce generycznego parametru typu. Kod, który wynika z monomorfizacji, wykonuje statyczne wysyłanie, czyli sytuację, w której kompilator wie, którą metodę wywołujesz w czasie kompilacji. Jest to przeciwieństwo dynamicznego wysyłania, czyli sytuacji, w której kompilator nie może w czasie kompilacji określić, którą metodę wywołujesz. W przypadkach dynamicznego wysyłania kompilator emituje kod, który w czasie wykonania będzie wiedział, którą metodę wywołać.
Kiedy używamy obiektów cech, Rust musi użyć dynamicznego wysyłania. Kompilator nie zna wszystkich typów, które mogą być użyte z kodem używającym obiektów cech, więc nie wie, która metoda zaimplementowana na którym typie ma być wywołana. Zamiast tego, w czasie wykonania, Rust używa wskaźników w obiekcie cechy, aby wiedzieć, którą metodę wywołać. To wyszukiwanie wiąże się z kosztem wykonania, który nie występuje przy statycznym wysyłaniu. Dynamiczne wysyłanie uniemożliwia również kompilatorowi wstawienie kodu metody, co z kolei uniemożliwia niektóre optymalizacje, a Rust ma pewne zasady dotyczące tego, gdzie można, a gdzie nie można używać dynamicznego wysyłania, zwane kompatybilnością dyn. Te zasady wykraczają poza zakres tej dyskusji, ale możesz przeczytać o nich więcej w referencji. Jednakże uzyskaliśmy dodatkową elastyczność w kodzie, który napisaliśmy na Liście 18-5 i byliśmy w stanie obsługiwać na Liście 18-9, więc jest to kompromis do rozważenia.
Implementacja Obiektowo Zorientowanego Wzorca Projektowego
Implementacja Obiektowo Zorientowanego Wzorca Projektowego
Wzorzec stanu to obiektowo zorientowany wzorzec projektowy. Istotą wzorca jest to, że definiujemy zestaw stanów, które wartość może mieć wewnętrznie. Stany są reprezentowane przez zestaw obiektów stanu, a zachowanie wartości zmienia się w zależności od jej stanu. Przejdziemy przez przykład struktury wpisu na blogu, która ma pole do przechowywania swojego stanu, który będzie obiektem stanu z zestawu „szkic”, „do recenzji” lub „opublikowany”.
Obiekty stanu dzielą funkcjonalność: w Rust, oczywiście, używamy struktur i cech zamiast obiektów i dziedziczenia. Każdy obiekt stanu jest odpowiedzialny za własne zachowanie i za to, kiedy powinien zmienić się w inny stan. Wartość, która przechowuje obiekt stanu, nic nie wie o różnych zachowaniach stanów ani o tym, kiedy przechodzić między stanami.
Zaletą stosowania wzorca stanu jest to, że gdy zmienią się wymagania biznesowe programu, nie będziemy musieli zmieniać kodu wartości przechowującej stan ani kodu, który używa tej wartości. Będziemy musieli jedynie zaktualizować kod wewnątrz jednego z obiektów stanu, aby zmienić jego zasady lub ewentualnie dodać więcej obiektów stanu.
Najpierw zaimplementujemy wzorzec stanu w bardziej tradycyjny, obiektowy sposób. Następnie użyjemy podejścia, które jest nieco bardziej naturalne w Rust. Zagłębimy się w stopniową implementację przepływu pracy wpisu na blogu, używając wzorca stanu.
Końcowa funkcjonalność będzie wyglądać tak:
- Wpis na blogu zaczyna się jako pusty szkic.
- Po zakończeniu szkicu, prosi się o jego recenzję.
- Po zatwierdzeniu wpis zostaje opublikowany.
- Tylko opublikowane wpisy na blogu zwracają treść do wydrukowania, aby niezaprobowane wpisy nie mogły zostać przypadkowo opublikowane.
Wszelkie inne próby zmian we wpisie nie powinny mieć żadnego efektu. Na przykład, jeśli spróbujemy zatwierdzić szkic wpisu na blogu, zanim poprosimy o recenzję, wpis powinien pozostać nieopublikowanym szkicem.
Próba w Tradycyjnym Stylu Obiektowym
Istnieje nieskończenie wiele sposobów strukturyzowania kodu w celu rozwiązania tego samego problemu, każdy z różnymi kompromisami. Implementacja w tej sekcji jest bardziej tradycyjnym stylem obiektowym, który jest możliwy do napisania w Rust, ale nie wykorzystuje niektórych mocnych stron Rust. Później zademonstrujemy inne rozwiązanie, które nadal używa wzorca projektowego zorientowanego obiektowo, ale jest skonstruowane w sposób, który może wydawać się mniej znajomy programistom z doświadczeniem w programowaniu obiektowym. Porównamy oba rozwiązania, aby doświadczyć kompromisów związanych z projektowaniem kodu Rust inaczej niż w innych językach.
Lista 18-11 pokazuje ten przepływ pracy w formie kodu: jest to przykład użycia API, które zaimplementujemy w bibliotece o nazwie blog. To się jeszcze nie skompiluje, ponieważ nie zaimplementowaliśmy crate blog.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}blogChcemy umożliwić użytkownikowi utworzenie nowego szkicu wpisu na blogu za pomocą Post::new. Chcemy umożliwić dodawanie tekstu do wpisu na blogu. Jeśli spróbujemy natychmiast uzyskać treść wpisu, przed zatwierdzeniem, nie powinniśmy otrzymać żadnego tekstu, ponieważ wpis jest nadal szkicem. Dodaliśmy assert_eq! w kodzie w celach demonstracyjnych. Doskonałym testem jednostkowym byłoby sprawdzenie, czy szkic wpisu na blogu zwraca pusty ciąg z metody content, ale nie będziemy pisać testów dla tego przykładu.
Następnie chcemy umożliwić prośbę o recenzję wpisu i chcemy, aby content zwracało pusty ciąg, podczas gdy czekamy na recenzję. Kiedy wpis zostanie zatwierdzony, powinien zostać opublikowany, co oznacza, że tekst wpisu zostanie zwrócony, gdy wywołana zostanie metoda content.
Zauważ, że jedynym typem, z którym wchodzimy w interakcję z biblioteki, jest typ Post. Ten typ będzie używał wzorca stanu i będzie przechowywał wartość, która będzie jednym z trzech obiektów stanu reprezentujących różne stany, w jakich może znajdować się wpis — szkic, do recenzji lub opublikowany. Zmiana z jednego stanu na drugi będzie zarządzana wewnętrznie w typie Post. Stany zmieniają się w odpowiedzi na metody wywoływane przez użytkowników naszej biblioteki na instancji Post, ale nie muszą oni bezpośrednio zarządzać zmianami stanu. Ponadto użytkownicy nie mogą popełnić błędu ze stanami, na przykład publikując wpis przed jego zrecenzowaniem.
Definiowanie Post i Tworzenie Nowej Instancji
Rozpocznijmy implementację biblioteki! Wiemy, że potrzebujemy publicznej struktury Post, która przechowuje pewną zawartość, więc zaczniemy od definicji struktury i powiązanej publicznej funkcji new do tworzenia instancji Post, jak pokazano na Liście 18-12. Stworzymy również prywatną cechę State, która zdefiniuje zachowanie, które muszą mieć wszystkie obiekty stanu dla Post.
Następnie Post będzie przechowywać obiekt cechy Box<dyn State> wewnątrz Option<T> w prywatnym polu o nazwie state, aby przechowywać obiekt stanu. Za chwilę zobaczysz, dlaczego Option<T> jest konieczny.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Post i funkcji new, która tworzy nową instancję Post, cechy State i struktury DraftCecha State definiuje zachowanie dzielone przez różne stany wpisu. Obiekty stanu to Draft, PendingReview i Published, i wszystkie one będą implementować cechę State. Na razie cecha nie ma żadnych metod, a zaczniemy od zdefiniowania tylko stanu Draft, ponieważ to jest stan, w którym chcemy, aby wpis zaczynał się.
Kiedy tworzymy nowy Post, ustawiamy jego pole state na wartość Some, która zawiera Box. Ten Box wskazuje na nową instancję struktury Draft. To zapewnia, że za każdym razem, gdy tworzymy nową instancję Post, zaczyna ona jako szkic. Ponieważ pole state w Post jest prywatne, nie ma możliwości utworzenia Post w żadnym innym stanie! W funkcji Post::new ustawiamy pole content na nowy, pusty String.
Przechowywanie Tekstu Treści Wpisu
Widzieliśmy w Liście 18-11, że chcemy mieć możliwość wywołania metody add_text i przekazania jej &str, który jest następnie dodawany jako tekstowa zawartość wpisu na blogu. Implementujemy to jako metodę, zamiast udostępniać pole content jako pub, aby później móc zaimplementować metodę, która będzie kontrolować, w jaki sposób odczytywane są dane pola content. Metoda add_text jest dość prosta, więc dodajmy implementację z Listy 18-13 do bloku impl Post.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}add_text do dodawania tekstu do content wpisuMetoda add_text przyjmuje zmienną referencję do self, ponieważ zmieniamy instancję Post, na której wywołujemy add_text. Następnie wywołujemy push_str na String w content i przekazujemy argument text, aby dodać go do zapisanej content. To zachowanie nie zależy od stanu, w jakim znajduje się wpis, więc nie jest częścią wzorca stanu. Metoda add_text w ogóle nie wchodzi w interakcje z polem state, ale jest częścią zachowania, które chcemy wspierać.
Zapewnienie, że Zawartość Szkicu Wpisu Jest Pusta
Nawet po wywołaniu add_text i dodaniu treści do naszego wpisu, nadal chcemy, aby metoda content zwracała pusty fragment ciągu, ponieważ wpis jest nadal w stanie szkicu, jak pokazano przez pierwsze assert_eq! na Liście 18-11. Na razie zaimplementujmy metodę content w najprostszy sposób, który spełni to wymaganie: zawsze zwracając pusty fragment ciągu. Zmienimy to później, gdy zaimplementujemy możliwość zmiany stanu wpisu, tak aby mógł zostać opublikowany. Do tej pory wpisy mogą być tylko w stanie szkicu, więc zawartość wpisu powinna być zawsze pusta. Lista 18-14 pokazuje tę implementację zastępczą.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}content w Post, która zawsze zwraca pusty fragment ciąguDzięki tej dodanej metodzie content wszystko z Listy 18-11 aż do pierwszego assert_eq! działa zgodnie z przeznaczeniem.
Zlecenie recenzji, która zmienia stan wpisu
Następnie musimy dodać funkcjonalność do żądania recenzji wpisu, co powinno zmienić jego stan ze Draft na PendingReview. Lista 18-15 pokazuje ten kod.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}request_review w Post i cechy StateDajemy Post publiczną metodę request_review, która przyjmuje zmienną referencję do self. Następnie wywołujemy wewnętrzną metodę request_review na bieżącym stanie Post, a ta druga metoda request_review konsumuje bieżący stan i zwraca nowy stan.
Dodajemy metodę request_review do cechy State; wszystkie typy, które implementują tę cechę, będą teraz musiały zaimplementować metodę request_review. Zauważ, że zamiast self, &self lub &mut self jako pierwszego parametru metody, mamy self: Box<Self>. Ta składnia oznacza, że metoda jest prawidłowa tylko wtedy, gdy jest wywoływana na Box zawierającym ten typ. Ta składnia przejmuje własność Box<Self>, unieważniając stary stan, tak aby wartość stanu Post mogła przekształcić się w nowy stan.
Aby skonsumować stary stan, metoda request_review musi przejąć własność wartości stanu. To tutaj wchodzi w grę Option w polu state struktury Post: wywołujemy metodę take, aby pobrać wartość Some z pola state i pozostawić None na jej miejscu, ponieważ Rust nie pozwala nam mieć niezapelnionych pól w strukturach. To pozwala nam przenieść wartość state z Post, zamiast jej pożyczać. Następnie ustawimy wartość state wpisu na wynik tej operacji.
Musimy tymczasowo ustawić state na None, zamiast ustawiać go bezpośrednio kodem takim jak self.state = self.state.request_review();, aby uzyskać własność wartości state. Zapewnia to, że Post nie może używać starej wartości state po tym, jak przekształciliśmy ją w nowy stan.
Metoda request_review w Draft zwraca nową, opakowaną instancję nowej struktury PendingReview, która reprezentuje stan, gdy wpis oczekuje na recenzję. Struktura PendingReview również implementuje metodę request_review, ale nie wykonuje żadnych transformacji. Zamiast tego zwraca siebie, ponieważ gdy prosimy o recenzję wpisu, który jest już w stanie PendingReview, powinien on pozostać w stanie PendingReview.
Teraz możemy zacząć dostrzegać zalety wzorca stanu: metoda request_review w Post jest taka sama niezależnie od jej wartości state. Każdy stan jest odpowiedzialny za własne reguły.
Pozostawimy metodę content w Post w niezmienionej postaci, zwracając pusty fragment ciągu. Możemy teraz mieć Post w stanie PendingReview, a także w stanie Draft, ale chcemy tego samego zachowania w stanie PendingReview. Lista 18-11 działa teraz aż do drugiego wywołania assert_eq!!
Dodawanie approve w celu zmiany zachowania content
Metoda approve będzie podobna do metody request_review: ustawi state na wartość, którą bieżący stan powinien mieć po zatwierdzeniu, jak pokazano na Liście 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}approve w Post i cechy StateDodajemy metodę approve do cechy State i nową strukturę, która implementuje State, czyli stan Published.
Podobnie jak działa request_review w PendingReview, jeśli wywołamy metodę approve na Draft, nie będzie to miało żadnego efektu, ponieważ approve zwróci self. Kiedy wywołamy approve na PendingReview, zwróci nową, spakowaną instancję struktury Published. Struktura Published implementuje cechę State, a dla obu metod request_review i approve zwraca siebie, ponieważ w tych przypadkach wpis powinien pozostać w stanie Published.
Teraz musimy zaktualizować metodę content w Post. Chcemy, aby wartość zwracana przez content zależała od bieżącego stanu Post, dlatego Post będzie delegować do metody content zdefiniowanej na swoim state, jak pokazano na Liście 18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}content w Post w celu delegowania do metody content w StatePonieważ celem jest utrzymanie wszystkich tych zasad wewnątrz struktur implementujących State, wywołujemy metodę content na wartości w state i przekazujemy instancję wpisu (czyli self) jako argument. Następnie zwracamy wartość zwróconą przez użycie metody content na wartości state.
Wywołujemy metodę as_ref na Option, ponieważ chcemy referencję do wartości wewnątrz Option, a nie własności wartości. Ponieważ state jest Option<Box<dyn State>>, po wywołaniu as_ref zwracane jest Option<&Box<dyn State>>. Gdybyśmy nie wywołali as_ref, otrzymalibyśmy błąd, ponieważ nie możemy przenieść state poza pożyczone &self z parametru funkcji.
Następnie wywołujemy metodę unwrap, o której wiemy, że nigdy nie spowoduje paniki, ponieważ wiemy, że metody w Post zapewniają, że state zawsze będzie zawierać wartość Some po zakończeniu tych metod. Jest to jeden z przypadków, o których mówiliśmy w sekcji „Kiedy masz więcej informacji niż kompilator” w Rozdziale 9, kiedy wiemy, że wartość None nigdy nie jest możliwa, mimo że kompilator nie jest w stanie tego zrozumieć.
W tym momencie, gdy wywołamy content na &Box<dyn State>, nastąpi koercja dereferencji na & i Box, tak że metoda content zostanie ostatecznie wywołana na typie, który implementuje cechę State. Oznacza to, że musimy dodać content do definicji cechy State, i to tam umieścimy logikę dotyczącą tego, jaką zawartość zwrócić w zależności od posiadanego stanu, jak pokazano na Liście 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}content do cechy StateDodajemy domyślną implementację metody content, która zwraca pusty fragment ciągu. Oznacza to, że nie musimy implementować content w strukturach Draft i PendingReview. Struktura Published nadpisze metodę content i zwróci wartość z post.content. Choć wygodne, posiadanie metody content w State, która określa zawartość Post, zaciera granice między odpowiedzialnością State a odpowiedzialnością Post.
Zauważ, że potrzebujemy adnotacji dotyczących czasu życia w tej metodzie, jak omówiliśmy w Rozdziale 10. Przyjmujemy referencję do post jako argument i zwracamy referencję do części tego post, więc czas życia zwróconej referencji jest związany z czasem życia argumentu post.
I gotowe — cała Lista 18-11 działa! Zaimplementowaliśmy wzorzec stanu z zasadami przepływu pracy wpisu na blogu. Logika związana z zasadami znajduje się w obiektach stanu, a nie jest rozproszona po Post.
Dlaczego Nie Wyliczenie (Enum)?
Być może zastanawiałeś się, dlaczego nie użyliśmy wyliczenia (enum) z różnymi możliwymi stanami wpisu jako wariantami. To z pewnością możliwe rozwiązanie; spróbuj go i porównaj ostateczne wyniki, aby zobaczyć, które wolisz! Jedną z wad używania wyliczenia jest to, że każde miejsce, które sprawdza wartość wyliczenia, będzie potrzebowało wyrażenia match lub podobnego, aby obsłużyć każdy możliwy wariant. To mogłoby stać się bardziej powtarzalne niż to rozwiązanie z obiektem cechy.
Ocena Wzorca Stanu
Pokazaliśmy, że Rust jest zdolny do implementacji obiektowo zorientowanego wzorca stanu w celu hermetyzacji różnych rodzajów zachowań, jakie powinien mieć wpis w każdym stanie. Metody w Post nic nie wiedzą o różnych zachowaniach. Dzięki temu, jak zorganizowaliśmy kod, musimy patrzeć tylko w jedno miejsce, aby poznać różne sposoby zachowania opublikowanego wpisu: implementację cechy State na strukturze Published.
Gdybyśmy stworzyli alternatywną implementację, która nie używałaby wzorca stanu, moglibyśmy zamiast tego użyć wyrażeń match w metodach w Post lub nawet w kodzie main, który sprawdza stan wpisu i zmienia zachowanie w tych miejscach. Oznaczałoby to, że musielibyśmy patrzeć w kilku miejscach, aby zrozumieć wszystkie implikacje bycia w stanie opublikowanym.
Przy użyciu wzorca stanu, metody Post i miejsca, w których używamy Post, nie potrzebują wyrażeń match, a aby dodać nowy stan, wystarczyłoby dodać nową strukturę i zaimplementować metody cech na tej jednej strukturze w jednym miejscu.
Implementacja wykorzystująca wzorzec stanu jest łatwa do rozszerzenia o dodatkową funkcjonalność. Aby zobaczyć prostotę utrzymywania kodu, który używa wzorca stanu, wypróbuj kilka z tych sugestii:
- Dodaj metodę
reject, która zmienia stan wpisu zPendingReviewz powrotem naDraft. - Wymagaj dwóch wywołań
approve, zanim stan będzie mógł zostać zmieniony naPublished. - Zezwalaj użytkownikom na dodawanie treści tekstowej tylko wtedy, gdy wpis jest w stanie
Draft. Wskazówka: niech obiekt stanu będzie odpowiedzialny za to, co może się zmienić w treści, ale nie za modyfikowaniePost.
Jedną z wad wzorca stanu jest to, że ponieważ stany implementują przejścia między stanami, niektóre stany są ze sobą powiązane. Gdybyśmy dodali inny stan między PendingReview a Published, taki jak Scheduled, musielibyśmy zmienić kod w PendingReview, aby przejść do Scheduled. Byłoby to mniej pracy, gdyby PendingReview nie wymagało zmian wraz z dodaniem nowego stanu, ale to oznaczałoby przejście na inny wzorzec projektowy.
Inną wadą jest to, że powieliliśmy trochę logiki. Aby wyeliminować część powtórzeń, moglibyśmy spróbować stworzyć domyślne implementacje dla metod request_review i approve w cechy State, które zwracają self. Jednak to by nie zadziałało: używając State jako obiektu cechy, cecha nie wie dokładnie, czym będzie konkretny self, więc typ zwracany nie jest znany w czasie kompilacji. (To jedna z wcześniej wspomnianych reguł kompatybilności dyn).
Inne powtórzenia obejmują podobne implementacje metod request_review i approve w Post. Obie metody używają Option::take z polem state z Post, a jeśli state jest Some, delegują do implementacji tej samej metody przez owiniętą wartość i ustawiają nową wartość pola state na wynik. Gdybyśmy mieli wiele metod w Post, które postępowałyby zgodnie z tym wzorcem, moglibyśmy rozważyć zdefiniowanie makra, aby wyeliminować powtórzenia (patrz sekcja „Makrodefinicje” w Rozdziale 20).
Implementując wzorzec stanu dokładnie tak, jak jest zdefiniowany dla języków zorientowanych obiektowo, nie wykorzystujemy w pełni mocnych stron Rust. Przyjrzyjmy się kilku zmianom, które możemy wprowadzić w bibliotece blog, aby nieprawidłowe stany i przejścia stały się błędami w czasie kompilacji.
Kodowanie Stanów i Zachowania jako Typy
Pokażemy, jak przemyśleć wzorzec stanu, aby uzyskać inny zestaw kompromisów. Zamiast całkowicie hermetyzować stany i przejścia, tak aby zewnętrzny kod nie miał o nich wiedzy, zakodujemy stany w różnych typach. W konsekwencji system sprawdzania typów Rust zapobiegnie próbom użycia szkiców wpisów tam, gdzie dozwolone są tylko opublikowane wpisy, zgłaszając błąd kompilacji.
Rozważmy pierwszą część main na Liście 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Dalej umożliwiamy tworzenie nowych wpisów w stanie szkicu za pomocą Post::new oraz możliwość dodawania tekstu do treści wpisu. Ale zamiast mieć metodę content w szkicu wpisu, która zwraca pusty ciąg, sprawimy, że szkice wpisów w ogóle nie będą miały metody content. W ten sposób, jeśli spróbujemy uzyskać treść szkicu wpisu, otrzymamy błąd kompilatora informujący nas, że metoda nie istnieje. W rezultacie niemożliwe będzie przypadkowe wyświetlenie treści szkicu wpisu w produkcji, ponieważ ten kod nawet się nie skompiluje. Lista 18-19 pokazuje definicję struktury Post i struktury DraftPost, a także metody na każdej z nich.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Post z metodą content i DraftPost bez metody contentZarówno struktury Post, jak i DraftPost mają prywatne pole content, które przechowuje tekst wpisu na blogu. Struktury nie mają już pola state, ponieważ przenosimy kodowanie stanu do typów struktur. Struktura Post będzie reprezentować opublikowany wpis i ma metodę content, która zwraca content.
Dalej mamy funkcję Post::new, ale zamiast zwracać instancję Post, zwraca instancję DraftPost. Ponieważ content jest prywatne i nie ma żadnych funkcji zwracających Post, obecnie nie jest możliwe utworzenie instancji Post.
Struktura DraftPost posiada metodę add_text, więc możemy dodawać tekst do content tak jak wcześniej, ale zauważ, że DraftPost nie ma zdefiniowanej metody content! Teraz program zapewnia, że wszystkie wpisy zaczynają się jako szkice wpisów, a szkice wpisów nie mają dostępnej treści do wyświetlenia. Każda próba obejścia tych ograniczeń spowoduje błąd kompilatora.
Więc jak zdobyć opublikowany wpis? Chcemy wymusić zasadę, że szkic wpisu musi zostać zrecenzowany i zatwierdzony, zanim zostanie opublikowany. Wpis w stanie oczekiwania na recenzję nadal nie powinien wyświetlać żadnej treści. Zaimplementujmy te ograniczenia, dodając kolejną strukturę, PendingReviewPost, definiując metodę request_review w DraftPost, aby zwracała PendingReviewPost, i definiując metodę approve w PendingReviewPost, aby zwracała Post, jak pokazano na Liście 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}PendingReviewPost, która jest tworzona poprzez wywołanie request_review na DraftPost, oraz metoda approve, która zamienia PendingReviewPost w opublikowany PostMetody request_review i approve przejmują własność self, konsumując w ten sposób instancje DraftPost i PendingReviewPost i przekształcając je odpowiednio w PendingReviewPost i opublikowany Post. W ten sposób nie będziemy mieć żadnych pozostałych instancji DraftPost po wywołaniu na nich request_review i tak dalej. Struktura PendingReviewPost nie ma zdefiniowanej metody content, więc próba odczytania jej treści skutkuje błędem kompilacji, podobnie jak w przypadku DraftPost. Ponieważ jedynym sposobem na uzyskanie opublikowanej instancji Post, która ma zdefiniowaną metodę content, jest wywołanie metody approve na PendingReviewPost, a jedynym sposobem na uzyskanie PendingReviewPost jest wywołanie metody request_review na DraftPost, zakodowaliśmy teraz przepływ pracy wpisu na blogu w systemie typów.
Musimy jednak wprowadzić również niewielkie zmiany w main. Metody request_review i approve zwracają nowe instancje zamiast modyfikować strukturę, na której są wywoływane, więc musimy dodać więcej przypisań let post = w celu zapisania zwróconych instancji. Nie możemy też mieć asercji dotyczących pustych ciągów w treści szkiców i wpisów oczekujących na recenzję, ani ich nie potrzebujemy: nie możemy już skompilować kodu, który próbuje użyć treści wpisów w tych stanach. Zaktualizowany kod w main pokazano na Liście 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}main w celu użycia nowej implementacji przepływu pracy wpisu na bloguZmiany, które musieliśmy wprowadzić w main, aby ponownie przypisać post, oznaczają, że ta implementacja nie do końca już odpowiada wzorcowi stanu zorientowanemu obiektowo: transformacje między stanami nie są już w pełni hermetyzowane w implementacji Post. Jednak naszym zyskiem jest to, że nieprawidłowe stany są teraz niemożliwe dzięki systemowi typów i sprawdzaniu typów, które odbywa się w czasie kompilacji! To zapewnia, że pewne błędy, takie jak wyświetlanie treści nieopublikowanego wpisu, zostaną wykryte, zanim trafią do produkcji.
Wypróbuj zadania sugerowane na początku tej sekcji na bibliotece blog w stanie po Liście 18-21, aby zobaczyć, co myślisz o projekcie tej wersji kodu. Zauważ, że niektóre zadania mogą być już ukończone w tym projekcie.
Widzieliśmy, że chociaż Rust jest w stanie implementować obiektowo zorientowane wzorce projektowe, inne wzorce, takie jak kodowanie stanu w systemie typów, są również dostępne w Rust. Te wzorce mają różne kompromisy. Chociaż możesz być bardzo zaznajomiony z obiektowo zorientowanymi wzorcami, ponowne przemyślenie problemu w celu wykorzystania funkcji Rust może przynieść korzyści, takie jak zapobieganie niektórym błędom w czasie kompilacji. Wzorce obiektowo zorientowane nie zawsze będą najlepszym rozwiązaniem w Rust ze względu na pewne cechy, takie jak własność, których języki obiektowo zorientowane nie posiadają.
Podsumowanie
Niezależnie od tego, czy uważasz Rust za język obiektowy po przeczytaniu tego rozdziału, wiesz już, że możesz używać obiektów cech, aby uzyskać niektóre cechy obiektowe w Rust. Dynamiczne wysyłanie może zapewnić Twojemu kodowi pewną elastyczność w zamian za niewielki koszt wydajności w czasie wykonania. Możesz wykorzystać tę elastyczność do implementacji obiektowych wzorców, które mogą pomóc w utrzymaniu kodu. Rust ma również inne cechy, takie jak własność, których języki obiektowe nie mają. Wzorzec obiektowy nie zawsze będzie najlepszym sposobem na wykorzystanie mocnych stron Rust, ale jest to dostępna opcja.
Następnie przyjrzymy się wzorcom, które są kolejną z funkcji Rust, które umożliwiają dużą elastyczność. Przyglądaliśmy się im krótko w całej książce, ale nie widzieliśmy jeszcze ich pełnych możliwości. Zacznijmy!
Wzorce i Dopasowywanie
Wzorce to specjalna składnia w Rust służąca do dopasowywania struktury typów, zarówno złożonych, jak i prostych. Używanie wzorców w połączeniu z wyrażeniami match i innymi konstrukcjami daje większą kontrolę nad przepływem sterowania programu. Wzorzec składa się z pewnej kombinacji następujących elementów:
- Literały
- Zdekonstruowane tablice, wyliczenia, struktury lub krotki
- Zmienne
- Symbole wieloznaczne
- Zastępcze miejsca
Przykładowe wzorce to x, (a, 3) i Some(Color::Red). W kontekstach, w których wzorce są prawidłowe, te komponenty opisują kształt danych. Nasz program dopasowuje wartości do wzorców, aby określić, czy ma prawidłowy kształt danych do kontynuowania wykonywania określonego fragmentu kodu.
Aby użyć wzorca, porównujemy go z pewną wartością. Jeśli wzorzec pasuje do wartości, używamy części wartości w naszym kodzie. Przypomnij sobie wyrażenia match z Rozdziału 6, które używały wzorców, takie jak przykład maszyny do sortowania monet. Jeśli wartość pasuje do kształtu wzorca, możemy użyć nazwanych elementów. Jeśli nie, kod powiązany ze wzorcem nie zostanie uruchomiony.
Ten rozdział jest referencją do wszystkiego, co związane ze wzorcami. Omówimy prawidłowe miejsca użycia wzorców, różnicę między wzorcami odrzucalnymi i nieodrzucalnymi oraz różne rodzaje składni wzorców, które możesz zobaczyć. Pod koniec rozdziału będziesz wiedzieć, jak używać wzorców do wyrażania wielu koncepcji w jasny sposób.
Wszystkie Miejsca, w Których Można Używać Wzorców
Wszystkie Miejsca, w Których Można Używać Wzorców
Wzorce pojawiają się w wielu miejscach w Rust, a Ty używałeś ich wiele razy, nie zdając sobie z tego sprawy! Ta sekcja omawia wszystkie miejsca, w których wzorce są prawidłowe.
Ramiona match
Jak omówiono w Rozdziale 6, używamy wzorców w ramionach wyrażeń match. Formalnie wyrażenia match są definiowane jako słowo kluczowe match, wartość do dopasowania i jedno lub więcej ramion dopasowania, które składają się ze wzorca i wyrażenia do uruchomienia, jeśli wartość pasuje do wzorca tego ramienia, w ten sposób:
match WARTOŚĆ {
WZORZEC => WYRAŻENIE,
WZORZEC => WYRAŻENIE,
WZORZEC => WYRAŻENIE,
}Na przykład, oto wyrażenie match z Listy 6-5, które dopasowuje wartość Option<i32> w zmiennej x:
match x {
None => None,
Some(i) => Some(i + 1),
}Wzorce w tym wyrażeniu match to None i Some(i) po lewej stronie każdej strzałki.
Jednym z wymagań dla wyrażeń match jest to, że muszą być wyczerpujące w tym sensie, że wszystkie możliwości dla wartości w wyrażeniu match muszą być uwzględnione. Jednym ze sposobów zapewnienia, że pokryłeś każdą możliwość, jest posiadanie wzorca catch-all dla ostatniego ramienia: na przykład nazwa zmiennej pasująca do dowolnej wartości nigdy nie może się nie powieść i tym samym pokrywa każdy pozostały przypadek.
Konkretny wzorzec _ pasuje do wszystkiego, ale nigdy nie wiąże się ze zmienną, więc często jest używany w ostatnim ramieniu match. Wzorzec _ może być użyteczny, gdy chcesz zignorować dowolną nieokreśloną wartość, na przykład. Omówimy wzorzec _ bardziej szczegółowo w sekcji „Ignorowanie wartości we wzorcu” w dalszej części tego rozdziału.
Instrukcje let
Przed tym rozdziałem jawnie omawialiśmy używanie wzorców tylko z match i if let, ale w rzeczywistości używaliśmy wzorców również w innych miejscach, w tym w instrukcjach let. Na przykład, rozważ to proste przypisanie zmiennej za pomocą let:
#![allow(unused)]
fn main() {
let x = 5;
}Za każdym razem, gdy używałeś instrukcji let w ten sposób, używałeś wzorców, chociaż mogłeś tego nie zdawać sobie sprawy! Bardziej formalnie, instrukcja let wygląda tak:
let WZORZEC = WYRAŻENIE;
W instrukcjach takich jak let x = 5; z nazwą zmiennej w miejscu PATTERN, nazwa zmiennej jest po prostu szczególnie prostą formą wzorca. Rust porównuje wyrażenie ze wzorcem i przypisuje wszystkie znalezione nazwy. Tak więc, w przykładzie let x = 5;, x jest wzorcem, który oznacza „zwiąż to, co pasuje tutaj, ze zmienną x”. Ponieważ nazwa x jest całym wzorcem, ten wzorzec skutecznie oznacza „zwiąż wszystko ze zmienną x, niezależnie od wartości”.
Aby wyraźniej zobaczyć aspekt dopasowywania wzorców w let, rozważ Listę 19-1, która używa wzorca z let do dekonstrukcji krotki.
fn main() {
let (x, y, z) = (1, 2, 3);
}Tutaj dopasowujemy krotkę do wzorca. Rust porównuje wartość (1, 2, 3) ze wzorcem (x, y, z) i widzi, że wartość pasuje do wzorca — to znaczy, widzi, że liczba elementów jest taka sama w obu — więc Rust wiąże 1 z x, 2 z y i 3 z z. Możesz myśleć o tym wzorcu krotki jako o zagnieżdżeniu w nim trzech pojedynczych wzorców zmiennych.
Jeśli liczba elementów we wzorcu nie odpowiada liczbie elementów w krotce, ogólny typ nie będzie pasował i otrzymamy błąd kompilacji. Na przykład, Lista 19-2 pokazuje próbę dekompozycji krotki z trzema elementami na dwie zmienne, co nie zadziała.
fn main() {
let (x, y) = (1, 2, 3);
}Próba skompilowania tego kodu skutkuje błędem typu:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Aby naprawić błąd, moglibyśmy zignorować jedną lub więcej wartości w krotce za pomocą _ lub .., jak zobaczysz w sekcji „Ignorowanie wartości we wzorcu”. Jeśli problem polega na tym, że mamy zbyt wiele zmiennych we wzorcu, rozwiązaniem jest dopasowanie typów poprzez usunięcie zmiennych, tak aby liczba zmiennych była równa liczbie elementów w krotce.
Warunkowe Wyrażenia if let
W Rozdziale 6 omówiliśmy, jak używać wyrażeń if let głównie jako krótszego sposobu na zapisanie odpowiednika match, który pasuje tylko do jednego przypadku. Opcjonalnie, if let może mieć odpowiadający mu else zawierający kod do uruchomienia, jeśli wzorzec w if let nie pasuje.
Lista 19-3 pokazuje, że możliwe jest również mieszanie i dopasowywanie wyrażeń if let, else if i else if let. Działanie to daje nam większą elastyczność niż wyrażenie match, w którym możemy wyrazić tylko jedną wartość do porównania ze wzorcami. Ponadto Rust nie wymaga, aby warunki w serii ramion if let, else if i else if let były ze sobą powiązane.
Kod na Liście 19-3 określa kolor tła na podstawie serii sprawdzeń kilku warunków. W tym przykładzie stworzyliśmy zmienne z zakodowanymi na stałe wartościami, które w rzeczywistym programie mogłyby pochodzić z danych wejściowych użytkownika.
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}if let, else if, else if let i elseJeśli użytkownik określi ulubiony kolor, ten kolor zostanie użyty jako tło. Jeśli nie określono ulubionego koloru i dziś jest wtorek, kolor tła jest zielony. W przeciwnym razie, jeśli użytkownik poda swój wiek jako ciąg znaków i uda nam się go poprawnie sparsować jako liczbę, kolor będzie fioletowy lub pomarańczowy w zależności od wartości liczby. Jeśli żaden z tych warunków nie zostanie spełniony, kolor tła będzie niebieski.
Ta struktura warunkowa pozwala nam obsługiwać złożone wymagania. Z zakodowanymi na stałe wartościami, ten przykład wydrukuje Using purple as the background color.
Widzisz, że if let może również wprowadzać nowe zmienne, które zacieniają istniejące zmienne w taki sam sposób, jak ramiona match: linia if let Ok(age) = age wprowadza nową zmienną age, która zawiera wartość wewnątrz wariantu Ok, zacieniając istniejącą zmienną age. Oznacza to, że musimy umieścić warunek if age > 30 w tym bloku: nie możemy połączyć tych dwóch warunków w if let Ok(age) = age && age > 30. Nowa zmienna age, którą chcemy porównać z 30, nie jest prawidłowa, dopóki nowy zakres nie zacznie się od nawiasu klamrowego.
Wadą stosowania wyrażeń if let jest to, że kompilator nie sprawdza wyczerpująco wszystkich możliwości, w przeciwieństwie do wyrażeń match. Gdybyśmy pominęli ostatni blok else, a tym samym nie obsłużyli niektórych przypadków, kompilator nie ostrzegłby nas o możliwym błędzie logicznym.
Pętle Warunkowe while let
Podobnie jak w przypadku if let, pętla warunkowa while let pozwala na działanie pętli while tak długo, jak wzorzec pasuje. Na Liście 19-4 pokazujemy pętlę while let, która czeka na wiadomości wysyłane między wątkami, ale w tym przypadku sprawdza Result zamiast Option.
fn main() {
let (tx, rx) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for val in [1, 2, 3] {
tx.send(val).unwrap();
}
});
while let Ok(value) = rx.recv() {
println!("{value}");
}
}while let do drukowania wartości tak długo, jak rx.recv() zwraca OkTen przykład wypisuje 1, 2, a następnie 3. Metoda recv pobiera pierwszą wiadomość z odbiornika kanału i zwraca Ok(value). Kiedy po raz pierwszy widzieliśmy recv w Rozdziale 16, bezpośrednio rozpakowaliśmy błąd lub wchodziliśmy z nim w interakcję jako z iteratorem za pomocą pętli for. Jak pokazuje Lista 19-4, możemy jednak również użyć while let, ponieważ metoda recv zwraca Ok za każdym razem, gdy nadejdzie wiadomość, dopóki nadawca istnieje, a następnie generuje Err, gdy strona nadawcy się rozłączy.
Pętle for
W pętli for wartość, która bezpośrednio następuje po słowie kluczowym for, jest wzorcem. Na przykład w for x in y, x jest wzorcem. Lista 19-5 demonstruje, jak użyć wzorca w pętli for do dekonstrukcji, czyli rozłożenia, krotki jako część pętli for.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{value} is at index {index}");
}
}for do dekonstrukcji krotkiKod na Liście 19-5 wypisze następujące informacje:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
Adaptujemy iterator za pomocą metody enumerate tak, aby produkowała ona wartość i indeks dla tej wartości, umieszczone w krotce. Pierwsza wyprodukowana wartość to krotka (0, 'a'). Gdy ta wartość zostanie dopasowana do wzorca (index, value), index będzie 0, a value będzie 'a', drukując pierwszą linię wyjścia.
Parametry Funkcji
Parametry funkcji również mogą być wzorcami. Kod z Listy 19-6, który deklaruje funkcję foo przyjmującą jeden parametr x typu i32, powinien być już znany.
fn foo(x: i32) {
// code goes here
}
fn main() {}Część x to wzorzec! Tak jak w przypadku let, moglibyśmy dopasować krotkę w argumentach funkcji do wzorca. Lista 19-7 rozdziela wartości w krotce, gdy przekazujemy ją do funkcji.
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({x}, {y})");
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}Ten kod wypisuje Current location: (3, 5). Wartości &(3, 5) pasują do wzorca &(x, y), więc x ma wartość 3, a y ma wartość 5.
Możemy również używać wzorców w listach parametrów domknięć w taki sam sposób, jak w listach parametrów funkcji, ponieważ domknięcia są podobne do funkcji, jak omówiono w Rozdziale 13.
Do tej pory widziałeś kilka sposobów użycia wzorców, ale wzorce nie działają tak samo w każdym miejscu, w którym możemy ich użyć. W niektórych miejscach wzorce muszą być nieodrzucalne; w innych okolicznościach mogą być odrzucalne. Następnie omówimy te dwie koncepcje.
Odrzucalność: Czy Wzorzec Może Nie Pasować
Odrzucalność: Czy Wzorzec Może Nie Pasować
Wzorce występują w dwóch formach: odrzucalne i nieodrzucalne. Wzorce, które pasują do każdej możliwej przekazanej wartości, są nieodrzucalne. Przykładem może być x w instrukcji let x = 5;, ponieważ x pasuje do wszystkiego i dlatego nie może się nie dopasować. Wzorce, które mogą nie pasować do pewnej możliwej wartości, są odrzucalne. Przykładem może być Some(x) w wyrażeniu if let Some(x) = a_value, ponieważ jeśli wartość w zmiennej a_value to None, a nie Some, wzorzec Some(x) nie zostanie dopasowany.
Parametry funkcji, instrukcje let i pętle for mogą akceptować tylko wzorce nieodrzucalne, ponieważ program nie może nic znaczącego zrobić, gdy wartości nie pasują. Wyrażenia if let i while let oraz instrukcja let...else akceptują wzorce odrzucalne i nieodrzucalne, ale kompilator ostrzega przed wzorcami nieodrzucalnymi, ponieważ z definicji są przeznaczone do obsługi możliwych błędów: funkcjonalność warunku polega na jego zdolności do działania inaczej w zależności od sukcesu lub porażki.
Ogólnie rzecz biorąc, nie powinieneś martwić się rozróżnieniem między wzorcami odrzucalnymi i nieodrzucalnymi; jednak musisz być zaznajomiony z koncepcją odrzucalności, aby móc reagować, gdy zobaczysz ją w komunikacie o błędzie. W takich przypadkach będziesz musiał zmienić albo wzorzec, albo konstrukcję, z którą używasz wzorca, w zależności od zamierzonego zachowania kodu.
Przyjrzyjmy się przykładowi, co się dzieje, gdy próbujemy użyć wzorca odrzucalnego tam, gdzie Rust wymaga wzorca nieodrzucalnego, i odwrotnie. Lista 19-8 pokazuje instrukcję let, ale dla wzorca określiliśmy Some(x), wzorzec odrzucalny. Jak można się spodziewać, ten kod się nie skompiluje.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}letGdyby some_option_value miało wartość None, nie pasowałoby do wzorca Some(x), co oznacza, że wzorzec jest odrzucalny. Jednak instrukcja let może przyjmować tylko wzorzec nieodrzucalny, ponieważ nie ma niczego ważnego, co kod mógłby zrobić z wartością None. W czasie kompilacji Rust skarży się, że próbowaliśmy użyć wzorca odrzucalnego tam, gdzie wymagany jest wzorzec nieodrzucalny:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Ponieważ nie pokryliśmy (i nie mogliśmy pokryć!) każdej prawidłowej wartości wzorcem Some(x), Rust słusznie zwraca błąd kompilacji.
Jeśli mamy wzorzec odrzucalny tam, gdzie potrzebny jest wzorzec nieodrzucalny, możemy to naprawić, zmieniając kod, który używa wzorca: zamiast używać let, możemy użyć let...else. Wtedy, jeśli wzorzec nie pasuje, kod w nawiasach klamrowych obsłuży wartość. Lista 19-9 pokazuje, jak naprawić kod z Listy 19-8.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value else {
return;
};
}let...else i bloku z wzorcami odrzucalnymi zamiast letDaliśmy kodowi wyjście! Ten kod jest całkowicie poprawny, chociaż oznacza to, że nie możemy użyć wzorca nieodrzucalnego bez otrzymywania ostrzeżenia. Jeśli damy let...else wzorzec, który zawsze będzie pasował, taki jak x, jak pokazano na Liście 19-10, kompilator wyświetli ostrzeżenie.
fn main() {
let x = 5 else {
return;
};
}let...elseRust skarży się, że użycie let...else z wzorcem nieodrzucalnym nie ma sensu:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
Z tego powodu ramiona match muszą używać wzorców odrzucalnych, z wyjątkiem ostatniego ramienia, które powinno pasować do wszystkich pozostałych wartości za pomocą wzorca nieodrzucalnego. Rust pozwala nam używać wzorca nieodrzucalnego w match z tylko jednym ramieniem, ale ta składnia nie jest szczególnie użyteczna i mogłaby być zastąpiona prostszą instrukcją let.
Teraz, gdy wiesz, gdzie używać wzorców i jaka jest różnica między wzorcami odrzucalnymi i nieodrzucalnymi, przejdźmy do omówienia całej składni, której możemy użyć do tworzenia wzorców.
Składnia Wzorców
Składnia Wzorców
W tej sekcji zbieramy całą składnię, która jest prawidłowa we wzorcach, i omawiamy, dlaczego i kiedy warto używać każdej z nich.
Dopasowywanie Literałów
Jak widziałeś w Rozdziale 6, możesz dopasowywać wzorce bezpośrednio do literałów. Poniższy kod przedstawia kilka przykładów:
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("anything"),
}
}Ten kod wypisuje one, ponieważ wartość w x wynosi 1. Ta składnia jest użyteczna, gdy chcesz, aby Twój kod podjął działanie, jeśli otrzyma konkretną wartość.
Dopasowywanie Nazwanych Zmiennych
Nazwane zmienne to nieodrzucalne wzorce, które pasują do dowolnej wartości, i używaliśmy ich wiele razy w tej książce. Jednakże, pojawia się komplikacja, gdy używasz nazwanych zmiennych w wyrażeniach match, if let lub while let. Ponieważ każdy z tych rodzajów wyrażeń rozpoczyna nowy zakres, zmienne zadeklarowane jako część wzorca wewnątrz tych wyrażeń będą zasłaniać te o tej samej nazwie poza konstrukcjami, tak jak to ma miejsce w przypadku wszystkich zmiennych. Na Liście 19-11 deklarujemy zmienną x o wartości Some(5) i zmienną y o wartości 10. Następnie tworzymy wyrażenie match na wartości x. Spójrz na wzorce w ramionach match i println! na końcu, a spróbuj odgadnąć, co kod wydrukuje, zanim uruchomisz ten kod lub przeczytasz dalej.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(y) => println!("Matched, y = {y}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}match z ramieniem, które wprowadza nową zmienną, która zasłania istniejącą zmienną yPrzeanalizujmy, co dzieje się, gdy uruchamia się wyrażenie match. Wzorzec w pierwszym ramieniu match nie pasuje do zdefiniowanej wartości x, więc kod kontynuuje działanie.
Wzorzec w drugim ramieniu match wprowadza nową zmienną o nazwie y, która będzie pasować do dowolnej wartości wewnątrz wartości Some. Ponieważ jesteśmy w nowym zakresie wewnątrz wyrażenia match, jest to nowa zmienna y, a nie y, którą zadeklarowaliśmy na początku z wartością 10. To nowe powiązanie y będzie pasować do wewnętrznej wartości Some w x. Ta wartość to 5, więc wyrażenie dla tego ramienia wykonuje się i wypisuje Matched, y = 5.
Gdyby x było wartością None zamiast Some(5), wzorce w dwóch pierwszych ramionach nie pasowałyby, więc wartość pasowałaby do podkreślenia. Nie wprowadziliśmy zmiennej x do wzorca ramienia podkreślenia, więc x w wyrażeniu jest nadal zewnętrznym x, które nie zostało zacienione. W tym hipotetycznym przypadku match wypisałby Default case, x = None.
Po zakończeniu wyrażenia match, jego zakres się kończy, podobnie jak zakres wewnętrznego y. Ostatnie println! wypisuje at the end: x = Some(5), y = 10.
Aby stworzyć wyrażenie match, które porównuje wartości zewnętrznych x i y, zamiast wprowadzać nową zmienną, która zasłania istniejącą zmienną y, musielibyśmy użyć warunkowego ograniczenia dopasowania. O match guardach porozmawiamy później w sekcji „Dodawanie warunków za pomocą match guardów”.
Dopasowywanie Wielu Wzorców
W wyrażeniach match możesz dopasowywać wiele wzorców za pomocą składni |, która jest operatorem lub wzorca. Na przykład, w poniższym kodzie dopasowujemy wartość x do ramion match, z których pierwsze ma opcję lub, co oznacza, że jeśli wartość x pasuje do którejkolwiek z wartości w tym ramieniu, kod tego ramienia zostanie uruchomiony:
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}Ten kod wypisuje one or two.
Dopasowywanie Zakresów Wartości za pomocą ..=
Składnia ..= pozwala nam dopasowywać do włącznie zakresu wartości. W poniższym kodzie, gdy wzorzec pasuje do którejkolwiek z wartości w danym zakresie, to ramię zostanie wykonane:
fn main() {
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
}Jeśli x wynosi 1, 2, 3, 4 lub 5, pierwsze ramię zostanie dopasowane. Ta składnia jest wygodniejsza dla wielu wartości dopasowania niż używanie operatora | do wyrażenia tej samej idei; gdybyśmy mieli użyć |, musielibyśmy określić 1 | 2 | 3 | 4 | 5. Określanie zakresu jest znacznie krótsze, zwłaszcza jeśli chcemy dopasować, powiedzmy, dowolną liczbę od 1 do 1000!
Kompilator sprawdza w czasie kompilacji, czy zakres nie jest pusty, a ponieważ jedynymi typami, dla których Rust może stwierdzić, czy zakres jest pusty, są char i wartości liczbowe, zakresy są dozwolone tylko z wartościami liczbowymi lub char.
Oto przykład użycia zakresów wartości char:
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("early ASCII letter"),
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}Rust może stwierdzić, że 'c' znajduje się w zakresie pierwszego wzorca i wypisuje early ASCII letter.
Dekonstrukcja w Celu Rozbicia Wartości
Możemy również używać wzorców do dekonstrukcji struktur, wyliczeń i krotek, aby używać różnych części tych wartości. Przejdźmy przez każdą wartość.
Struktury
Lista 19-12 pokazuje strukturę Point z dwoma polami, x i y, które możemy rozdzielić za pomocą wzorca z instrukcją let.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}Ten kod tworzy zmienne a i b, które odpowiadają wartościom pól x i y struktury p. Ten przykład pokazuje, że nazwy zmiennych we wzorcu nie muszą odpowiadać nazwom pól struktury. Jednak często dopasowuje się nazwy zmiennych do nazw pól, aby łatwiej było zapamiętać, które zmienne pochodzą z których pól. Z powodu tego powszechnego użycia i ponieważ pisanie let Point { x: x, y: y } = p; zawiera wiele powtórzeń, Rust ma skrót dla wzorców, które dopasowują pola struktury: wystarczy wymienić nazwę pola struktury, a zmienne utworzone na podstawie wzorca będą miały te same nazwy. Lista 19-13 działa tak samo jak kod z Listy 19-12, ale zmienne utworzone we wzorcu let to x i y zamiast a i b.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}Ten kod tworzy zmienne x i y, które pasują do pól x i y zmiennej p. Wynikiem jest to, że zmienne x i y zawierają wartości ze struktury p.
Możemy również dokonywać dekonstrukcji z użyciem wartości literałowych jako części wzorca struktury, zamiast tworzyć zmienne dla wszystkich pól. Pozwala nam to testować niektóre pola pod kątem określonych wartości, jednocześnie tworząc zmienne do dekonstrukcji pozostałych pól.
Na Liście 19-14 mamy wyrażenie match, które dzieli wartości Point na trzy przypadki: punkty leżące bezpośrednio na osi x (co jest prawdą, gdy y = 0), na osi y (x = 0) lub na żadnej z osi.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}Pierwsze ramię dopasuje każdy punkt leżący na osi x, określając, że pole y pasuje, jeśli jego wartość odpowiada literałowi 0. Wzorzec nadal tworzy zmienną x, której możemy użyć w kodzie dla tego ramienia.
Podobnie, drugie ramię pasuje do każdego punktu na osi y, określając, że pole x pasuje, jeśli jego wartość wynosi 0, i tworzy zmienną y dla wartości pola y. Trzecie ramię nie określa żadnych literałów, więc pasuje do każdego innego Point i tworzy zmienne dla pól x i y.
W tym przykładzie wartość p pasuje do drugiego ramienia dzięki temu, że x zawiera 0, więc ten kod wypisze On the y axis at 7.
Pamiętaj, że wyrażenie match przestaje sprawdzać ramiona, gdy tylko znajdzie pierwszy pasujący wzorzec, więc nawet jeśli Point { x: 0, y: 0 } znajduje się na osi x i osi y, ten kod wydrukowałby tylko On the x axis at 0.
Wyliczenia (Enums)
Dekonstruowaliśmy wyliczenia w tej książce (na przykład Lista 6-5 w Rozdziale 6), ale nie omówiliśmy jeszcze wyraźnie, że wzorzec do dekonstrukcji wyliczenia odpowiada sposobowi definiowania danych przechowywanych w wyliczeniu. Jako przykład, na Liście 19-15 używamy wyliczenia Message z Listy 6-2 i piszemy match z wzorcami, które dekonstruują każdą wewnętrzną wartość.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}Ten kod wypisze Change color to red 0, green 160, and blue 255. Spróbuj zmienić wartość msg, aby zobaczyć, jak działa kod z innych ramion.
Dla wariantów wyliczeniowych bez żadnych danych, takich jak Message::Quit, nie możemy dalej dekonstruować wartości. Możemy dopasować tylko literał Message::Quit, a w tym wzorcu nie ma żadnych zmiennych.
Dla wariantów wyliczeń podobnych do struktur, takich jak Message::Move, możemy użyć wzorca podobnego do wzorca, który określamy w celu dopasowania struktur. Po nazwie wariantu umieszczamy nawiasy klamrowe, a następnie wymieniamy pola ze zmiennymi, tak abyśmy rozdzielili elementy do użycia w kodzie dla tego ramienia. Tutaj używamy skróconej formy, tak jak na Liście 19-13.
Dla wariantów wyliczeniowych typu krotka, takich jak Message::Write, które przechowuje krotkę z jednym elementem, oraz Message::ChangeColor, które przechowuje krotkę z trzema elementami, wzorzec jest podobny do wzorca, który określamy, aby dopasować krotki. Liczba zmiennych we wzorcu musi odpowiadać liczbie elementów w wariancie, który dopasowujemy.
Zagnieżdżone Struktury i Wyliczenia
Do tej pory wszystkie nasze przykłady dotyczyły dopasowywania struktur lub wyliczeń na jednym poziomie, ale dopasowywanie może działać również na zagnieżdżonych elementach! Na przykład, możemy refaktoryzować kod z Listy 19-15, aby obsługiwał kolory RGB i HSV w wiadomości ChangeColor, jak pokazano na Liście 19-16.
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
_ => (),
}
}Wzorzec pierwszego ramienia w wyrażeniu match pasuje do wariantu wyliczeniowego Message::ChangeColor, który zawiera wariant Color::Rgb; następnie wzorzec wiąże się z trzema wewnętrznymi wartościami i32. Wzorzec drugiego ramienia również pasuje do wariantu wyliczeniowego Message::ChangeColor, ale wewnętrzne wyliczenie pasuje zamiast tego do Color::Hsv. Możemy określić te złożone warunki w jednym wyrażeniu match, mimo że biorą w nim udział dwa wyliczenia.
Struktury i Krotki
Możemy mieszać, dopasowywać i zagnieżdżać wzorce dekonstrukcji na jeszcze bardziej złożone sposoby. Poniższy przykład pokazuje skomplikowaną dekonstrukcję, w której zagnieżdżamy struktury i krotki wewnątrz krotki i dekonstruujemy wszystkie wartości pierwotne:
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}Ten kod pozwala nam rozbić złożone typy na ich części składowe, abyśmy mogli osobno używać wartości, które nas interesują.
Dekonstrukcja za pomocą wzorców to wygodny sposób na używanie części wartości, takich jak wartość z każdego pola w strukturze, oddzielnie od siebie.
Ignorowanie Wartości we Wzorcu
Widziałeś, że czasami przydatne jest ignorowanie wartości we wzorcu, na przykład w ostatnim ramieniu match, aby uzyskać catch-all, który faktycznie nic nie robi, ale uwzględnia wszystkie pozostałe możliwe wartości. Istnieje kilka sposobów ignorowania całych wartości lub części wartości we wzorcu: użycie wzorca _ (który już widziałeś), użycie wzorca _ w innym wzorcu, użycie nazwy zaczynającej się od podkreślenia lub użycie .., aby zignorować pozostałe części wartości. Przyjrzyjmy się, jak i dlaczego używać każdego z tych wzorców.
Cała Wartość za pomocą _
Używaliśmy podkreślenia jako wzorca wieloznacznego, który będzie pasował do dowolnej wartości, ale nie będzie wiązał się z wartością. Jest to szczególnie przydatne jako ostatnie ramię w wyrażeniu match, ale możemy go również używać w dowolnym wzorcu, w tym w parametrach funkcji, jak pokazano na Liście 19-17.
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {y}");
}
fn main() {
foo(3, 4);
}_ w sygnaturze funkcjiTen kod całkowicie zignoruje wartość 3 przekazaną jako pierwszy argument i wydrukuje This code only uses the y parameter: 4.
W większości przypadków, gdy nie potrzebujesz już konkretnego parametru funkcji, zmieniłbyś sygnaturę tak, aby nie zawierała nieużywanego parametru. Ignorowanie parametru funkcji może być szczególnie przydatne w przypadkach, gdy na przykład implementujesz cechę, gdy potrzebujesz określonej sygnatury typu, ale ciało funkcji w Twojej implementacji nie potrzebuje jednego z parametrów. Wtedy unikasz ostrzeżenia kompilatora o nieużywanych parametrach funkcji, tak jakbyś użył nazwy zamiast.
Fragmenty Wartości z Zagnieżdżonym _
Możemy również używać _ wewnątrz innego wzorca, aby zignorować tylko część wartości, na przykład, gdy chcemy przetestować tylko część wartości, ale nie mamy zastosowania dla pozostałych części w odpowiadającym kodzie, który chcemy uruchomić. Lista 19-18 pokazuje kod odpowiedzialny za zarządzanie wartością ustawienia. Wymagania biznesowe są takie, że użytkownikowi nie wolno nadpisywać istniejącej dostosowanej wartości ustawienia, ale może anulować ustawienie i nadać mu wartość, jeśli jest ono obecnie niezdefiniowane.
fn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {setting_value:?}");
}Some, gdy nie musimy używać wartości wewnątrz SomeTen kod wypisze Can't overwrite an existing customized value, a następnie setting is Some(5). W pierwszym ramieniu match nie musimy dopasowywać ani używać wartości wewnątrz żadnego z wariantów Some, ale musimy sprawdzić przypadek, gdy setting_value i new_setting_value są wariantem Some. W takim przypadku wypisujemy powód, dla którego setting_value nie zostanie zmienione, i nie zostanie ono zmienione.
We wszystkich innych przypadkach (jeśli setting_value lub new_setting_value jest None), wyrażonych wzorcem _ w drugim ramieniu, chcemy, aby new_setting_value stało się setting_value.
Możemy również używać podkreśleń w wielu miejscach w jednym wzorcu, aby ignorować określone wartości. Lista 19-19 pokazuje przykład ignorowania drugiej i czwartej wartości w krotce pięciu elementów.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {first}, {third}, {fifth}");
}
}
}Ten kod wypisze Some numbers: 2, 8, 32, a wartości 4 i 16 zostaną zignorowane.
Nieużywana Zmienna, Zaczynająca Się od _
Jeśli utworzysz zmienną, ale nie użyjesz jej nigdzie, Rust zazwyczaj wyświetli ostrzeżenie, ponieważ nieużywana zmienna może być błędem. Czasami jednak przydatne jest stworzenie zmiennej, której jeszcze nie użyjesz, na przykład podczas prototypowania lub rozpoczynania projektu. W tej sytuacji możesz powiedzieć Rust, aby nie ostrzegał Cię o nieużywanej zmiennej, zaczynając nazwę zmiennej od podkreślenia. Na Liście 19-20 tworzymy dwie nieużywane zmienne, ale po skompilowaniu tego kodu powinniśmy otrzymać ostrzeżenie tylko o jednej z nich.
fn main() {
let _x = 5;
let y = 10;
}Tutaj otrzymujemy ostrzeżenie o nieużywaniu zmiennej y, ale nie otrzymujemy ostrzeżenia o nieużywaniu _x.
Zauważ, że istnieje subtelna różnica między używaniem samego _ a używaniem nazwy zaczynającej się od podkreślenia. Składnia _x nadal wiąże wartość ze zmienną, podczas gdy _ w ogóle nie wiąże. Aby pokazać przypadek, w którym ta różnica ma znaczenie, Lista 19-21 dostarczy nam błędu.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}Otrzymamy błąd, ponieważ wartość s zostanie nadal przeniesiona do _s, co uniemożliwi nam ponowne użycie s. Jednak użycie samego podkreślenia nigdy nie wiąże się z wartością. Lista 19-22 skompiluje się bez błędów, ponieważ s nie zostanie przeniesione do _.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{s:?}");
}Ten kod działa bez zarzutu, ponieważ nigdy nie wiążemy s z niczym; nie zostaje przeniesione.
Pozostałe Części Wartości za pomocą ..
W przypadku wartości, które mają wiele części, możemy użyć składni .., aby użyć konkretnych części i zignorować resztę, unikając konieczności wymieniania podkreśleń dla każdej ignorowanej wartości. Wzorzec .. ignoruje wszystkie części wartości, których nie dopasowaliśmy jawnie w pozostałej części wzorca. Na Liście 19-23 mamy strukturę Point, która przechowuje współrzędną w trójwymiarowej przestrzeni. W wyrażeniu match chcemy operować tylko na współrzędnej x i ignorować wartości w polach y i z.
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {x}"),
}
}Point oprócz x za pomocą ..Wypisujemy wartość x, a następnie po prostu dodajemy wzorzec ... Jest to szybsze niż konieczność wypisywania y: _ i z: _, szczególnie gdy pracujemy ze strukturami, które mają wiele pól w sytuacjach, gdy tylko jedno lub dwa pola są istotne.
Składnia .. rozszerzy się do tylu wartości, ile potrzebuje. Lista 19-24 pokazuje, jak używać .. z krotką.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}W tym kodzie pierwsza i ostatnia wartość są dopasowywane do first i last. .. dopasuje i zignoruje wszystko pośrodku.
Jednakże, używanie .. musi być jednoznaczne. Jeśli nie jest jasne, które wartości są przeznaczone do dopasowania, a które powinny zostać zignorowane, Rust zgłosi błąd. Lista 19-25 pokazuje przykład niejednoznacznego użycia .., dlatego nie skompiluje się.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}.. w sposób niejednoznacznyKiedy skompilujemy ten przykład, otrzymamy ten błąd:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Rust nie jest w stanie określić, ile wartości w krotce należy zignorować przed dopasowaniem wartości do second, a następnie ile dalszych wartości należy zignorować. Ten kod mógłby oznaczać, że chcemy zignorować 2, powiązać second z 4, a następnie zignorować 8, 16 i 32; albo że chcemy zignorować 2 i 4, powiązać second z 8, a następnie zignorować 16 i 32; i tak dalej. Nazwa zmiennej second nie oznacza niczego specjalnego dla Rust, więc otrzymujemy błąd kompilatora, ponieważ użycie .. w dwóch miejscach w ten sposób jest niejednoznaczne.
Dodawanie Warunków za pomocą Match Guardów
Match guard to dodatkowy warunek if, określony po wzorcu w ramieniu match, który również musi zostać spełniony, aby to ramię zostało wybrane. Match guardy są przydatne do wyrażania bardziej złożonych idei niż sam wzorzec. Zauważ jednak, że są one dostępne tylko w wyrażeniach match, a nie w wyrażeniach if let ani while let.
Warunek może używać zmiennych utworzonych we wzorcu. Lista 19-26 pokazuje match, gdzie pierwsze ramię ma wzorzec Some(x) i dodatkowo match guard if x % 2 == 0 (który będzie true, jeśli liczba jest parzysta).
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {x} is even"),
Some(x) => println!("The number {x} is odd"),
None => (),
}
}Ten przykład wypisze The number 4 is even. Gdy num jest porównywane z wzorcem w pierwszym ramieniu, pasuje, ponieważ Some(4) pasuje do Some(x). Następnie match guard sprawdza, czy reszta z dzielenia x przez 2 jest równa 0, a ponieważ tak jest, wybrane zostaje pierwsze ramię.
Gdyby num było Some(5) zamiast tego, match guard w pierwszym ramieniu byłby false, ponieważ reszta z dzielenia 5 przez 2 wynosi 1, co nie jest równe 0. Rust następnie przeszedłby do drugiego ramienia, które by pasowało, ponieważ drugie ramię nie ma match guarda i dlatego pasuje do dowolnego wariantu Some.
Nie ma sposobu, aby wyrazić warunek if x % 2 == 0 w ramach wzorca, więc match guard daje nam możliwość wyrażenia tej logiki. Wadą tej dodatkowej ekspresywności jest to, że kompilator nie próbuje sprawdzać kompletności, gdy w grę wchodzą wyrażenia match guard.
Podczas omawiania Listy 19-11, wspomnieliśmy, że moglibyśmy użyć match guardów do rozwiązania naszego problemu z zasłanianiem wzorców. Przypomnijmy, że stworzyliśmy nową zmienną wewnątrz wzorca w wyrażeniu match zamiast używać zmiennej poza match. Ta nowa zmienna oznaczała, że nie mogliśmy testować wartości zmiennej zewnętrznej. Lista 19-27 pokazuje, jak możemy użyć match guarda, aby naprawić ten problem.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {n}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}Ten kod wydrukuje teraz Default case, x = Some(5). Wzorzec w drugim ramieniu match nie wprowadza nowej zmiennej y, która zasłaniałaby zewnętrzną y, co oznacza, że możemy użyć zewnętrznej y w match guardzie. Zamiast określać wzorzec jako Some(y), co zasłoniłoby zewnętrzną y, określamy Some(n). Tworzy to nową zmienną n, która niczego nie zasłania, ponieważ poza match nie ma zmiennej n.
Match guard if n == y nie jest wzorcem i dlatego nie wprowadza nowych zmiennych. To y jest zewnętrznym y, a nie nowym y je zasłaniającym, i możemy szukać wartości, która ma taką samą wartość jak zewnętrzne y, porównując n z y.
Możesz również użyć operatora lub | w match guardzie, aby określić wiele wzorców; warunek match guarda będzie miał zastosowanie do wszystkich wzorców. Lista 19-28 pokazuje pierwszeństwo przy łączeniu wzorca używającego | z match guardem. Ważną częścią tego przykładu jest to, że match guard if y ma zastosowanie do 4, 5 i 6, mimo że może wydawać się, że if y ma zastosowanie tylko do 6.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}
}Warunek dopasowania stwierdza, że ramię pasuje tylko wtedy, gdy wartość x jest równa 4, 5 lub 6 i jeśli y jest true. Kiedy ten kod się uruchamia, wzorzec pierwszego ramienia pasuje, ponieważ x wynosi 4, ale match guard if y jest false, więc pierwsze ramię nie zostaje wybrane. Kod przechodzi do drugiego ramienia, które pasuje, a program wypisuje no. Powodem jest to, że warunek if ma zastosowanie do całego wzorca 4 | 5 | 6, a nie tylko do ostatniej wartości 6. Innymi słowy, pierwszeństwo match guarda w stosunku do wzorca zachowuje się w ten sposób:
(4 | 5 | 6) if y => ...
zamiast tego:
4 | 5 | (6 if y) => ...
Po uruchomieniu kodu zachowanie pierwszeństwa jest oczywiste: gdyby match guard był stosowany tylko do ostatniej wartości na liście wartości określonych za pomocą operatora |, ramię pasowałoby, a program wydrukowałby yes.
Używanie Wiązań @
Operator at @ pozwala nam utworzyć zmienną, która przechowuje wartość w tym samym czasie, gdy testujemy tę wartość pod kątem dopasowania wzorca. Na Liście 19-29 chcemy sprawdzić, czy pole id w Message::Hello mieści się w zakresie 3..=7. Chcemy również powiązać wartość ze zmienną id, aby móc jej użyć w kodzie skojarzonym z ramieniem.
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id @ 3..=7 } => {
println!("Found an id in range: {id}")
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {id}"),
}
}@ do związania się z wartością we wzorcu, jednocześnie ją testującTen przykład wydrukuje Found an id in range: 5. Określając id @ przed zakresem 3..=7, przechwytujemy dowolną wartość, która pasuje do zakresu, w zmiennej nazwanej id, jednocześnie testując, czy wartość pasuje do wzorca zakresu.
W drugim ramieniu, gdzie we wzorcu mamy określony tylko zakres, kod skojarzony z ramieniem nie ma zmiennej zawierającej faktyczną wartość pola id. Wartość pola id mogła wynosić 10, 11 lub 12, ale kod, który towarzyszy temu wzorcowi, nie wie, która to jest. Kod wzorca nie jest w stanie użyć wartości z pola id, ponieważ nie zapisaliśmy wartości id w zmiennej.
W ostatnim ramieniu, gdzie określiliśmy zmienną bez zakresu, mamy dostępną wartość do użycia w kodzie ramienia w zmiennej o nazwie id. Powodem jest to, że użyliśmy skróconej składni pól struktury. Ale w tym ramieniu nie zastosowaliśmy żadnego testu do wartości w polu id, tak jak zrobiliśmy to w dwóch pierwszych ramionach: dowolna wartość pasowałaby do tego wzorca.
Używanie @ pozwala nam testować wartość i zapisywać ją w zmiennej w ramach jednego wzorca.
Podsumowanie
Wzorce Rust są bardzo przydatne w rozróżnianiu różnych rodzajów danych. Używane w wyrażeniach match, Rust zapewnia, że Twoje wzorce obejmują każdą możliwą wartość, w przeciwnym razie Twój program się nie skompiluje. Wzorce w instrukcjach let i parametrach funkcji czynią te konstrukcje bardziej użytecznymi, umożliwiając dekonstrukcję wartości na mniejsze części i przypisywanie tych części do zmiennych. Możemy tworzyć proste lub złożone wzorce, aby sprostać naszym potrzebom.
Następnie, w przedostatnim rozdziale książki, przyjrzymy się niektórym zaawansowanym aspektom różnych funkcji Rust.
Zaawansowane Funkcje
Do tej pory poznałeś najczęściej używane części języka programowania Rust. Zanim przejdziemy do kolejnego projektu w Rozdziale 21, przyjrzymy się kilku aspektom języka, z którymi możesz się od czasu do czasu spotkać, ale których być może nie będziesz używać na co dzień. Możesz używać tego rozdziału jako odniesienia, gdy napotkasz jakieś niewiadome. Funkcje omówione tutaj są przydatne w bardzo specyficznych sytuacjach. Chociaż możesz nie sięgać po nie często, chcemy upewnić się, że rozumiesz wszystkie funkcje, które Rust ma do zaoferowania.
W tym rozdziale omówimy:
- Niebezpieczny Rust: Jak zrezygnować z niektórych gwarancji Rust i wziąć odpowiedzialność za ręczne ich utrzymanie
- Zaawansowane traity: Typy stowarzyszone, domyślne parametry typów, w pełni kwalifikowana składnia, supertraity i wzorzec newtype w odniesieniu do traitów
- Zaawansowane typy: Więcej o wzorcu newtype, aliasach typów, typie nigdy i typach o dynamicznym rozmiarze
- Zaawansowane funkcje i domknięcia: Wskaźniki funkcji i zwracanie domknięć
- Makrodefinicje: Sposoby definiowania kodu, który definiuje więcej kodu w czasie kompilacji
To prawdziwa paleta funkcji Rust, w której każdy znajdzie coś dla siebie! Zanurzmy się!
Niebezpieczny Rust
Niebezpieczny Rust
Wszystkie omawiane do tej pory kody miały gwarancje bezpieczeństwa pamięci Rust egzekwowane w czasie kompilacji. Jednak Rust ma w sobie drugi, ukryty język, który nie egzekwuje tych gwarancji bezpieczeństwa pamięci: nazywa się go niebezpiecznym Rustem i działa dokładnie tak samo jak zwykły Rust, ale daje nam dodatkowe supermoce.
Niebezpieczny Rust istnieje, ponieważ z natury analiza statyczna jest konserwatywna. Kiedy kompilator próbuje określić, czy kod spełnia gwarancje, lepiej jest, aby odrzucił niektóre prawidłowe programy, niż zaakceptował niektóre nieprawidłowe programy. Chociaż kod może być w porządku, jeśli kompilator Rust nie ma wystarczających informacji, aby być pewnym, odrzuci kod. W takich przypadkach możesz użyć kodu niebezpiecznego, aby powiedzieć kompilatorowi: „Zaufaj mi, wiem, co robię”. Ostrzegamy jednak, że używasz niebezpiecznego Rust na własne ryzyko: jeśli użyjesz kodu niebezpiecznego niepoprawnie, mogą wystąpić problemy z powodu niebezpieczeństwa pamięci, takie jak dereferencja wskaźnika null.
Innym powodem, dla którego Rust ma swoje niebezpieczne alter ego, jest to, że podstawowy sprzęt komputerowy jest z natury niebezpieczny. Gdyby Rust nie pozwalał na wykonywanie niebezpiecznych operacji, nie można by wykonywać pewnych zadań. Rust musi pozwalać na programowanie systemów niskiego poziomu, takie jak bezpośrednia interakcja z systemem operacyjnym, a nawet pisanie własnego systemu operacyjnego. Praca z programowaniem systemów niskiego poziomu jest jednym z celów języka. Przyjrzyjmy się, co możemy zrobić z niebezpiecznym Rust i jak to zrobić.
Wykonywanie Niebezpiecznych Supermocy
Aby przełączyć się na niebezpieczny Rust, użyj słowa kluczowego unsafe, a następnie rozpocznij nowy blok, który zawiera niebezpieczny kod. W niebezpiecznym Rust możesz wykonać pięć akcji, których nie możesz w bezpiecznym Rust, które nazywamy niebezpiecznymi supermocami. Te supermoce obejmują zdolność do:
- Dereferencji surowego wskaźnika.
- Wywołania niebezpiecznej funkcji lub metody.
- Dostępu lub modyfikacji zmiennej statycznej zmiennej.
- Implementacji niebezpiecznej cechy.
- Dostępu do pól
unionów.
Ważne jest, aby zrozumieć, że unsafe nie wyłącza sprawdzania pożyczania (borrow checker) ani nie wyłącza żadnych innych kontroli bezpieczeństwa Rust: jeśli użyjesz referencji w kodzie niebezpiecznym, nadal będzie ona sprawdzana. Słowo kluczowe unsafe daje jedynie dostęp do tych pięciu funkcji, które następnie nie są sprawdzane przez kompilator pod kątem bezpieczeństwa pamięci. Nadal uzyskasz pewien stopień bezpieczeństwa wewnątrz bloku unsafe.
Ponadto, unsafe nie oznacza, że kod wewnątrz bloku jest koniecznie niebezpieczny lub że na pewno będzie miał problemy z bezpieczeństwem pamięci: intencją jest, aby jako programista zapewnił, że kod wewnątrz bloku unsafe będzie miał dostęp do pamięci w prawidłowy sposób.
Ludzie są omylni i błędy się zdarzą, ale wymagając, aby te pięć niebezpiecznych operacji znajdowało się w blokach opatrzonych adnotacją unsafe, będziesz wiedzieć, że wszelkie błędy związane z bezpieczeństwem pamięci muszą znajdować się w bloku unsafe. Pamiętaj, aby bloki unsafe były małe; będziesz za to wdzięczny później, gdy będziesz badać błędy pamięci.
Aby jak najbardziej izolować niebezpieczny kod, najlepiej jest umieścić go w bezpiecznej abstrakcji i udostępnić bezpieczne API, co omówimy później w rozdziale, gdy będziemy badać niebezpieczne funkcje i metody. Części biblioteki standardowej są implementowane jako bezpieczne abstrakcje nad niebezpiecznym kodem, który został poddany audytowi. Opakowanie niebezpiecznego kodu w bezpieczną abstrakcję zapobiega wyciekaniu użycia unsafe do wszystkich miejsc, w których Ty lub Twoi użytkownicy moglibyście chcieć użyć funkcjonalności zaimplementowanej za pomocą kodu unsafe, ponieważ użycie bezpiecznej abstrakcji jest bezpieczne.
Przyjrzyjmy się z kolei każdej z pięciu niebezpiecznych supermocy. Przyjrzymy się również niektórym abstrakcjom, które zapewniają bezpieczny interfejs do niebezpiecznego kodu.
Dereferencja Surowego Wskaźnika
W Rozdziale 4, w sekcji „Wiszące referencje”, wspomnieliśmy, że kompilator zapewnia, że referencje są zawsze prawidłowe. Niebezpieczny Rust ma dwa nowe typy zwane surowymi wskaźnikami, które są podobne do referencji. Podobnie jak referencje, surowe wskaźniki mogą być niemodyfikowalne lub modyfikowalne i są zapisywane odpowiednio jako *const T i *mut T. Gwiazdka nie jest operatorem dereferencji; jest częścią nazwy typu. W kontekście surowych wskaźników, niemodyfikowalne oznacza, że wskaźnik nie może być bezpośrednio przypisany po dereferencji.
Różniące się od referencji i inteligentnych wskaźników, surowe wskaźniki:
- Mogą ignorować zasady pożyczania, posiadając zarówno niemodyfikowalne, jak i modyfikowalne wskaźniki, lub wiele modyfikowalnych wskaźników do tej samej lokalizacji
- Nie mają gwarancji, że wskazują na prawidłową pamięć
- Mogą być null
- Nie implementują żadnego automatycznego czyszczenia
Rezygnując z egzekwowania tych gwarancji przez Rust, możesz zrezygnować z gwarantowanego bezpieczeństwa w zamian za większą wydajność lub możliwość współpracy z innym językiem lub sprzętem, gdzie gwarancje Rust nie mają zastosowania.
Lista 20-1 pokazuje, jak utworzyć niemodyfikowalny i modyfikowalny surowy wskaźnik.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}Zauważ, że w tym kodzie nie używamy słowa kluczowego unsafe. Możemy tworzyć surowe wskaźniki w bezpiecznym kodzie; po prostu nie możemy dereferencjonować surowych wskaźników poza blokiem unsafe, jak zobaczysz za chwilę.
Stworzyliśmy surowe wskaźniki za pomocą operatorów surowego pożyczania: &raw const num tworzy niemodyfikowalny surowy wskaźnik *const i32, a &raw mut num tworzy modyfikowalny surowy wskaźnik *mut i32. Ponieważ stworzyliśmy je bezpośrednio ze zmiennej lokalnej, wiemy, że te konkretne surowe wskaźniki są prawidłowe, ale nie możemy zakładać tego samego o każdym surowym wskaźniku.
Aby to zademonstrować, następnie stworzymy surowy wskaźnik, którego ważności nie możemy być tak pewni, używając słowa kluczowego as do rzutowania wartości zamiast operatora surowego pożyczenia. Lista 20-2 pokazuje, jak stworzyć surowy wskaźnik do dowolnej lokalizacji w pamięci. Próba użycia dowolnej pamięci jest niezdefiniowana: pod tym adresem mogą być dane lub nie, kompilator może zoptymalizować kod tak, że nie ma dostępu do pamięci, lub program może zakończyć się błędem segmentacji. Zazwyczaj nie ma dobrego powodu do pisania takiego kodu, zwłaszcza w przypadkach, gdy zamiast tego można użyć operatora surowego pożyczenia, ale jest to możliwe.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}Przypomnij sobie, że możemy tworzyć surowe wskaźniki w bezpiecznym kodzie, ale nie możemy ich dereferencjonować i odczytywać wskazywanych danych. Na Liście 20-3 używamy operatora dereferencji * na surowym wskaźniku, co wymaga bloku unsafe.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}unsafeTworzenie wskaźnika nie szkodzi; dopiero gdy próbujemy uzyskać dostęp do wartości, na którą wskazuje, możemy skończyć z nieprawidłową wartością.
Zauważ również, że na Liście 20-1 i 20-3 stworzyliśmy surowe wskaźniki *const i32 i *mut i32, które oba wskazywały na tę samą lokalizację w pamięci, gdzie przechowywany jest num. Gdybyśmy zamiast tego spróbowali stworzyć niemodyfikowalną i modyfikowalną referencję do num, kod nie skompilowałby się, ponieważ zasady własności Rust nie pozwalają na jednoczesne istnienie modyfikowalnej referencji i niemodyfikowalnych referencji. Z surowymi wskaźnikami możemy stworzyć modyfikowalny wskaźnik i niemodyfikowalny wskaźnik do tej samej lokalizacji i zmieniać dane za pomocą modyfikowalnego wskaźnika, potencjalnie tworząc wyścig danych. Bądź ostrożny!
Przy wszystkich tych niebezpieczeństwach, dlaczego w ogóle miałbyś używać surowych wskaźników? Jednym z głównych przypadków użycia jest interakcja z kodem C, jak zobaczysz w następnej sekcji. Innym przypadkiem jest budowanie bezpiecznych abstrakcji, których sprawdzający pożyczanie nie rozumie. Przedstawimy niebezpieczne funkcje, a następnie przyjrzymy się przykładowi bezpiecznej abstrakcji, która używa niebezpiecznego kodu.
Wywoływanie Niebezpiecznej Funkcji lub Metody
Drugi rodzaj operacji, którą można wykonać w bloku unsafe, to wywołanie niebezpiecznych funkcji. Niebezpieczne funkcje i metody wyglądają dokładnie tak samo jak zwykłe funkcje i metody, ale mają dodatkowe unsafe przed resztą definicji. Słowo kluczowe unsafe w tym kontekście wskazuje, że funkcja ma wymagania, które musimy spełnić, gdy ją wywołujemy, ponieważ Rust nie może zagwarantować, że spełniliśmy te wymagania. Wywołując niebezpieczną funkcję w bloku unsafe, mówimy, że przeczytaliśmy dokumentację tej funkcji i bierzemy odpowiedzialność za przestrzeganie jej kontraktów.
Oto niebezpieczna funkcja o nazwie dangerous, która nic nie robi w swoim ciele:
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}Musimy wywołać funkcję dangerous w osobnym bloku unsafe. Jeśli spróbujemy wywołać dangerous bez bloku unsafe, otrzymamy błąd:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Dzięki blokowi unsafe zapewniamy Rust, że przeczytaliśmy dokumentację funkcji, rozumiemy, jak jej właściwie używać, i zweryfikowaliśmy, że spełniamy kontrakt funkcji.
Aby wykonywać niebezpieczne operacje w ciele funkcji unsafe, nadal musisz użyć bloku unsafe, tak jak w zwykłej funkcji, a kompilator ostrzeże Cię, jeśli zapomnisz. Pomaga to nam utrzymywać bloki unsafe tak małe, jak to możliwe, ponieważ operacje niebezpieczne mogą nie być potrzebne w całym ciele funkcji.
Tworzenie Bezpiecznej Abstrakcji nad Niebezpiecznym Kodem
To, że funkcja zawiera niebezpieczny kod, nie oznacza, że musimy oznaczyć całą funkcję jako niebezpieczną. W rzeczywistości, opakowywanie niebezpiecznego kodu w bezpieczną funkcję jest powszechną abstrakcją. Jako przykład, przeanalizujmy funkcję split_at_mut z biblioteki standardowej, która wymaga pewnego niebezpiecznego kodu. Zbadamy, jak moglibyśmy ją zaimplementować. Ta bezpieczna metoda jest zdefiniowana dla zmiennych wycinków: bierze jeden wycinek i tworzy z niego dwa, dzieląc wycinek na indeksie podanym jako argument. Lista 20-4 pokazuje, jak używać split_at_mut.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}split_at_mutNie możemy zaimplementować tej funkcji używając wyłącznie bezpiecznego Rust. Próba mogłaby wyglądać mniej więcej jak Lista 20-5, która się nie skompiluje. Dla uproszczenia, zaimplementujemy split_at_mut jako funkcję, a nie metodę, i tylko dla wycinków wartości i32, a nie dla generycznego typu T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut używając wyłącznie bezpiecznego RustTa funkcja najpierw pobiera całkowitą długość wycinka. Następnie sprawdza, czy indeks podany jako parametr mieści się w wycinku, sprawdzając, czy jest mniejszy lub równy długości. Asercja oznacza, że jeśli przekażemy indeks większy niż długość do podziału wycinka, funkcja spanikuje, zanim spróbuje użyć tego indeksu.
Następnie zwracamy dwa modyfikowalne wycinki w krotce: jeden od początku oryginalnego wycinka do indeksu mid i drugi od mid do końca wycinka.
Kiedy spróbujemy skompilować kod z Listy 20-5, otrzymamy błąd:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Sprawdzający pożyczanie Rust nie może zrozumieć, że pożyczamy różne części wycinka; wie tylko, że pożyczamy z tego samego wycinka dwa razy. Pożyczanie różnych części wycinka jest zasadniczo w porządku, ponieważ te dwa wycinki nie nakładają się na siebie, ale Rust nie jest na tyle sprytny, aby to wiedzieć. Kiedy wiemy, że kod jest w porządku, ale Rust nie, nadszedł czas, aby sięgnąć po niebezpieczny kod.
Lista 20-6 pokazuje, jak użyć bloku unsafe, surowego wskaźnika i kilku wywołań niebezpiecznych funkcji, aby implementacja split_at_mut działała.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mutPrzypomnij sobie z sekcji „Typ wycinka” w Rozdziale 4, że wycinek jest wskaźnikiem do pewnych danych i długością wycinka. Używamy metody len, aby uzyskać długość wycinka, i metody as_mut_ptr, aby uzyskać dostęp do surowego wskaźnika wycinka. W tym przypadku, ponieważ mamy modyfikowalny wycinek wartości i32, as_mut_ptr zwraca surowy wskaźnik typu *mut i32, który zapisaliśmy w zmiennej ptr.
Utrzymujemy asercję, że indeks mid znajduje się w zakresie wycinka. Następnie przechodzimy do kodu niebezpiecznego: funkcja slice::from_raw_parts_mut przyjmuje surowy wskaźnik i długość i tworzy wycinek. Używamy tej funkcji do stworzenia wycinka, który zaczyna się od ptr i ma długość mid elementów. Następnie wywołujemy metodę add na ptr z mid jako argumentem, aby uzyskać surowy wskaźnik, który zaczyna się na mid, i tworzymy wycinek używając tego wskaźnika i pozostałej liczby elementów po mid jako długości.
Funkcja slice::from_raw_parts_mut jest niebezpieczna, ponieważ przyjmuje surowy wskaźnik i musi ufać, że ten wskaźnik jest prawidłowy. Metoda add na surowych wskaźnikach jest również niebezpieczna, ponieważ musi ufać, że lokalizacja offsetu jest również prawidłowym wskaźnikiem. Dlatego musieliśmy umieścić blok unsafe wokół naszych wywołań slice::from_raw_parts_mut i add, aby móc je wywołać. Patrząc na kod i dodając asercję, że mid musi być mniejsze lub równe len, możemy stwierdzić, że wszystkie surowe wskaźniki użyte w bloku unsafe będą prawidłowe i będą wskazywać na dane wewnątrz wycinka. Jest to dopuszczalne i odpowiednie użycie unsafe.
Zauważ, że nie musimy oznaczać wynikowej funkcji split_at_mut jako unsafe, a możemy wywołać tę funkcję z bezpiecznego Rust. Stworzyliśmy bezpieczną abstrakcję dla niebezpiecznego kodu z implementacją funkcji, która używa kodu unsafe w bezpieczny sposób, ponieważ tworzy tylko prawidłowe wskaźniki z danych, do których ta funkcja ma dostęp.
W przeciwieństwie do tego, użycie slice::from_raw_parts_mut na Liście 20-7 prawdopodobnie spowodowałoby awarię programu, gdy wycinek zostałby użyty. Ten kod pobiera dowolną lokalizację w pamięci i tworzy wycinek o długości 10 000 elementów.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}Nie posiadamy pamięci w tej dowolnej lokalizacji i nie ma gwarancji, że wycinek, który ten kod tworzy, zawiera prawidłowe wartości i32. Próba użycia values tak, jakby był to prawidłowy wycinek, prowadzi do niezdefiniowanego zachowania.
Używanie funkcji extern do wywoływania zewnętrznego kodu
Czasami kod w Rust może potrzebować interakcji z kodem napisanym w innym języku. W tym celu Rust posiada słowo kluczowe extern, które ułatwia tworzenie i używanie interfejsu funkcji obcych (FFI), czyli sposobu, w jaki język programowania może definiować funkcje i umożliwiać innemu (obcemu) językowi programowania wywoływanie tych funkcji.
Lista 20-8 demonstruje, jak skonfigurować integrację z funkcją abs z biblioteki standardowej C. Funkcje zadeklarowane w blokach extern są zazwyczaj niebezpieczne do wywoływania z kodu Rust, dlatego bloki extern muszą być również oznaczone jako unsafe. Powodem jest to, że inne języki nie egzekwują zasad i gwarancji Rust, a Rust nie może ich sprawdzić, więc odpowiedzialność za zapewnienie bezpieczeństwa spoczywa na programiście.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}extern zdefiniowanej w innym językuW bloku unsafe extern "C" wymieniamy nazwy i sygnatury funkcji zewnętrznych z innego języka, które chcemy wywołać. Część "C" definiuje, który interfejs binarny aplikacji (ABI) używa funkcja zewnętrzna: ABI definiuje, jak wywołać funkcję na poziomie asemblera. ABI "C" jest najpopularniejsze i jest zgodne z ABI języka programowania C. Informacje o wszystkich ABI obsługiwanych przez Rust są dostępne w referencji Rust.
Każdy element zadeklarowany w bloku unsafe extern jest domyślnie niebezpieczny. Jednak niektóre funkcje FFI są bezpieczne do wywołania. Na przykład funkcja abs z biblioteki standardowej C nie ma żadnych ograniczeń bezpieczeństwa pamięci i wiemy, że można ją wywołać z dowolną i32. W takich przypadkach możemy użyć słowa kluczowego safe, aby powiedzieć, że ta konkretna funkcja jest bezpieczna do wywołania, nawet jeśli znajduje się w bloku unsafe extern. Po dokonaniu tej zmiany, wywołanie jej nie wymaga już bloku unsafe, jak pokazano na Liście 20-9.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("Absolute value of -3 according to C: {}", abs(-3));
}safe w bloku unsafe extern i bezpieczne jej wywoływanieOznaczenie funkcji jako safe nie czyni jej z natury bezpieczną! Zamiast tego, jest to obietnica, którą składasz Rust, że jest bezpieczna. Nadal Twoim obowiązkiem jest upewnienie się, że ta obietnica jest dotrzymana!
Wywoływanie funkcji Rust z innych języków
Możemy również użyć extern do stworzenia interfejsu, który pozwala innym językom wywoływać funkcje Rust. Zamiast tworzyć cały blok extern, dodajemy słowo kluczowe extern i określamy ABI do użycia tuż przed słowem kluczowym fn dla odpowiedniej funkcji. Musimy również dodać adnotację #[unsafe(no_mangle)], aby powiedzieć kompilatorowi Rust, aby nie zmieniał nazwy tej funkcji. Mangling to proces, w którym kompilator zmienia nazwę, którą nadaliśmy funkcji, na inną nazwę, która zawiera więcej informacji dla innych części procesu kompilacji, ale jest mniej czytelna dla człowieka. Każdy kompilator języka programowania nieco inaczej zniekształca nazwy, więc aby funkcja Rust mogła być nazwana przez inne języki, musimy wyłączyć zniekształcanie nazw przez kompilator Rust. Jest to niebezpieczne, ponieważ bez wbudowanego zniekształcania mogą występować kolizje nazw w bibliotekach, więc naszym obowiązkiem jest upewnienie się, że wybrana nazwa jest bezpieczna do eksportu bez zniekształcania.
W poniższym przykładzie udostępniamy funkcję call_from_c z kodu C, po skompilowaniu jej do biblioteki współdzielonej i połączeniu z C:
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
To użycie extern wymaga unsafe tylko w atrybucie, a nie w bloku extern.
Dostęp do Zmiennej Statycznej Modyfikowalnej lub Jej Modyfikowanie
W tej książce nie mówiliśmy jeszcze o zmiennych globalnych, które Rust obsługuje, ale które mogą być problematyczne z zasadami własności Rust. Jeśli dwa wątki uzyskują dostęp do tej samej zmiennej globalnej, może to spowodować wyścig danych.
W Rust zmienne globalne nazywane są zmiennymi statycznymi. Lista 20-10 pokazuje przykład deklaracji i użycia zmiennej statycznej z fragmentem ciągu jako wartością.
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("value is: {HELLO_WORLD}");
}Zmienne statyczne są podobne do stałych, które omówiliśmy w sekcji „Deklarowanie stałych” w Rozdziale 3. Nazwy zmiennych statycznych są konwencjonalnie zapisywane w formacie SCREAMING_SNAKE_CASE. Zmienne statyczne mogą przechowywać tylko referencje z czasem życia 'static, co oznacza, że kompilator Rust może określić czas życia i nie musimy go jawnie adnotować. Dostęp do niemodyfikowalnej zmiennej statycznej jest bezpieczny.
Subtelna różnica między stałymi a niemodyfikowalnymi zmiennymi statycznymi polega na tym, że wartości w zmiennej statycznej mają stały adres w pamięci. Użycie wartości zawsze będzie odwoływać się do tych samych danych. Stałe natomiast mogą duplikować swoje dane za każdym razem, gdy są używane. Inną różnicą jest to, że zmienne statyczne mogą być zmienne. Dostęp i modyfikacja zmiennych statycznych zmiennych jest niebezpieczna. Lista 20-11 pokazuje, jak zadeklarować, uzyskać dostęp i zmodyfikować zmienną statyczną zmienną o nazwie COUNTER.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling this from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: This is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}Podobnie jak w przypadku zwykłych zmiennych, mutowalność określamy za pomocą słowa kluczowego mut. Każdy kod, który odczytuje lub zapisuje z COUNTER, musi znajdować się w bloku unsafe. Kod z Listy 20-11 kompiluje się i wypisuje COUNTER: 3, tak jak byśmy się spodziewali, ponieważ jest jednowątkowy. Dostęp do COUNTER z wielu wątków prawdopodobnie skutkowałby wyścigami danych, więc jest to niezdefiniowane zachowanie. Dlatego musimy oznaczyć całą funkcję jako unsafe i udokumentować ograniczenie bezpieczeństwa, aby każdy, kto wywołuje funkcję, wiedział, co mu wolno, a czego nie wolno bezpiecznie robić.
Zawsze, gdy piszemy funkcję unsafe, idiomatyczne jest umieszczenie komentarza zaczynającego się od SAFETY i wyjaśniającego, co wywołujący musi zrobić, aby bezpiecznie wywołać funkcję. Podobnie, zawsze, gdy wykonujemy operację unsafe, idiomatyczne jest umieszczenie komentarza zaczynającego się od SAFETY, aby wyjaśnić, w jaki sposób zasady bezpieczeństwa są przestrzegane.
Ponadto, kompilator domyślnie odrzuci wszelkie próby tworzenia referencji do zmiennej statycznej zmiennej za pomocą lintu kompilatora. Musisz albo jawnie zrezygnować z ochrony tego lintu, dodając adnotację #[allow(static_mut_refs)], albo uzyskać dostęp do zmiennej statycznej zmiennej za pośrednictwem surowego wskaźnika utworzonego za pomocą jednego z operatorów surowego pożyczania. Obejmuje to przypadki, w których referencja jest tworzona niewidocznie, jak w przypadku jej użycia w println! w tej liście kodu. Wymaganie, aby referencje do zmiennych statycznych zmiennych były tworzone za pośrednictwem surowych wskaźników, pomaga uczynić wymagania bezpieczeństwa ich użycia bardziej oczywistymi.
Przy zmiennych danych, które są globalnie dostępne, trudno jest zapewnić, że nie ma wyścigów danych, dlatego Rust uważa zmienne statyczne zmienne za niebezpieczne. Tam, gdzie to możliwe, lepiej jest używać technik współbieżności i inteligentnych wskaźników bezpiecznych dla wątków, które omówiliśmy w Rozdziale 16, aby kompilator sprawdzał, czy dostęp do danych z różnych wątków odbywa się bezpiecznie.
Implementowanie Niebezpiecznej Cechy
Możemy użyć unsafe do zaimplementowania niebezpiecznej cechy. Cecha jest niebezpieczna, gdy co najmniej jedna z jej metod ma jakąś niezmienną, której kompilator nie może zweryfikować. Deklarujemy, że cecha jest unsafe, dodając słowo kluczowe unsafe przed trait i oznaczając implementację cechy jako unsafe, jak pokazano na Liście 20-12.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}Używając unsafe impl, obiecujemy, że będziemy przestrzegać niezmiennych, których kompilator nie może zweryfikować.
Jako przykład, przypomnijmy cechy znaczników Send i Sync, które omówiliśmy w sekcji „Rozszerzalna współbieżność z Send i Sync” w Rozdziale 16: kompilator implementuje te cechy automatycznie, jeśli nasze typy składają się wyłącznie z innych typów, które implementują Send i Sync. Jeśli zaimplementujemy typ zawierający typ, który nie implementuje Send lub Sync, taki jak surowe wskaźniki, i chcemy oznaczyć ten typ jako Send lub Sync, musimy użyć unsafe. Rust nie może zweryfikować, czy nasz typ spełnia gwarancje, że może być bezpiecznie przesyłany między wątkami lub dostępny z wielu wątków; dlatego musimy ręcznie wykonać te sprawdzenia i wskazać to za pomocą unsafe.
Dostęp do Pól Unii
Ostatnią akcją, która działa tylko z unsafe, jest dostęp do pól unii. Unia jest podobna do struct, ale tylko jedno zadeklarowane pole jest używane w danej instancji w danym momencie. Unie są używane głównie do interfejsu z uniami w kodzie C. Dostęp do pól unii jest niebezpieczny, ponieważ Rust nie może zagwarantować typu danych aktualnie przechowywanych w instancji unii. Możesz dowiedzieć się więcej o uniach w referencji Rust.
Używanie Miri do Sprawdzania Niebezpiecznego Kodu
Podczas pisania kodu niebezpiecznego, możesz chcieć sprawdzić, czy to, co napisałeś, jest faktycznie bezpieczne i poprawne. Jednym z najlepszych sposobów na to jest użycie Miri, oficjalnego narzędzia Rust do wykrywania niezdefiniowanego zachowania. Podczas gdy sprawdzający pożyczanie (borrow checker) jest narzędziem statycznym, które działa w czasie kompilacji, Miri jest narzędziem dynamicznym, które działa w czasie wykonania. Sprawdza Twój kod, uruchamiając Twój program lub jego pakiet testowy i wykrywając, kiedy naruszasz zasady, które rozumie, jak Rust powinien działać.
Używanie Miri wymaga nocnej (nightly) wersji Rust (o której więcej mówimy w Dodatku G: Jak powstaje Rust i „Nocny Rust”). Możesz zainstalować zarówno nocną wersję Rust, jak i narzędzie Miri, wpisując rustup +nightly component add miri. Nie zmienia to wersji Rust używanej w Twoim projekcie; dodaje tylko narzędzie do Twojego systemu, abyś mógł go używać, kiedy zechcesz. Miri możesz uruchomić na projekcie, wpisując cargo +nightly miri run lub cargo +nightly miri test.
Na przykładzie, jak bardzo to może być pomocne, rozważmy, co się dzieje, gdy uruchomimy go na Liście 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri poprawnie ostrzega nas, że rzutujemy liczbę całkowitą na wskaźnik, co może być problemem, ale Miri nie może ustalić, czy problem istnieje, ponieważ nie wie, skąd pochodzi wskaźnik. Następnie Miri zwraca błąd, gdzie Lista 20-7 ma niezdefiniowane zachowanie, ponieważ mamy wiszący wskaźnik. Dzięki Miri wiemy teraz, że istnieje ryzyko niezdefiniowanego zachowania i możemy zastanowić się, jak uczynić kod bezpiecznym. W niektórych przypadkach Miri może nawet zalecić, jak naprawić błędy.
Miri nie wychwytuje wszystkiego, co możesz zrobić źle podczas pisania niebezpiecznego kodu. Miri to narzędzie do analizy dynamicznej, więc wykrywa problemy tylko w kodzie, który faktycznie zostaje uruchomiony. Oznacza to, że będziesz musiał używać go w połączeniu z dobrymi technikami testowania, aby zwiększyć swoją pewność co do napisanego niebezpiecznego kodu. Miri nie obejmuje również wszystkich możliwych sposobów, w jaki Twój kod może być niestabilny.
Inaczej mówiąc: jeśli Miri znajdzie problem, wiesz, że jest błąd, ale to, że Miri nie znajdzie błędu, nie oznacza, że problemu nie ma. Może jednak wychwycić wiele. Spróbuj uruchomić go na innych przykładach niebezpiecznego kodu w tym rozdziale i zobacz, co powie!
Więcej o Miri dowiesz się w repozytorium GitHub.
Poprawne Użycie Kodu Niebezpiecznego
Użycie unsafe do wykorzystania jednej z pięciu omówionych właśnie supermocy nie jest błędem ani nawet czymś, na co patrzy się krzywo, ale poprawne napisanie kodu unsafe jest trudniejsze, ponieważ kompilator nie może pomóc w utrzymaniu bezpieczeństwa pamięci. Kiedy masz powód, aby użyć kodu unsafe, możesz to zrobić, a jawna adnotacja unsafe ułatwia śledzenie źródła problemów, gdy się pojawią. Zawsze, gdy piszesz kod unsafe, możesz użyć Miri, aby zwiększyć pewność, że napisany kod przestrzega zasad Rust.
Aby uzyskać znacznie głębsze poznanie, jak efektywnie pracować z niebezpiecznym Rust, przeczytaj oficjalny przewodnik Rust dotyczący unsafe, The Rustonomicon.
Zaawansowane Traity
Zaawansowane Traity
Po raz pierwszy omówiliśmy traity w sekcji „Definiowanie wspólnego zachowania za pomocą traitów” w Rozdziale 10, ale nie omówiliśmy bardziej zaawansowanych szczegółów. Teraz, gdy wiesz więcej o Rust, możemy przejść do sedna.
Definiowanie Traitów z Typami Stowarzyszonymi
Typy stowarzyszone łączą typ zastępczy z traitem w taki sposób, że definicje metod traitów mogą używać tych typów zastępczych w swoich sygnaturach. Implementator traitu określi konkretny typ, który ma być użyty zamiast typu zastępczego dla konkretnej implementacji. W ten sposób możemy zdefiniować trait, który używa pewnych typów, bez konieczności dokładnego poznania tych typów, dopóki trait nie zostanie zaimplementowany.
Większość zaawansowanych funkcji w tym rozdziale opisaliśmy jako rzadko potrzebne. Typy stowarzyszone znajdują się gdzieś pośrodku: są używane rzadziej niż funkcje wyjaśnione w pozostałej części książki, ale częściej niż wiele innych funkcji omówionych w tym rozdziale.
Jednym z przykładów traitu z typem stowarzyszonym jest trait Iterator, który udostępnia biblioteka standardowa. Typ stowarzyszony nazywa się Item i zastępuje typ wartości, po których iteruje typ implementujący trait Iterator. Definicja traitu Iterator jest pokazana na Liście 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Iterator, który ma stowarzyszony typ ItemTyp Item jest zastępczy, a definicja metody next pokazuje, że zwróci ona wartości typu Option<Self::Item>. Implementatorzy traitu Iterator określą konkretny typ dla Item, a metoda next zwróci Option zawierający wartość tego konkretnego typu.
Typy stowarzyszone mogą wydawać się podobną koncepcją do generyków, w tym sensie, że te ostatnie pozwalają nam zdefiniować funkcję bez określania, jakie typy może obsługiwać. Aby zbadać różnicę między tymi dwoma koncepcjami, przyjrzymy się implementacji traitu Iterator na typie o nazwie Counter, który określa, że typ Item to u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Ta składnia wydaje się porównywalna do składni generyków. Więc dlaczego nie zdefiniować cechy Iterator za pomocą generyków, jak pokazano na Liście 20-14?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Iterator używającego generykówRóżnica polega na tym, że używając generyków, jak na Liście 20-14, musimy adnotować typy w każdej implementacji; ponieważ możemy również zaimplementować Iterator<String> for Counter lub dowolny inny typ, moglibyśmy mieć wiele implementacji Iterator dla Counter. Innymi słowy, gdy trait ma parametr generyczny, może być implementowany dla typu wiele razy, zmieniając konkretne typy generycznych parametrów typu za każdym razem. Kiedy używamy metody next na Counter, musielibyśmy podać adnotacje typów, aby wskazać, którą implementację Iterator chcemy użyć.
Z typami stowarzyszonymi nie musimy adnotować typów, ponieważ nie możemy zaimplementować traitu na typie wiele razy. Na Liście 20-13 z definicją używającą typów stowarzyszonych, możemy wybrać typ Item tylko raz, ponieważ może istnieć tylko jedna impl Iterator for Counter. Nie musimy określać, że chcemy iteratora wartości u32 wszędzie tam, gdzie wywołujemy next na Counter.
Typy stowarzyszone stają się również częścią kontraktu traitu: Implementatorzy traitu muszą dostarczyć typ, który zastąpi symbol zastępczy typu stowarzyszonego. Typy stowarzyszone często mają nazwę opisującą sposób użycia typu, a dokumentowanie typu stowarzyszonego w dokumentacji API jest dobrą praktyką.
Używanie Domyślnych Parametrów Typów Generycznych i Przeciążanie Operatorów
Kiedy używamy generycznych parametrów typu, możemy określić domyślny konkretny typ dla typu generycznego. Eliminuje to potrzebę określania konkretnego typu przez implementatorów cechy, jeśli domyślny typ działa. Domyślny typ określa się podczas deklarowania typu generycznego za pomocą składni <PlaceholderType=ConcreteType>.
Świetnym przykładem sytuacji, w której ta technika jest przydatna, jest przeciążanie operatorów, w którym dostosowujesz zachowanie operatora (takiego jak +) w określonych sytuacjach.
Rust nie pozwala na tworzenie własnych operatorów ani na przeciążanie dowolnych operatorów. Możesz jednak przeciążać operacje i odpowiadające im traity wymienione w std::ops, implementując traity powiązane z operatorem. Na przykład, na Liście 20-15 przeciążamy operator +, aby dodawać dwie instancje Point. Robimy to, implementując trait Add na strukturze Point.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 }
);
}Add w celu przeciążenia operatora + dla instancji PointMetoda add dodaje wartości x dwóch instancji Point i wartości y dwóch instancji Point, aby stworzyć nową Point. Trait Add ma stowarzyszony typ o nazwie Output, który określa typ zwracany przez metodę add.
Domyślny typ generyczny w tym kodzie znajduje się wewnątrz traitu Add. Oto jego definicja:
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}Ten kod powinien być ogólnie znany: trait z jedną metodą i stowarzyszonym typem. Nowa część to Rhs=Self: ta składnia nazywa się domyślnymi parametrami typu. Generyczny parametr typu Rhs (skrót od „right-hand side” – prawa strona) definiuje typ parametru rhs w metodzie add. Jeśli nie określimy konkretnego typu dla Rhs podczas implementacji traitu Add, typ Rhs domyślnie przyjmie Self, czyli typ, na którym implementujemy Add.
Kiedy implementowaliśmy Add dla Point, użyliśmy domyślnego Rhs, ponieważ chcieliśmy dodać dwie instancje Point. Przyjrzyjmy się przykładowi implementacji traitu Add, gdzie chcemy dostosować typ Rhs, zamiast używać wartości domyślnej.
Mamy dwie struktury, Millimeters i Meters, przechowujące wartości w różnych jednostkach. To cienkie opakowanie istniejącego typu w inną strukturę jest znane jako wzorzec newtype, który szczegółowo opisujemy w sekcji „Implementowanie zewnętrznych traitów za pomocą wzorca newtype”. Chcemy dodawać wartości w milimetrach do wartości w metrach i chcemy, aby implementacja Add poprawnie wykonywała konwersję. Możemy zaimplementować Add dla Millimeters z Meters jako Rhs, jak pokazano na Liście 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Add na Millimeters w celu dodawania Millimeters i MetersAby dodać Millimeters i Meters, określamy impl Add<Meters>, aby ustawić wartość parametru typu Rhs zamiast używać domyślnego Self.
Parametry typu domyślnego będziesz używać na dwa główne sposoby:
- Aby rozszerzyć typ bez naruszania istniejącego kodu
- Aby umożliwić dostosowanie w konkretnych przypadkach, których większość użytkowników nie będzie potrzebować
Trait Add z biblioteki standardowej jest przykładem drugiego celu: zazwyczaj dodajesz dwa podobne typy, ale trait Add zapewnia możliwość dostosowania wykraczającego poza to. Użycie domyślnego parametru typu w definicji traitu Add oznacza, że nie musisz określać dodatkowego parametru przez większość czasu. Innymi słowy, nie jest potrzebna pewna ilość kodu boilerplate, co ułatwia używanie traitu.
Pierwszy cel jest podobny do drugiego, ale odwrotnie: jeśli chcesz dodać parametr typu do istniejącego traitu, możesz nadać mu wartość domyślną, aby umożliwić rozszerzenie funkcjonalności traitu bez naruszania istniejącego kodu implementacji.
Rozróżnianie Metod o Identycznych Nazwach
Nic w Rust nie zapobiega temu, aby trait miał metodę o tej samej nazwie co metoda innego traitu, ani Rust nie zapobiega implementowaniu obu traitów na jednym typie. Możliwe jest również zaimplementowanie metody bezpośrednio na typie z tą samą nazwą co metody z traitów.
Podczas wywoływania metod o tej samej nazwie, będziesz musiał powiedzieć Rust, której chcesz użyć. Rozważ kod na Liście 20-17, gdzie zdefiniowaliśmy dwa traity, Pilot i Wizard, które oba mają metodę fly. Następnie implementujemy oba traity na typie Human, który już ma zaimplementowaną metodę fly. Każda metoda fly robi coś innego.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {}fly i zaimplementowane na typie Human, oraz metoda fly zaimplementowana bezpośrednio na Human.Kiedy wywołujemy fly na instancji Human, kompilator domyślnie wywołuje metodę, która jest bezpośrednio zaimplementowana na typie, jak pokazano na Liście 20-18.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}fly na instancji HumanUruchomienie tego kodu wydrukuje *waving arms furiously*, pokazując, że Rust wywołał metodę fly zaimplementowaną bezpośrednio na Human.
Aby wywołać metody fly z traitu Pilot lub traitu Wizard, musimy użyć bardziej jawnej składni, aby określić, którą metodę fly mamy na myśli. Lista 20-19 demonstruje tę składnię.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
}fly z traitu chcemy wywołaćOkreślenie nazwy traitu przed nazwą metody wyjaśnia Rust, którą implementację fly chcemy wywołać. Moglibyśmy również napisać Human::fly(&person), co jest równoważne person.fly(), którego użyliśmy na Liście 20-19, ale jest to nieco dłuższe do napisania, jeśli nie musimy rozróżniać.
Uruchomienie tego kodu wypisuje następujące informacje:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Ponieważ metoda fly przyjmuje parametr self, gdybyśmy mieli dwa typy, które oba implementują jeden trait, Rust mógłby ustalić, którą implementację traitu użyć na podstawie typu self.
Jednak funkcje stowarzyszone, które nie są metodami, nie mają parametru self. Gdy istnieje wiele typów lub cech, które definiują funkcje niestowarzyszone z tą samą nazwą funkcji, Rust nie zawsze wie, o który typ chodzi, chyba że użyjesz w pełni kwalifikowanej składni. Na przykład na Liście 20-20 tworzymy cechę dla schroniska dla zwierząt, które chce nazwać wszystkie szczenięta Spot. Tworzymy cechę Animal z powiązaną funkcją niestowarzyszoną baby_name. Cecha Animal jest zaimplementowana dla struktury Dog, dla której również udostępniamy bezpośrednio powiązaną funkcję niestowarzyszoną baby_name.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}Implementujemy kod do nazywania wszystkich szczeniąt Spot w funkcji stowarzyszonej baby_name, która jest zdefiniowana na Dog. Typ Dog implementuje również trait Animal, który opisuje cechy, które mają wszystkie zwierzęta. Młode psy nazywane są szczeniętami, co jest wyrażone w implementacji traitu Animal na Dog w funkcji baby_name stowarzyszonej z traitem Animal.
W main wywołujemy funkcję Dog::baby_name, która wywołuje bezpośrednio funkcję stowarzyszoną zdefiniowaną na Dog. Ten kod wypisuje następujące informacje:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Ten wynik nie jest tym, czego chcieliśmy. Chcemy wywołać funkcję baby_name, która jest częścią cechy Animal, którą zaimplementowaliśmy na Dog, tak aby kod wypisywał A baby dog is called a puppy. Technika określania nazwy cechy, której użyliśmy na Liście 20-19, nie pomaga tutaj; jeśli zmienimy main na kod z Listy 20-21, otrzymamy błąd kompilacji.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}baby_name z traitu Animal, ale Rust nie wie, której implementacji użyćPonieważ Animal::baby_name nie ma parametru self, a mogą istnieć inne typy, które implementują cechę Animal, Rust nie może ustalić, którą implementację Animal::baby_name chcemy. Otrzymamy ten błąd kompilacji:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
Aby rozróżnić i powiedzieć Rust, że chcemy użyć implementacji Animal dla Dog w przeciwieństwie do implementacji Animal dla jakiegoś innego typu, musimy użyć w pełni kwalifikowanej składni. Lista 20-22 demonstruje, jak używać w pełni kwalifikowanej składni.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}baby_name z traitu Animal zaimplementowanego na DogDostarczamy Rust adnotację typu w nawiasach ostrych, która wskazuje, że chcemy wywołać metodę baby_name z cechy Animal zaimplementowanej na Dog, mówiąc, że chcemy traktować typ Dog jako Animal dla tego wywołania funkcji. Ten kod wydrukuje teraz to, czego chcemy:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
Ogólnie, w pełni kwalifikowana składnia jest zdefiniowana następująco:
<Typ jako Trait>::funkcja(odbiorca_jeśli_metoda, następny_argument, ...);Dla funkcji stowarzyszonych, które nie są metodami, nie byłoby odbiorcy: byłaby tylko lista innych argumentów. Można by używać w pełni kwalifikowanej składni wszędzie tam, gdzie wywołuje się funkcje lub metody. Jednakże, można pominąć dowolną część tej składni, którą Rust może ustalić na podstawie innych informacji w programie. Tę bardziej rozbudowaną składnię trzeba używać tylko w przypadkach, gdy istnieje wiele implementacji, które używają tej samej nazwy, a Rust potrzebuje pomocy w zidentyfikowaniu, którą implementację chcesz wywołać.
Używanie Supertraitów
Czasami możesz napisać definicję traitu, która zależy od innego traitu: Aby typ implementował pierwszy trait, chcesz wymagać, aby ten typ również implementował drugi trait. Robisz to po to, aby Twoja definicja traitu mogła korzystać ze stowarzyszonych elementów drugiego traitu. Trait, na którym opiera się Twoja definicja traitu, nazywany jest supertraitem Twojego traitu.
Na przykład, powiedzmy, że chcemy stworzyć cechę OutlinePrint z metodą outline_print, która będzie drukować podaną wartość sformatowaną tak, aby była obramowana gwiazdkami. Oznacza to, że biorąc pod uwagę strukturę Point, która implementuje standardową cechę Display, aby uzyskać (x, y), gdy wywołamy outline_print na instancji Point, która ma 1 dla x i 3 dla y, powinna ona wydrukować następujące:
**********
* *
* (1, 3) *
* *
**********
W implementacji metody outline_print chcemy użyć funkcjonalności cechy Display. Dlatego musimy określić, że cecha OutlinePrint będzie działać tylko dla typów, które również implementują Display i dostarczają funkcjonalność, której potrzebuje OutlinePrint. Możemy to zrobić w definicji cechy, określając OutlinePrint: Display. Ta technika jest podobna do dodawania ograniczenia cechy do cechy. Lista 20-23 pokazuje implementację cechy OutlinePrint.
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}OutlinePrint, który wymaga funkcjonalności z DisplayPonieważ określiliśmy, że OutlinePrint wymaga traitu Display, możemy użyć funkcji to_string, która jest automatycznie implementowana dla każdego typu, który implementuje Display. Gdybyśmy spróbowali użyć to_string bez dodania dwukropka i określenia traitu Display po nazwie traitu, otrzymalibyśmy błąd mówiący, że w bieżącym zakresie nie znaleziono metody o nazwie to_string dla typu &Self.
Zobaczmy, co się stanie, gdy spróbujemy zaimplementować OutlinePrint na typie, który nie implementuje Display, takim jak struktura Point:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Otrzymujemy błąd mówiący, że Display jest wymagane, ale nie zaimplementowane:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Aby to naprawić, implementujemy Display na Point i spełniamy ograniczenie, którego wymaga OutlinePrint, w ten sposób:
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
use std::fmt;
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Wtedy implementacja cechy OutlinePrint na Point skompiluje się pomyślnie, i będziemy mogli wywołać outline_print na instancji Point, aby wyświetlić ją w obramowaniu z gwiazdek.
Implementowanie Zewnętrznych Traitów za pomocą Wzorca Newtype
W sekcji „Implementowanie traitu na typie” w Rozdziale 10 wspomnieliśmy o regule sieroty, która stanowi, że możemy implementować trait na typie tylko wtedy, gdy albo trait, albo typ, albo oba, są lokalne dla naszego crate’u. Możliwe jest obejście tego ograniczenia za pomocą wzorca newtype, który polega na utworzeniu nowego typu w strukturze krotkowej. (Struktury krotkowe omówiliśmy w sekcji „Tworzenie różnych typów za pomocą struktur krotkowych” w Rozdziale 5.) Struktura krotkowa będzie miała jedno pole i będzie cienkim opakowaniem wokół typu, dla którego chcemy zaimplementować trait. Wtedy typ opakowujący jest lokalny dla naszego crate’u, i możemy zaimplementować trait na opakowaniu. Newtype to termin, który pochodzi z języka programowania Haskell. Nie ma kary za wydajność w czasie wykonania za użycie tego wzorca, a typ opakowujący jest pomijany w czasie kompilacji.
Na przykład, załóżmy, że chcemy zaimplementować Display na Vec<T>, czego reguła sieroty uniemożliwia nam bezpośrednio, ponieważ trait Display i typ Vec<T> są zdefiniowane poza naszym crate. Możemy stworzyć strukturę Wrapper, która przechowuje instancję Vec<T>; następnie możemy zaimplementować Display na Wrapper i użyć wartości Vec<T>, jak pokazano na Liście 20-24.
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {w}");
}Wrapper wokół Vec<String> w celu implementacji DisplayImplementacja Display używa self.0 do dostępu do wewnętrznego Vec<T>, ponieważ Wrapper jest strukturą krotkową, a Vec<T> jest elementem o indeksie 0 w krotce. Następnie możemy użyć funkcjonalności cechy Display na Wrapper.
Wadą stosowania tej techniki jest to, że Wrapper jest nowym typem, więc nie ma metod wartości, którą przechowuje. Musielibyśmy zaimplementować wszystkie metody Vec<T> bezpośrednio na Wrapper, tak aby metody delegowały do self.0, co pozwoliłoby nam traktować Wrapper dokładnie tak jak Vec<T>. Gdybyśmy chcieli, aby nowy typ miał każdą metodę, którą ma typ wewnętrzny, zaimplementowanie cechy Deref na Wrapper, aby zwracała typ wewnętrzny, byłoby rozwiązaniem (omówiliśmy implementację cechy Deref w sekcji „Traktowanie inteligentnych wskaźników jak zwykłych referencji” w Rozdziale 15). Gdybyśmy nie chcieli, aby typ Wrapper miał wszystkie metody typu wewnętrznego — na przykład, aby ograniczyć zachowanie typu Wrapper — musielibyśmy ręcznie zaimplementować tylko te metody, które chcemy.
Ten wzorzec newtype jest również użyteczny nawet wtedy, gdy traity nie są zaangażowane. Zmieńmy fokus i przyjrzyjmy się niektórym zaawansowanym sposobom interakcji z systemem typów Rust.
Zaawansowane Typy
Zaawansowane Typy
System typów Rust posiada pewne funkcje, o których wspominaliśmy, ale jeszcze
nie omawialiśmy. Zaczniemy od omówienia ogólnych “nowych typów” (newtypes),
badając, dlaczego są one przydatne jako typy. Następnie przejdziemy do aliasów
typów, funkcji podobnej do “nowych typów”, ale z nieco odmienną semantyką.
Omówimy także typ ! oraz typy o dynamicznym rozmiarze.
Bezpieczeństwo typów i abstrakcja z wzorcem nowego typu
Ta sekcja zakłada, że przeczytałeś wcześniejszą sekcję „Implementowanie cech
zewnętrznych za pomocą wzorca nowego typu”. Wzorzec
nowego typu jest również przydatny do zadań wykraczających poza te, które
omówiliśmy do tej pory, w tym do statycznego egzekwowania, aby wartości nigdy
nie były mylone, oraz do wskazywania jednostek wartości. Przykład użycia
nowych typów do wskazywania jednostek widziałeś w Listing 20-16: Przypomnij
sobie, że struktury Millimeters i Meters opakowywały wartości u32 w nowy
typ. Gdybyśmy napisali funkcję z parametrem typu Millimeters, nie bylibyśmy
w stanie skompilować programu, który przypadkowo próbowałby wywołać tę funkcję
z wartością typu Meters lub zwykłym u32.
Możemy również użyć wzorca nowego typu, aby odseparować niektóre szczegóły implementacji typu: Nowy typ może ujawniać publiczne API, które różni się od API prywatnego typu wewnętrznego.
Nowe typy mogą również ukrywać wewnętrzną implementację. Na przykład, moglibyśmy
dostarczyć typ People, aby opakować HashMap<i32, String>, który przechowuje
ID osoby skojarzone z jej imieniem. Kod używający People wchodziłby w
interakcję tylko z publicznym API, które dostarczamy, takim jak metoda
dodawania ciągu znaków z imieniem do kolekcji People; ten kod nie musiałby
wiedzieć, że wewnętrznie przypisujemy imionom ID typu i32. Wzorzec nowego
typu to lekki sposób na osiągnięcie hermetyzacji w celu ukrycia szczegółów
implementacji, co omówiliśmy w sekcji „Hermetyzacja ukrywająca szczegóły
implementacji”
w Rozdziale 18.
Synonimy typów i aliasy typów
Rust umożliwia deklarowanie aliasu typu, aby nadać istniejącemu typowi
inne imię. Używamy do tego słowa kluczowego type. Na przykład, możemy
utworzyć alias Kilometers dla i32 w następujący sposób:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Teraz alias Kilometers jest synonimem dla i32; w przeciwieństwie do
typów Millimeters i Meters, które stworzyliśmy w Listing 20-16,
Kilometers nie jest osobnym, nowym typem. Wartości, które mają typ
Kilometers, będą traktowane tak samo jak wartości typu i32:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Ponieważ Kilometers i i32 są tego samego typu, możemy dodawać wartości obu
typów i przekazywać wartości Kilometers do funkcji, które przyjmują
parametry i32. Jednakże, używając tej metody, nie uzyskujemy korzyści z
kontroli typów, które daje wzorzec nowego typu omówiony wcześniej. Innymi
słowy, jeśli gdzieś pomylimy wartości Kilometers i i32, kompilator nie
zgłosi nam błędu.
Głównym przypadkiem użycia synonimów typów jest zmniejszenie powtórzeń. Na przykład, możemy mieć długi typ, taki jak ten:
Box<dyn Fn() + Send + 'static>Pisanie tego długiego typu w sygnaturach funkcji i jako adnotacji typów w całym kodzie może być męczące i podatne na błędy. Wyobraź sobie projekt pełen kodu takiego jak w Listing 20-25.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// --snip--
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// --snip--
Box::new(|| ())
}
}Alias typu sprawia, że ten kod jest łatwiejszy do zarządzania, redukując
powtórzenia. W Listing 20-26 wprowadziliśmy alias nazwany Thunk dla
obszernego typu i możemy zastąpić wszystkie użycia typu krótszym aliasem
Thunk.
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
Box::new(|| ())
}
}Thunk, w celu zmniejszenia powtórzeńTen kod jest znacznie łatwiejszy do czytania i pisania! Wybranie znaczącej nazwy dla aliasu typu może pomóc w komunikowaniu intencji (thunk to słowo opisujące kod, który ma być ewaluowany w późniejszym czasie, więc jest to odpowiednia nazwa dla przechowywanego domknięcia).
Aliasy typów są również powszechnie używane z typem Result<T, E> w celu
zmniejszenia powtórzeń. Rozważ moduł std::io w standardowej bibliotece.
Operacje wejścia/wyjścia często zwracają Result<T, E>, aby obsługiwać
sytuacje, gdy operacje kończą się niepowodzeniem. Ta biblioteka posiada
strukturę std::io::Error, która reprezentuje wszystkie możliwe błędy I/O.
Wiele funkcji w std::io będzie zwracać Result<T, E>, gdzie E to
std::io::Error, takie jak te funkcje w cesze Write:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Result<..., Error> powtarza się często. W związku z tym std::io ma tę
deklarację aliasu typu:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Ponieważ ta deklaracja znajduje się w module std::io, możemy użyć w pełni
kwalifikowanego aliasu std::io::Result<T>; to znaczy Result<T, E>, gdzie
E jest wypełnione jako std::io::Error. Sygnatury funkcji cechy Write
wyglądają tak:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Alias typu pomaga na dwa sposoby: ułatwia pisanie kodu i zapewnia nam
spójny interfejs w całym std::io. Ponieważ jest to alias, jest to po
prostu kolejny Result<T, E>, co oznacza, że możemy z nim używać dowolnych
metod działających na Result<T, E>, a także specjalnej składni, takiej jak
operator ?.
Typ Nigdy, który nigdy nie zwraca
Rust posiada specjalny typ nazwany !, który w terminologii teorii typów
nazywany jest typem pustym, ponieważ nie posiada żadnych wartości. My
wolimy nazywać go typem nigdy, ponieważ zajmuje on miejsce typu zwracanego,
gdy funkcja nigdy nie zwraca wartości. Oto przykład:
fn bar() -> ! {
// --snip--
panic!();
}Ten kod czytamy jako „funkcja bar nigdy nie zwraca”. Funkcje, które nigdy nie
zwracają, nazywane są funkcjami rozbieżnymi. Nie możemy tworzyć wartości
typu !, więc bar nigdy nie może zwrócić wartości.
Ale jakie jest zastosowanie typu, dla którego nigdy nie można stworzyć wartości? Przypomnijmy kod z Listing 2-5, część gry w zgadywanie liczb; odtworzyliśmy jego fragment tutaj w Listing 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}match z ramieniem, które kończy się na continueWówczas pominęliśmy pewne szczegóły tego kodu. W sekcji „Konstrukcja przepływu
sterowania match” w
Rozdziale 6 omówiliśmy, że ramiona match muszą zwracać ten sam typ. Na
przykład, poniższy kod nie działa:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}Typ guess w tym kodzie musiałby być liczbą całkowitą i ciągiem znaków,
a Rust wymaga, aby guess miał tylko jeden typ. Zatem, co zwraca continue?
Jak mogliśmy zwrócić u32 z jednego ramienia i mieć drugie ramię, które kończy
się na continue w Listing 20-27?
Jak się domyślasz, continue ma wartość !. Oznacza to, że gdy Rust
oblicza typ guess, patrzy na oba ramiona match, pierwsze z wartością u32
i drugie z wartością !. Ponieważ ! nigdy nie może mieć wartości, Rust
przyjmuje, że typ guess to u32.
Formalny sposób opisu tego zachowania jest taki, że wyrażenia typu ! mogą
być konwertowane na dowolny inny typ. Możemy zakończyć to ramię match za
pomocą continue, ponieważ continue nie zwraca wartości; zamiast tego
przenosi sterowanie na początek pętli, więc w przypadku Err nigdy nie
przypisujemy wartości do guess.
Typ nigdy jest również przydatny z makrem panic!. Przypomnij sobie funkcję
unwrap, którą wywołujemy na wartościach Option<T>, aby wyprodukować
wartość lub wywołać panikę, z następującą definicją:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}W tym kodzie dzieje się to samo, co w match w Listing 20-27: Rust widzi,
że val ma typ T, a panic! ma typ !, więc wynikiem całego wyrażenia
match jest T. Ten kod działa, ponieważ panic! nie produkuje wartości;
kończy program. W przypadku None nie zwrócimy wartości z unwrap, więc ten
kod jest poprawny.
Ostatnie wyrażenie, które ma typ !, to pętla:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Tutaj pętla nigdy się nie kończy, więc ! jest wartością wyrażenia. Jednakże,
nie byłoby to prawdą, gdybyśmy dodali break, ponieważ pętla zakończyłaby się
wtedy, gdy doszłaby do break.
Typy o dynamicznym rozmiarze i cecha Sized
Rust musi znać pewne szczegóły dotyczące swoich typów, takie jak ile miejsca przydzielić dla wartości konkretnego typu. To pozostawia jeden zakątek jego systemu typów na początku nieco mylący: koncepcję typów o dynamicznym rozmiarze. Czasami nazywane DST lub typami bez rozmiaru, te typy umożliwiają pisanie kodu z użyciem wartości, których rozmiar możemy poznać tylko w czasie wykonania.
Zagłębmy się w szczegóły typu o dynamicznym rozmiarze o nazwie str, którego
używaliśmy w całej książce. Zgadza się, nie &str, ale str sam w sobie,
jest DST. W wielu przypadkach, takich jak przechowywanie tekstu wprowadzonego
przez użytkownika, nie możemy wiedzieć, jak długi jest ciąg, dopóki program
się nie uruchomi. Oznacza to, że nie możemy utworzyć zmiennej typu str,
ani przyjąć argumentu typu str. Rozważ poniższy kod, który nie działa:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust musi wiedzieć, ile pamięci przydzielić dla każdej wartości danego typu,
i wszystkie wartości danego typu muszą używać tej samej ilości pamięci. Gdyby
Rust pozwolił nam napisać ten kod, te dwie wartości str musiałyby zajmować
tę samą ilość miejsca. Ale mają one różne długości: s1 potrzebuje 12 bajtów
pamięci, a s2 potrzebuje 15. Dlatego nie jest możliwe utworzenie zmiennej
przechowującej typ o dynamicznym rozmiarze.
Więc co robimy? W tym przypadku znasz już odpowiedź: Zmieniamy typ s1 i s2
na wycinek ciągu znaków (&str), a nie str. Przypomnij sobie z sekcji
„Wycinki ciągów znaków” w Rozdziale 4,
że struktura danych wycinka przechowuje tylko pozycję początkową i długość
wycinka. Zatem, chociaż &T jest pojedynczą wartością, która przechowuje
adres pamięci, gdzie znajduje się T, wycinek ciągu znaków to dwie wartości:
adres str i jego długość. W związku z tym możemy znać rozmiar wartości
wycinka ciągu znaków w czasie kompilacji: Jest to dwukrotność długości usize.
Oznacza to, że zawsze znamy rozmiar wycinka ciągu znaków, niezależnie od tego,
jak długi jest ciąg, do którego się odnosi. Ogólnie rzecz biorąc, w ten sposób
używa się typów o dynamicznym rozmiarze w Rust: Posiadają dodatkowy bit
metadanych, który przechowuje rozmiar dynamicznych informacji. Złotą zasadą
typów o dynamicznym rozmiarze jest to, że zawsze musimy umieszczać wartości
typów o dynamicznym rozmiarze za wskaźnikiem jakiegoś rodzaju.
Możemy łączyć str z różnymi rodzajami wskaźników: na przykład Box<str> lub
Rc<str>. W rzeczywistości widziałeś to już wcześniej, ale z innym typem
o dynamicznym rozmiarze: cechami. Każda cecha jest typem o dynamicznym
rozmiarze, do którego możemy się odwoływać, używając nazwy cechy. W sekcji
„Używanie obiektów cech do abstrakcji nad wspólnym
zachowaniem” w Rozdziale 18 wspomnieliśmy, że aby używać cech jako obiektów
cech, musimy umieścić je za wskaźnikiem, takim jak &dyn Trait lub Box<dyn Trait>
(Rc<dyn Trait> również by działało).
Aby pracować z DST, Rust udostępnia cechę Sized, aby określić, czy rozmiar
typu jest znany w czasie kompilacji. Ta cecha jest automatycznie
implementowana dla wszystkiego, czego rozmiar jest znany w czasie kompilacji.
Dodatkowo, Rust niejawnie dodaje ograniczenie na Sized do każdej funkcji
generycznej. Oznacza to, że definicja funkcji generycznej, taka jak ta:
fn generic<T>(t: T) {
// --snip--
}jest w rzeczywistości traktowana tak, jakbyśmy napisali to:
fn generic<T: Sized>(t: T) {
// --snip--
}Domyślnie funkcje generyczne będą działać tylko na typach, które mają znany rozmiar w czasie kompilacji. Możesz jednak użyć następującej specjalnej składni, aby złagodzić to ograniczenie:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}Ograniczenie cechy na ?Sized oznacza „T może, ale nie musi być Sized”,
a ta notacja zastępuje domyślną zasadę, że typy generyczne muszą mieć znany
rozmiar w czasie kompilacji. Składnia ?Trait z tym znaczeniem jest dostępna
tylko dla Sized, a nie dla żadnych innych cech.
Zauważ również, że zmieniliśmy typ parametru t z T na &T. Ponieważ typ
może nie być Sized, musimy używać go za wskaźnikiem jakiegoś rodzaju. W tym
przypadku wybraliśmy referencję.
Następnie porozmawiamy o funkcjach i domknięciach!
Zaawansowane Funkcje i Domknięcia
Zaawansowane Funkcje i Domknięcia
Ta sekcja omawia niektóre zaawansowane funkcje związane z funkcjami i domknięciami, w tym wskaźniki na funkcje i zwracanie domknięć.
Wskaźniki na Funkcje
Mówiliśmy o tym, jak przekazywać domknięcia do funkcji; możesz również
przekazywać do funkcji zwykłe funkcje! Ta technika jest przydatna, gdy chcesz
przekazać funkcję, którą już zdefiniowałeś, zamiast definiować nowe domknięcie.
Funkcje konwertują się do typu fn (z małą literą f), nie mylić z cechą
domknięcia Fn. Typ fn nazywany jest wskaźnikiem na funkcję. Przekazywanie
funkcji za pomocą wskaźników na funkcje umożliwi ci używanie funkcji jako
argumentów dla innych funkcji.
Składnia określania, że parametr jest wskaźnikiem na funkcję, jest podobna do
tej dla domknięć, jak pokazano w Listing 20-28, gdzie zdefiniowaliśmy funkcję
add_one, która dodaje 1 do swojego parametru. Funkcja do_twice przyjmuje
dwa parametry: wskaźnik na funkcję do dowolnej funkcji, która przyjmuje
parametr i32 i zwraca i32, oraz jedną wartość i32. Funkcja do_twice
wywołuje funkcję f dwukrotnie, przekazując jej wartość arg, a następnie
dodaje do siebie wyniki dwóch wywołań funkcji. Funkcja main wywołuje
do_twice z argumentami add_one i 5.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {answer}");
}fn do przyjęcia wskaźnika na funkcję jako argumentuTen kod wyświetla The answer is: 12. Określamy, że parametr f w do_twice
jest typu fn, który przyjmuje jeden parametr typu i32 i zwraca i32.
Następnie możemy wywołać f w ciele do_twice. W main możemy przekazać
nazwę funkcji add_one jako pierwszy argument do do_twice.
W przeciwieństwie do domknięć, fn jest typem, a nie cechą, więc określamy fn
jako typ parametru bezpośrednio, zamiast deklarować parametr typu generycznego
z jedną z cech domknięć jako ograniczeniem cechy.
Wskaźniki na funkcje implementują wszystkie trzy cechy domknięć (Fn, FnMut
i FnOnce), co oznacza, że zawsze możesz przekazać wskaźnik na funkcję jako
argument do funkcji, która oczekuje domknięcia. Najlepiej jest pisać funkcje,
używając typu generycznego i jednej z cech domknięć, aby twoje funkcje mogły
przyjmować zarówno funkcje, jak i domknięcia.
Jednakże, jednym z przykładów, gdzie chciałbyś akceptować tylko fn, a nie
domknięcia, jest interakcja z zewnętrznym kodem, który nie ma domknięć: Funkcje
w C mogą przyjmować funkcje jako argumenty, ale C nie ma domknięć.
Jako przykład, gdzie można by użyć zarówno domknięcia zdefiniowanego inline,
jak i nazwanej funkcji, przyjrzyjmy się zastosowaniu metody map dostarczonej
przez cechę Iterator w standardowej bibliotece. Aby użyć metody map do
przekształcenia wektora liczb w wektor ciągów znaków, moglibyśmy użyć
domknięcia, jak w Listing 20-29.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}map do konwersji liczb na ciągi znakówAlbo moglibyśmy nazwać funkcję jako argument do map zamiast domknięcia.
Listing 20-30 pokazuje, jak by to wyglądało.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}String::to_string z metodą map do konwersji liczb na ciągi znakówZauważ, że musimy użyć w pełni kwalifikowanej składni, o której mówiliśmy w
sekcji „Zaawansowane Cechy”, ponieważ
istnieje wiele dostępnych funkcji o nazwie to_string.
Tutaj używamy funkcji to_string zdefiniowanej w cesze ToString, którą
standardowa biblioteka zaimplementowała dla każdego typu, który implementuje
Display.
Przypomnij sobie z sekcji „Wartości enum” w Rozdziale 6, że nazwa każdego wariantu enum, który definiujemy, staje się także funkcją inicjalizującą. Możemy używać tych funkcji inicjalizujących jako wskaźników na funkcje, które implementują cechy domknięć, co oznacza, że możemy określać funkcje inicjalizujące jako argumenty dla metod, które przyjmują domknięcia, jak pokazano w Listing 20-31.
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}map do tworzenia instancji Status z liczbTutaj tworzymy instancje Status::Value używając każdej wartości u32 w
zakresie, na którym wywołano map, poprzez użycie funkcji inicjalizującej
Status::Value. Niektórzy wolą ten styl, a inni wolą używać domknięć.
Kompilują się one do tego samego kodu, więc używaj stylu, który jest dla ciebie
jaśniejszy.
Zwracanie Domknięć
Domknięcia są reprezentowane przez cechy, co oznacza, że nie można zwracać
domknięć bezpośrednio. W większości przypadków, gdy chcesz zwrócić cechę,
możesz zamiast tego użyć konkretnego typu, który implementuje tę cechę, jako
wartości zwracanej funkcji. Jednakże, zazwyczaj nie możesz tego zrobić z
domknięciami, ponieważ nie mają one konkretnego typu, który można zwrócić;
nie wolno używać wskaźnika na funkcję fn jako typu zwracanego, jeśli
domknięcie przechwytuje jakiekolwiek wartości ze swojego zasięgu, na przykład.
Zamiast tego, zazwyczaj będziesz używać składni impl Trait, którą poznaliśmy
w Rozdziale 10. Możesz zwracać dowolny typ funkcji, używając Fn, FnOnce
i FnMut. Na przykład, kod z Listing 20-32 skompiluje się bez problemu.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}impl TraitJednakże, jak zauważyliśmy w sekcji „Wnioskowanie i adnotacje typów domknięć” w Rozdziale 13, każde domknięcie jest również swoim własnym, odrębnym typem. Jeśli musisz pracować z wieloma funkcjami, które mają tę samą sygnaturę, ale różne implementacje, będziesz musiał użyć dla nich obiektu cechy. Rozważ, co się stanie, jeśli napiszesz kod taki jak pokazano w Listing 20-33.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Vec<T> domknięć zdefiniowanych przez funkcje, które zwracają typy impl FnW tym miejscu mamy dwie funkcje, returns_closure i returns_initialized_closure,
które obie zwracają impl Fn(i32) -> i32. Zauważ, że domknięcia, które zwracają,
są różne, mimo że implementują tę samą cechę. Jeśli spróbujemy to skompilować,
Rust poinformuje nas, że to nie zadziała:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
Komunikat o błędzie informuje nas, że za każdym razem, gdy zwracamy impl Trait,
Rust tworzy unikalny typ nieprzezroczysty – typ, w którego szczegóły tego,
co Rust dla nas konstruuje, nie możemy wniknąć, ani nie możemy odgadnąć
typu, który Rust wygeneruje, aby samemu go napisać. Zatem, mimo że te funkcje
zwracają domknięcia, które implementują tę samą cechę, Fn(i32) -> i32,
nieprzezroczyste typy, które Rust generuje dla każdego z nich, są odrębne.
(Jest to podobne do tego, jak Rust produkuje różne konkretne typy dla
różnych bloków async, nawet jeśli mają ten sam typ wyjściowy, jak widzieliśmy
w „Typ Pin i cecha Unpin” w Rozdziale 17.)
Rozwiązanie tego problemu widzieliśmy już kilkakrotnie: Możemy użyć obiektu
cechy, jak w Listing 20-34.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}Vec<T> domknięć zdefiniowanych przez funkcje, które zwracają Box<dyn Fn>, tak aby miały ten sam typTen kod skompiluje się bez problemu. Więcej informacji na temat obiektów cech znajdziesz w sekcji „Używanie obiektów cech do abstrakcji nad wspólnym zachowaniem” w Rozdziale 18.
Następnie przyjrzyjmy się makrom!
Makra
Makra
Makr takich jak println! używaliśmy w całej książce, ale nie zbadaliśmy
jeszcze w pełni, czym jest makro i jak działa. Termin makro odnosi się do
rodziny funkcji w Rust—makra deklaratywne z macro_rules! oraz trzy rodzaje
makr proceduralnych:
- Niestandardowe makra
#[derive], które określają kod dodany za pomocą atrybutuderiveużywanego w strukturach i enumach - Makra podobne do atrybutów, które definiują niestandardowe atrybuty możliwe do użycia z dowolnym elementem
- Makra podobne do funkcji, które wyglądają jak wywołania funkcji, ale operują na tokenach określonych jako ich argument
Będziemy mówić o każdym z nich po kolei, ale najpierw przyjrzyjmy się, dlaczego w ogóle potrzebujemy makr, skoro mamy już funkcje.
Różnica między makrami a funkcjami
Zasadniczo, makra to sposób pisania kodu, który pisze inny kod, co jest znane
jako metaprogramowanie. W Dodatku C omawiamy atrybut derive, który
generuje implementację różnych cech dla ciebie. Używaliśmy również makr
println! i vec! w całej książce. Wszystkie te makra rozszerzają się,
aby wyprodukować więcej kodu niż ten, który napisałeś ręcznie.
Metaprogramowanie jest przydatne do zmniejszania ilości kodu, który musisz napisać i utrzymać, co jest również jedną z ról funkcji. Jednak makra mają pewne dodatkowe moce, których funkcje nie mają.
Sygnatura funkcji musi deklarować liczbę i typ parametrów, które funkcja
posiada. Makra natomiast mogą przyjmować zmienną liczbę parametrów: Możemy
wywołać println!("hello") z jednym argumentem lub println!("hello {}", name)
z dwoma argumentami. Ponadto, makra są rozszerzane zanim kompilator zinterpretuje
znaczenie kodu, więc makro może na przykład zaimplementować cechę na danym
typie. Funkcja tego nie może, ponieważ jest wywoływana w czasie wykonania, a
cecha musi być zaimplementowana w czasie kompilacji.
Wadą implementacji makra zamiast funkcji jest to, że definicje makr są bardziej złożone niż definicje funkcji, ponieważ piszesz kod Rust, który pisze kod Rust. Z powodu tej pośredniości, definicje makr są zazwyczaj trudniejsze do czytania, zrozumienia i utrzymania niż definicje funkcji.
Inną ważną różnicą między makrami a funkcjami jest to, że musisz definiować makra lub wprowadzać je do zasięgu przed ich wywołaniem w pliku, w przeciwieństwie do funkcji, które możesz zdefiniować i wywołać w dowolnym miejscu.
Makra deklaratywne do ogólnego metaprogramowania
Najczęściej używaną formą makr w Rust są makra deklaratywne. Czasami są
również nazywane „makrami na przykładach”, „makrami macro_rules!” lub po
prostu „makrami”. W swej istocie makra deklaratywne pozwalają na pisanie
codś podobnego do wyrażenia match w Rust. Jak omówiono w Rozdziale 6,
wyrażenia match są strukturami kontrolnymi, które przyjmują wyrażenie,
porównują wynikową wartość wyrażenia z wzorcami, a następnie uruchamiają kod
skojarzony z pasującym wzorcem. Makra również porównują wartość z wzorcami,
które są skojarzone z konkretnym kodem: w tej sytuacji wartością jest literał
kodu źródłowego Rust przekazany do makra; wzorce są porównywane ze strukturą
tego kodu źródłowego; a kod skojarzony z każdym wzorcem, gdy zostanie dopasowany,
zastępuje kod przekazany do makra. Wszystko to dzieje się podczas kompilacji.
Aby zdefiniować makro, używasz konstrukcji macro_rules!. Zbadajmy, jak używać
macro_rules!, przyglądając się, jak zdefiniowane jest makro vec!. Rozdział 8
omówił, jak możemy używać makra vec! do tworzenia nowego wektora z
konkretnymi wartościami. Na przykład, poniższe makro tworzy nowy wektor
zawierający trzy liczby całkowite:
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}Moglibyśmy również użyć makra vec!, aby stworzyć wektor dwóch liczb
całkowitych lub wektor pięciu wycinków ciągów znaków. Nie bylibyśmy w stanie
użyć funkcji do wykonania tego samego, ponieważ nie znalibyśmy liczby ani
typu wartości z góry.
Listing 20-35 pokazuje nieco uproszczoną definicję makra vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}vec!Uwaga: Rzeczywista definicja makra vec! w standardowej bibliotece zawiera
kod do wcześniejszego przydzielania odpowiedniej ilości pamięci. Ten kod
jest optymalizacją, której tutaj nie uwzględniamy, aby przykład był prostszy.
Adnotacja #[macro_export] wskazuje, że to makro powinno być dostępne
zawsze, gdy pakiet, w którym makro jest zdefiniowane, zostanie wprowadzony do
zasięgu. Bez tej adnotacji makro nie może zostać wprowadzone do zasięgu.
Następnie rozpoczynamy definicję makra od macro_rules! i nazwy definiowanego
makra bez wykrzyknika. Nazwa, w tym przypadku vec, jest poprzedzona
nawiasami klamrowymi oznaczającymi ciało definicji makra.
Struktura w ciele vec! jest podobna do struktury wyrażenia match. Tutaj
mamy jedno ramię ze wzorcem ( $( $x:expr ),* ), po którym następuje =>
i blok kodu skojarzony z tym wzorcem. Jeśli wzorzec pasuje, skojarzony blok
kodu zostanie wygenerowany. Biorąc pod uwagę, że jest to jedyny wzorzec w tym
makrze, istnieje tylko jeden prawidłowy sposób dopasowania; każdy inny wzorzec
spowoduje błąd. Bardziej złożone makra będą miały więcej niż jedno ramię.
Poprawna składnia wzorców w definicjach makr różni się od składni wzorców omówionej w Rozdziale 19, ponieważ wzorce makr są dopasowywane do struktury kodu Rust, a nie do wartości. Przejdźmy przez to, co oznaczają fragmenty wzorców w Listing 20-29; pełną składnię wzorców makr znajdziesz w Referencjach Rust.
Najpierw używamy zestawu nawiasów do objęcia całego wzorca. Używamy znaku
dolara ($), aby zadeklarować zmienną w systemie makr, która będzie
zawierać kod Rust pasujący do wzorca. Znak dolara jasno wskazuje, że jest to
zmienna makra, w przeciwieństwie do zwykłej zmiennej Rust. Następnie następuje
zestaw nawiasów, który przechwytuje wartości pasujące do wzorca w nawiasach
do wykorzystania w kodzie zastępującym. Wewnątrz $() znajduje się $x:expr,
który pasuje do dowolnego wyrażenia Rust i nadaje wyrażeniu nazwę $x.
Przecinek po $() wskazuje, że dosłowny znak separatora przecinka musi
powtarzać się między każdą instancją kodu, który pasuje do kodu w $().
Gwiazdka * określa, że wzorzec pasuje do zera lub więcej elementów
poprzedzających *.
Kiedy wywołujemy to makro za pomocą vec![1, 2, 3];, wzorzec $x pasuje
trzy razy do trzech wyrażeń 1, 2 i 3.
Teraz przyjrzyjmy się wzorcowi w ciele kodu skojarzonego z tym ramieniem:
temp_vec.push() w $()* jest generowane dla każdej części, która pasuje
do $() we wzorcu zero lub więcej razy, w zależności od tego, ile razy wzorzec
pasuje. $x jest zastępowane każdym pasującym wyrażeniem. Kiedy wywołujemy
to makro za pomocą vec![1, 2, 3];, wygenerowany kod, który zastępuje to
wywołanie makra, będzie następujący:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Zdefiniowaliśmy makro, które może przyjmować dowolną liczbę argumentów dowolnego typu i generować kod do tworzenia wektora zawierającego określone elementy.
Aby dowiedzieć się więcej o tym, jak pisać makra, zajrzyj do dokumentacji online lub innych zasobów, takich jak „The Little Book of Rust Macros” rozpoczęta przez Daniela Keepa i kontynuowana przez Lukasa Wirtha.
Makra proceduralne do generowania kodu z atrybutów
Druga forma makr to makro proceduralne, które działa bardziej jak funkcja
(i jest rodzajem procedury). Makra proceduralne przyjmują pewien kod jako
wejście, operują na tym kodzie i produkują pewien kod jako wyjście, zamiast
dopasowywać się do wzorców i zastępować kod innym kodem, jak to robią makra
deklaratywne. Trzy rodzaje makr proceduralnych to niestandardowe derive,
podobne do atrybutów i podobne do funkcji, a wszystkie działają w podobny
sposób.
Podczas tworzenia makr proceduralnych definicje muszą znajdować się we
własnym pakiecie ze specjalnym typem pakietu. Wynika to ze złożonych przyczyn
technicznych, które mamy nadzieję wyeliminować w przyszłości. W Listing 20-36
pokazujemy, jak zdefiniować makro proceduralne, gdzie some_attribute jest
zastępcą dla użycia konkretnej odmiany makra.
use proc_macro::TokenStream;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Funkcja, która definiuje makro proceduralne, przyjmuje TokenStream jako
wejście i produkuje TokenStream jako wyjście. Typ TokenStream jest
zdefiniowany przez pakiet proc_macro, który jest dołączony do Rust i
reprezentuje sekwencję tokenów. To jest rdzeń makra: Kod źródłowy, na którym
makro operuje, tworzy wejściowy TokenStream, a kod, który makro produkuje,
jest wyjściowym TokenStream. Funkcja posiada również dołączony atrybut,
który określa, jaki rodzaj makra proceduralnego tworzymy. Możemy mieć wiele
rodzajów makr proceduralnych w tym samym pakiecie.
Przyjrzyjmy się różnym rodzajom makr proceduralnych. Zaczniemy od niestandardowego
makra derive, a następnie wyjaśnimy małe różnice, które sprawiają, że
inne formy są odmienne.
Niestandardowe makra derive
Stwórzmy pakiet o nazwie hello_macro, który definiuje cechę nazwaną
HelloMacro z jedną skojarzoną funkcją nazwaną hello_macro. Zamiast
wymagać od naszych użytkowników implementowania cechy HelloMacro dla każdego
z ich typów, dostarczymy makro proceduralne, aby użytkownicy mogli opatrzyć
swój typ adnotacją #[derive(HelloMacro)], aby uzyskać domyślną
implementację funkcji hello_macro. Domyślna implementacja wyświetli
Hello, Macro! My name is TypeName!, gdzie TypeName to nazwa typu, na
którym ta cecha została zdefiniowana. Innymi słowy, napiszemy pakiet, który
umożliwi innemu programiście napisanie kodu takiego jak w Listing 20-37
przy użyciu naszego pakietu.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Ten kod wyświetli Hello, Macro! My name is Pancakes! po zakończeniu. Pierwszym
krokiem jest stworzenie nowego pakietu bibliotecznego w ten sposób:
$ cargo new hello_macro --lib
Następnie, w Listing 20-38, zdefiniujemy cechę HelloMacro i jej skojarzoną
funkcję.
pub trait HelloMacro {
fn hello_macro();
}deriveMamy cechę i jej funkcję. W tym momencie użytkownik naszego pakietu mógłby implementować cechę, aby osiągnąć pożądaną funkcjonalność, jak w Listing 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}HelloMacroJednak musieliby napisać blok implementacji dla każdego typu, którego chcieliby
użyć z hello_macro; chcemy ich oszczędzić tego wysiłku.
Dodatkowo, nie możemy jeszcze dostarczyć funkcji hello_macro z domyślną
implementacją, która wyświetli nazwę typu, na którym zaimplementowano cechę:
Rust nie posiada możliwości refleksji, więc nie może odczytać nazwy typu w
czasie wykonania. Potrzebujemy makra do generowania kodu w czasie kompilacji.
Następnym krokiem jest zdefiniowanie makra proceduralnego. W chwili pisania
tego tekstu makra proceduralne muszą znajdować się we własnym pakiecie.
Ostatecznie to ograniczenie może zostać zniesione. Konwencja strukturyzowania
pakietów i pakietów makr jest następująca: Dla pakietu o nazwie foo,
pakiet makra proceduralnego derive nazywa się foo_derive. Stwórzmy nowy
pakiet o nazwie hello_macro_derive w projekcie hello_macro:
$ cargo new hello_macro_derive --lib
Nasze dwa pakiety są ściśle powiązane, dlatego tworzymy pakiet makra
proceduralnego w katalogu naszego pakietu hello_macro. Jeśli zmienimy
definicję cechy w hello_macro, będziemy musieli również zmienić implementację
makra proceduralnego w hello_macro_derive. Oba pakiety będą musiały być
publikowane oddzielnie, a programiści używający tych pakietów będą musieli
dodać je oba jako zależności i wprowadzić je oba do zasięgu. Moglibyśmy zamiast
tego sprawić, by pakiet hello_macro używał hello_macro_derive jako zależności
i ponownie eksportował kod makra proceduralnego. Jednak sposób, w jaki
strukturyzowaliśmy projekt, umożliwia programistom używanie hello_macro
nawet jeśli nie chcą funkcjonalności derive.
Musimy zadeklarować pakiet hello_macro_derive jako pakiet makra
proceduralnego. Będziemy również potrzebować funkcjonalności z pakietów syn
i quote, jak zobaczysz za chwilę, więc musimy dodać je jako zależności.
Dodaj następujące wiersze do pliku Cargo.toml dla hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Aby rozpocząć definiowanie makra proceduralnego, umieść kod z Listing 20-40
w pliku src/lib.rs pakietu hello_macro_derive. Zauważ, że ten kod nie
skompiluje się, dopóki nie dodamy definicji funkcji impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}Zauważ, że podzieliliśmy kod na funkcję hello_macro_derive, która jest
odpowiedzialna za parsowanie TokenStream, oraz funkcję impl_hello_macro,
która jest odpowiedzialna za przekształcanie drzewa składni: to sprawia,
że pisanie makra proceduralnego jest wygodniejsze. Kod w zewnętrznej funkcji
(w tym przypadku hello_macro_derive) będzie taki sam dla prawie każdego
pakietu makr proceduralnych, który zobaczysz lub stworzysz. Kod, który określisz
w ciele funkcji wewnętrznej (w tym przypadku impl_hello_macro), będzie
inny w zależności od celu twojego makra proceduralnego.
Wprowadziliśmy trzy nowe pakiety: proc_macro, syn,
oraz quote. Pakiet proc_macro jest dostarczany
z Rust, więc nie musieliśmy dodawać go do zależności w Cargo.toml. Pakiet
proc_macro to API kompilatora, które pozwala nam czytać i manipulować kodem
Rust z naszego kodu.
Pakiet syn parsuje kod Rust ze stringa do struktury danych, na której możemy
wykonywać operacje. Pakiet quote przekształca struktury danych syn z
powrotem w kod Rust. Te pakiety znacznie upraszczają parsowanie wszelkiego
rodzaju kodu Rust, który możemy chcieć obsłużyć: Napisanie pełnego parsera dla
kodu Rust nie jest prostym zadaniem.
Funkcja hello_macro_derive zostanie wywołana, gdy użytkownik naszej
biblioteki określi #[derive(HelloMacro)] dla typu. Jest to możliwe, ponieważ
otagowaliśmy tutaj funkcję hello_macro_derive za pomocą proc_macro_derive
i określiliśmy nazwę HelloMacro, która pasuje do nazwy naszej cechy; jest
to konwencja, której przestrzega większość makr proceduralnych.
Funkcja hello_macro_derive najpierw konwertuje input z TokenStream na
strukturę danych, którą możemy następnie interpretować i na której wykonywać
operacje. W tym miejscu do gry wkracza syn. Funkcja parse w syn pobiera
TokenStream i zwraca strukturę DeriveInput reprezentującą sparsowany kod
Rust. Listing 20-41 pokazuje odpowiednie części struktury DeriveInput,
którą otrzymujemy po sparsowaniu ciągu struct Pancakes;.
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}DeriveInput, którą otrzymujemy podczas parsowania kodu posiadającego atrybut makra w Listing 20-37Pola tej struktury pokazują, że sparsowany kod Rust to struktura jednostkowa
z ident (identyfikatorem, czyli nazwą) Pancakes. W tej strukturze jest
więcej pól opisujących wszelkiego rodzaju kod Rust; sprawdź dokumentację
syn dla DeriveInput po więcej informacji.
Wkrótce zdefiniujemy funkcję impl_hello_macro, w której zbudujemy nowy kod
Rust, który chcemy uwzględnić. Ale zanim to zrobimy, zauważ, że wyjście dla
naszego makra derive jest również TokenStream. Zwrócony TokenStream jest
dodawany do kodu, który piszą użytkownicy naszego pakietu, więc kiedy skompilują
swój pakiet, uzyskają dodatkową funkcjonalność, którą zapewniamy w zmodyfikowanym
TokenStream.
Być może zauważyłeś, że wywołujemy unwrap, aby spowodować panikę funkcji
hello_macro_derive, jeśli wywołanie funkcji syn::parse tutaj zakończy się
niepowodzeniem. Konieczne jest, aby nasze makro proceduralne wywołało panikę
w przypadku błędów, ponieważ funkcje proc_macro_derive muszą zwracać
TokenStream zamiast Result, aby były zgodne z API makr proceduralnych.
Uprościliśmy ten przykład, używając unwrap; w kodzie produkcyjnym powinieneś
dostarczyć bardziej szczegółowe komunikaty o błędach, używając panic! lub
expect.
Teraz, gdy mamy kod do przekształcenia adnotowanego kodu Rust z TokenStream
w instancję DeriveInput, wygenerujmy kod, który implementuje cechę
HelloMacro na adnotowanym typie, jak pokazano w Listing 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}HelloMacro przy użyciu sparsowanego kodu RustUzyskujemy instancję struktury Ident zawierającą nazwę (identyfikator)
adnotowanego typu za pomocą ast.ident. Struktura w Listing 20-41 pokazuje,
że gdy uruchomimy funkcję impl_hello_macro na kodzie z Listing 20-37,
ident, który otrzymamy, będzie miał pole ident z wartością "Pancakes".
W ten sposób zmienna name w Listing 20-42 będzie zawierać instancję
struktury Ident, która po wydrukowaniu będzie ciągiem znaków "Pancakes",
nazwą struktury z Listing 20-37.
Makro quote! pozwala nam zdefiniować kod Rust, który chcemy zwrócić.
Kompilator oczekuje czegoś innego niż bezpośredni wynik wykonania makra quote!,
więc musimy przekonwertować go na TokenStream. Robimy to, wywołując metodę
into, która konsumuje tę pośrednią reprezentację i zwraca wartość
wymaganego typu TokenStream.
Makro quote! zapewnia również bardzo fajne mechanizmy szablonowania: Możemy
wpisać #name, a quote! zastąpi to wartością zmiennej name. Możesz nawet
wykonywać pewne powtórzenia podobnie do tego, jak działają zwykłe makra.
Sprawdź dokumentację pakietu quote dla szczegółowego
wprowadzenia.
Chcemy, aby nasze makro proceduralne generowało implementację naszej cechy
HelloMacro dla typu, który użytkownik adnotował, co możemy uzyskać za
pomocą #name. Implementacja cechy ma jedną funkcję hello_macro, której
ciało zawiera funkcjonalność, którą chcemy zapewnić: wyświetlenie Hello, Macro! My name is,
a następnie nazwy adnotowanego typu.
Używane tutaj makro stringify! jest wbudowane w Rust. Przyjmuje ono wyrażenie
Rust, takie jak 1 + 2, i w czasie kompilacji zamienia to wyrażenie w literał
ciągu znaków, taki jak "1 + 2". Różni się to od format! lub println!,
które są makrami, które ewaluują wyrażenie, a następnie zamieniają wynik na
String. Istnieje możliwość, że wejście #name może być wyrażeniem do
wydrukowania dosłownie, dlatego używamy stringify!. Użycie stringify!
oszczędza również alokację, konwertując #name na literał ciągu znaków w
czasie kompilacji.
W tym momencie cargo build powinno zakończyć się pomyślnie zarówno w
hello_macro, jak i hello_macro_derive. Podłączmy te pakiety do kodu w
Listing 20-37, aby zobaczyć makro proceduralne w akcji! Utwórz nowy projekt
binarny w katalogu projects za pomocą cargo new pancakes. Musimy dodać
hello_macro i hello_macro_derive jako zależności w pliku Cargo.toml
pakietu pancakes. Jeśli publikujesz swoje wersje hello_macro i
hello_macro_derive na crates.io,
byłyby to zwykłe zależności; jeśli nie, możesz określić je jako zależności
path w następujący sposób:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Umieść kod z Listing 20-37 w pliku src/main.rs i uruchom cargo run:
powinien wyświetlić Hello, Macro! My name is Pancakes!. Implementacja cechy
HelloMacro z makra proceduralnego została włączona bez konieczności
implementowania jej przez pakiet pancakes; #[derive(HelloMacro)] dodało
implementację cechy.
Następnie zbadamy, jak inne rodzaje makr proceduralnych różnią się od
niestandardowych makr derive.
Makra podobne do atrybutów
Makra podobne do atrybutów są podobne do niestandardowych makr derive, ale
zamiast generować kod dla atrybutu derive, pozwalają tworzyć nowe atrybuty.
Są również bardziej elastyczne: derive działa tylko dla struktur i enumów;
atrybuty mogą być stosowane również do innych elementów, takich jak funkcje.
Oto przykład użycia makra podobnego do atrybutu. Powiedzmy, że masz atrybut o
nazwie route, który adnotuje funkcje podczas używania frameworka
aplikacji webowych:
#[route(GET, "/")]
fn index() {Ten atrybut #[route] byłby zdefiniowany przez framework jako makro
proceduralne. Sygnatura funkcji definicji makra wyglądałaby tak:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Tutaj mamy dwa parametry typu TokenStream. Pierwszy dotyczy zawartości
atrybutu: część GET, "/". Drugi to ciało elementu, do którego atrybut jest
dołączony: w tym przypadku fn index() {} i reszta ciała funkcji.
Poza tym, makra podobne do atrybutów działają tak samo jak niestandardowe
makra derive: Tworzysz pakiet z typem pakietu proc-macro i implementujesz
funkcję, która generuje kod, którego potrzebujesz!
Makra podobne do funkcji
Makra podobne do funkcji definiują makra, które wyglądają jak wywołania
funkcji. Podobnie jak makra macro_rules!, są bardziej elastyczne niż funkcje;
na przykład mogą przyjmować nieznaną liczbę argumentów. Jednak makra
macro_rules! mogą być definiowane tylko za pomocą składni podobnej do
match, którą omówiliśmy wcześniej w sekcji „Makra deklaratywne do ogólnego
metaprogramowania”. Makra podobne do funkcji przyjmują
parametr TokenStream, a ich definicja manipuluje tym TokenStream za pomocą
kodu Rust, tak jak robią to inne dwa typy makr proceduralnych. Przykładem
makra podobnego do funkcji jest makro sql!, które może być wywołane w
następujący sposób:
let sql = sql!(SELECT * FROM posts WHERE id=1);To makro parsowałoby instrukcję SQL wewnątrz i sprawdzałoby, czy jest
składniowo poprawna, co jest znacznie bardziej złożonym przetwarzaniem niż
to, co może wykonać makro macro_rules!. Makro sql! byłoby zdefiniowane tak:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Ta definicja jest podobna do sygnatury makra derive: Otrzymujemy tokeny,
które znajdują się w nawiasach, i zwracamy kod, który chcieliśmy wygenerować.
Podsumowanie
Uff! Teraz masz w swoim zestawie narzędzi Rust kilka funkcji, których prawdopodobnie nie będziesz często używać, ale będziesz wiedzieć, że są dostępne w bardzo szczególnych okolicznościach. Przedstawiliśmy kilka złożonych tematów, abyś mógł rozpoznać te koncepcje i składnię, gdy napotkasz je w sugestiach komunikatów o błędach lub w cudzym kodzie. Użyj tego rozdziału jako odniesienia, które poprowadzi cię do rozwiązań.
Następnie wprowadzimy w życie wszystko, co omówiliśmy w całej książce, i zrobimy jeszcze jeden projekt!
Projekt Końcowy: Budowanie Wielowątkowego Serwera WWW
To była długa podróż, ale dotarliśmy do końca książki. W tym rozdziale zbudujemy razem jeszcze jeden projekt, aby zademonstrować niektóre z koncepcji, które omówiliśmy w ostatnich rozdziałach, a także podsumować niektóre wcześniejsze lekcje.
Na nasz końcowy projekt stworzymy serwer WWW, który wyświetla „Witaj!” i wygląda jak na Rysunku 21-1 w przeglądarce internetowej.
Oto nasz plan budowy serwera WWW:
- Naucz się trochę o TCP i HTTP.
- Nasłuchuj połączeń TCP na gnieździe.
- Parsuj niewielką liczbę żądań HTTP.
- Utwórz poprawną odpowiedź HTTP.
- Popraw przepustowość naszego serwera za pomocą puli wątków.
Rysunek 21-1: Nasz końcowy wspólny projekt
Zanim zaczniemy, powinniśmy wspomnieć o dwóch szczegółach. Po pierwsze, metoda, której użyjemy, nie będzie najlepszym sposobem na zbudowanie serwera WWW w Rust. Członkowie społeczności opublikowali wiele gotowych do produkcji pakietów dostępnych na crates.io, które dostarczają bardziej kompletne implementacje serwera WWW i puli wątków niż te, które zbudujemy. Jednak naszym zamiarem w tym rozdziale jest pomoc w nauce, a nie wybieranie łatwej drogi. Ponieważ Rust jest językiem programowania systemowego, możemy wybrać poziom abstrakcji, z którym chcemy pracować i zejść na niższy poziom, niż jest to możliwe lub praktyczne w innych językach.
Po drugie, nie będziemy tutaj używać async i await. Budowanie puli wątków
to wystarczająco duże wyzwanie samo w sobie, bez dodawania budowania
środowiska wykonawczego async! Jednakże, zauważymy, jak async i await
mogą być stosowane do niektórych z tych samych problemów, które zobaczymy w
tym rozdziale. Ostatecznie, jak zauważyliśmy w Rozdziale 17, wiele środowisk
wykonawczych async używa pul wątków do zarządzania swoją pracą.
Dlatego napiszemy podstawowy serwer HTTP i pulę wątków ręcznie, abyś mógł poznać ogólne idee i techniki stojące za pakietami, których możesz użyć w przyszłości.
Budowanie jednowątkowego serwera WWW
Budowanie jednowątkowego serwera WWW
Zaczniemy od uruchomienia jednowątkowego serwera WWW. Zanim zaczniemy, spójrzmy na szybki przegląd protokołów zaangażowanych w budowanie serwerów WWW. Szczegóły tych protokołów wykraczają poza zakres tej książki, ale krótki przegląd dostarczy ci niezbędnych informacji.
Dwa główne protokoły zaangażowane w serwery WWW to Hypertext Transfer Protocol (HTTP) i Transmission Control Protocol (TCP). Oba protokoły są protokołami typu żądanie-odpowiedź, co oznacza, że klient inicjuje żądania, a serwer nasłuchuje żądań i dostarcza klientowi odpowiedź. Zawartość tych żądań i odpowiedzi jest definiowana przez protokoły.
TCP to protokół niższego poziomu, który opisuje szczegóły, jak informacje trafiają z jednego serwera do drugiego, ale nie precyzuje, czym są te informacje. HTTP buduje na TCP, definiując zawartość żądań i odpowiedzi. Technicznie możliwe jest używanie HTTP z innymi protokołami, ale w zdecydowanej większości przypadków HTTP wysyła swoje dane przez TCP. Będziemy pracować z surowymi bajtami żądań i odpowiedzi TCP i HTTP.
Nasłuchiwanie połączeń TCP
Nasz serwer WWW musi nasłuchiwać połączeń TCP, więc to jest pierwsza część, nad którą będziemy pracować. Biblioteka standardowa oferuje moduł std::net, który nam to umożliwia. Stwórzmy nowy projekt w zwykły sposób:
$ cargo new hello
Utworzono projekt binarny (aplikacja) `hello`
$ cd hello
Teraz wprowadź kod z Listingu 21-1 do src/main.rs, aby rozpocząć. Ten kod będzie nasłuchiwał przy lokalnym adresie 127.0.0.1:7878 na przychodzące strumienie TCP. Kiedy otrzyma przychodzący strumień, wydrukuje Connection established!.
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}Używając TcpListener, możemy nasłuchiwać połączeń TCP pod adresem 127.0.0.1:7878. W adresie, sekcja przed dwukropkiem to adres IP reprezentujący twój komputer (jest taki sam na każdym komputerze i nie reprezentuje konkretnie komputera autorów), a 7878 to port. Wybraliśmy ten port z dwóch powodów: HTTP nie jest zwykle akceptowany na tym porcie, więc nasz serwer raczej nie będzie kolidował z żadnym innym serwerem WWW, który możesz mieć uruchomiony na swojej maszynie, a 7878 to rust wpisane na telefonie.
Funkcja bind w tym scenariuszu działa jak funkcja new w tym sensie, że zwróci nową instancję TcpListener. Funkcja nazywa się bind, ponieważ w sieciach połączenie z portem w celu nasłuchiwania jest znane jako „wiązanie się z portem”.
Funkcja bind zwraca Result<T, E>, co wskazuje, że wiązanie może się nie powieść, na przykład, gdybyśmy uruchomili dwie instancje naszego programu i tym samym mieli dwa programy nasłuchujące na tym samym porcie. Ponieważ piszemy podstawowy serwer wyłącznie w celach edukacyjnych, nie będziemy martwić się o obsługę tego typu błędów; zamiast tego używamy unwrap, aby zatrzymać program, jeśli wystąpią błędy.
Metoda incoming na TcpListener zwraca iterator, który dostarcza nam sekwencję strumieni (dokładniej, strumieni typu TcpStream). Pojedynczy strumień reprezentuje otwarte połączenie między klientem a serwerem. Połączenie to nazwa pełnego procesu żądanie-odpowiedź, w którym klient łączy się z serwerem, serwer generuje odpowiedź i serwer zamyka połączenie. W związku z tym będziemy czytać z TcpStream, aby zobaczyć, co klient wysłał, a następnie zapiszemy naszą odpowiedź do strumienia, aby wysłać dane z powrotem do klienta. Ogólnie rzecz biorąc, ta pętla for będzie przetwarzać każde połączenie po kolei i generować serię strumieni, które będziemy obsługiwać.
Na razie nasza obsługa strumienia polega na wywołaniu unwrap, aby zakończyć program, jeśli strumień ma jakieś błędy; jeśli błędów nie ma, program wyświetla komunikat. W następnym listingu dodamy więcej funkcjonalności dla przypadku sukcesu. Powodem, dla którego możemy otrzymać błędy z metody incoming, gdy klient łączy się z serwerem, jest to, że nie iterujemy faktycznie po połączeniach. Zamiast tego iterujemy po próbach połączenia. Połączenie może się nie powieść z wielu powodów, z których wiele jest specyficznych dla systemu operacyjnego. Na przykład, wiele systemów operacyjnych ma limit liczby jednoczesnych otwartych połączeń, które mogą obsługiwać; nowe próby połączenia powyżej tej liczby będą generować błąd, dopóki niektóre z otwartych połączeń nie zostaną zamknięte.
Spróbujmy uruchomić ten kod! Wywołaj cargo run w terminalu, a następnie załaduj 127.0.0.1:7878 w przeglądarce internetowej. Przeglądarka powinna wyświetlić komunikat o błędzie, taki jak „Connection reset”, ponieważ serwer obecnie nie wysyła żadnych danych. Ale kiedy spojrzysz na swój terminal, powinieneś zobaczyć kilka komunikatów, które zostały wydrukowane, gdy przeglądarka połączyła się z serwerem!
Uruchamianie `target/debug/hello`
Połączenie nawiązane!
Połączenie nawiązane!
Połączenie nawiązane!
Czasami zobaczysz wiele komunikatów wydrukowanych dla jednego żądania przeglądarki; powodem może być to, że przeglądarka wysyła żądanie o stronę, a także żądanie o inne zasoby, takie jak ikona favicon.ico, która pojawia się w zakładce przeglądarki.
Może się również zdarzyć, że przeglądarka próbuje połączyć się z serwerem wielokrotnie, ponieważ serwer nie odpowiada żadnymi danymi. Gdy stream wychodzi poza zakres i jest porzucony na końcu pętli, połączenie jest zamykane w ramach implementacji drop. Przeglądarki czasami radzą sobie z zamkniętymi połączeniami, ponawiając próbę, ponieważ problem może być tymczasowy.
Przeglądarki czasami otwierają również wiele połączeń z serwerem bez wysyłania żadnych żądań, aby w przypadku późniejszego wysłania żądań, te żądania mogły nastąpić szybciej. Kiedy to nastąpi, nasz serwer zobaczy każde połączenie, niezależnie od tego, czy istnieją jakiekolwiek żądania przez to połączenie. Robi tak wiele wersji przeglądarek opartych na Chrome, na przykład; możesz wyłączyć tę optymalizację, używając trybu przeglądania prywatnego lub innej przeglądarki.
Ważnym czynnikiem jest to, że z powodzeniem uzyskaliśmy uchwyt do połączenia TCP!
Pamiętaj, aby zatrzymać program, naciskając ctrl-C, gdy skończysz uruchamiać określoną wersję kodu. Następnie uruchom program ponownie, wywołując polecenie cargo run po wprowadzeniu każdej serii zmian w kodzie, aby upewnić się, że uruchamiasz najnowszy kod.
Odczytywanie żądania
Zaimplementujmy funkcjonalność do odczytywania żądania z przeglądarki! Aby oddzielić kwestie nawiązania połączenia od wykonania jakiejś akcji z nim związanej, rozpoczniemy nową funkcję do przetwarzania połączeń. W tej nowej funkcji handle_connection będziemy czytać dane ze strumienia TCP i drukować je, abyśmy mogli zobaczyć dane wysyłane z przeglądarki. Zmień kod, aby wyglądał jak na Listingu 21-2.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Żądanie: {http_request:#?}");
}Wprowadzamy std::io::BufReader i std::io::prelude do zakresu, aby uzyskać dostęp do cech i typów, które pozwalają nam czytać i zapisywać do strumienia. W pętli for w funkcji main, zamiast wyświetlać komunikat informujący o nawiązaniu połączenia, wywołujemy teraz nową funkcję handle_connection i przekazujemy jej stream.
W funkcji handle_connection tworzymy nową instancję BufReader, która opakowuje referencję do stream. BufReader dodaje buforowanie, zarządzając za nas wywołaniami metod cechy std::io::Read.
Tworzymy zmienną o nazwie http_request, aby zbierać linie żądania, które przeglądarka wysyła do naszego serwera. Wskazujemy, że chcemy zebrać te linie w wektorze, dodając adnotację typu Vec<_>.
BufReader implementuje cechę std::io::BufRead, która dostarcza metodę lines. Metoda lines zwraca iterator Result<String, std::io::Error>, dzieląc strumień danych za każdym razem, gdy zobaczy znak nowej linii. Aby uzyskać każdy String, mapujemy i unwrapujemy każdy Result. Result może być błędem, jeśli dane nie są prawidłowym UTF-8 lub jeśli wystąpił problem podczas czytania ze strumienia. Ponownie, program produkcyjny powinien obsługiwać te błędy bardziej elegancko, ale my decydujemy się na zatrzymanie programu w przypadku błędu dla uproszczenia.
Przeglądarka sygnalizuje koniec żądania HTTP, wysyłając dwa znaki nowej linii z rzędu, więc aby uzyskać jedno żądanie ze strumienia, pobieramy linie, dopóki nie otrzymamy linii, która jest pustym ciągiem znaków. Po zebraniu linii do wektora, drukujemy je, używając ładnego formatowania debugowania, abyśmy mogli przyjrzeć się instrukcjom, które przeglądarka internetowa wysyła do naszego serwera.
Spróbujmy tego kodu! Uruchom program i ponownie wyślij żądanie w przeglądarce internetowej. Zauważ, że nadal otrzymamy stronę błędu w przeglądarce, ale wynik naszego programu w terminalu będzie teraz wyglądał podobnie do tego:
$ cargo run
Kompilowanie hello v0.1.0 (file:///projects/hello)
Zakończono `dev` profil [nieoptymalny + debuginfo] cel(e) w 0.42s
Uruchamianie `target/debug/hello`
Żądanie: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
W zależności od przeglądarki, możesz otrzymać nieco inny wynik. Teraz, gdy drukujemy dane żądania, możemy zobaczyć, dlaczego otrzymujemy wiele połączeń z jednego żądania przeglądarki, patrząc na ścieżkę po GET w pierwszej linii żądania. Jeśli powtarzające się połączenia wszystkie żądają /, wiemy, że przeglądarka próbuje wielokrotnie pobrać /, ponieważ nie otrzymuje odpowiedzi z naszego programu.
Przeanalizujmy te dane żądania, aby zrozumieć, o co przeglądarka prosi nasz program.
Bliższe spojrzenie na żądanie HTTP
HTTP to protokół tekstowy, a żądanie ma następujący format:
Metoda Identyfikator-żądania Wersja-HTTP CRLF
nagłówki CRLF
ciało-wiadomości
Pierwsza linia to linia żądania, która zawiera informacje o tym, czego klient żąda. Pierwsza część linii żądania wskazuje używaną metodę, taką jak GET lub POST, która opisuje, w jaki sposób klient wysyła to żądanie. Nasz klient użył żądania GET, co oznacza, że prosi o informacje.
Następną częścią linii żądania jest /, która wskazuje uniform resource identifier (URI), o który prosi klient: URI jest prawie, ale niezupełnie, tym samym co uniform resource locator (URL). Różnica między URI a URL nie jest istotna dla naszych celów w tym rozdziale, ale specyfikacja HTTP używa terminu URI, więc możemy tutaj po prostu mentalnie zastąpić URL przez URI.
Ostatnią częścią jest wersja HTTP używana przez klienta, a następnie linia żądania kończy się sekwencją CRLF. (CRLF to skrót od carriage return i line feed, co są terminami z czasów maszyn do pisania!) Sekwencję CRLF można również zapisać jako \r\n, gdzie \r to znak powrotu karetki, a \n to znak nowej linii. Sekwencja CRLF oddziela linię żądania od reszty danych żądania. Zauważ, że gdy CRLF jest drukowane, widzimy początek nowej linii, a nie \r\n.
Patrząc na dane linii żądania, które otrzymaliśmy po uruchomieniu naszego programu, widzimy, że GET to metoda, / to URI żądania, a HTTP/1.1 to wersja.
Po linii żądania, pozostałe linie zaczynające się od Host: to nagłówki. Żądania GET nie mają ciała.
Spróbuj wysłać żądanie z innej przeglądarki lub poprosić o inny adres, na przykład 127.0.0.1:7878/test, aby zobaczyć, jak zmieniają się dane żądania.
Teraz, gdy wiemy, o co prosi przeglądarka, wyślijmy z powrotem jakieś dane!
Pisanie odpowiedzi
Zaimplementujemy wysyłanie danych w odpowiedzi na żądanie klienta. Odpowiedzi mają następujący format:
Wersja-HTTP Kod-statusu Fraza-powodowa CRLF
nagłówki CRLF
ciało-wiadomości
Pierwsza linia to linia statusu, która zawiera wersję HTTP używaną w odpowiedzi, numeryczny kod statusu, który podsumowuje wynik żądania, oraz frazę powodową, która zawiera tekstowy opis kodu statusu. Po sekwencji CRLF następują nagłówki, kolejna sekwencja CRLF i treść odpowiedzi.
Poniżej znajduje się przykładowa odpowiedź, która używa protokołu HTTP w wersji 1.1 i ma kod statusu 200, frazę „OK”, brak nagłówków i brak treści:
HTTP/1.1 200 OK\r\n\r\n
Kod statusu 200 to standardowa odpowiedź sukcesu. Tekst to mała, udana odpowiedź HTTP. Zapiszmy to do strumienia jako naszą odpowiedź na udane żądanie! Z funkcji handle_connection usuń println!, które drukowało dane żądania, i zastąp je kodem z Listingu 21-3.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r\n\r\n";
stream.write_all(response.as_bytes()).unwrap();
}Pierwsza nowa linia definiuje zmienną response, która przechowuje dane wiadomości o sukcesie. Następnie wywołujemy as_bytes na naszym response, aby przekonwertować dane ciągu na bajty. Metoda write_all na stream przyjmuje &[u8] i wysyła te bajty bezpośrednio przez połączenie. Ponieważ operacja write_all może zakończyć się niepowodzeniem, używamy unwrap dla każdego wyniku błędu, tak jak poprzednio. Ponownie, w prawdziwej aplikacji, należałoby tutaj dodać obsługę błędów.
Dzięki tym zmianom, uruchommy nasz kod i wyślijmy żądanie. Nie drukujemy już żadnych danych do terminala, więc nie zobaczymy żadnego wyniku poza danymi z Cargo. Gdy załadujesz 127.0.0.1:7878 w przeglądarce internetowej, powinieneś otrzymać pustą stronę zamiast błędu. Właśnie ręcznie zakodowałeś odbieranie żądania HTTP i wysyłanie odpowiedzi!
Zwracanie prawdziwego kodu HTML
Zaimplementujmy funkcjonalność zwracania czegoś więcej niż pustej strony. Utwórz nowy plik hello.html w katalogu głównym swojego projektu, a nie w katalogu src. Możesz wpisać dowolny kod HTML; Listing 21-4 pokazuje jedną z możliwości.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Witaj!</title>
</head>
<body>
<h1>Witaj!</h1>
<p>Cześć z Rust</p>
</body>
</html>
Jest to minimalny dokument HTML5 z nagłówkiem i tekstem. Aby zwrócić go z serwera po otrzymaniu żądania, zmodyfikujemy handle_connection, jak pokazano na Listingu 21-5, aby odczytać plik HTML, dodać go do odpowiedzi jako ciało i wysłać.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Dodaliśmy fs do instrukcji use, aby wprowadzić moduł systemu plików biblioteki standardowej do zakresu. Kod do odczytywania zawartości pliku do ciągu znaków powinien wyglądać znajomo; użyliśmy go, gdy czytaliśmy zawartość pliku dla naszego projektu I/O w Listingu 12-4.
Następnie używamy format! do dodania zawartości pliku jako treści odpowiedzi sukcesu. Aby zapewnić prawidłową odpowiedź HTTP, dodajemy nagłówek Content-Length, który jest ustawiony na rozmiar naszej treści odpowiedzi – w tym przypadku, rozmiar hello.html.
Uruchom ten kod za pomocą cargo run i załaduj 127.0.0.1:7878 w swojej przeglądarce; powinieneś zobaczyć wyrenderowany HTML!
Obecnie ignorujemy dane żądania w http_request i po prostu bezwarunkowo wysyłamy z powrotem zawartość pliku HTML. Oznacza to, że jeśli spróbujesz zażądać 127.0.0.1:7878/cos-innego w przeglądarce, nadal otrzymasz tę samą odpowiedź HTML. W tej chwili nasz serwer jest bardzo ograniczony i nie robi tego, co robi większość serwerów WWW. Chcemy dostosować nasze odpowiedzi w zależności od żądania i wysyłać plik HTML tylko dla dobrze sformułowanego żądania do /.
Walidacja żądania i selektywne odpowiadanie
W tej chwili nasz serwer WWW zwróci HTML w pliku niezależnie od tego, co klient zażądał. Dodajmy funkcjonalność, aby sprawdzić, czy przeglądarka żąda / przed zwróceniem pliku HTML i aby zwrócić błąd, jeśli przeglądarka zażąda czegoś innego. W tym celu musimy zmodyfikować handle_connection, jak pokazano na Listingu 21-6. Ten nowy kod sprawdza zawartość otrzymanego żądania w porównaniu z tym, jak wygląda żądanie do /, i dodaje bloki if i else, aby traktować żądania inaczej.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// inne żądanie
}
}Będziemy tylko patrzeć na pierwszą linię żądania HTTP, więc zamiast odczytywać całe żądanie do wektora, wywołujemy next, aby pobrać pierwszy element z iteratora. Pierwszy unwrap zajmuje się Option i zatrzymuje program, jeśli iterator nie ma żadnych elementów. Drugi unwrap obsługuje Result i ma taki sam efekt jak unwrap, który został dodany w map w Listingu 21-2.
Następnie sprawdzamy request_line, aby zobaczyć, czy jest równa linii żądania GET do ścieżki /. Jeśli tak, blok if zwraca zawartość naszego pliku HTML.
Jeśli request_line nie jest równe żądaniu GET do ścieżki /, oznacza to, że otrzymaliśmy jakieś inne żądanie. Za chwilę dodamy kod do bloku else, aby odpowiedzieć na wszystkie inne żądania.
Uruchom ten kod teraz i zażądaj 127.0.0.1:7878; powinieneś otrzymać HTML z hello.html. Jeśli wyślesz jakiekolwiek inne żądanie, takie jak 127.0.0.1:7878/cos-innego, otrzymasz błąd połączenia, podobny do tych, które widziałeś, uruchamiając kod z Listingu 21-1 i Listingu 21-2.
Teraz dodajmy kod z Listingu 21-7 do bloku else, aby zwrócić odpowiedź z kodem statusu 404, który sygnalizuje, że zawartość dla żądania nie została znaleziona. Zwrócimy również kod HTML dla strony, aby przeglądarka mogła ją wyrenderować, wskazując odpowiedź użytkownikowi końcowemu.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
// --snip--
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
}Tutaj nasza odpowiedź zawiera linię statusu z kodem statusu 404 i frazą powodu NOT FOUND. Ciałem odpowiedzi będzie HTML z pliku 404.html. Będziesz musiał utworzyć plik 404.html obok hello.html dla strony błędu; ponownie, możesz użyć dowolnego kodu HTML, jaki chcesz, lub użyć przykładowego kodu HTML z Listingu 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Witaj!</title>
</head>
<body>
<h1>Ups!</h1>
<p>Przepraszam, nie wiem, o co prosisz.</p>
</body>
</html>
Dzięki tym zmianom uruchom ponownie swój serwer. Żądanie 127.0.0.1:7878 powinno zwrócić zawartość pliku hello.html, a każde inne żądanie, takie jak 127.0.0.1:7878/foo, powinno zwrócić kod HTML błędu z 404.html.
Refaktoryzacja
W tej chwili bloki if i else mają wiele powtórzeń: oba odczytują pliki i zapisują zawartość plików do strumienia. Jedyne różnice to linia statusu i nazwa pliku. Uczyńmy kod bardziej zwięzłym, wyodrębniając te różnice w osobne linie if i else, które przypiszą wartości linii statusu i nazwy pliku do zmiennych; możemy następnie użyć tych zmiennych bezwarunkowo w kodzie do odczytu pliku i zapisu odpowiedzi. Listing 21-9 pokazuje wynikowy kod po zastąpieniu dużych bloków if i else.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Teraz bloki if i else zwracają tylko odpowiednie wartości dla linii statusu i nazwy pliku w krotce; następnie używamy dekompozycji do przypisania tych dwóch wartości do status_line i filename za pomocą wzorca w instrukcji let, jak omówiono w Rozdziale 19.
Poprzednio zduplikowany kod znajduje się teraz poza blokami if i else i używa zmiennych status_line i filename. Ułatwia to dostrzeżenie różnicy między dwoma przypadkami, a także oznacza, że mamy tylko jedno miejsce do aktualizacji kodu, jeśli chcemy zmienić sposób działania odczytu plików i zapisu odpowiedzi. Zachowanie kodu z Listingu 21-9 będzie takie samo jak z Listingu 21-7.
Świetnie! Mamy teraz prosty serwer WWW w około 40 liniach kodu Rust, który odpowiada na jedno żądanie stroną treści i na wszystkie inne żądania odpowiedzią 404.
Obecnie nasz serwer działa w jednym wątku, co oznacza, że może obsługiwać tylko jedno żądanie na raz. Zbadajmy, jak to może być problemem, symulując kilka wolnych żądań. Następnie naprawimy to, aby nasz serwer mógł obsługiwać wiele żądań jednocześnie.
Od serwera jednowątkowego do wielowątkowego
Od serwera jednowątkowego do wielowątkowego
Obecnie serwer będzie przetwarzał każde żądanie po kolei, co oznacza, że nie przetworzy drugiego połączenia, dopóki pierwsze połączenie nie zostanie zakończone. Gdyby serwer otrzymywał coraz więcej żądań, to wykonanie sekwencyjne byłoby coraz mniej optymalne. Jeśli serwer otrzyma żądanie, którego przetwarzanie zajmuje dużo czasu, kolejne żądania będą musiały czekać, aż długie żądanie zostanie zakończone, nawet jeśli nowe żądania mogą być przetworzone szybko. Będziemy musieli to naprawić, ale najpierw przyjrzymy się problemowi w działaniu.
Symulacja wolnego żądania
Przyjrzymy się, jak wolno przetwarzane żądanie może wpływać na inne żądania wysyłane do naszej obecnej implementacji serwera. Listing 21-10 implementuje obsługę żądania do /sleep z symulowaną wolną odpowiedzią, która spowoduje, że serwer będzie spał przez pięć sekund przed odpowiedzią.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// --snip--
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Przełączyliśmy się z if na match, ponieważ mamy teraz trzy przypadki. Musimy jawnie dopasować do wycinka request_line, aby dopasować wzorce do wartości literałów ciągów znaków; match nie wykonuje automatycznego referencjonowania i dereferencjonowania, tak jak to robi metoda równości.
Pierwsze ramię jest takie samo jak blok if z Listingu 21-9. Drugie ramię pasuje do żądania do /sleep. Po odebraniu tego żądania serwer będzie spał przez pięć sekund przed renderowaniem pomyślnej strony HTML. Trzecie ramię jest takie samo jak blok else z Listingu 21-9.
Możesz zobaczyć, jak prymitywny jest nasz serwer: prawdziwe biblioteki obsługiwałyby rozpoznawanie wielu żądań w znacznie mniej obszerny sposób!
Uruchom serwer za pomocą cargo run. Następnie otwórz dwa okna przeglądarki: jedno dla http://127.0.0.1:7878 i drugie dla http://127.0.0.1:7878/sleep. Jeśli wprowadzisz URI / kilka razy, jak poprzednio, zobaczysz, że odpowiada szybko. Ale jeśli wprowadzisz /sleep, a następnie załadujesz /, zobaczysz, że / czeka, aż sleep zakończy swój pełny pięciosekundowy czas, zanim zostanie załadowane.
Istnieje wiele technik, których moglibyśmy użyć, aby uniknąć kumulowania się żądań za wolnym żądaniem, w tym użycie async, jak zrobiliśmy to w Rozdziale 17; ta, którą zaimplementujemy, to pula wątków.
Zwiększanie przepustowości za pomocą puli wątków
Pula wątków to grupa uruchomionych wątków, które są gotowe i czekają na obsługę zadania. Kiedy program otrzymuje nowe zadanie, przypisuje jeden z wątków w puli do tego zadania, a ten wątek będzie przetwarzał zadanie. Pozostałe wątki w puli są dostępne do obsługi wszelkich innych zadań, które nadejdą, podczas gdy pierwszy wątek przetwarza. Kiedy pierwszy wątek zakończy przetwarzanie swojego zadania, zostaje on zwrócony do puli bezczynnych wątków, gotowy do obsługi nowego zadania. Pula wątków pozwala na współbieżne przetwarzanie połączeń, zwiększając przepustowość serwera.
Ograniczymy liczbę wątków w puli do niewielkiej liczby, aby chronić się przed atakami DoS; gdyby nasz program tworzył nowy wątek dla każdego żądania, gdy ono nadejdzie, ktoś, kto wykona 10 milionów żądań do naszego serwera, mógłby spowodować chaos, zużywając wszystkie zasoby naszego serwera i zatrzymując przetwarzanie żądań.
Zamiast tworzyć nieograniczoną liczbę wątków, będziemy mieć stałą liczbę wątków oczekujących w puli. Żądania, które nadejdą, są wysyłane do puli do przetworzenia. Pula będzie utrzymywać kolejkę przychodzących żądań. Każdy z wątków w puli pobierze żądanie z tej kolejki, obsłuży je, a następnie poprosi kolejkę o kolejne żądanie. Dzięki tej konstrukcji możemy przetwarzać do N żądań współbieżnie, gdzie N to liczba wątków. Jeśli każdy wątek odpowiada na długotrwałe żądanie, kolejne żądania mogą nadal gromadzić się w kolejce, ale zwiększyliśmy liczbę długotrwałych żądań, które możemy obsłużyć, zanim osiągniemy ten punkt.
Ta technika to tylko jeden z wielu sposobów na zwiększenie przepustowości serwera WWW. Inne opcje, które możesz zbadać, to model fork/join, jednowątkowy model asynchronicznego I/O oraz wielowątkowy model asynchronicznego I/O. Jeśli interesuje Cię ten temat, możesz poczytać więcej o innych rozwiązaniach i spróbować je zaimplementować; w języku niskiego poziomu, takim jak Rust, wszystkie te opcje są możliwe.
Zanim zaczniemy implementować pulę wątków, porozmawiajmy o tym, jak powinno wyglądać użycie puli. Kiedy próbujesz zaprojektować kod, najpierw napisanie interfejsu klienta może pomóc w kierowaniu twoim projektem. Napisz API kodu tak, aby było ono ustrukturyzowane w sposób, w jaki chcesz je wywołać; następnie zaimplementuj funkcjonalność w ramach tej struktury, zamiast implementować funkcjonalność, a następnie projektować publiczne API.
Podobnie jak w Rozdziale 12 stosowaliśmy rozwój sterowany testami, tutaj zastosujemy rozwój sterowany kompilatorem. Napiszemy kod, który wywołuje pożądane funkcje, a następnie będziemy analizować błędy kompilatora, aby określić, co powinniśmy zmienić, aby kod zadziałał. Zanim to jednak zrobimy, zbadamy technikę, której nie będziemy używać jako punktu wyjścia.
Struktura kodu, gdybyśmy mogli tworzyć wątek dla każdego żądania
Najpierw zbadajmy, jak nasz kod mógłby wyglądać, gdyby tworzył nowy wątek dla każdego połączenia. Jak wspomniano wcześniej, nie jest to nasz ostateczny plan ze względu na problemy z potencjalnym tworzeniem nieograniczonej liczby wątków, ale jest to punkt wyjścia do uzyskania najpierw działającego serwera wielowątkowego. Następnie dodamy pulę wątków jako ulepszenie, a kontrastowanie obu rozwiązań będzie łatwiejsze.
Listing 21-11 pokazuje zmiany, które należy wprowadzić w funkcji main, aby utworzyć nowy wątek do obsługi każdego strumienia w pętli for.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Jak nauczyłeś się w Rozdziale 16, thread::spawn utworzy nowy wątek, a następnie uruchomi kod w zamknięciu w nowym wątku. Jeśli uruchomisz ten kod i załadujesz /sleep w przeglądarce, a następnie / w dwóch kolejnych zakładkach przeglądarki, faktycznie zobaczysz, że żądania do / nie muszą czekać na zakończenie /sleep. Jednak, jak wspomnieliśmy, ostatecznie to przeciąży system, ponieważ tworzyłbyś nowe wątki bez żadnego limitu.
Możesz również pamiętać z Rozdziału 17, że to jest dokładnie ten rodzaj sytuacji, w której async i await naprawdę błyszczą! Miej to na uwadze, gdy budujemy pulę wątków i zastanawiamy się, jak wyglądałyby rzeczy inaczej lub tak samo z async.
Tworzenie skończonej liczby wątków
Chcemy, aby nasza pula wątków działała w podobny, znajomy sposób, tak aby przejście z wątków na pulę wątków nie wymagało dużych zmian w kodzie, który używa naszego API. Listing 21-12 przedstawia hipotetyczny interfejs struktury ThreadPool, której chcemy użyć zamiast thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Używamy ThreadPool::new do utworzenia nowej puli wątków z konfigurowalną liczbą wątków, w tym przypadku czterech. Następnie, w pętli for, pool.execute ma podobny interfejs do thread::spawn w tym sensie, że przyjmuje zamknięcie, które pula powinna uruchomić dla każdego strumienia. Musimy zaimplementować pool.execute tak, aby przyjmował zamknięcie i przekazywał je do wątku w puli do uruchomienia. Ten kod jeszcze się nie skompiluje, ale spróbujemy, aby kompilator mógł nas poprowadzić, jak go naprawić.
Budowanie ThreadPool za pomocą rozwoju sterowanego kompilatorem
Wprowadź zmiany z Listingu 21-12 do src/main.rs, a następnie użyjmy błędów kompilatora z cargo check, aby kierować naszym rozwojem. Oto pierwszy błąd, który otrzymujemy:
$ cargo check
Sprawdzanie hello v0.1.0 (file:///projects/hello)
error[E0433]: nie udało się rozwiązać: użycie niezadeklarowanego typu `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ użycie niezadeklarowanego typu `ThreadPool`
Więcej informacji o tym błędzie znajdziesz, używając `rustc --explain E0433`.
error: nie udało się skompilować `hello` (bin "hello") z powodu 1 poprzedniego błędu
Świetnie! Ten błąd mówi nam, że potrzebujemy typu lub modułu ThreadPool, więc teraz go zbudujemy. Nasza implementacja ThreadPool będzie niezależna od rodzaju pracy, jaką wykonuje nasz serwer WWW. Zatem, zmieńmy skrzynkę hello z skrzynki binarnej na skrzynkę biblioteki, aby przechowywać naszą implementację ThreadPool. Po zmianie na skrzynkę biblioteki, moglibyśmy również używać oddzielnej biblioteki puli wątków do dowolnej pracy, którą chcemy wykonać za pomocą puli wątków, a nie tylko do obsługi żądań WWW.
Utwórz plik src/lib.rs zawierający następującą, najprostszą definicję struktury ThreadPool, jaką możemy na razie mieć:
pub struct ThreadPool;Następnie edytuj plik main.rs, aby wprowadzić ThreadPool do zakresu z skrzynki biblioteki, dodając następujący kod na początku src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Ten kod nadal nie będzie działać, ale sprawdźmy go ponownie, aby otrzymać następny błąd, którym musimy się zająć:
$ cargo check
Sprawdzanie hello v0.1.0 (file:///projects/hello)
error[E0599]: nie znaleziono funkcji ani elementu stowarzyszonego o nazwie `new` dla struktury `ThreadPool` w bieżącym zakresie
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ nie znaleziono funkcji ani elementu stowarzyszonego w `ThreadPool`
Więcej informacji o tym błędzie znajdziesz, używając `rustc --explain E0599`.
error: nie udało się skompilować `hello` (bin "hello") z powodu 1 poprzedniego błędu
Ten błąd wskazuje, że następnym krokiem jest utworzenie stowarzyszonej funkcji o nazwie new dla ThreadPool. Wiemy również, że new musi mieć jeden parametr, który może przyjąć 4 jako argument i powinien zwracać instancję ThreadPool. Zaimplementujmy najprostszą funkcję new, która będzie miała te cechy:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}Wybraliśmy usize jako typ parametru size, ponieważ wiemy, że ujemna liczba wątków nie ma sensu. Wiemy również, że użyjemy tej 4 jako liczby elementów w kolekcji wątków, do czego służy typ usize, jak omówiono w sekcji „Typy całkowite” w Rozdziale 3.
Sprawdźmy ponownie kod:
$ cargo check
Sprawdzanie hello v0.1.0 (file:///projects/hello)
error[E0599]: nie znaleziono metody o nazwie `execute` dla struktury `ThreadPool` w bieżącym zakresie
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ nie znaleziono metody w `ThreadPool`
Więcej informacji o tym błędzie znajdziesz, używając `rustc --explain E0599`.
error: nie udało się skompilować `hello` (bin "hello") z powodu 1 poprzedniego błędu
Teraz błąd występuje, ponieważ nie mamy metody execute na ThreadPool. Przypomnij sobie z sekcji „Tworzenie skończonej liczby wątków”, że zdecydowaliśmy, iż nasza pula wątków powinna mieć interfejs podobny do thread::spawn. Ponadto, zaimplementujemy funkcję execute tak, aby pobierała przekazane jej zamknięcie i oddawała je bezczynnemu wątkowi w puli do uruchomienia.
Zdefiniujemy metodę execute na ThreadPool, aby przyjmowała zamknięcie jako parametr. Przypomnij sobie z sekcji „Przenoszenie przechwyconych wartości poza zamknięcia” w Rozdziale 13, że możemy przyjmować zamknięcia jako parametry z trzema różnymi cechami: Fn, FnMut i FnOnce. Musimy zdecydować, jaki rodzaj zamknięcia użyć tutaj. Wiemy, że skończymy robiąc coś podobnego do implementacji thread::spawn z biblioteki standardowej, więc możemy spojrzeć na ograniczenia, jakie ma sygnatura thread::spawn na swoim parametrze. Dokumentacja pokazuje nam następujące:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Parametr typu F jest tym, który nas tutaj interesuje; parametr typu T jest związany z wartością zwracaną, a tym się nie zajmujemy. Widzimy, że spawn używa FnOnce jako ograniczenia cechy dla F. To prawdopodobnie to, czego chcemy, ponieważ ostatecznie przekażemy argument, który otrzymamy w execute, do spawn. Możemy być jeszcze bardziej pewni, że FnOnce to cecha, której chcemy użyć, ponieważ wątek do uruchomienia żądania wykona zamknięcie tego żądania tylko raz, co pasuje do Once w FnOnce.
Parametr typu F ma również ograniczenie cechy Send i ograniczenie czasu życia 'static, które są przydatne w naszej sytuacji: potrzebujemy Send do przeniesienia zamknięcia z jednego wątku do drugiego oraz 'static, ponieważ nie wiemy, jak długo wątek będzie wykonywał. Stwórzmy metodę execute na ThreadPool, która będzie przyjmować parametr generyczny typu F z tymi ograniczeniami:
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Nadal używamy () po FnOnce, ponieważ to FnOnce reprezentuje zamknięcie, które nie przyjmuje żadnych parametrów i zwraca typ jednostkowy (). Podobnie jak w definicjach funkcji, typ zwracany może być pominięty z sygnatury, ale nawet jeśli nie mamy parametrów, nadal potrzebujemy nawiasów.
Powołując się na to, jest to najprostsza implementacja metody execute: nic nie robi, ale staramy się tylko, aby nasz kod się skompilował. Sprawdźmy to ponownie:
$ cargo check
Sprawdzanie hello v0.1.0 (file:///projects/hello)
Zakończono `dev` profil [nieoptymalny + debuginfo] cel(e) w 0.24s
Kompiluje się! Ale zwróć uwagę, że jeśli spróbujesz cargo run i wyślesz żądanie w przeglądarce, zobaczysz błędy w przeglądarce, które widzieliśmy na początku rozdziału. Nasza biblioteka jeszcze nie wywołuje zamknięcia przekazanego do execute!
Uwaga: Powiedzenie, które możesz usłyszeć o językach z rygorystycznymi kompilatorami, takich jak Haskell i Rust, brzmi: „Jeśli kod się kompiluje, to działa”. Ale to powiedzenie nie jest uniwersalnie prawdziwe. Nasz projekt się kompiluje, ale absolutnie nic nie robi! Gdybyśmy budowali prawdziwy, kompletny projekt, byłby to dobry moment, aby zacząć pisać testy jednostkowe, aby sprawdzić, czy kod się kompiluje i ma pożądane zachowanie.
Zastanów się: co byłoby tu inne, gdybyśmy zamiast zamknięcia wykonywali przyszłość?
Walidacja liczby wątków w new
Nic nie robimy z parametrami new i execute. Zaimplementujmy ciała tych funkcji z pożądanym zachowaniem. Na początek pomyślmy o new. Wcześniej wybraliśmy typ bez znaku dla parametru size, ponieważ pula z ujemną liczbą wątków nie ma sensu. Jednak pula z zerową liczbą wątków również nie ma sensu, a zero jest jak najbardziej prawidłowym usize. Dodamy kod, który sprawdzi, czy size jest większe od zera, zanim zwrócimy instancję ThreadPool, i spowodujemy panikę programu, jeśli otrzyma zero, używając makra assert!, jak pokazano na Listingu 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Dodaliśmy również dokumentację dla naszego ThreadPool za pomocą komentarzy doc. Zauważ, że zastosowaliśmy dobre praktyki dokumentacyjne, dodając sekcję, która wskazuje sytuacje, w których nasza funkcja może spowodować panikę, jak omówiono w Rozdziale 14. Spróbuj uruchomić cargo doc --open i kliknąć strukturę ThreadPool, aby zobaczyć, jak wyglądają wygenerowane dokumenty dla new!
Zamiast dodawać makro assert!, jak to zrobiliśmy tutaj, moglibyśmy zmienić new na build i zwrócić Result, tak jak zrobiliśmy to z Config::build w projekcie I/O w Listingu 12-9. Ale w tym przypadku zdecydowaliśmy, że próba utworzenia puli wątków bez żadnych wątków powinna być nieodwracalnym błędem. Jeśli czujesz się ambitny, spróbuj napisać funkcję o nazwie build z następującą sygnaturą, aby porównać ją z funkcją new:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Tworzenie miejsca na przechowywanie wątków
Teraz, gdy wiemy, że mamy prawidłową liczbę wątków do przechowywania w puli, możemy utworzyć te wątki i przechowywać je w strukturze ThreadPool przed zwróceniem tej struktury. Ale jak „przechowujemy” wątek? Spójrzmy jeszcze raz na sygnaturę thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Funkcja spawn zwraca JoinHandle<T>, gdzie T to typ, który zwraca zamknięcie. Spróbujmy użyć JoinHandle i zobaczmy, co się stanie. W naszym przypadku zamknięcia, które przekazujemy do puli wątków, będą obsługiwać połączenie i nic nie zwracać, więc T będzie typem jednostkowym ().
Kod z Listingu 21-14 skompiluje się, ale jeszcze nie tworzy żadnych wątków. Zmieniliśmy definicję ThreadPool, aby przechowywała wektor instancji thread::JoinHandle<()>, zainicjalizowaliśmy wektor o pojemności size, skonfigurowaliśmy pętlę for, która uruchomi kod do tworzenia wątków, i zwróciła instancję ThreadPool zawierającą je.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// utwórz kilka wątków i zapisz je w wektorze
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Wprowadziliśmy std::thread do zakresu w skrzynce biblioteki, ponieważ używamy thread::JoinHandle jako typu elementów w wektorze w ThreadPool.
Po otrzymaniu prawidłowego rozmiaru, nasz ThreadPool tworzy nowy wektor, który może przechowywać size elementów. Funkcja with_capacity wykonuje to samo zadanie co Vec::new, ale z ważną różnicą: wstępnie alokuje miejsce w wektorze. Ponieważ wiemy, że musimy przechowywać size elementów w wektorze, wykonanie tej alokacji z góry jest nieco bardziej wydajne niż użycie Vec::new, który zmienia rozmiar w miarę wstawiania elementów.
Po ponownym uruchomieniu cargo check powinno się udać.
Wysyłanie kodu z ThreadPool do wątku
Zostawiliśmy komentarz w pętli for w Listingu 21-14 dotyczący tworzenia wątków. Tutaj przyjrzymy się, jak faktycznie tworzymy wątki. Biblioteka standardowa zapewnia thread::spawn jako sposób tworzenia wątków, a thread::spawn oczekuje kodu, który wątek powinien uruchomić natychmiast po utworzeniu wątku. Jednak w naszym przypadku chcemy utworzyć wątki i sprawić, by czekały na kod, który wyślemy później. Implementacja wątków w bibliotece standardowej nie zawiera sposobu, aby to zrobić; musimy to zaimplementować ręcznie.
Zaimplementujemy to zachowanie, wprowadzając nową strukturę danych między ThreadPool a wątkami, która będzie zarządzać tym nowym zachowaniem. Nazwiemy tę strukturę danych Worker, co jest powszechnym terminem w implementacjach puli. Worker pobiera kod, który musi zostać uruchomiony, i uruchamia go w swoim wątku.
Pomyśl o ludziach pracujących w kuchni w restauracji: pracownicy czekają, aż przyjdą zamówienia od klientów, a następnie są odpowiedzialni za przyjęcie tych zamówień i ich zrealizowanie.
Zamiast przechowywać wektor instancji JoinHandle<()> w puli wątków, będziemy przechowywać instancje struktury Worker. Każdy Worker będzie przechowywał pojedynczą instancję JoinHandle<()>. Następnie zaimplementujemy metodę w Worker, która przyjmie zamknięcie kodu do uruchomienia i wyśle je do już działającego wątku do wykonania. Każdemu Workerowi nadamy również id, abyśmy mogli odróżnić różne instancje Worker w puli podczas logowania lub debugowania.
Oto nowy proces, który nastąpi po utworzeniu ThreadPool. Kod, który wysyła zamknięcie do wątku, zaimplementujemy po skonfigurowaniu Worker w ten sposób:
- Zdefiniuj strukturę
Worker, która zawieraidiJoinHandle<()>. - Zmień
ThreadPool, aby zawierał wektor instancjiWorker. - Zdefiniuj funkcję
Worker::new, która przyjmuje numeridi zwraca instancjęWorkerzawierającąidi wątek uruchomiony z pustym zamknięciem. - W
ThreadPool::newużyj licznika pętlifordo wygenerowaniaid, utwórz nowegoWorkerz tymidi przechowujWorkerw wektorze.
Jeśli jesteś gotowy na wyzwanie, spróbuj samodzielnie zaimplementować te zmiany, zanim spojrzysz na kod w Listingu 21-15.
Gotowy? Oto Listing 21-15 z jednym ze sposobów wprowadzenia powyższych modyfikacji.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Zmieniliśmy nazwę pola w ThreadPool z threads na workers, ponieważ teraz przechowuje ono instancje Worker zamiast instancji JoinHandle<()>. Używamy licznika w pętli for jako argumentu do Worker::new i przechowujemy każdego nowego Worker w wektorze o nazwie workers.
Zewnętrzny kod (taki jak nasz serwer w src/main.rs) nie musi znać szczegółów implementacji dotyczących używania struktury Worker w ThreadPool, dlatego sprawiamy, że struktura Worker i jej funkcja new są prywatne. Funkcja Worker::new używa podanego przez nas id i przechowuje instancję JoinHandle<()>, która jest tworzona poprzez uruchomienie nowego wątku za pomocą pustego zamknięcia.
Uwaga: Jeśli system operacyjny nie może utworzyć wątku z powodu niewystarczających zasobów systemowych,
thread::spawnspowoduje panikę. To spowoduje panikę całego naszego serwera, nawet jeśli utworzenie niektórych wątków może się powieść. Dla uproszczenia, takie zachowanie jest w porządku, ale w produkcyjnej implementacji puli wątków prawdopodobnie chciałbyś użyćstd::thread::Builderi jego metodyspawn, która zamiast tego zwracaResult.
Ten kod skompiluje się i przechowuje liczbę instancji Worker, którą określiliśmy jako argument do ThreadPool::new. Ale nadal nie przetwarzamy zamknięcia, które otrzymujemy w execute. Przyjrzyjmy się, jak to zrobić w następnej kolejności.
Wysyłanie żądań do wątków za pośrednictwem kanałów
Następny problem, którym się zajmiemy, to fakt, że zamknięcia przekazane do thread::spawn absolutnie nic nie robią. Obecnie zamknięcie, które chcemy wykonać, otrzymujemy w metodzie execute. Ale musimy przekazać thread::spawn zamknięcie do uruchomienia, gdy tworzymy każdego Worker podczas tworzenia ThreadPool.
Chcemy, aby struktury Worker, które właśnie utworzyliśmy, pobierały kod do uruchomienia z kolejki przechowywanej w ThreadPool i wysyłały ten kod do swojego wątku do wykonania.
Kanały, o których dowiedzieliśmy się w Rozdziale 16 – prosty sposób komunikacji między dwoma wątkami – byłyby idealne do tego zastosowania. Użyjemy kanału do pełnienia funkcji kolejki zadań, a execute wyśle zadanie z ThreadPool do instancji Worker, które wyślą zadanie do swojego wątku. Oto plan:
ThreadPoolutworzy kanał i będzie trzymać się nadawcy.- Każdy
Workerbędzie trzymać się odbiorcy. - Utworzymy nową strukturę
Job, która będzie przechowywać zamknięcia, które chcemy wysłać kanałem. - Metoda
executewyśle zadanie, które chce wykonać, za pośrednictwem nadawcy. - W swoim wątku,
Workerbędzie iterował po swoim odbiorniku i wykonywał zamknięcia wszystkich otrzymanych zadań.
Zacznijmy od utworzenia kanału w ThreadPool::new i przechowywania nadawcy w instancji ThreadPool, jak pokazano na Listingu 21-16. Struktura Job na razie nic nie przechowuje, ale będzie typem elementu, który wysyłamy kanałem.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}W ThreadPool::new tworzymy nasz nowy kanał i sprawiamy, że pula przechowuje nadawcę. To się pomyślnie skompiluje.
Spróbujmy przekazać odbiornik kanału do każdego Worker’a, gdy pula wątków tworzy kanał. Wiemy, że chcemy użyć odbiornika w wątku, który uruchamiają instancje Worker, więc odwołamy się do parametru receiver w zamknięciu. Kod z Listingu 21-17 jeszcze się nie skompiluje.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Wprowadziliśmy kilka małych i prostych zmian: przekazujemy odbiornik do Worker::new, a następnie używamy go wewnątrz zamknięcia.
Kiedy próbujemy sprawdzić ten kod, otrzymujemy następujący błąd:
$ cargo check
Sprawdzanie hello v0.1.0 (file:///projects/hello)
error[E0382]: użycie przeniesionej wartości: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- następuje przeniesienie, ponieważ `receiver` ma typ `std::sync::mpsc::Receiver<Job>`, który nie implementuje cechy `Copy`
...
25 | for id in 0..size {
| ----------------- wewnątrz tej pętli
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ wartość przeniesiona tutaj, w poprzedniej iteracji pętli
|
note: rozważ zmianę typu tego parametru w metodzie `new` na pożyczanie, jeśli posiadanie wartości nie jest konieczne
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- w tej metodzie ^^^^^^^^^^^^^^^^^^^ ten parametr przejmuje własność wartości
help: rozważ przeniesienie wyrażenia poza pętlę, aby było przeniesione tylko raz
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
Więcej informacji o tym błędzie znajdziesz, używając `rustc --explain E0382`.
error: nie udało się skompilować `hello` (lib) z powodu 1 poprzedniego błędu
Kod próbuje przekazać receiver do wielu instancji Worker. To nie zadziała, jak pamiętacie z Rozdziału 16: implementacja kanału dostarczana przez Rusta to kanał wielu producentów, jednego konsumenta. Oznacza to, że nie możemy po prostu sklonować końca konsumującego kanału, aby naprawić ten kod. Nie chcemy również wysyłać wiadomości wielokrotnie do wielu konsumentów; chcemy jednej listy wiadomości z wieloma instancjami Worker, tak aby każda wiadomość była przetwarzana raz.
Dodatkowo, pobieranie zadania z kolejki kanału wiąże się z mutacją receiver, więc wątki potrzebują bezpiecznego sposobu na współdzielenie i modyfikowanie receiver; w przeciwnym razie mogą wystąpić warunki wyścigu (omówione w Rozdziale 16).
Przypomnij sobie inteligentne wskaźniki bezpieczne dla wątków omówione w Rozdziale 16: Aby współdzielić własność między wieloma wątkami i umożliwić wątkom mutację wartości, musimy użyć Arc<Mutex<T>>. Typ Arc pozwoli wielu instancjom Worker posiadać odbiornik, a Mutex zapewni, że tylko jeden Worker pobierze zadanie z odbiornika na raz. Listing 21-18 pokazuje zmiany, które musimy wprowadzić.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}W ThreadPool::new umieszczamy odbiornik w Arc i Mutex. Dla każdego nowego Worker, klonujemy Arc, aby zwiększyć licznik referencji, tak aby instancje Worker mogły współdzielić własność odbiornika.
Dzięki tym zmianom kod się kompiluje! Coraz bliżej!
Implementacja metody execute
Zaimplementujmy w końcu metodę execute na ThreadPool. Zmienimy również Job ze struktury na alias typu dla obiektu cechy, który przechowuje typ zamknięcia, który otrzymuje execute. Jak omówiono w sekcji „Synonimy typów i aliasy typów” w Rozdziale 20, aliasy typów pozwalają nam skracać długie typy dla ułatwienia użytkowania. Spójrz na Listing 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Po utworzeniu nowej instancji Job za pomocą zamknięcia, które otrzymujemy w execute, wysyłamy to zadanie przez koniec wysyłający kanału. Wywołujemy unwrap na send w przypadku, gdy wysyłanie się nie powiedzie. Może się to zdarzyć, jeśli na przykład zatrzymamy wszystkie nasze wątki od wykonywania, co oznacza, że koniec odbierający przestał odbierać nowe wiadomości. W tej chwili nie możemy zatrzymać naszych wątków od wykonywania: nasze wątki kontynuują wykonywanie tak długo, jak długo istnieje pula. Powodem, dla którego używamy unwrap, jest to, że wiemy, że przypadek błędu się nie zdarzy, ale kompilator tego nie wie.
Ale jeszcze nie skończyliśmy! W Worker, nasze zamknięcie przekazywane do thread::spawn nadal tylko referuje koniec odbiorczy kanału. Zamiast tego, potrzebujemy, aby zamknięcie zapętlało się w nieskończoność, prosząc koniec odbiorczy kanału o zadanie i uruchamiając zadanie, gdy je otrzyma. Wprowadźmy zmianę pokazaną na Listingu 21-20 w Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
});
Worker { id, thread }
}
}Tutaj najpierw wywołujemy lock na receiver, aby uzyskać muteks, a następnie wywołujemy unwrap, aby spowodować panikę w przypadku błędów. Uzyskanie blokady może zakończyć się niepowodzeniem, jeśli muteks jest w stanie zatrucia, co może się zdarzyć, jeśli jakiś inny wątek panikował, trzymając blokadę, zamiast ją zwolnić. W tej sytuacji wywołanie unwrap w celu spowodowania paniki tego wątku jest prawidłowym działaniem. Możesz zmienić to unwrap na expect z komunikatem o błędzie, który jest dla ciebie sensowny.
Jeśli uzyskamy blokadę na muteksie, wywołujemy recv, aby otrzymać Job z kanału. Ostateczny unwrap również tutaj pomija wszelkie błędy, które mogą wystąpić, jeśli wątek posiadający nadawcę został zamknięty, podobnie jak metoda send zwraca Err, jeśli odbiornik zostanie zamknięty.
Wywołanie recv blokuje, więc jeśli nie ma jeszcze zadania, bieżący wątek będzie czekał, aż zadanie stanie się dostępne. Mutex<T> zapewnia, że tylko jeden wątek Worker w danym momencie próbuje zażądać zadania.
Nasza pula wątków jest teraz w stanie działającym! Uruchom ją za pomocą cargo run i wyślij kilka żądań:
$ cargo run
Kompilowanie hello v0.1.0 (file:///projects/hello)
warning: pole `workers` nigdy nie jest odczytywane
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- pole w tej strukturze
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` domyślnie włączone
warning: pola `id` i `thread` nigdy nie są odczytywane
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ pola w tej strukturze
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) wygenerowało 2 ostrzeżenia
Zakończono `dev` profil [nieoptymalny + debuginfo] cel(e) w 4.91s
Uruchamianie `target/debug/hello`
Worker 0 otrzymał zadanie; wykonuję.
Worker 2 otrzymał zadanie; wykonuję.
Worker 1 otrzymał zadanie; wykonuję.
Worker 3 otrzymał zadanie; wykonuję.
Worker 0 otrzymał zadanie; wykonuję.
Worker 2 otrzymał zadanie; wykonuję.
Worker 1 otrzymał zadanie; wykonuję.
Worker 3 otrzymał zadanie; wykonuję.
Worker 0 otrzymał zadanie; wykonuję.
Worker 2 otrzymał zadanie; wykonuję.
Sukces! Mamy teraz pulę wątków, która wykonuje połączenia asynchronicznie. Nigdy nie jest tworzonych więcej niż cztery wątki, więc nasz system nie zostanie przeciążony, jeśli serwer otrzyma wiele żądań. Jeśli wyślemy żądanie do /sleep, serwer będzie mógł obsłużyć inne żądania, zlecając je innym wątkom.
Uwaga: Jeśli otworzysz /sleep w wielu oknach przeglądarki jednocześnie, mogą się ładować po kolei w pięciosekundowych odstępach. Niektóre przeglądarki internetowe wykonują wiele instancji tego samego żądania sekwencyjnie z powodów buforowania. To ograniczenie nie jest spowodowane przez nasz serwer WWW.
To dobry moment, aby zatrzymać się i zastanowić, jak kod z Listingów 21-18, 21-19 i 21-20 różniłby się, gdybyśmy używali przyszłości zamiast zamknięcia dla wykonywanej pracy. Jakie typy uległyby zmianie? Jak różniłyby się sygnatury metod, jeśli w ogóle? Jakie części kodu pozostałyby takie same?
Po zapoznaniu się z pętlą while let w Rozdziale 17 i Rozdziale 19, możesz się zastanawiać, dlaczego nie napisaliśmy kodu wątku Worker, jak pokazano na Listingu 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
});
Worker { id, thread }
}
}Ten kod kompiluje się i działa, ale nie prowadzi do pożądanego zachowania wątkowości: wolne żądanie nadal będzie powodować, że inne żądania będą czekać na przetworzenie. Powód jest nieco subtelny: struktura Mutex nie ma publicznej metody unlock, ponieważ własność blokady opiera się na czasie życia MutexGuard<T> wewnątrz LockResult<MutexGuard<T>>, które zwraca metoda lock. W czasie kompilacji, checker pożyczeń może wymusić zasadę, że zasób chroniony przez Mutex nie może być dostępny, chyba że posiadamy blokadę. Jednak ta implementacja może również spowodować, że blokada będzie utrzymywana dłużej niż zamierzono, jeśli nie będziemy pamiętać o czasie życia MutexGuard<T>.
Kod z Listingu 21-20, który używa let job = receiver.lock().unwrap().recv().unwrap(); działa, ponieważ w przypadku let, wszelkie tymczasowe wartości użyte w wyrażeniu po prawej stronie znaku równości są natychmiast usuwane, gdy kończy się instrukcja let. Jednak while let (oraz if let i match) nie usuwa tymczasowych wartości aż do końca powiązanego bloku. W Listingu 21-21 blokada pozostaje w posiadaniu przez cały czas trwania wywołania job(), co oznacza, że inne instancje Worker nie mogą odbierać zadań.
Delikatne zamykanie i sprzątanie
Delikatne zamykanie i sprzątanie
Kod z Listingu 21-20 odpowiada na żądania asynchronicznie, używając puli wątków, tak jak zamierzaliśmy. Otrzymujemy kilka ostrzeżeń o polach workers, id i thread, których nie używamy w bezpośredni sposób, co przypomina nam, że nic nie sprzątamy. Gdy użyjemy mniej eleganckiej metody ctrl-C do zatrzymania głównego wątku, wszystkie inne wątki są natychmiast zatrzymywane, nawet jeśli są w trakcie obsługi żądania.
Następnie zaimplementujemy cechę Drop, aby wywołać join dla każdego z wątków w puli, aby mogły zakończyć pracę nad żądaniami, zanim się zamkną. Następnie zaimplementujemy sposób, aby poinformować wątki, że powinny przestać akceptować nowe żądania i zamknąć się. Aby zobaczyć ten kod w akcji, zmodyfikujemy nasz serwer, aby akceptował tylko dwa żądania przed delikatnym zamknięciem puli wątków.
Jedna rzecz do zauważenia, gdy będziemy postępować: nic z tego nie wpływa na części kodu, które obsługują wykonywanie zamknięć, więc wszystko tutaj byłoby takie samo, gdybyśmy używali puli wątków do asynchronicznego środowiska uruchomieniowego.
Implementacja cechy Drop dla ThreadPool
Zacznijmy od zaimplementowania Drop dla naszej puli wątków. Kiedy pula zostanie zrzucona, wszystkie nasze wątki powinny się połączyć, aby upewnić się, że zakończyły swoją pracę. Listing 21-22 pokazuje pierwszą próbę implementacji Drop; ten kod jeszcze nie będzie działał poprawnie.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Zamykanie wątku roboczego {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
});
Worker { id, thread }
}
}Najpierw przechodzimy przez każdego z workerów puli wątków. Używamy &mut do tego, ponieważ self jest mutowalną referencją, a my musimy również być w stanie mutować worker. Dla każdego workera, drukujemy komunikat informujący, że ta konkretna instancja Worker jest zamykana, a następnie wywołujemy join na wątku tej instancji Worker. Jeśli wywołanie join zakończy się niepowodzeniem, używamy unwrap, aby Rust panikował i przeszedł w stan niełaskawego zamknięcia.
Oto błąd, który otrzymujemy podczas kompilacji tego kodu:
$ cargo check
Sprawdzanie hello v0.1.0 (file:///projects/hello)
error[E0507]: nie można przenieść z `worker.thread`, który znajduje się za mutowalną referencją
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` przeniesiony z powodu wywołania tej metody
| |
| przeniesienie następuje, ponieważ `worker.thread` ma typ `JoinHandle<()>`, który nie implementuje cechy `Copy`
|
note: `JoinHandle::<T>::join` przejmuje własność odbiornika `self`, co przenosi `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
Więcej informacji o tym błędzie znajdziesz, używając `rustc --explain E0507`.
error: nie udało się skompilować `hello` (lib) z powodu 1 poprzedniego błędu
Błąd mówi nam, że nie możemy wywołać join, ponieważ mamy tylko mutowalne pożyczenie każdego workera, a join przejmuje własność swojego argumentu. Aby rozwiązać ten problem, musimy przenieść wątek z instancji Worker, która jest właścicielem thread, tak aby join mogło zużyć wątek. Jednym ze sposobów jest zastosowanie tego samego podejścia, które przyjęliśmy w Listingu 18-15. Gdyby Worker zawierał Option<thread::JoinHandle<()>>, moglibyśmy wywołać metodę take na Option, aby przenieść wartość z wariantu Some i pozostawić wariant None na jego miejscu. Innymi słowy, działający Worker miałby wariant Some w thread, a gdybyśmy chcieli posprzątać Workera, zastąpilibyśmy Some przez None, aby Worker nie miał wątku do uruchomienia.
Jednakże, jedynym momentem, kiedy to by się pojawiło, byłoby zrzucanie Workera. W zamian, musielibyśmy radzić sobie z Option<thread::JoinHandle<()>> wszędzie, gdzie uzyskiwaliśmy dostęp do worker.thread. Idiomatyczny Rust często używa Option, ale gdy zauważysz, że opakowujesz coś, co wiesz, że zawsze będzie obecne, w Option jako obejście, to dobrym pomysłem jest poszukanie alternatywnych podejść, aby uczynić kod czystszym i mniej podatnym na błędy.
W tym przypadku istnieje lepsza alternatywa: metoda Vec::drain. Akceptuje parametr zakresu, aby określić, które elementy usunąć z wektora i zwraca iterator tych elementów. Przekazanie składni zakresu .. usunie wszystkie wartości z wektora.
Zatem musimy zaktualizować implementację drop w ThreadPool w następujący sposób:
#![allow(unused)]
fn main() {
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("Zamykanie wątku roboczego {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
});
Worker { id, thread }
}
}
}To rozwiązuje błąd kompilatora i nie wymaga żadnych innych zmian w naszym kodzie. Zauważ, że ponieważ drop może być wywołany podczas paniki, unwrap również może spowodować panikę i doprowadzić do podwójnej paniki, co natychmiastowo crashuje program i kończy wszelkie trwające sprzątanie. Jest to w porządku dla przykładowego programu, ale nie jest zalecane dla kodu produkcyjnego.
Sygnalizowanie wątkom, aby przestały nasłuchiwać zadań
Dzięki wszystkim zmianom, które wprowadziliśmy, nasz kod kompiluje się bez żadnych ostrzeżeń. Niestety, ten kod nie działa tak, jak byśmy chcieli. Klucz leży w logice zamknięć uruchamianych przez wątki instancji Worker: obecnie wywołujemy join, ale to nie spowoduje zamknięcia wątków, ponieważ one loop w nieskończoność, szukając zadań. Jeśli spróbujemy zrzucić nasz ThreadPool z naszą obecną implementacją drop, główny wątek będzie blokował się w nieskończoność, czekając na zakończenie pierwszego wątku.
Aby rozwiązać ten problem, będziemy potrzebować zmiany w implementacji drop dla ThreadPool, a następnie zmiany w pętli Worker.
Najpierw zmienimy implementację drop w ThreadPool tak, aby jawnie zrzucić sender przed oczekiwaniem na zakończenie wątków. Listing 21-23 pokazuje zmiany w ThreadPool w celu jawnego zrzucenia sender. W przeciwieństwie do wątku, tutaj musimy użyć Option, aby móc przenieść sender z ThreadPool za pomocą Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Zamykanie wątku roboczego {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
});
Worker { id, thread }
}
}Zrzucenie sender zamyka kanał, co oznacza, że więcej wiadomości nie zostanie wysłanych. Kiedy to nastąpi, wszystkie wywołania recv, które instancje Worker wykonują w nieskończonej pętli, zwrócą błąd. W Listingu 21-24 zmieniamy pętlę Worker tak, aby w tym przypadku elegancko wychodziła z pętli, co oznacza, że wątki zakończą działanie, gdy implementacja drop w ThreadPool wywoła na nich join.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Zamykanie wątku roboczego {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
Err(_) => {
println!("Worker {id} rozłączył się; zamykam.");
break;
}
}
}
});
Worker { id, thread }
}
}Aby zobaczyć ten kod w akcji, zmodyfikujmy main, aby akceptował tylko dwa żądania przed delikatnym zamknięciem serwera, jak pokazano na Listingu 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Zamykam.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Nie chciałbyś, aby prawdziwy serwer WWW zamykał się po obsłużeniu zaledwie dwóch żądań. Ten kod jedynie demonstruje, że delikatne zamykanie i sprzątanie działa poprawnie.
Metoda take jest zdefiniowana w ceche Iterator i ogranicza iterację do maksymalnie dwóch pierwszych elementów. ThreadPool wyjdzie poza zakres na końcu main, a implementacja drop zostanie uruchomiona.
Uruchom serwer za pomocą cargo run i wyślij trzy żądania. Trzecie żądanie powinno zakończyć się błędem, a w terminalu powinieneś zobaczyć wynik podobny do tego:
$ cargo run
Kompilowanie hello v0.1.0 (file:///projects/hello)
Zakończono `dev` profil [nieoptymalny + debuginfo] cel(e) w 0.41s
Uruchamianie `target/debug/hello`
Worker 0 otrzymał zadanie; wykonuję.
Zamykam.
Zamykanie wątku roboczego 0
Worker 3 otrzymał zadanie; wykonuję.
Worker 1 rozłączył się; zamykam.
Worker 2 rozłączył się; zamykam.
Worker 3 rozłączył się; zamykam.
Worker 0 rozłączył się; zamykam.
Zamykanie wątku roboczego 1
Zamykanie wątku roboczego 2
Zamykanie wątku roboczego 3
Możesz zobaczyć inną kolejność identyfikatorów Worker i wydrukowanych komunikatów. Z komunikatów widzimy, jak działa ten kod: instancje Worker 0 i 3 otrzymały pierwsze dwa żądania. Serwer przestał akceptować połączenia po drugim połączeniu, a implementacja Drop w ThreadPool zaczyna się wykonywać, zanim Worker 3 nawet rozpocznie swoje zadanie. Zrzucone sender odłącza wszystkie instancje Worker i informuje je o zamknięciu. Instancje Worker drukują komunikat, gdy się odłączają, a następnie pula wątków wywołuje join, aby poczekać, aż każdy wątek Worker zakończy działanie.
Zauważ jeden ciekawy aspekt tego konkretnego wykonania: ThreadPool zrzucił sender, a zanim którykolwiek Worker otrzymał błąd, próbowaliśmy dołączyć Worker 0. Worker 0 nie otrzymał jeszcze błędu z recv, więc główny wątek zablokował się, czekając na zakończenie Worker 0. W międzyczasie Worker 3 otrzymał zadanie, a następnie wszystkie wątki otrzymały błąd. Gdy Worker 0 zakończył działanie, główny wątek czekał na zakończenie pozostałych instancji Worker. W tym momencie wszystkie one wyszły ze swoich pętli i zatrzymały się.
Gratulacje! Właśnie zakończyliśmy nasz projekt; mamy podstawowy serwer WWW, który używa puli wątków do asynchronicznej odpowiedzi. Jesteśmy w stanie wykonać delikatne zamknięcie serwera, które czyści wszystkie wątki w puli.
Poniżej znajduje się cały kod dla odniesienia:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Zamykam.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Tworzy nową pulę wątków.
///
/// `size` to liczba wątków w puli.
///
/// # Panics
///
/// Funkcja `new` spowoduje panikę, jeśli `size` wynosi zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Zamykanie wątku roboczego {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} otrzymał zadanie; wykonuję.");
job();
}
Err(_) => {
println!("Worker {id} rozłączył się; zamykam.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Można by tu zrobić więcej! Jeśli chcesz kontynuować ulepszanie tego projektu, oto kilka pomysłów:
- Dodaj więcej dokumentacji do
ThreadPooli jego publicznych metod. - Dodaj testy funkcjonalności biblioteki.
- Zmień wywołania
unwrapna bardziej solidną obsługę błędów. - Użyj
ThreadPooldo wykonania innego zadania niż obsługa żądań WWW. - Znajdź skrzynkę puli wątków na crates.io i zaimplementuj podobny serwer WWW, używając zamiast tego tej skrzynki. Następnie porównaj jej API i solidność z zaimplementowaną przez nas pulą wątków.
Podsumowanie
Świetnie! Dotarłeś do końca książki! Chcemy podziękować za dołączenie do nas w tej podróży po Rust. Jesteś teraz gotowy, aby zaimplementować własne projekty Rust i pomagać w projektach innych ludzi. Pamiętaj, że istnieje gościnna społeczność innych Rustaceans, którzy z przyjemnością pomogą ci w wszelkich wyzwaniach, które napotkasz w swojej podróży z Rustem.
Dodatek
Poniższe sekcje zawierają materiały referencyjne, które mogą okazać się przydatne w Twojej podróży z Rustem.
A - Słowa kluczowe
Dodatek A: Słowa kluczowe
Poniższe listy zawierają słowa kluczowe, które są zarezerwowane do obecnego lub przyszłego użytku przez język Rust. W związku z tym nie mogą być używane jako identyfikatory (z wyjątkiem surowych identyfikatorów, jak omawiamy w sekcji „Surowe identyfikatory”). Identyfikatory to nazwy funkcji, zmiennych, parametrów, pól struktur, modułów, skrzynek, stałych, makr, wartości statycznych, atrybutów, typów, cech lub czasów życia.
Słowa kluczowe obecnie w użyciu
Poniżej znajduje się lista słów kluczowych obecnie używanych, z opisem ich funkcjonalności.
as: Wykonuje prymitywną konwersję typów, rozróżnia konkretną cechę zawierającą element lub zmienia nazwy elementów w instrukcjachuse.async: ZwracaFuturezamiast blokowania bieżącego wątku.await: Zawiesza wykonywanie, dopóki wynikFuturenie będzie gotowy.break: Natychmiast wychodzi z pętli.const: Definiuje stałe elementy lub stałe surowe wskaźniki.continue: Przechodzi do następnej iteracji pętli.crate: W ścieżce modułu odnosi się do katalogu głównego skrzynki (crate).dyn: Dynamiczne wysyłanie do obiektu cechy.else: Alternatywa dla konstrukcji sterującychifiif let.enum: Definiuje wyliczenie.extern: Łączy funkcję lub zmienną zewnętrzną.false: Literał boolowski fałsz.fn: Definiuje funkcję lub typ wskaźnika na funkcję.for: Iteruje po elementach z iteratora, implementuje cechę lub określa czas życia wyższego rzędu.if: Rozgałęzia kod na podstawie wyniku wyrażenia warunkowego.impl: Implementuje wbudowaną lub cechową funkcjonalność.in: Część składni pętlifor.let: Wiąże zmienną.loop: Pętla bezwarunkowa.match: Dopasowuje wartość do wzorców.mod: Definiuje moduł.move: Sprawia, że zamknięcie przejmuje własność wszystkich swoich przechwyconych wartości.mut: Oznacza zmienność w referencjach, surowych wskaźnikach lub wiązaniach wzorcowych.pub: Oznacza publiczną widoczność w polach struktur, blokachimpllub modułach.ref: Wiąże przez referencję.return: Zwraca z funkcji.Self: Alias typu dla definiowanego lub implementowanego typu.self: Podmiot metody lub bieżący moduł.static: Zmienna globalna lub czas życia trwający przez całe wykonanie programu.struct: Definiuje strukturę.super: Moduł nadrzędny bieżącego modułu.trait: Definiuje cechę.true: Literał boolowski prawda.type: Definiuje alias typu lub stowarzyszony typ.union: Definiuje unię; jest słowem kluczowym tylko wtedy, gdy używane w deklaracji unii.unsafe: Oznacza niebezpieczny kod, funkcje, cechy lub implementacje.use: Wprowadza symbole do zakresu.where: Oznacza klauzule, które ograniczają typ.while: Pętla warunkowa na podstawie wyniku wyrażenia.
Słowa kluczowe zarezerwowane do przyszłego użytku
Poniższe słowa kluczowe nie mają jeszcze żadnej funkcjonalności, ale są zarezerwowane przez Rust do potencjalnego przyszłego użytku:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Surowe identyfikatory
Surowe identyfikatory to składnia, która pozwala używać słów kluczowych tam, gdzie normalnie nie byłoby to dozwolone. Surowy identyfikator używasz, poprzedzając słowo kluczowe r#.
Na przykład, match jest słowem kluczowym. Jeśli spróbujesz skompilować następującą funkcję, która używa match jako swojej nazwy:
Nazwa pliku: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}otrzymasz następujący błąd:
błąd: oczekiwano identyfikatora, znaleziono słowo kluczowe `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ oczekiwano identyfikatora, znaleziono słowo kluczowe
Błąd pokazuje, że nie możesz użyć słowa kluczowego match jako identyfikatora funkcji. Aby użyć match jako nazwy funkcji, musisz użyć składni surowego identyfikatora, tak jak tutaj:
Nazwa pliku: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}Ten kod skompiluje się bez żadnych błędów. Zwróć uwagę na prefiks r# w nazwie funkcji w jej definicji, a także tam, gdzie funkcja jest wywoływana w main.
Surowe identyfikatory pozwalają używać dowolnego słowa jako identyfikatora, nawet jeśli to słowo jest zarezerwowanym słowem kluczowym. Daje to nam większą swobodę w wyborze nazw identyfikatorów, a także umożliwia integrację z programami napisanymi w języku, w którym te słowa nie są słowami kluczowymi. Ponadto, surowe identyfikatory pozwalają używać bibliotek napisanych w innej edycji Rust niż ta, której używa twoja skrzynka. Na przykład, try nie jest słowem kluczowym w edycji 2015, ale jest w edycjach 2018, 2021 i 2024. Jeśli zależy Ci na bibliotece napisanej w edycji 2015 i ma ona funkcję try, będziesz musiał użyć składni surowego identyfikatora, w tym przypadku r#try, aby wywołać tę funkcję z kodu w późniejszych edycjach. Więcej informacji na temat edycji znajdziesz w Dodatku E.
B - Operatory i symbole
Dodatek B: Operatory i symbole
Ten dodatek zawiera słownik składni Rust, w tym operatory i inne symbole, które pojawiają się samodzielnie lub w kontekście ścieżek, typów generycznych, ograniczeń cech, makr, atrybutów, komentarzy, krotek i nawiasów.
Operatory
Tabela B-1 zawiera operatory w Rust, przykład, jak operator pojawiłby się w kontekście, krótkie wyjaśnienie i informację, czy operator jest przeciążalny. Jeśli operator jest przeciążalny, wymieniona jest odpowiednia cecha do użycia w celu przeciążenia tego operatora.
Tabela B-1: Operatory
| Operator | Przykład | Wyjaśnienie | Przeciążalny? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Rozwinięcie makra | |
! | !expr | Bitowa lub logiczna negacja | Not |
!= | expr != expr | Porównanie nierówności | PartialEq |
% | expr % expr | Reszta z dzielenia arytmetycznego | Rem |
%= | var %= expr | Reszta z dzielenia arytmetycznego i przypisanie | RemAssign |
& | &expr, &mut expr | Pożyczenie | |
& | &type, &mut type, &'a type, &'a mut type | Typ wskaźnika pożyczonego | |
& | expr & expr | Bitowe AND | BitAnd |
&= | var &= expr | Bitowe AND i przypisanie | BitAndAssign |
&& | expr && expr | Krótkookresowe logiczne AND | |
* | expr * expr | Mnożenie arytmetyczne | Mul |
*= | var *= expr | Mnożenie arytmetyczne i przypisanie | MulAssign |
* | *expr | Dereferencja | Deref |
* | *const type, *mut type | Surowy wskaźnik | |
+ | trait + trait, 'a + trait | Ograniczenie typu złożonego | |
+ | expr + expr | Dodawanie arytmetyczne | Add |
+= | var += expr | Dodawanie arytmetyczne i przypisanie | AddAssign |
, | expr, expr | Separator argumentów i elementów | |
- | - expr | Negacja arytmetyczna | Neg |
- | expr - expr | Odejmowanie arytmetyczne | Sub |
-= | var -= expr | Odejmowanie arytmetyczne i przypisanie | SubAssign |
-> | fn(...) -> type, |…| -> type | Typ zwracany funkcji i zamknięcia | |
. | expr.ident | Dostęp do pola | |
. | expr.ident(expr, ...) | Wywołanie metody | |
. | expr.0, expr.1, i tak dalej | Indeksowanie krotek | |
.. | .., expr.., ..expr, expr..expr | Literał zakresu wyłączającego prawą stronę | PartialOrd |
..= | ..=expr, expr..=expr | Literał zakresu włączającego prawą stronę | PartialOrd |
.. | ..expr | Składnia aktualizacji literału struktury | |
.. | variant(x, ..), struct_type { x, .. } | Wiązanie wzorca „i reszta” | |
... | expr...expr | (Przestarzałe, użyj ..= zamiast) We wzorcu: wzorzec zakresu włączającego | |
/ | expr / expr | Dzielenie arytmetyczne | Div |
/= | var /= expr | Dzielenie arytmetyczne i przypisanie | DivAssign |
: | pat: type, ident: type | Ograniczenia | |
: | ident: expr | Inicjalizator pola struktury | |
: | 'a: loop {...} | Etykieta pętli | |
; | expr; | Terminator instrukcji i elementu | |
; | [...; len] | Część składni tablicy o stałym rozmiarze | |
<< | expr << expr | Przesunięcie w lewo | Shl |
<<= | var <<= expr | Przesunięcie w lewo i przypisanie | ShlAssign |
< | expr < expr | Porównanie „mniejsze niż” | PartialOrd |
<= | expr <= expr | Porównanie „mniejsze niż lub równe” | PartialOrd |
= | var = expr, ident = type | Przypisanie/równoważność | |
== | expr == expr | Porównanie równości | PartialEq |
=> | pat => expr | Część składni ramienia dopasowania | |
> | expr > expr | Porównanie „większe niż” | PartialOrd |
>= | expr >= expr | Porównanie „większe niż lub równe” | PartialOrd |
>> | expr >> expr | Przesunięcie w prawo | Shr |
>>= | var >>= expr | Przesunięcie w prawo i przypisanie | ShrAssign |
@ | ident @ pat | Wiązanie wzorca | |
^ | expr ^ expr | Bitowe OR wyłączne | BitXor |
^= | var ^= expr | Bitowe OR wyłączne i przypisanie | BitXorAssign |
| | pat | pat | Alternatywy wzorców | |
| | expr | expr | Bitowe OR | BitOr |
|= | var |= expr | Bitowe OR i przypisanie | BitOrAssign |
|| | expr || expr | Krótkookresowe logiczne OR | |
? | expr? | Propagacja błędu |
Symbole niebędące operatorami
Poniższe tabele zawierają wszystkie symbole, które nie pełnią funkcji operatorów; to znaczy, nie zachowują się jak wywołanie funkcji lub metody.
Tabela B-2 przedstawia symbole, które występują samodzielnie i są ważne w różnych miejscach.
Tabela B-2: Składnia samodzielna
| Symbol | Wyjaśnienie |
|---|---|
'ident | Nazwane życie lub etykieta pętli |
Cyfry natychmiastowo poprzedzone u8, i32, f64, usize itd. | Literał numeryczny określonego typu |
"..." | Literał ciągu znaków |
r"...", r#"..."#, r##"..."## itd. | Surowy literał ciągu znaków; znaki ucieczki nie są przetwarzane |
b"..." | Literał ciągu bajtów; konstruuje tablicę bajtów zamiast ciągu znaków |
br"...", br#"..."#, br##"..."## itd. | Surowy literał ciągu bajtów; połączenie surowego i bajtowego literału |
'...' | Literał znaku |
b'...' | Literał bajtu ASCII |
|…| expr | Zamknięcie (closure) |
! | Zawsze pusty typ dolny dla funkcji rozbieżnych |
_ | Wiązanie wzorca „ignorowane”; używane również do czytelności literałów całkowitych |
Tabela B-3 przedstawia symbole, które pojawiają się w kontekście ścieżki przez hierarchię modułów do elementu.
Tabela B-3: Składnia związana ze ścieżkami
| Symbol | Wyjaśnienie |
|---|---|
ident::ident | Ścieżka przestrzeni nazw |
::path | Ścieżka względna do katalogu głównego skrzynki (tj. jawnie ścieżka bezwzględna) |
self::path | Ścieżka względna do bieżącego modułu (tj. jawnie ścieżka względna) |
super::path | Ścieżka względna do nadrzędnego modułu bieżącego modułu |
type::ident, <type as trait>::ident | Stowarzyszone stałe, funkcje i typy |
<type>::... | Stowarzyszony element dla typu, którego nie można bezpośrednio nazwać (na przykład <&T>::..., <[T]>::... itd.) |
trait::method(...) | Rozróżnianie wywołania metody przez nazwanie cechy, która ją definiuje |
type::method(...) | Rozróżnianie wywołania metody przez nazwanie typu, dla którego jest zdefiniowana |
<type as trait>::method(...) | Rozróżnianie wywołania metody przez nazwanie cechy i typu |
Tabela B-4 przedstawia symbole, które pojawiają się w kontekście używania generycznych parametrów typu.
Tabela B-4: Typy generyczne
| Symbol | Wyjaśnienie |
|---|---|
path<...> | Określa parametry dla typu generycznego w typie (np. Vec<u8>) |
path::<...>, method::<...> | Określa parametry dla typu, funkcji lub metody generycznej w wyrażeniu; często określane jako turbofish (np. "42".parse::<i32>()) |
fn ident<...> ... | Definiuje funkcję generyczną |
struct ident<...> ... | Definiuje strukturę generyczną |
enum ident<...> ... | Definiuje wyliczenie generyczne |
impl<...> ... | Definiuje implementację generyczną |
for<...> type | Ograniczenia czasu życia wyższego rzędu |
type<ident=type> | Typ generyczny, w którym jeden lub więcej stowarzyszonych typów ma określone przypisania (np. Iterator<Item=T>) |
Tabela B-5 przedstawia symbole, które pojawiają się w kontekście ograniczania generycznych parametrów typu za pomocą ograniczeń cech.
Tabela B-5: Ograniczenia cech
| Symbol | Wyjaśnienie |
|---|---|
T: U | Parametr generyczny T ograniczony do typów, które implementują U |
T: 'a | Typ generyczny T musi przetrwać czas życia 'a (co oznacza, że typ nie może przejściowo zawierać żadnych referencji o krótszych czasach życia niż 'a) |
T: 'static | Typ generyczny T nie zawiera żadnych pożyczonych referencji innych niż te 'static |
'b: 'a | Generyczny czas życia 'b musi przetrwać czas życia 'a |
T: ?Sized | Zezwala parametrowi typu generycznego na bycie typem o dynamicznym rozmiarze |
'a + trait, trait + trait | Ograniczenie typu złożonego |
Tabela B-6 przedstawia symbole, które pojawiają się w kontekście wywoływania lub definiowania makr oraz określania atrybutów dla elementu.
Tabela B-6: Makra i atrybuty
| Symbol | Wyjaśnienie |
|---|---|
#[meta] | Atrybut zewnętrzny |
#![meta] | Atrybut wewnętrzny |
$ident | Podstawienie makra |
$ident:kind | Metazmienna makra |
$(...)... | Powtórzenie makra |
ident!(...), ident!{...}, ident![...] | Wywołanie makra |
Tabela B-7 przedstawia symbole tworzące komentarze.
Tabela B-7: Komentarze
| Symbol | Wyjaśnienie |
|---|---|
// | Komentarz liniowy |
//! | Wewnętrzny komentarz doc. liniowy |
/// | Zewnętrzny komentarz doc. liniowy |
/*...*/ | Komentarz blokowy |
/*!...*/ | Wewnętrzny komentarz doc. blokowy |
/**...*/ | Zewnętrzny komentarz doc. blokowy |
Tabela B-8 przedstawia konteksty, w których używane są nawiasy.
Tabela B-8: Nawiasy
| Symbol | Wyjaśnienie |
|---|---|
() | Pusta krotka (aka jednostka), zarówno literał, jak i typ |
(expr) | Wyrażenie w nawiasach |
(expr,) | Wyrażenie krotki z jednym elementem |
(type,) | Typ krotki z jednym elementem |
(expr, ...) | Wyrażenie krotki |
(type, ...) | Typ krotki |
expr(expr, ...) | Wyrażenie wywołania funkcji; używane również do inicjalizacji struktur krotek i wariantów enum krotek |
Tabela B-9 przedstawia konteksty, w których używane są nawiasy klamrowe.
Tabela B-9: Nawiasy klamrowe
| Kontekst | Wyjaśnienie |
|---|---|
{...} | Wyrażenie bloku |
Type {...} | Literał struktury |
Tabela B-10 przedstawia konteksty, w których używane są nawiasy kwadratowe.
Tabela B-10: Nawiasy kwadratowe
| Kontekst | Wyjaśnienie |
|---|---|
[...] | Literał tablicy |
[expr; len] | Literał tablicy zawierający len kopii expr |
[type; len] | Typ tablicy zawierający len instancji type |
expr[expr] | Indeksowanie kolekcji; przeciążalne (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Indeksowanie kolekcji udające wycinanie kolekcji, używające Range, RangeFrom, RangeTo lub RangeFull jako „indeksu” |
C - Cechy dziedziczne
Dodatek C: Cechy dziedziczne (Derivable Traits)
W różnych miejscach w książce omawialiśmy atrybut derive, który można zastosować do definicji struktury lub wyliczenia. Atrybut derive generuje kod, który zaimplementuje cechę z własną domyślną implementacją dla typu, który opatrzyłeś składnią derive.
W tym dodatku przedstawiamy odniesienie do wszystkich cech w bibliotece standardowej, których możesz używać z derive. Każda sekcja obejmuje:
- Jakie operatory i metody umożliwi dziedziczenie tej cechy.
- Co robi implementacja cechy dostarczana przez
derive. - Co implementacja cechy oznacza dla typu.
- Warunki, w których dozwolone lub niedozwolone jest implementowanie cechy.
- Przykłady operacji, które wymagają tej cechy.
Jeśli chcesz innego zachowania niż to, które zapewnia atrybut derive, zapoznaj się z dokumentacją biblioteki standardowej dla każdej cechy, aby uzyskać szczegółowe informacje na temat ręcznej ich implementacji.
Cechy wymienione tutaj są jedynymi zdefiniowanymi przez bibliotekę standardową, które mogą być implementowane na twoich typach za pomocą derive. Inne cechy zdefiniowane w bibliotece standardowej nie mają sensownego domyślnego zachowania, więc to od ciebie zależy, jak je zaimplementujesz, aby miały sens dla tego, co próbujesz osiągnąć.
Przykładem cechy, której nie można dziedziczyć, jest Display, która obsługuje formatowanie dla użytkowników końcowych. Zawsze powinieneś rozważyć odpowiedni sposób wyświetlania typu użytkownikowi końcowemu. Jakie części typu powinny być widoczne dla użytkownika końcowego? Jakie części byłyby dla nich istotne? Jaki format danych byłby dla nich najbardziej istotny? Kompilator Rusta nie ma tej wiedzy, więc nie może zapewnić odpowiedniego domyślnego zachowania.
Lista cech dziedzicznych podana w tym dodatku nie jest wyczerpująca: biblioteki mogą implementować derive dla własnych cech, co sprawia, że lista cech, z którymi można używać derive, jest naprawdę otwarta. Implementacja derive wiąże się z użyciem makra proceduralnego, co zostało omówione w sekcji „Niestandardowe makra derive” w Rozdziale 20.
Debug dla wyjścia programisty
Cecha Debug umożliwia formatowanie debugowania w ciągach formatujących, co sygnalizujesz, dodając :? wewnątrz symboli zastępczych {}.
Cecha Debug pozwala na drukowanie instancji typu w celach debugowania, dzięki czemu ty i inni programiści używający twojego typu możecie sprawdzić instancję w określonym punkcie wykonania programu.
Cecha Debug jest wymagana, na przykład, przy użyciu makra assert_eq!. To makro drukuje wartości instancji podanych jako argumenty, jeśli twierdzenie o równości zawiedzie, tak aby programiści mogli zobaczyć, dlaczego dwie instancje nie były równe.
PartialEq i Eq dla porównań równości
Cecha PartialEq pozwala porównywać instancje typu pod kątem równości i umożliwia użycie operatorów == i !=.
Dziedziczenie PartialEq implementuje metodę eq. Gdy PartialEq jest dziedziczone w strukturach, dwie instancje są równe tylko wtedy, gdy wszystkie pola są równe, i nie są równe, jeśli którekolwiek pola nie są równe. Gdy dziedziczone w wyliczeniach, każdy wariant jest równy sam sobie i nierówny innym wariantom.
Cecha PartialEq jest wymagana, na przykład, przy użyciu makra assert_eq!, które musi być w stanie porównać dwie instancje typu pod kątem równości.
Cecha Eq nie ma żadnych metod. Jej celem jest sygnalizowanie, że dla każdej wartości typu oznaczonego, wartość jest równa sobie. Cecha Eq może być zastosowana tylko do typów, które również implementują PartialEq, chociaż nie wszystkie typy, które implementują PartialEq, mogą implementować Eq. Jednym z przykładów są typy liczb zmiennoprzecinkowych: implementacja liczb zmiennoprzecinkowych mówi, że dwie instancje wartości not-a-number (NaN) nie są sobie równe.
Przykładem, kiedy wymagana jest cecha Eq, jest użycie kluczy w HashMap<K, V>, aby HashMap<K, V> mogło stwierdzić, czy dwa klucze są takie same.
PartialOrd i Ord dla porównań porządkowania
Cecha PartialOrd pozwala porównywać instancje typu w celach sortowania. Typ, który implementuje PartialOrd, może być używany z operatorami <, >, <=, i >=. Cechę PartialOrd można zastosować tylko do typów, które również implementują PartialEq.
Dziedziczenie PartialOrd implementuje metodę partial_cmp, która zwraca Option<Ordering>, która będzie None, gdy podane wartości nie dają porządku. Przykładem wartości, która nie daje porządku, nawet jeśli większość wartości tego typu można porównać, jest wartość zmiennoprzecinkowa NaN. Wywołanie partial_cmp z dowolną liczbą zmiennoprzecinkową i wartością zmiennoprzecinkową NaN zwróci None.
Dziedzicząc w strukturach, PartialOrd porównuje dwie instancje, porównując wartość w każdym polu w kolejności, w jakiej pola pojawiają się w definicji struktury. Dziedzicząc w wyliczeniach, warianty wyliczenia zadeklarowane wcześniej w definicji wyliczenia są uważane za mniejsze niż warianty wymienione później.
Cecha PartialOrd jest wymagana, na przykład, dla metody gen_range z crate rand, która generuje losową wartość w zakresie określonym przez wyrażenie zakresowe.
Cecha Ord pozwala wiedzieć, że dla dowolnych dwóch wartości typu opisanego adnotacją, zawsze będzie istniało prawidłowe uporządkowanie. Cecha Ord implementuje metodę cmp, która zwraca Ordering zamiast Option<Ordering>, ponieważ prawidłowe uporządkowanie zawsze będzie możliwe. Cechę Ord można zastosować tylko do typów, które również implementują PartialOrd i Eq (a Eq wymaga PartialEq). Dziedzicząc w strukturach i wyliczeniach, cmp zachowuje się tak samo jak zaimplementowane partial_cmp w PartialOrd.
Przykładem, kiedy wymagana jest cecha Ord, jest przechowywanie wartości w BTreeSet<T>, strukturze danych, która przechowuje dane na podstawie kolejności sortowania wartości.
Clone i Copy do duplikowania wartości
Cecha Clone pozwala jawnie utworzyć głęboką kopię wartości, a proces duplikacji może obejmować uruchomienie dowolnego kodu i kopiowanie danych na stercie. Aby uzyskać więcej informacji na temat Clone, zobacz sekcję „Zmienne i dane współdziałające z Clone” w Rozdziale 4.
Dziedziczenie Clone implementuje metodę clone, która, zaimplementowana dla całego typu, wywołuje clone na każdej z części typu. Oznacza to, że wszystkie pola lub wartości w typie muszą również implementować Clone, aby dziedziczyć Clone.
Przykładem, kiedy wymagana jest cecha Clone, jest wywołanie metody to_vec na wycinku. Wycinek nie jest właścicielem instancji typów, które zawiera, ale wektor zwrócony z to_vec będzie musiał być właścicielem swoich instancji, więc to_vec wywołuje clone na każdym elemencie. W ten sposób typ przechowywany w wycinku musi implementować Clone.
Cecha Copy pozwala duplikować wartość tylko poprzez kopiowanie bitów przechowywanych na stosie; nie jest potrzebny żaden arbitralny kod. Więcej informacji na temat Copy znajdziesz w sekcji „Dane tylko na stosie: Copy” w Rozdziale 4.
Cecha Copy nie definiuje żadnych metod, aby zapobiec przeciążaniu tych metod przez programistów i naruszaniu założenia, że żaden arbitralny kod nie jest wykonywany. W ten sposób wszyscy programiści mogą zakładać, że kopiowanie wartości będzie bardzo szybkie.
Możesz dziedziczyć Copy na dowolnym typie, którego wszystkie części implementują Copy. Typ, który implementuje Copy, musi również implementować Clone, ponieważ typ, który implementuje Copy, ma trywialną implementację Clone, która wykonuje to samo zadanie co Copy.
Cecha Copy jest rzadko wymagana; typy, które implementują Copy, mają dostępne optymalizacje, co oznacza, że nie musisz wywoływać clone, co sprawia, że kod jest bardziej zwięzły.
Wszystko, co jest możliwe z Copy, można również osiągnąć z Clone, ale kod może być wolniejszy lub musi używać clone w niektórych miejscach.
Hash do mapowania wartości na wartość o stałym rozmiarze
Cecha Hash pozwala na pobranie instancji typu o dowolnym rozmiarze i zmapowanie jej na wartość o stałym rozmiarze za pomocą funkcji haszującej. Dziedziczenie Hash implementuje metodę hash. Zaimplementowana metoda hash łączy wynik wywołania hash na każdej z części typu, co oznacza, że wszystkie pola lub wartości muszą również implementować Hash, aby dziedziczyć Hash.
Przykładem, kiedy wymagana jest cecha Hash, jest przechowywanie kluczy w HashMap<K, V> w celu efektywnego przechowywania danych.
Default dla wartości domyślnych
Cecha Default pozwala utworzyć domyślną wartość dla typu. Dziedziczenie Default implementuje funkcję default. Dziedziczona implementacja funkcji default wywołuje funkcję default dla każdej części typu, co oznacza, że wszystkie pola lub wartości w typie muszą również implementować Default, aby dziedziczyć Default.
Funkcja Default::default jest powszechnie używana w połączeniu ze składnią aktualizacji struktury omówioną w sekcji „Tworzenie instancji z innych instancji za pomocą składni aktualizacji struktur” w Rozdziale 5. Możesz dostosować kilka pól struktury, a następnie ustawić i użyć domyślnej wartości dla pozostałych pól, używając ..Default::default().
Cecha Default jest wymagana, gdy używasz metody unwrap_or_default na instancjach Option<T>, na przykład. Jeśli Option<T> jest None, metoda unwrap_or_default zwróci wynik Default::default dla typu T przechowywanego w Option<T>.
D - Przydatne narzędzia deweloperskie
Dodatek D: Przydatne narzędzia deweloperskie
W tym dodatku omówimy kilka przydatnych narzędzi deweloperskich, które udostępnia projekt Rust. Przyjrzymy się automatycznemu formatowaniu, szybkim sposobom stosowania poprawek ostrzeżeń, linterowi oraz integracji z IDE.
Automatyczne formatowanie z rustfmt
Narzędzie rustfmt formatuje twój kod zgodnie ze społecznościowym stylem kodu. Wiele projektów współpracujących używa rustfmt, aby zapobiec sporom o to, jaki styl zastosować podczas pisania w Rust: każdy formatuje swój kod za pomocą narzędzia.
Instalacje Rust domyślnie zawierają rustfmt, więc powinieneś już mieć programy rustfmt i cargo-fmt w swoim systemie. Te dwa polecenia są analogiczne do rustc i cargo w tym sensie, że rustfmt pozwala na bardziej szczegółową kontrolę, a cargo-fmt rozumie konwencje projektu używającego Cargo. Aby sformatować dowolny projekt Cargo, wpisz następujące polecenie:
$ cargo fmt
Uruchomienie tego polecenia formatuje cały kod Rust w bieżącej skrzynce. Powinno to zmienić tylko styl kodu, a nie semantykę kodu. Aby uzyskać więcej informacji o rustfmt, zobacz jego dokumentację.
Napraw swój kod za pomocą rustfix
Narzędzie rustfix jest dołączone do instalacji Rust i może automatycznie naprawiać ostrzeżenia kompilatora, które mają jasny sposób rozwiązania problemu, który jest prawdopodobnie tym, czego chcesz. Prawdopodobnie widziałeś już ostrzeżenia kompilatora. Na przykład, rozważ ten kod:
Nazwa pliku: src/main.rs
fn main() {
let mut x = 42;
println!("{x}");
}Tutaj definiujemy zmienną x jako zmienną, ale nigdy jej faktycznie nie modyfikujemy. Rust ostrzega nas o tym:
$ cargo build
Kompilowanie myprogram v0.1.0 (file:///projects/myprogram)
warning: zmienna nie musi być mutowalna
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| pomoc: usuń to `mut`
|
= note: `#[warn(unused_mut)]` domyślnie włączone
Ostrzeżenie sugeruje, aby usunąć słowo kluczowe mut. Możemy automatycznie zastosować tę sugestię za pomocą narzędzia rustfix, uruchamiając polecenie cargo fix:
$ cargo fix
Sprawdzanie myprogram v0.1.0 (file:///projects/myprogram)
Naprawianie src/main.rs (1 poprawka)
Zakończono dev [nieoptymalny + debuginfo] cel(e) w 0.59s
Kiedy ponownie spojrzymy na src/main.rs, zobaczymy, że cargo fix zmienił kod:
Nazwa pliku: src/main.rs
fn main() {
let x = 42;
println!("{x}");
}Zmienna x jest teraz niezmienna, a ostrzeżenie już się nie pojawia.
Możesz również użyć polecenia cargo fix, aby przetransformować swój kod między różnymi edycjami Rust. Edycje są omówione w Dodatku E.
Więcej lintów z Clippy
Narzędzie Clippy to zbiór lintów do analizowania kodu, dzięki czemu możesz wyłapać typowe błędy i ulepszyć swój kod w Rust. Clippy jest dołączone do standardowych instalacji Rust.
Aby uruchomić lintery Clippy w dowolnym projekcie Cargo, wpisz następujące polecenie:
$ cargo clippy
Na przykład, powiedzmy, że piszesz program, który używa przybliżenia stałej matematycznej, takiej jak pi, jak ten program:
fn main() {
let x = 3.1415;
let r = 8.0;
println!("powierzchnia koła wynosi {}", x * r * r);
}Uruchomienie cargo clippy w tym projekcie powoduje następujący błąd:
błąd: znaleziono przybliżoną wartość `f{32, 64}::consts::PI`
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` domyślnie włączone
= help: rozważ użycie stałej bezpośrednio
= help: więcej informacji znajdziesz na https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Ten błąd informuje, że Rust ma już zdefiniowaną bardziej precyzyjną stałą PI, i że twój program byłby bardziej poprawny, gdybyś zamiast tego użył tej stałej. Następnie zmieniłbyś swój kod, aby używać stałej PI.
Poniższy kod nie powoduje żadnych błędów ani ostrzeżeń z Clippy:
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("powierzchnia koła wynosi {}", x * r * r);
}Aby uzyskać więcej informacji o Clippy, zobacz jego dokumentację.
Integracja z IDE za pomocą rust-analyzer
Aby pomóc w integracji z IDE, społeczność Rust zaleca używanie rust-analyzer. To narzędzie to zestaw narzędzi zorientowanych na kompilator, które komunikują się za pomocą Language Server Protocol, czyli specyfikacji komunikacji między IDE a językami programowania. Różni klienci mogą używać rust-analyzer, np. wtyczka Rust analyzer dla Visual Studio Code.
Odwiedź stronę główną projektu rust-analyzer, aby zapoznać się z instrukcjami instalacji, a następnie zainstaluj obsługę serwera języka w swoim IDE. Twoje IDE zyska takie możliwości jak autouzupełnianie, skok do definicji i wbudowane błędy.
E - Edycje
Dodatek E: Edycje
W Rozdziale 1 widziałeś, że cargo new dodaje nieco metadanych do pliku Cargo.toml dotyczących edycji. Ten dodatek opowiada o tym, co to oznacza!
Język i kompilator Rust mają sześciotygodniowy cykl wydawniczy, co oznacza, że użytkownicy otrzymują stały strumień nowych funkcji. Inne języki programowania rzadziej wydają większe zmiany; Rust częściej wydaje mniejsze aktualizacje. Po pewnym czasie wszystkie te drobne zmiany sumują się. Ale z wydania na wydanie trudno jest spojrzeć wstecz i powiedzieć: „Wow, między Rustem 1.10 a Rustem 1.31 Rust bardzo się zmienił!”
Co około trzy lata zespół Rust tworzy nową edycję Rust. Każda edycja łączy funkcje, które wylądowały, w przejrzysty pakiet z w pełni zaktualizowaną dokumentacją i narzędziami. Nowe edycje są dostarczane w ramach zwykłego sześciotygodniowego procesu wydawniczego.
Edycje służą różnym celom dla różnych ludzi:
- Dla aktywnych użytkowników Rusta, nowa edycja łączy stopniowe zmiany w łatwy do zrozumienia pakiet.
- Dla nie-użytkowników, nowa edycja sygnalizuje, że nastąpiły pewne poważne postępy, co może sprawić, że Rust będzie wart ponownego rozważenia.
- Dla tych, którzy rozwijają Rusta, nowa edycja stanowi punkt zborny dla całego projektu.
W chwili pisania tego tekstu dostępne są cztery edycje Rusta: Rust 2015, Rust 2018, Rust 2021 i Rust 2024. Ta książka jest napisana z użyciem idiomów edycji Rust 2024.
Klucz edition w Cargo.toml wskazuje, której edycji kompilator powinien używać dla twojego kodu. Jeśli klucz nie istnieje, Rust używa 2015 jako wartości edycji z powodu kompatybilności wstecznej.
Każdy projekt może zdecydować się na edycję inną niż domyślna edycja 2015. Edycje mogą zawierać niekompatybilne zmiany, takie jak włączenie nowego słowa kluczowego, które koliduje z identyfikatorami w kodzie. Jednak, jeśli nie zdecydujesz się na te zmiany, twój kod będzie nadal kompilować się, nawet jeśli zaktualizujesz wersję kompilatora Rust, której używasz.
Wszystkie wersje kompilatora Rust obsługują każdą edycję, która istniała przed wydaniem tego kompilatora, i mogą łączyć skrzynki z dowolnych obsługiwanych edycji. Zmiany edycji wpływają tylko na sposób, w jaki kompilator początkowo parsuje kod. Dlatego, jeśli używasz Rust 2015, a jedna z twoich zależności używa Rust 2018, twój projekt skompiluje się i będzie mógł używać tej zależności. Sytuacja odwrotna, w której twój projekt używa Rust 2018, a zależność używa Rust 2015, również działa.
Aby było jasne: większość funkcji będzie dostępna we wszystkich edycjach. Programiści używający dowolnej edycji Rust nadal będą widzieć ulepszenia w miarę pojawiania się nowych stabilnych wydań. Jednak w niektórych przypadkach, głównie gdy dodawane są nowe słowa kluczowe, niektóre nowe funkcje mogą być dostępne tylko w późniejszych edycjach. Będziesz musiał zmienić edycję, jeśli chcesz skorzystać z takich funkcji.
Więcej szczegółów znajdziesz w Przewodniku po Edycjach Rust. Jest to kompletna książka, która wylicza różnice między edycjami i wyjaśnia, jak automatycznie zaktualizować kod do nowej edycji za pomocą cargo fix.
F - Tłumaczenia książki
Dodatek F: Tłumaczenia książki
Dla zasobów w językach innych niż angielski. Większość z nich jest nadal w toku; zobacz etykietę Tłumaczenia, aby pomóc lub dać nam znać o nowym tłumaczeniu!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternatywna, Español by RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
G - Jak powstaje Rust i „Nightly Rust”
Dodatek G - Jak powstaje Rust i „Nightly Rust”
Ten dodatek opisuje, jak powstaje Rust i jak to wpływa na Ciebie jako dewelopera Rust.
Stabilność bez stagnacji
Jako język, Rust bardzo dba o stabilność Twojego kodu. Chcemy, aby Rust był solidnym fundamentem, na którym możesz budować, a gdyby rzeczy ciągle się zmieniały, byłoby to niemożliwe. Jednocześnie, jeśli nie będziemy mogli eksperymentować z nowymi funkcjami, możemy nie odkryć ważnych wad aż do momentu ich wydania, kiedy to nie będziemy już w stanie nic zmienić.
Naszym rozwiązaniem tego problemu jest to, co nazywamy „stabilnością bez stagnacji”, a nasza przewodnia zasada brzmi: nigdy nie powinieneś obawiać się aktualizacji do nowej wersji stabilnego Rusta. Każda aktualizacja powinna być bezbolesna, ale także przynosić nowe funkcje, mniej błędów i szybszy czas kompilacji.
Ciuch, ciuch! Kanały wydań i jazda pociągami
Rozwój Rusta odbywa się według rozkładu jazdy pociągów. Oznacza to, że cały rozwój odbywa się w głównej gałęzi repozytorium Rusta. Wydania są zgodne z modelem pociągu wydań oprogramowania, który był używany przez Cisco IOS i inne projekty. Istnieją trzy kanały wydań Rusta:
- Nightly
- Beta
- Stabilny
Większość deweloperów Rusta używa głównie kanału stabilnego, ale ci, którzy chcą wypróbować eksperymentalne nowe funkcje, mogą używać nightly lub beta.
Oto przykład, jak działa proces rozwoju i wydawania: załóżmy, że zespół Rusta pracuje nad wydaniem Rust 1.5. To wydanie miało miejsce w grudniu 2015 roku, ale dostarczy nam realistycznych numerów wersji. Do Rusta dodawana jest nowa funkcja: nowy commit ląduje w głównej gałęzi. Każdej nocy tworzona jest nowa wersja nightly Rusta. Każdy dzień jest dniem wydania, a te wydania są tworzone automatycznie przez naszą infrastrukturę wydawniczą. Tak więc z biegiem czasu nasze wydania wyglądają tak, raz na noc:
nightly: * - - * - - *
Co sześć tygodni nadchodzi czas na przygotowanie nowego wydania! Gałąź beta repozytorium Rusta rozgałęzia się od głównej gałęzi używanej przez nightly. Teraz istnieją dwa wydania:
nightly: * - - * - - *
|
beta: *
Większość użytkowników Rusta nie używa aktywnie wydań beta, ale testuje je w swoich systemach CI, aby pomóc Rustowi odkryć możliwe regresje. W międzyczasie, każdej nocy nadal pojawia się wydanie nightly:
nightly: * - - * - - * - - * - - *
|
beta: *
Powiedzmy, że znaleziono regresję. Dobrze, że mieliśmy trochę czasu na przetestowanie wydania beta, zanim regresja wkradła się do stabilnego wydania! Poprawka jest stosowana do głównej gałęzi, tak aby nightly zostało naprawione, a następnie poprawka jest przenoszona do gałęzi beta, i tworzone jest nowe wydanie beta:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Sześć tygodni po stworzeniu pierwszej bety, nadszedł czas na stabilne wydanie! Gałąź stable jest tworzona z gałęzi beta:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Hura! Rust 1.5 jest gotowy! Zapomnieliśmy jednak o jednej rzeczy: ponieważ minęło sześć tygodni, potrzebujemy również nowej bety następnej wersji Rusta, 1.6. Tak więc po tym, jak stable rozgałęzia się od beta, następna wersja beta ponownie rozgałęzia się od nightly:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
Nazywa się to „modelem pociągu”, ponieważ co sześć tygodni wydanie „opuszcza stację”, ale nadal musi odbyć podróż przez kanał beta, zanim dotrze jako stabilne wydanie.
Rust wydaje się co sześć tygodni, jak w zegarku. Jeśli znasz datę jednego wydania Rusta, możesz poznać datę następnego: to sześć tygodni później. Miłym aspektem harmonogramu wydań co sześć tygodni jest to, że następny pociąg nadjedzie wkrótce. Jeśli jakaś funkcja przypadkowo ominie konkretne wydanie, nie ma powodu do obaw: kolejne pojawi się w krótkim czasie! Pomaga to zmniejszyć presję na dodawanie niedopracowanych funkcji tuż przed terminem wydania.
Dzięki temu procesowi zawsze możesz sprawdzić następną kompilację Rusta i samodzielnie zweryfikować, że łatwo jest ją zaktualizować: jeśli wydanie beta nie działa zgodnie z oczekiwaniami, możesz zgłosić to zespołowi i uzyskać poprawkę przed wydaniem kolejnej stabilnej wersji! Awarie w wydaniu beta są stosunkowo rzadkie, ale rustc to nadal oprogramowanie, i błędy istnieją.
Czas wsparcia
Projekt Rust wspiera najnowszą stabilną wersję. Gdy nowa stabilna wersja zostanie wydana, stara wersja osiąga koniec swojego życia (EOL). Oznacza to, że każda wersja jest wspierana przez sześć tygodni.
Funkcje niestabilne
W tym modelu wydań jest jeszcze jedna kwestia: funkcje niestabilne. Rust używa techniki zwanej „flagami funkcji” do określania, które funkcje są włączone w danym wydaniu. Jeśli nowa funkcja jest w trakcie aktywnego rozwoju, trafia ona do głównej gałęzi, a zatem do nightly, ale za flagą funkcji. Jeśli jako użytkownik chcesz wypróbować funkcję będącą w fazie rozwoju, możesz to zrobić, ale musisz używać wydania nightly Rusta i opatrzyć swój kod źródłowy odpowiednią flagą, aby ją włączyć.
Jeśli używasz wydania beta lub stabilnego Rusta, nie możesz używać żadnych flag funkcji. To jest klucz, który pozwala nam praktycznie korzystać z nowych funkcji, zanim ogłosimy je na zawsze stabilnymi. Ci, którzy chcą wypróbować najnowsze rozwiązania, mogą to zrobić, a ci, którzy chcą solidnego doświadczenia, mogą pozostać przy stabilnej wersji i wiedzieć, że ich kod nie zostanie zepsuty. Stabilność bez stagnacji.
Ta książka zawiera informacje wyłącznie o stabilnych funkcjach, ponieważ funkcje w trakcie rozwoju wciąż się zmieniają, i z pewnością będą się różnić między czasem, gdy ta książka została napisana, a momentem, gdy zostaną włączone w stabilnych kompilacjach. Dokumentację funkcji dostępnych tylko w nightly można znaleźć online.
Rustup i rola Rust Nightly
Rustup ułatwia przełączanie się między różnymi kanałami wydań Rusta, globalnie lub na zasadzie projektu. Domyślnie będziesz mieć zainstalowanego stabilnego Rusta. Aby zainstalować nightly, na przykład:
$ rustup toolchain install nightly
Możesz również zobaczyć wszystkie łańcuchy narzędzi (wydania Rusta i powiązane komponenty), które zainstalowałeś za pomocą rustup. Oto przykład na komputerze z systemem Windows jednego z autorów:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Jak widać, stabilny łańcuch narzędzi jest domyślny. Większość użytkowników Rusta używa stabilnej wersji przez większość czasu. Możesz chcieć używać stabilnej wersji przez większość czasu, ale używać nightly w konkretnym projekcie, ponieważ zależy Ci na najnowszej funkcji. Aby to zrobić, możesz użyć rustup override w katalogu tego projektu, aby ustawić łańcuch narzędzi nightly jako ten, którego rustup powinien używać, gdy znajdujesz się w tym katalogu:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Teraz, za każdym razem, gdy wywołasz rustc lub cargo w katalogu ~/projects/needs-nightly, rustup upewni się, że używasz Rusta nightly, zamiast domyślnego stabilnego Rusta. Jest to przydatne, gdy masz wiele projektów Rust!
Proces RFC i zespoły
Jak więc dowiedzieć się o tych nowych funkcjach? Model rozwoju Rusta opiera się na procesie Request For Comments (RFC). Jeśli chcesz wprowadzić ulepszenie w Rust, możesz napisać propozycję, zwaną RFC.
Każdy może pisać RFC, aby ulepszyć Rusta, a propozycje są recenzowane i dyskutowane przez zespół Rusta, który składa się z wielu podzespołów tematycznych. Pełną listę zespołów można znaleźć na stronie Rusta, która obejmuje zespoły dla każdego obszaru projektu: projektowanie języka, implementacja kompilatora, infrastruktura, dokumentacja i wiele innych. Odpowiedni zespół czyta propozycję i komentarze, pisze własne komentarze, a ostatecznie osiąga się konsensus w sprawie zaakceptowania lub odrzucenia funkcji.
Jeśli funkcja zostanie zaakceptowana, otwierane jest zgłoszenie w repozytorium Rusta i ktoś może ją zaimplementować. Osoba, która ją zaimplementuje, bardzo dobrze może nie być osobą, która pierwotnie zaproponowała tę funkcję! Kiedy implementacja jest gotowa, trafia do głównej gałęzi za bramą funkcji, tak jak omówiliśmy w sekcji „Funkcje niestabilne”.
Po pewnym czasie, gdy deweloperzy Rusta korzystający z wydań nightly będą mogli wypróbować nową funkcję, członkowie zespołu przedyskutują tę funkcję, jak sprawdziła się w nightly, i zdecydują, czy powinna trafić do stabilnego Rusta, czy nie. Jeśli decyzja zostanie podjęta o kontynuowaniu, brama funkcji zostaje usunięta, a funkcja jest teraz uważana za stabilną! Trafia ona pociągami do nowego stabilnego wydania Rusta.